
Spanish BERT (BETO) + POS
This model is a fine-tuned on Spanish CONLL CORPORA version of the Spanish BERT cased (BETO) for POS (Part of Speech tagging) downstream task.
Details of the downstream task (POS) - Dataset
- Dataset: CONLL Corpora ES with data augmentation techniques
I preprocessed the dataset and split it as train / dev (80/20)
| Dataset | # Examples |
|---|---|
| Train | 340 K |
| Dev | 50 K |
60 Labels covered:
AO, AQ, CC, CS, DA, DD, DE, DI, DN, DP, DT, Faa, Fat, Fc, Fd, Fe, Fg, Fh, Fia, Fit, Fp, Fpa, Fpt, Fs, Ft, Fx, Fz, I, NC, NP, P0, PD, PI, PN, PP, PR, PT, PX, RG, RN, SP, VAI, VAM, VAN, VAP, VAS, VMG, VMI, VMM, VMN, VMP, VMS, VSG, VSI, VSM, VSN, VSP, VSS, Y and Z
Metrics on evaluation set:
| Metric | # score |
|---|---|
| F1 | 90.06 |
| Precision | 89.46 |
| Recall | 90.67 |
Model in action
Fast usage with pipelines:
from transformers import pipeline
nlp_pos = pipeline(
"ner",
model="mrm8488/bert-spanish-cased-finetuned-pos",
tokenizer=(
'mrm8488/bert-spanish-cased-finetuned-pos',
{"use_fast": False}
))
text = 'Mis amigos están pensando en viajar a Londres este verano'
nlp_pos(text)
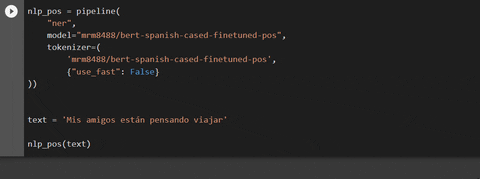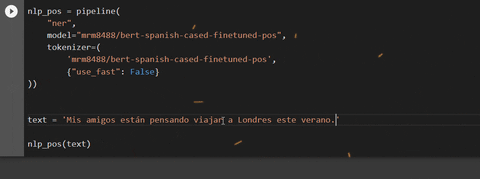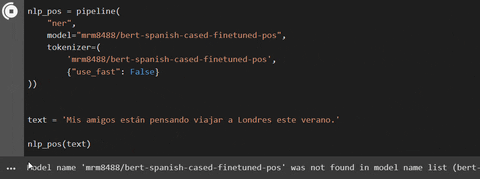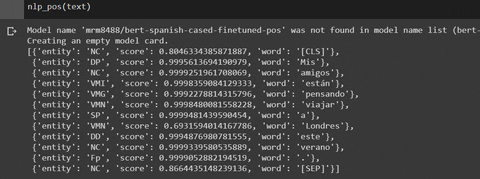
#Output:
'''
[{'entity': 'NC', 'score': 0.7792173624038696, 'word': '[CLS]'},
{'entity': 'DP', 'score': 0.9996283650398254, 'word': 'Mis'},
{'entity': 'NC', 'score': 0.9999253749847412, 'word': 'amigos'},
{'entity': 'VMI', 'score': 0.9998560547828674, 'word': 'están'},
{'entity': 'VMG', 'score': 0.9992249011993408, 'word': 'pensando'},
{'entity': 'SP', 'score': 0.9999602437019348, 'word': 'en'},
{'entity': 'VMN', 'score': 0.9998666048049927, 'word': 'viajar'},
{'entity': 'SP', 'score': 0.9999545216560364, 'word': 'a'},
{'entity': 'VMN', 'score': 0.8722310662269592, 'word': 'Londres'},
{'entity': 'DD', 'score': 0.9995203614234924, 'word': 'este'},
{'entity': 'NC', 'score': 0.9999248385429382, 'word': 'verano'},
{'entity': 'NC', 'score': 0.8802427649497986, 'word': '[SEP]'}]
'''
16 POS tags version also available here
Created by Manuel Romero/@mrm8488
Made with ♥ in Spain
- Downloads last month
- 169
This model does not have enough activity to be deployed to Inference API (serverless) yet. Increase its social
visibility and check back later, or deploy to Inference Endpoints (dedicated)
instead.