Создание голосового ассистента
В этом разделе мы объединим три модели, с которыми уже имели практический опыт работы, и создадим полноценный голосовой помощник под названием Marvin 🤖. Подобно Amazon Alexa или Apple Siri, Marvin - это виртуальный голосовой помощник, который реагирует на определенное “слово активации”, затем слушает голосовой запрос и, наконец, отвечает на него.
Мы можем разбить конвейер голосового помощника на четыре этапа, каждый из которых требует отдельной модели:

1. Обнаружение слова активации
Голосовые помощники постоянно прослушивают аудиосигналы, поступающие через микрофон вашего устройства, но включаются в работу только после произнесения определенного ‘слова активации’ или ‘триггерного слова’.
Задачу обнаружения слов активации решает небольшая модель классификации звука на устройстве, которая значительно меньше и легче модели распознавания речи - часто всего несколько миллионов параметров по сравнению с несколькими сотнями миллионов для распознавания речи. Таким образом, она может постоянно работать на устройстве, не разряжая аккумулятор. Только при обнаружении “слова активации” запускается более крупная модель распознавания речи, после чего она снова отключается.
2. Транскрибирование речи
Следующий этап - транскрибация произнесенного запроса в текст. На практике передача аудиофайлов с локального устройства в облако происходит медленно из-за большого размера аудиофайлов, поэтому эффективнее транскрибировать их напрямую с помощью модели автоматического распознавания речи (ASR) на устройстве, а не использовать модель в облаке. Модель на устройстве может быть меньше и, следовательно, менее точной, чем модель, размещенная в облаке, но более высокая скорость инференса оправдывает себя, поскольку мы можем работать с распознаванием речи практически в реальном времени, транскрибируя произнесенные нами фразы по мере их произнесения.
Мы уже хорошо знакомы с процессом распознавания речи, так что это должно быть проще простого!
3. Запрос к языковой модели
Теперь, когда мы знаем, что спросил пользователь, нам нужно сгенерировать ответ! Лучшими моделями-кандидатами для решения этой задачи являются большие языковые модели (Large Language Models, LLM), поскольку они способны эффективно понять семантику текстового запроса и сгенерировать подходящий ответ.
Поскольку наш текстовый запрос невелик (всего несколько текстовых токенов), а языковые модели велики (многие миллиарды параметров), наиболее эффективным способом проведения инференса LLM является отправка текстового запроса с устройства на LLM, запущенную в облаке, генерация текстового ответа и возврат ответа обратно на устройство.
4. Синтез речи
Наконец, мы используем модель преобразования текста в речь (TTS) для синтеза текстового ответа в устную речь. Это делается на устройстве, но можно запустить модель TTS в облаке, генерируя аудио вывод и передавая его обратно на устройство.
Опять же, мы делали это уже несколько раз, так что процесс будет очень знакомым!
Обнаружение слова активации
Первым этапом работы голосового помощника является определение того, было ли произнесено слово активации, для решения этой задачи нам необходимо найти подходящую
предварительно обученную модель! Из раздела Предварительно обученные модели классификации звука вы помните, что
Speech Commands - это набор устных слов, предназначенный для оценки моделей классификации звука на 15+ простых
командных словах, таких как "вверх", "вниз", "да" и "нет", а также метка "тишина" для классификации отсутствия речи. Уделите минутку прослушиванию
образцов в программе просмотра наборов данных на Hub и заново познакомиться с набором данных Speech Commands: datasets viewer.
Мы можем взять модель классификации звука, предварительно обученную на наборе данных Speech Commands, и выбрать одно из этих простых командных слов в качестве слова активации. Если из 15 с лишним возможных командных слов модель предсказывает выбранное нами слово активации с наибольшей вероятностью, мы можем быть уверены, что оно было произнесено”.
Давайте зайдем в Hugging Face Hub и перейдем на вкладку “Models”: https://huggingface.co/models.
