
error loading the model: pip install accelerate

I use the following sample code in the model car and I get this error:
ImportError: Using low_cpu_mem_usage=True or a device_map requires Accelerate: pip install accelerate
I run the install code but I still receive the same answer.
I am using colab with a100 gpu.
How can I solve this issue?
from PIL import Image
import requests
from transformers import AutoModelForCausalLM
from transformers import AutoProcessor
model_id = "microsoft/Phi-3-vision-128k-instruct"
model = AutoModelForCausalLM.from_pretrained(model_id, device_map="cuda", trust_remote_code=True, torch_dtype="auto", _attn_implementation='flash_attention_2') # use _attn_implementation='eager' to disable flash attention
processor = AutoProcessor.from_pretrained(model_id, trust_remote_code=True)
messages = [
{"role": "user", "content": "<|image_1|>\nWhat is shown in this image?"},
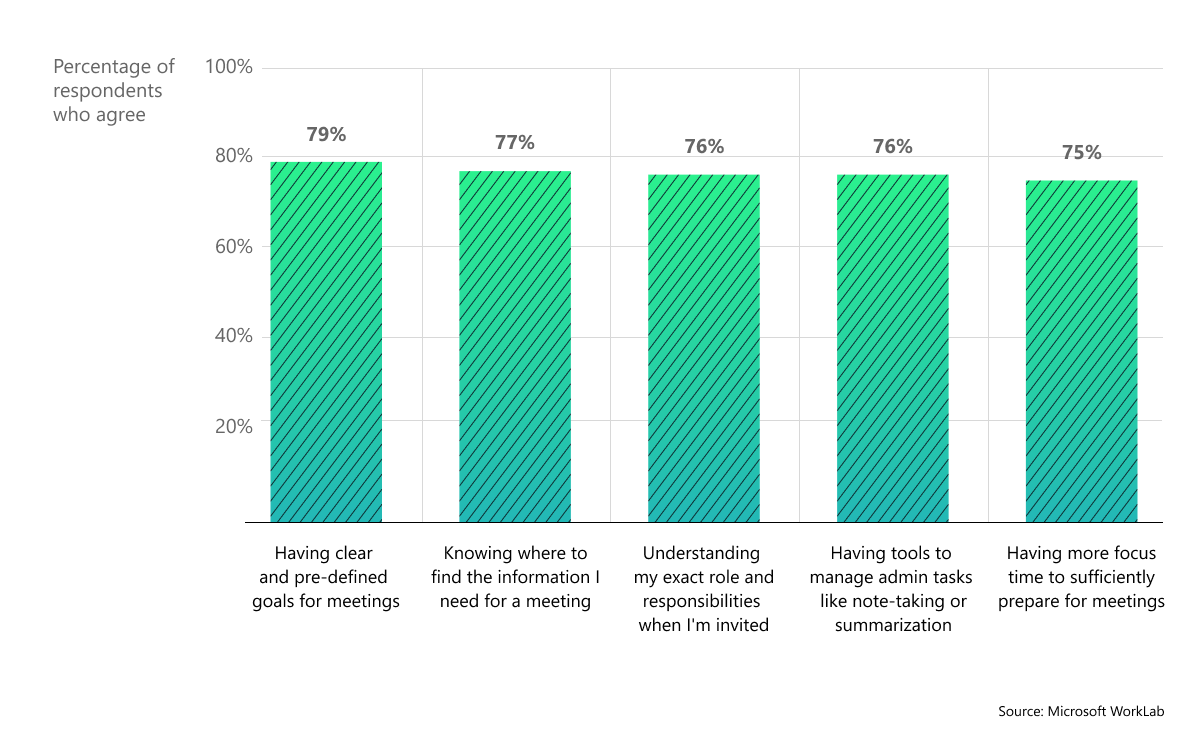
{"role": "assistant", "content": "The chart displays the percentage of respondents who agree with various statements about their preparedness for meetings. It shows five categories: 'Having clear and pre-defined goals for meetings', 'Knowing where to find the information I need for a meeting', 'Understanding my exact role and responsibilities when I'm invited', 'Having tools to manage admin tasks like note-taking or summarization', and 'Having more focus time to sufficiently prepare for meetings'. Each category has an associated bar indicating the level of agreement, measured on a scale from 0% to 100%."},
{"role": "user", "content": "Provide insightful questions to spark discussion."}
]
url = "https://assets-c4akfrf5b4d3f4b7.z01.azurefd.net/assets/2024/04/BMDataViz_661fb89f3845e.png"
image = Image.open(requests.get(url, stream=True).raw)
prompt = processor.tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
inputs = processor(prompt, [image], return_tensors="pt").to("cuda:0")
generation_args = {
"max_new_tokens": 500,
"temperature": 0.0,
"do_sample": False,
}
generate_ids = model.generate(**inputs, eos_token_id=processor.tokenizer.eos_token_id, **generation_args)
remove input tokens
generate_ids = generate_ids[:, inputs['input_ids'].shape[1]:]
response = processor.batch_decode(generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)[0]
print(response)

{kind=link}
have you solved the problem ?
have you solved the problem ?
no and I really wonder how all these people are using these HF VLM models without any problem. I keep getting these errors in most of the models.
I'm working on it , I'll write if I can figure it out
in colab and probably in jupyter notebooks in general, restarting the kernel after pip install accelerate solves the problem.
https://stackoverflow.com/questions/76902752/importerror-using-low-cpu-mem-usage-true-or-a-device-map-requires-accelerat
this step was okay for most models but for phi3 it also asks you to run this command pip install flash-attn --no-build-isolation