
Model Card for Model ID
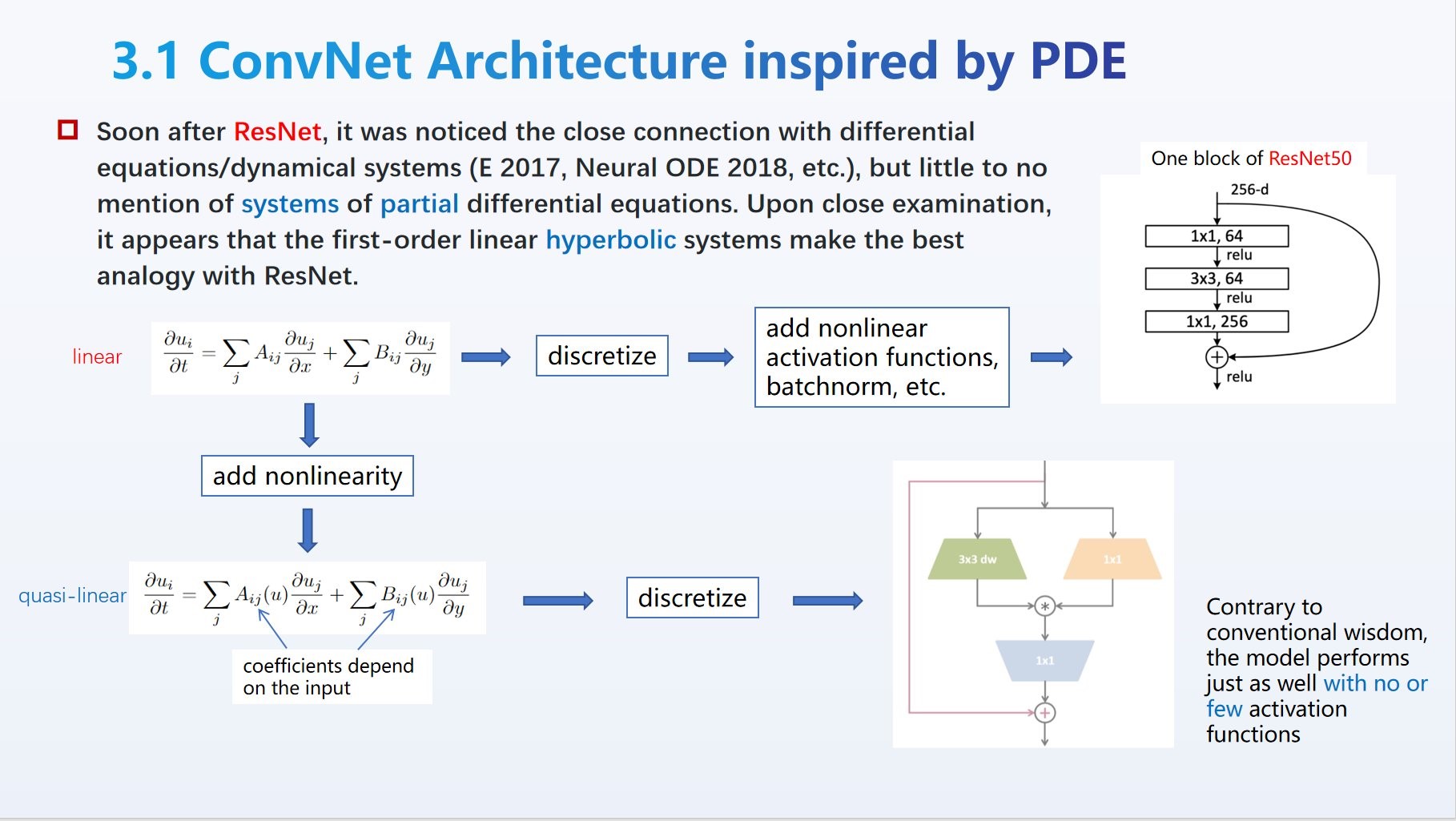
Based on a class of partial differential equations called quasi-linear hyperbolic systems [Liu et al, 2023], the QLNet breaks into uncharted waters of ConvNet model space marked by the use of (element-wise) multiplication in lieu of ReLU as the primary nonlinearity. It achieves comparable performance as ResNet50 on ImageNet-1k (acc=78.61), demonstrating that it has the same level of capacity/expressivity, and deserves further analysis and study (hyper-paremeter tuning, optimizer, etc.) by the academic community.