В результате будут отображены все модели на Hugging Face Hub, отсортированные по количеству загрузок за последние 30 дней:
С левой стороны вы заметите, что у нас есть ряд вкладок, которые мы можем выбрать для фильтрации моделей по задачам, библиотекам, набору данных и т.д. Прокрутите страницу вниз и выберите задачу ” Audio Classification ” из списка задач аудио:
Теперь нам представлено подмножество из 500+ моделей классификации звука на Hub. Для дальнейшего уточнения этой выборки мы можем отфильтровать модели по датасету. Перейдите на вкладку “Datasets” и в строке поиска введите “speech_commands”. При вводе текста под вкладкой поиска появится выделение `speech_commands. Нажав на эту кнопку, можно отфильтровать все модели классификации звука на те, которые были дообучены на датасете Speech Commands:
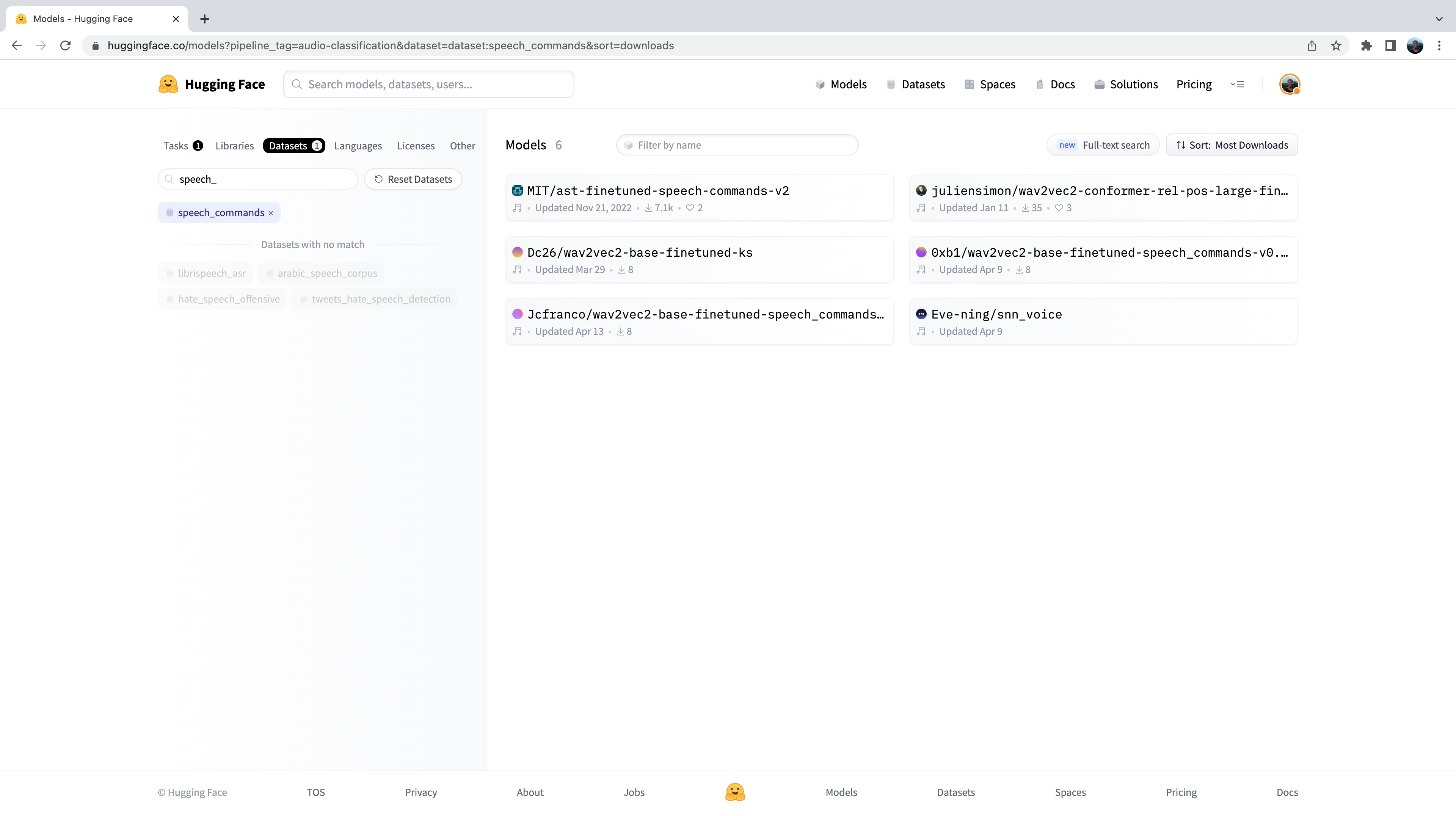
Отлично! Мы видим, что для данного датасета и задачи нам доступны шесть предварительно обученных моделей (хотя, если вы читаете этот материал позднее, могут быть добавлены новые модели!) Первую из этих моделей вы узнаете как Audio Spectrogram Transformer checkpoint которую мы использовали в примере 4-го раздела. Мы снова будем использовать эту контрольную точку для задачи определения слова активации.
