
1Mohamed Bin Zayed University of Artificial Intelligence (MBZUAI) 2Technical University of Munich (TUM) 3Aalto University 4Australian National University 5Linköping University
News
- 30 May 2024: Open-YOLO 3D released on arXiv. 📝
- 30 May 2024: Code released. 💻
Abstract
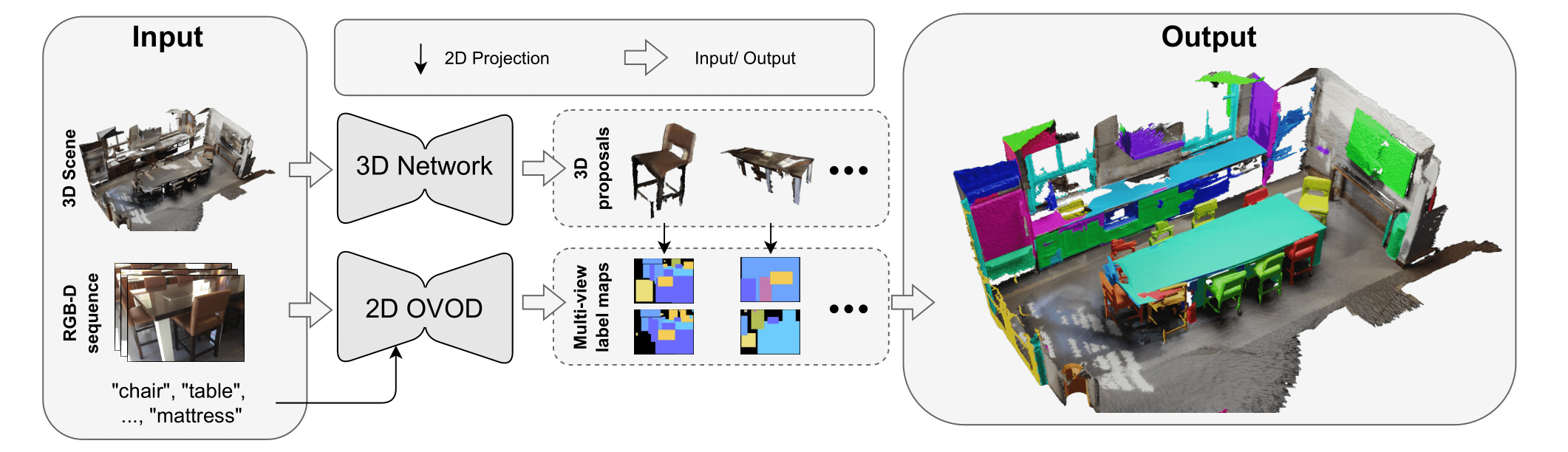
Recent works on open-vocabulary 3D instance segmentation show strong promise, but at the cost of slow inference speed and high computation requirements. This high computation cost is typically due to their heavy reliance on 3D clip features, which require computationally expensive 2D foundation models like Segment Anything (SAM) and CLIP for multi-view aggregation into 3D. As a consequence, this hampers their applicability in many real-world applications that require both fast and accurate predictions. To this end, we propose a fast yet accurate open-vocabulary 3D instance segmentation approach, named Open-YOLO 3D, that effectively leverages only 2D object detection from multi-view RGB images for open-vocabulary 3D instance segmentation. We address this task by generating class-agnostic 3D masks for objects in the scene and associating them with text prompts. We observe that the projection of class-agnostic 3D point cloud instances already holds instance information; thus, using SAM might only result in redundancy that unnecessarily increases the inference time. We empirically find that a better performance of matching text prompts to 3D masks can be achieved in a faster fashion with a 2D object detector. We validate our Open-YOLO 3D on two benchmarks, ScanNet200 and Replica, under two scenarios: (i) with ground truth masks, where labels are required for given object proposals, and (ii) with class-agnostic 3D proposals generated from a 3D proposal network. Our Open-YOLO 3D achieves state-of-the-art performance on both datasets while obtaining up to 16x speedup compared to the best existing method in literature. On ScanNet200 val. set, our Open-YOLO 3D achieves mean average precision (mAP) of 24.7% while operating at 22 seconds per scene.
Qualitative results

Acknoledgments
We would like to thank the authors of Mask3D and YoloWorld for their works which were used for our model.
BibTeX :
@misc{boudjoghra2024openyolo,
title={Open-YOLO 3D: Towards Fast and Accurate Open-Vocabulary 3D Instance Segmentation},
author={Mohamed El Amine Boudjoghra and Angela Dai and Jean Lahoud and Hisham Cholakkal and Rao Muhammad Anwer and Salman Khan and Fahad Shahbaz Khan},
year={2024},
eprint={2406.02548},
archivePrefix={arXiv},
primaryClass={cs.CV}
}