
MiniCheck & LLM-AggreFact
Collection
MiniCheck: Efficient Fact-Checking of LLMs on Grounding Documents
•
6 items
•
Updated
•
4
![]()
This is a fact-checking model from our work:
📃 MiniCheck: Efficient Fact-Checking of LLMs on Grounding Documents (EMNLP 2024, GitHub Repo)
The model is based on RoBERTA-Large that predicts a binary label - 1 for supported and 0 for unsupported. The model is doing predictions on the sentence-level. It takes as input a document and a sentence and determine whether the sentence is supported by the document: MiniCheck-Model(document, claim) -> {0, 1}
MiniCheck-RoBERTa-Large is fine tuned from the trained RoBERTA-Large model from AlignScore (Zha et al., 2023) on 14K synthetic data generated from scratch in a structed way (more details in the paper).
We also have other three MiniCheck model variants:
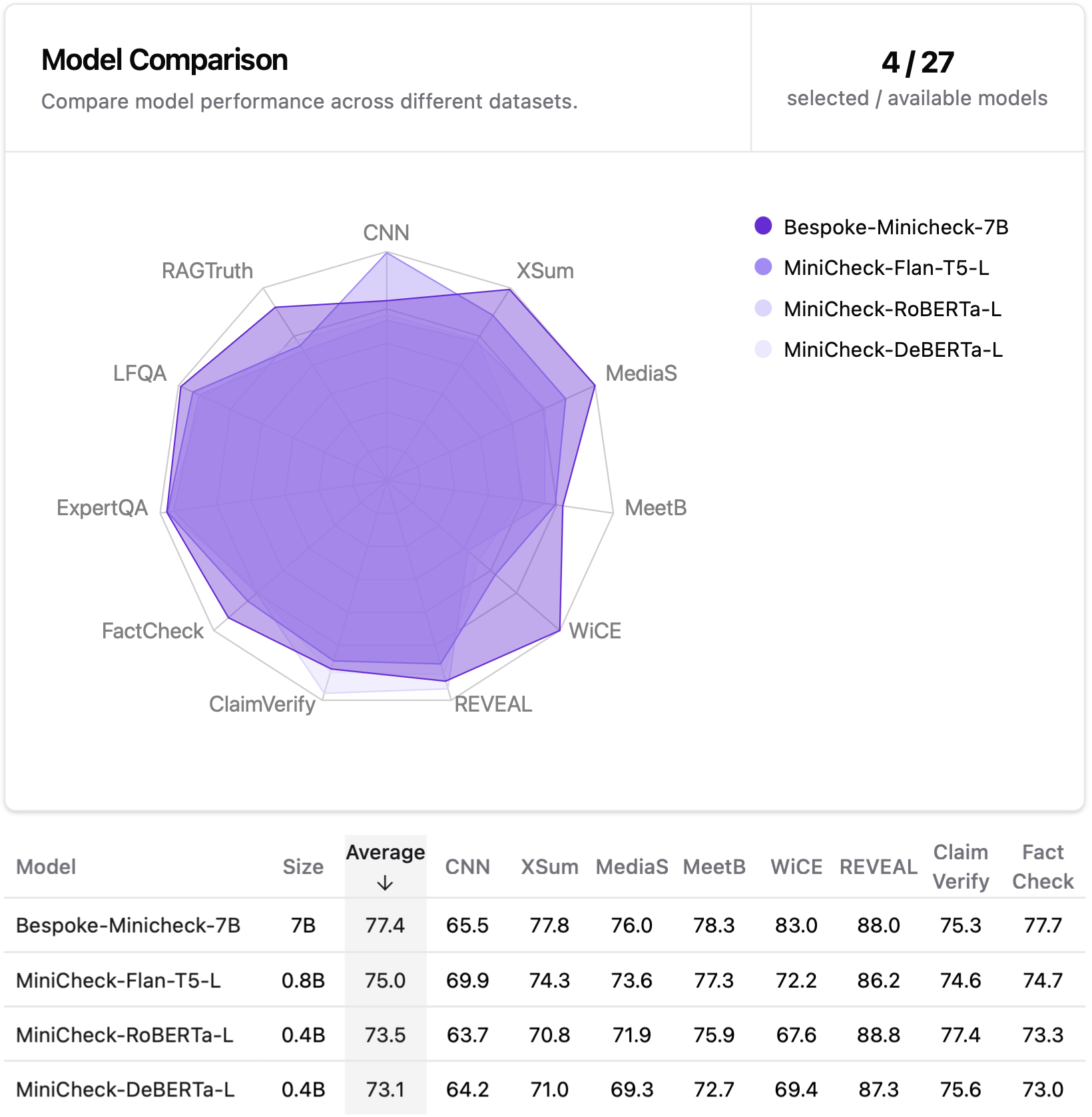
The performance of these models is evaluated on our new collected benchmark (unseen by our models during training), LLM-AggreFact, from 11 recent human annotated datasets on fact-checking and grounding LLM generations. MiniCheck-RoBERTa-Large outperform all exisiting specialized fact-checkers with a similar scale by a large margin. See full results in our work.
Note: We only evaluated the performance of our models on real claims -- without any human intervention in any format, such as injecting certain error types into model-generated claims. Those edited claims do not reflect LLMs' actual behaviors.
Please run the following command to install the MiniCheck package and all necessary dependencies.
pip install "minicheck @ git+https://github.com/Liyan06/MiniCheck.git@main"
from minicheck.minicheck import MiniCheck
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
doc = "A group of students gather in the school library to study for their upcoming final exams."
claim_1 = "The students are preparing for an examination."
claim_2 = "The students are on vacation."
# model_name can be one of ['roberta-large', 'deberta-v3-large', 'flan-t5-large', 'Bespoke-MiniCheck-7B']
scorer = MiniCheck(model_name='roberta-large', cache_dir='./ckpts')
pred_label, raw_prob, _, _ = scorer.score(docs=[doc, doc], claims=[claim_1, claim_2])
print(pred_label) # [1, 0]
print(raw_prob) # [0.9581979513168335, 0.031335990875959396]
import pandas as pd
from datasets import load_dataset
from minicheck.minicheck import MiniCheck
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
# load 29K test data
df = pd.DataFrame(load_dataset("lytang/LLM-AggreFact")['test'])
docs = df.doc.values
claims = df.claim.values
scorer = MiniCheck(model_name='roberta-large', cache_dir='./ckpts')
pred_label, raw_prob, _, _ = scorer.score(docs=docs, claims=claims) # ~ 800 docs/min, depending on hardware
To evalaute the result on the benchmark
from sklearn.metrics import balanced_accuracy_score
df['preds'] = pred_label
result_df = pd.DataFrame(columns=['Dataset', 'BAcc'])
for dataset in df.dataset.unique():
sub_df = df[df.dataset == dataset]
bacc = balanced_accuracy_score(sub_df.label, sub_df.preds) * 100
result_df.loc[len(result_df)] = [dataset, bacc]
result_df.loc[len(result_df)] = ['Average', result_df.BAcc.mean()]
result_df.round(1)
@InProceedings{tang-etal-2024-minicheck,
title = {MiniCheck: Efficient Fact-Checking of LLMs on Grounding Documents},
author = {Liyan Tang and Philippe Laban and Greg Durrett},
booktitle = {Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing},
year = {2024},
publisher = {Association for Computational Linguistics},
url = {https://arxiv.org/pdf/2404.10774}
}