Перейдем к загрузке контрольной точки с помощью класса pipeline:
from transformers import pipeline
import torch
device = "cuda:0" if torch.cuda.is_available() else "cpu"
classifier = pipeline(
"audio-classification", model="MIT/ast-finetuned-speech-commands-v2", device=device
)Мы можем проверить, на каких метках обучалась модель, проверив атрибут id2label в конфигурации модели:
classifier.model.config.id2label
Отлично! Мы видим, что модель была обучена на 35 метках классов, включая некоторые простые командные слова, которые мы описали выше, а
также некоторые конкретные объекты, такие как "bed", "house" и "cat". Мы видим, что в этих метках класса есть одно имя:
id 27 соответствует метке “marvin ”:
classifier.model.config.id2label[27]'marvin'Отлично! Мы можем использовать это имя в качестве слова активации для нашего голосового помощника, подобно тому, как используется
“Alexa” для Amazon Alexa или “Hey Siri” для Apple Siri. Если из всех возможных меток модель с наибольшей вероятностью предсказывает
"marvin", мы можем быть уверены, что выбранное нами слово активации было произнесено.
Теперь нам необходимо определить функцию, которая будет постоянно прослушивать микрофонный вход нашего устройства и непрерывно передавать
звук в модель классификации для проведения инференса. Для этого мы воспользуемся удобной вспомогательной функцией, входящей
в состав 🤗 Transformers, под названием ffmpeg_microphone_live.
Эта функция направляет в модель для классификации небольшие фрагменты звука заданной длины chunk_length_s. Для обеспечения плавных
границ между фрагментами звука мы используем скользящее окно с шагом chunk_length_s / 6. Чтобы не ждать, пока запишется весь первый фрагмент,
прежде чем приступить к инференсу, мы также определяем минимальную продолжительность по времени аудио входа stream_chunk_s,
который передается в модель до достижения времени chunk_length_s.
Функция ffmpeg_microphone_live возвращает объект generator, создающий последовательность аудиофрагментов, каждый из которых может быть
передан модели классификации для предсказания. Мы можем передать этот генератор непосредственно в pipeline, который, в свою очередь,
возвращает на выходе последовательность прогнозов, по одному для каждого фрагмента входного аудиосигнала. Мы можем просмотреть вероятности
меток классов для каждого фрагмента и остановить цикл обнаружения слов активации, когда обнаружим, что слово активации было произнесено.
Для классификации произнесения слова активации мы будем использовать очень простой критерий: если метка класса с наибольшей вероятностью является
словом активации и эта вероятность превышает порог prob_threshold, то мы объявляем, что слово активации было произнесено. Использование порога
вероятности для управления классификатором таким образом гарантирует, что слово активации не будет ошибочно предсказано, если аудиосигнал является
шумом, что обычно происходит, когда модель очень неопределенна и все вероятности меток классов низки. Возможно, вы захотите настроить этот порог
вероятности или использовать более сложные средства для принятия решения о слове активации с помощью метрики entropy
(или метрики, основанной на неопределенности).
from transformers.pipelines.audio_utils import ffmpeg_microphone_live
def launch_fn(
wake_word="marvin",
prob_threshold=0.5,
chunk_length_s=2.0,
stream_chunk_s=0.25,
debug=False,
):
if wake_word not in classifier.model.config.label2id.keys():
raise ValueError(
f"Wake word {wake_word} not in set of valid class labels, pick a wake word in the set {classifier.model.config.label2id.keys()}."