The overall architecture follows that of the origianl ConvNet (LeCun) and ResNet (He et al.), with the adoption of "depthwise convolution" as in MobileNet.
One notable feature is that the architecture (trained or not) admits a continuous symmetry in its parameters. Check out the notebook for a demo that makes a transformation on the weights while leaving the output unchanged.
FAQ (as the author imagines):
- Q: Who needs another ConvNet, when the SOTA for ImageNet-1k is now in the low 80s with models of comparable size?
- A: Aside from a lack of resources to perform extensive experiments, the real answer is that the new symmetry has the potential to be exploited (as a kind of symmetry-aware optimization). The "non-activation" nonlinearity is more "natural" (coordinate independence) as in many equations in mathematics and physics. Activation (of neurons or units) is but a legacy from the early days of models inspired by biological neural networks.
- Q: Multiplication is too simple, someone must have tried it?
- A: Perhaps. My guess is whoever tried it soon found the model fail to train with standard ReLU. Without the conviction in the underlying PDE perspective, maybe it wasn't pushed to its limit.
- Q: Is it not similar to attention in Transformer?
- A: Yes, indeed. It's natural to wonder if the activation functions in Transformer could be removed (or reduced) while still achieve comparable performance.
- Q: If the parameter space has a symmetry (beyond permutations), perhaps there's redundancy in the weights.
- A: The transformation in our demo indeed can be used to reduce the weights from the get-go. However, there are variants of the model that admit a much larger symmetry. It is also related to the phenomenon of "flat minima" found empirically in some conventional neural networks.
This modelcard aims to be a base template for new models. It has been generated using this raw template.
Model Details
Model Description
Instead of the bottleneck block of ResNet50 which consists of 1x1, 3x3, 1x1 in succession, this simplest version of QLNet does a 1x1, splits into two equal halves and multiplies them, then applies a 3x3 (depthwise), and a 1x1, all without activation functions except at the end of the block, where a "radial" activation function that we call hardball is applied.
class QLBlock(nn.Module):
...
def forward(self, x):
x0 = self.skip(x)
x = self.conv1(x) # 1x1
C = x.size(1) // 2
x = x[:, :C, :, :] * x[:, C:, :, :]
x = self.conv2(x) # 3x3 depthwise
x = self.conv3(x) # 1x1
x += x0
if self.act3 is not None:
x = self.act3(x)
return x
- Developed by: Yao Liu 刘杳
- Model type: Convolutional Neural Network (ConvNet)
- License: As academic work, it is free for all to use.
- Finetuned from model: N/A (trained from scratch)
Model Sources [optional]
- Repository: ConvNet from the PDE perspective
- Paper: A Novel ConvNet Architecture with a Continuous Symmetry
- Demo: [More Information Needed]
How to Get Started with the Model
Use the code below to get started with the model.
import torch, timm
from qlnet import QLNet
model = QLNet()
model.load_state_dict(torch.load('qlnet-10m.pth.tar'))
model.eval()
Training Details
Training and Testing Data
ImageNet-1k
[More Information Needed]
Training Procedure
We used the following training script in timm
python3 train.py ../datasets/imagenet/ --model resnet50 --num-classes 1000 --lr 0.1 --warmup-epochs 5 --epochs 240 --weight-decay 1e-4 --sched cosine --reprob 0.4 --recount 3 --remode pixel --aa rand-m7-mstd0.5-inc1 -b 192 -j 6 --amp --dist-bn reduce
Results
qlnet-10m: acc=78.608
- Downloads last month
- -