
Llama-2
Collection
The most recent LimaRP finetunes for Llama-2
•
2 items
•
Updated
This is an experimental version of LimaRP for Llama2 with an updated dataset (1800 training samples) and a 2-pass training procedure. The first pass includes unsupervised finetuning on about 6800 stories within 4k tokens length and the second pass is LimaRP with changes introducing more effective control on response length.
For more details about LimaRP, see the model page for the previously released version. Most details written there apply for this version as well.
It's recommended not to go overboard with low tail-free-sampling (TFS) values. From testing, decreasing it too much appears to easily yield rather repetitive responses. Suggested starting generation settings are:
Same as before. It uses the extended Alpaca format,
with ### Input: immediately preceding user inputs and ### Response: immediately preceding
model outputs. While Alpaca wasn't originally intended for multi-turn responses, in practice this
is not a problem; the format follows a pattern already used by other models.
### Instruction:
Character's Persona: {bot character description}
User's Persona: {user character description}
Scenario: {what happens in the story}
Play the role of Character. You must engage in a roleplaying chat with User below this line. Do not write dialogues and narration for User.
### Input:
User: {utterance}
### Response:
Character: {utterance}
### Input
User: {utterance}
### Response:
Character: {utterance}
(etc.)
You should:
User and Character with appropriate names.Inspired by the previously named "Roleplay" preset in SillyTavern, starting from this version of LimaRP it is possible to append a length modifier to the response instruction sequence, like this:
### Input
User: {utterance}
### Response: (length = medium)
Character: {utterance}
This has an immediately noticeable effect on bot responses. The available lengths are:
tiny, short, medium, long, huge, humongous, extreme, unlimited. The
recommended starting length is medium. Keep in mind that the AI may ramble
or impersonate the user with very long messages.
The length control effect is reproducible, but the messages will not necessarily follow lengths very precisely, rather follow certain ranges on average, as seen in this table with data from tests made with one reply at the beginning of the conversation:
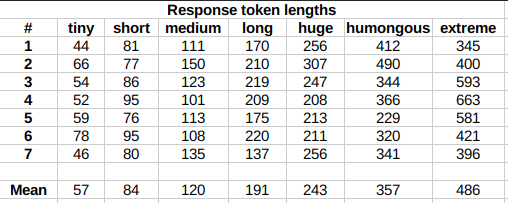
Response length control appears to work well also deep into the conversation.
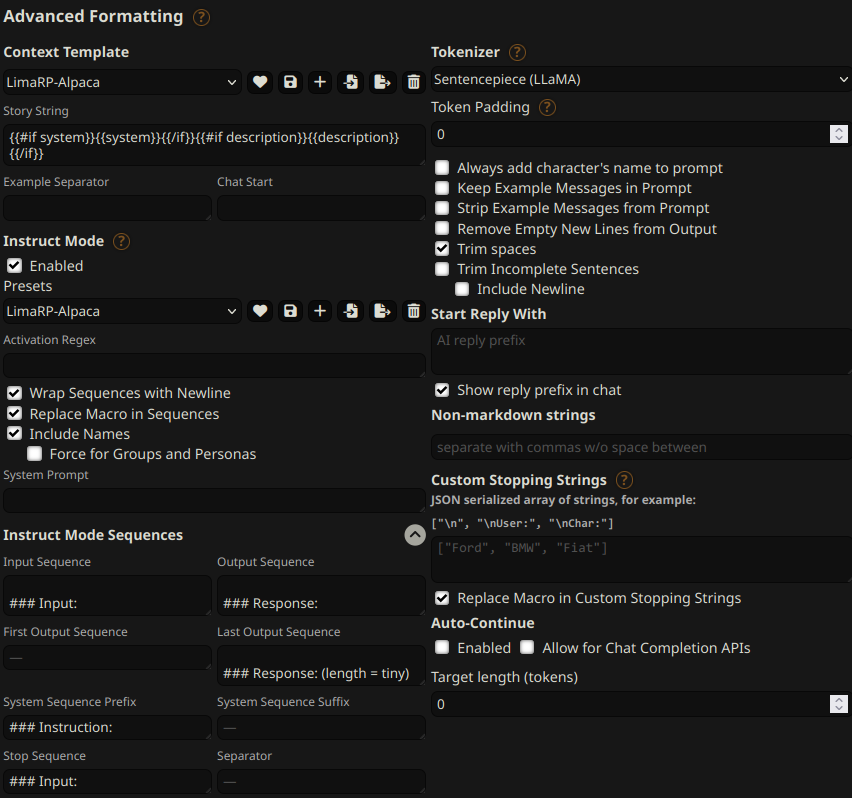
You can follow these instruction format settings in SillyTavern. Replace tiny with
your desired response length:
Axolotl was used for training on a 4x NVidia A40 GPU cluster.
The A40 GPU cluster has been graciously provided by Arc Compute.
The model has been trained as an 8-bit LoRA adapter, and it's so large because a LoRA rank of 256 was also used. The reasoning was that this might have helped the model internalize any newly acquired information, making the training process closer to a full finetune. It's suggested to merge the adapter to the base Llama2-7B model (or other Llama2-based models).
For the first pass these settings were used:
In the second pass, the lora_model_dir option was used to load and train the adapter
previously trained on a stories dataset. These settings were also changed:
Using 4 GPUs, the effective global batch size would have been 8.