)
sampling_rate = classifier.feature_extractor.sampling_rate
mic = ffmpeg_microphone_live(
sampling_rate=sampling_rate,
chunk_length_s=chunk_length_s,
stream_chunk_s=stream_chunk_s,
)
print("Listening for wake word...")
for prediction in classifier(mic):
prediction = prediction[0]
if debug:
print(prediction)
if prediction["label"] == wake_word:
if prediction["score"] > prob_threshold:
return TrueДавайте опробуем эту функцию и посмотрим, как она работает! Установим флаг debug=True, чтобы выводить прогнозы для каждого фрагмента звука. Пусть модель
поработает несколько секунд, чтобы увидеть, какие предсказания она делает при отсутствии речевого ввода, затем четко произнесем слово активации "marvin"
и увидим, как предсказание метки класса для "marvin" подскочит почти до 1:
launch_fn(debug=True)Listening for wake word...
{'score': 0.055326107889413834, 'label': 'one'}
{'score': 0.05999856814742088, 'label': 'off'}
{'score': 0.1282748430967331, 'label': 'five'}
{'score': 0.07310110330581665, 'label': 'follow'}
{'score': 0.06634809821844101, 'label': 'follow'}
{'score': 0.05992642417550087, 'label': 'tree'}
{'score': 0.05992642417550087, 'label': 'tree'}
{'score': 0.999913215637207, 'label': 'marvin'}Потрясающе! Как мы и ожидали, в течение первых нескольких секунд модель генерирует “мусорные” предсказания. Речевой ввод отсутствует, поэтому модель
делает прогнозы, близкие к случайным, но с очень низкой вероятностью. Как только мы произносим слово активации, модель прогнозирует "marvin"
с вероятностью, близкой к 1, и завершает цикл, сигнализируя о том, что слово активации обнаружено и система ASR должна быть активирована!
Транскрибирование речи
И снова мы будем использовать модель Whisper для нашей системы транскрипции речи. В частности, мы загрузим контрольную точку Whisper Base English, поскольку она достаточно мала, чтобы обеспечить хорошую скорость инференса при приемлемой точности транскрипции. Мы будем использовать трюк, позволяющий получить транскрипцию практически в реальном времени за счет умного подхода к передаче аудиосигнала в модель. Как и прежде, можно использовать любую контрольную точку распознавания речи на Hub, включая Wav2Vec2, MMS ASR или другие контрольные точки Whisper:
transcriber = pipeline(
"automatic-speech-recognition", model="openai/whisper-base.en", device=device
)"openai/whisper-small.en".Теперь мы можем определить функцию для записи сигнала с микрофона и транскрипции соответствующего текста. С помощью вспомогательной
функции ffmpeg_microphone_live мы можем управлять тем, насколько в реальном времени работает наша модель распознавания речи.
Использование меньшего stream_chunk_s позволяет распознавать речь в реальном времени, поскольку мы делим входной звук на более
мелкие фрагменты и транскрибируем их на лету. Однако за счет этого снижается точность, поскольку модель получает меньше контекста для инференса.
В процессе транскрибации речи нам также необходимо знать, когда пользователь прекращает говорить, чтобы можно было прервать запись.
Для простоты мы будем прекращать запись с микрофона после первого chunk_length_s (по умолчанию это 5 секунд), но вы можете
поэкспериментировать с использованием модели voice activity detection (VAD),
чтобы предсказать, когда пользователь прекращает говорить.
import sys
def transcribe(chunk_length_s=5.0, stream_chunk_s=1.0):
sampling_rate = transcriber.feature_extractor.sampling_rate
mic = ffmpeg_microphone_live(
sampling_rate=sampling_rate,
chunk_length_s=chunk_length_s,
stream_chunk_s=stream_chunk_s,
)
print("Start speaking...")
for item in transcriber(mic, generate_kwargs={"max_new_tokens": 128}):
sys.stdout.write("\033[K")
print(item["text"], end="\r")
if not item["partial"][0]:
break
return item["text"]Давайте попробуем и посмотрим, что у нас получится! Как только микрофон заработает, начинайте говорить и наблюдайте, как ваша транскрипция появляется в полуреальном времени:
transcribe()
Start speaking... Hey, this is a test with the whisper model.
Отлично! Вы можете регулировать максимальную длину звука chunk_length_s в зависимости от того, насколько быстро или медленно
вы говорите (увеличить, если вам показалось, что вы не успели договорить, уменьшить, если вы были вынуждены ждать в конце), и
stream_chunk_s для фактора реального времени. Просто передайте их в качестве аргументов функции transcribe.
Запрос к языковой модели
Теперь, когда мы получили транскрибацию нашего запроса, мы хотим сгенерировать осмысленный ответ. Для этого мы воспользуемся LLM, размещенным в облаке. В частности, мы выберем LLM на Hugging Face Hub и воспользуемся Inference API, чтобы легко передать запрос модели.
Для начала перейдём на хаб Hugging Face. Для выбора нашей модели LLM мы воспользуемся 🤗 Open LLM Leaderboard пространством, которое ранжирует модели LLM по производительности в четырех задачах генерации. Мы будем искать по “instruct”, чтобы отфильтровать модели, которые были дообучены на инструкциях, так как они должны лучше работать для нашей задачи передачи запроса (querying task):

Мы будем использовать контрольную точку tiiuae/falcon-7b-instruct от TII - LM с декодером только на 7B параметров, которая дообучена на смеси датасетов чатов и инструкций. Вы можете использовать любую LLM на Hugging Face Hub, у которой активирован параметр “Hosted inference API”, просто обратите внимание на виджет в правой части карточки модели:

Inference API позволяет отправить HTTP-запрос с локальной машины на LLM, размещенную на Hub, и возвращает ответ в виде файла json.
Все, что нам нужно, - это указать наш токен Hugging Face Hub (который мы получаем непосредственно из нашей папки Hugging Face Hub)
и идентификатор модели LLM, которой мы хотим передать запрос:
from huggingface_hub import HfFolder
import requests
def query(text, model_id="tiiuae/falcon-7b-instruct"):
api_url = f"https://api-inference.huggingface.co/models/{model_id}"
headers = {"Authorization": f"Bearer {HfFolder().get_token()}"}
payload = {"inputs": text}
print(f"Querying...: {text}")
response = requests.post(api_url, headers=headers, json=payload)
return response.json()[0]["generated_text"][len(text) + 1 :]Давайте попробуем это сделать с помощью тестового ввода!
query("What does Hugging Face do?")'Hugging Face is a company that provides natural language processing and machine learning tools for developers. They'Вы можете заметить, насколько быстро выполняется инференс с помощью Inference API - нам нужно отправить лишь небольшое количество текстовых токенов с нашей локальной машины на размещенную на сервере модель, поэтому затраты на связь очень малы. LLM размещается на GPU-ускорителях, поэтому инференс выполняется очень быстро. Наконец, сгенерированный ответ передается обратно от модели на нашу локальную машину, что также не требует больших коммуникационных затрат.
Синтез речи
Теперь мы готовы к получению окончательного речевого вывода! В очередной раз мы будем использовать модель Microsoft SpeechT5 TTS для TTS на английском языке, но вы можете использовать любую модель TTS по своему усмотрению. Давайте загрузим процессор и модель:
from transformers import SpeechT5Processor, SpeechT5ForTextToSpeech, SpeechT5HifiGan
processor = SpeechT5Processor.from_pretrained("microsoft/speecht5_tts")
model = SpeechT5ForTextToSpeech.from_pretrained("microsoft/speecht5_tts").to(device)
vocoder = SpeechT5HifiGan.from_pretrained("microsoft/speecht5_hifigan").to(device)А также эбеддинги диктора:
from datasets import load_dataset
embeddings_dataset = load_dataset("Matthijs/cmu-arctic-xvectors", split="validation")
speaker_embeddings = torch.tensor(embeddings_dataset[7306]["xvector"]).unsqueeze(0)Мы повторно используем функцию synthesise, которую мы определили в предыдущей главе [Перевод речи в речь] (speech-to-speech):
def synthesise(text):
inputs = processor(text=text, return_tensors="pt")
speech = model.generate_speech(
inputs["input_ids"].to(device), speaker_embeddings.to(device), vocoder=vocoder
)
return speech.cpu()Давайте быстро проверим, что все работает так, как и ожидается:
from IPython.display import Audio
audio = synthesise(
"Hugging Face is a company that provides natural language processing and machine learning tools for developers."
)
Audio(audio, rate=16000)Отличная работа 👍
Марвин 🤖
Теперь, когда мы определили функцию для каждого из четырех этапов конвейера голосового помощника, осталось только собрать их вместе,
чтобы получить готовый голосовой помощник. Мы просто объединим все четыре этапа, начиная с обнаружения слов активации (launch_fn),
транскрипции речи, передачи запроса LLM и заканчивая синтезом речи.
launch_fn()
transcription = transcribe()
response = query(transcription)
audio = synthesise(response)
Audio(audio, rate=16000, autoplay=True)Попробуйте сделать это с помощью нескольких запросов! Вот несколько примеров для начала:
- Какая самая жаркая страна в мире?
- Как работают модели-трансформеры?
- Знаешь ли ты испанский язык?
Вот и все, у нас есть готовый голосовой помощник, созданный с использованием 🤗 аудио инструментов, которые вы изучили в этом курсе, с добавлением в конце волшебства LLM. Есть несколько расширений, которые мы могли бы сделать для улучшения голосового помощника. Во-первых, модель классификации звука классифицирует 35 различных меток. Мы могли бы использовать более компактную и легкую модель бинарной классификации, которая прогнозирует только то, было ли произнесено слово активации или нет. Во-вторых, мы заранее загружаем все модели и держим их запущенными на нашем устройстве. Если бы мы хотели сэкономить электроэнергию, то загружали бы каждую модель только в тот момент, когда она необходима, а затем выгружали бы ее. В-третьих, в нашей функции транскрибации отсутствует модель определения активности голоса, транскрибация осуществляется в течение фиксированного времени, которое в одних случаях слишком длинное, а в других - слишком короткое.
Обобщаем всё 🪄
До сих пор мы видели, как можно генерировать речевой вывод с помощью нашего голосового помощника Marvin. В заключение мы продемонстрируем, как можно обобщить этот речевой вывод на текст, аудио и изображение.
Для построения нашего помощника мы будем использовать Transformers Agents. Transformers Agents предоставляет API для работы с естественным языком поверх библиотек 🤗 Transformers и Diffusers, интерпретирует входной сигнал на естественном языке с помощью LLM с тщательно продуманными подсказками и использует набор курируемых инструментов для обеспечения мультимодального вывода.
Давайте перейдем к инстанцированию агента. Для агентов-трансформеров существует три LLM, две из которых с открытым исходным кодом и бесплатно доступны на Hugging Face Hub. Третья - модель от OpenAI, требующая ключа OpenAI API. В данном примере мы будем использовать бесплатную модель Bigcode Starcoder, но вы также можете попробовать любую из других доступных LLM:
from transformers import HfAgent
agent = HfAgent(
url_endpoint="https://api-inference.huggingface.co/models/bigcode/starcoder"
)Чтобы воспользоваться агентом, достаточно вызвать agent.run с нашим текстовым приглашением. В качестве примера мы попросим
его сгенерировать изображение кота 🐈 (которое, надеюсь, выглядит немного лучше, чем этот эмоджи):
agent.run("Generate an image of a cat")
Все просто! Агент интерпретировал наш запрос и, используя Stable Diffusion под капотом, сгенерировал изображение, при этом нам не пришлось беспокоиться о загрузке модели, написании функции или выполнении кода.
Теперь мы можем заменить функцию передачи запроса LLM и шаг синтеза текста нашим агентом Transformers Agent в голосовом помощнике, поскольку агент будет выполнять оба этих действия за нас:
launch_fn() transcription = transcribe() agent.run(transcription)
Попробуйте произнести тот же запрос ” Generate an image of a cat” и посмотрите, как справится система. Если задать Агенту простой запрос “вопрос/ответ”, он ответит текстовым ответом. Можно побудить его генерировать мультимодальный вывод, попросив вернуть изображение или речь. Например, вы можете попросить его: “Generate an image of a cat, caption it, and speak the caption”.
Хотя агент является более гибким, чем наш первый итерационный ассистент Marvin 🤖, обобщение задачи голосового помощника таким образом может привести к снижению производительности при выполнении стандартных запросов к голосовому помощнику. Для восстановления производительности можно попробовать использовать более производительную контрольную точку LLM, например, от OpenAI, или определить набор custom tools, специфичный для задачи голосового помощника.
< > Update on GitHub