Audio Course documentation
Предварительно обученные модели и наборы данных для классификации звука
Предварительно обученные модели и наборы данных для классификации звука
Hugging Face Hub содержит более 500 предварительно обученных моделей для классификации звука. В этом разделе мы рассмотрим
несколько наиболее распространенных задач классификации звука и предложим для каждой из них подходящие предварительно обученные модели.
Использование pipeline() позволяет легко переключаться между моделями и задачами - как только вы узнаете, как использовать
pipeline() для одной модели, вы сможете использовать его для любой модели на Hugging Face Hub без изменений кода! Это делает эксперименты с
pipeline() чрезвычайно быстрыми, позволяя быстро выбрать наилучшую предварительно обученную модель для ваших нужд.
Прежде чем перейти к рассмотрению различных задач классификации звука, давайте кратко перечислим обычно используемые архитектуры трансформеров. Стандартная архитектура классификации звука обусловлена характером задачи; мы хотим преобразовать последовательность входных аудиосигналов (т.е. наш входной массив аудиосигналов) в предсказание метки одного из классов. Модели, архитектура которых состоит только из кодировщика, сначала преобразуют входную звуковую последовательность в последовательность представлений скрытых состояний, пропуская входные сигналы через блок трансформации. Последовательность представлений скрытых состояний преобразуется в выходную метку класса путем взятия среднего значения по скрытым состояниям и пропускания полученного вектора через слой линейной классификации. Поэтому для классификации аудиосигналов предпочтение отдается моделям, архитектура которых состоит только из кодировщика.
Модели, архитектура которых состоит только из декодировщика излишне усложняют задачу, поскольку предполагают что выходы могут быть в том числе и последовательностью предсказаний (а не одним предсказанием метки класса), и поэтому генерируют несколько выходов. Поэтому они имеют более низкую скорость вывода и, как правило, не используются. По этой же причине модели кодеровщик-декодировщик в значительной степени не рассматриваются. Такой выбор архитектуры аналогичен выбору в NLP, где для задач классификации последовательностей предпочтение отдается только моделям-кодировщикам, таким как BERT, а для задач генерации последовательностей - только моделям-декодировщикам, таким как GPT.
Теперь, когда мы рассказали о стандартной архитектуре трансформеров для классификации звука, перейдем к рассмотрению различных подмножеств классификации звука и наиболее популярных моделей!
🤗 Установка библиотеки Transformers
На момент написания статьи последние обновления, необходимые для работы конвейера классификации звука, находятся только в main ветке
репозитория 🤗 Transformers, а не в последней версии PyPi. Чтобы убедиться в наличии этих обновлений локально, мы установим Transformers
из ветки main следующей командой:
pip install git+https://github.com/huggingface/transformersПоиск ключевых слов
Поиск ключевых слов (Keyword Spotting, KWS) - это задача идентификации ключевого слова в произносимой речи. Набор возможных ключевых слов формирует набор прогнозируемых меток классов. Поэтому для использования предварительно обученной модели выделения ключевых слов необходимо убедиться, что ваши ключевые слова совпадают с теми, на которых модель была предварительно обучена. Ниже мы представим два набора данных и модели для выявления ключевых слов.
Minds-14
Воспользуемся тем же набором данных MINDS-14, который вы исследовали в предыдущем разделе.
Если вы помните, MINDS-14 содержит записи людей, задающих вопросы системе дистанционного банковского обслуживания на нескольких языках и
диалектах, и для каждой записи имеет значение intent_class. Мы можем классифицировать записи по намерению звонящего.
from datasets import load_dataset
minds = load_dataset("PolyAI/minds14", name="en-AU", split="train")Загрузим контрольную точку "anton-l/xtreme_s_xlsr_300m_minds14", которая
представляет собой XLS-R-модель, дообученную на MINDS-14 в течение примерно 50 эпох. На оценочной выборке набора MINDS-14 она достигает 90%
по метрике accuracy по всем языкам.
from transformers import pipeline
classifier = pipeline(
"audio-classification",
model="anton-l/xtreme_s_xlsr_300m_minds14",
)Наконец, мы можем передать сэмпл в конвейер классификации, чтобы сделать предсказание:
classifier(minds[0]["path"])Output:
[
{"score": 0.9631525278091431, "label": "pay_bill"},
{"score": 0.02819698303937912, "label": "freeze"},
{"score": 0.0032787492964416742, "label": "card_issues"},
{"score": 0.0019414445850998163, "label": "abroad"},
{"score": 0.0008378693601116538, "label": "high_value_payment"},
]Отлично! Мы определили, что целью звонка была оплата счета, с вероятностью 96%. Можно представить, что подобная система выявления ключевых слов используется в качестве первого этапа автоматизированного центра обработки вызовов (call-центр), где мы хотим классифицировать входящие звонки клиентов в зависимости от их запроса и предложить им соответствующую контекстную поддержку.
Speech Commands
Speech Commands - это набор устных слов, предназначенный для оценки моделей классификации звука на простых командных словах. Набор данных состоит из 15 классов ключевых слов, класса молчания и неизвестного класса, включающего ложные срабатывания. 15 ключевых слов - это отдельные слова, которые обычно используются в настройках устройства для управления основными задачами или запуска других процессов.
Аналогичная модель постоянно работает в вашем мобильном телефоне. Здесь вместо отдельных командных слов используются “слова пробуждения”, характерные для конкретного устройства, например “Привет, Google” или “Привет, Siri”. Когда модель классификации звука обнаруживает эти слова, она заставляет телефон начать прослушивание микрофона и транскрибировать вашу речь с помощью модели распознавания речи.
Модель классификации звука гораздо меньше и легче, чем модель распознавания речи, зачастую в ней всего несколько миллионов параметров по сравнению с несколькими сотнями миллионов параметров в модели для распознавания речи. Таким образом, она может непрерывно работать на вашем устройстве, не разряжая аккумулятор! Более крупная модель распознавания речи запускается только при обнаружении слова-пробуждения, после чего она снова отключается. В следующем разделе мы рассмотрим модели трансформеров для распознавания речи, так что к концу курса у вас должны быть все необходимые инструменты для создания собственного голосового помощника!
Как и в случае с любым набором данных на Hugging Face Hub, мы можем получить представление о том, какие аудиоданные в нем присутствуют, не скачивая и не сохраняя их в памяти компьютера. Перейдя к карточке набора данных Speech Commands’ dataset на Hugging Face Hub, мы можем воспользоваться средством просмотра набора данных (Dataset Viewer), чтобы пролистать первые 100 образцов набора, прослушать аудиофайлы и проверить любые другие метаданные:
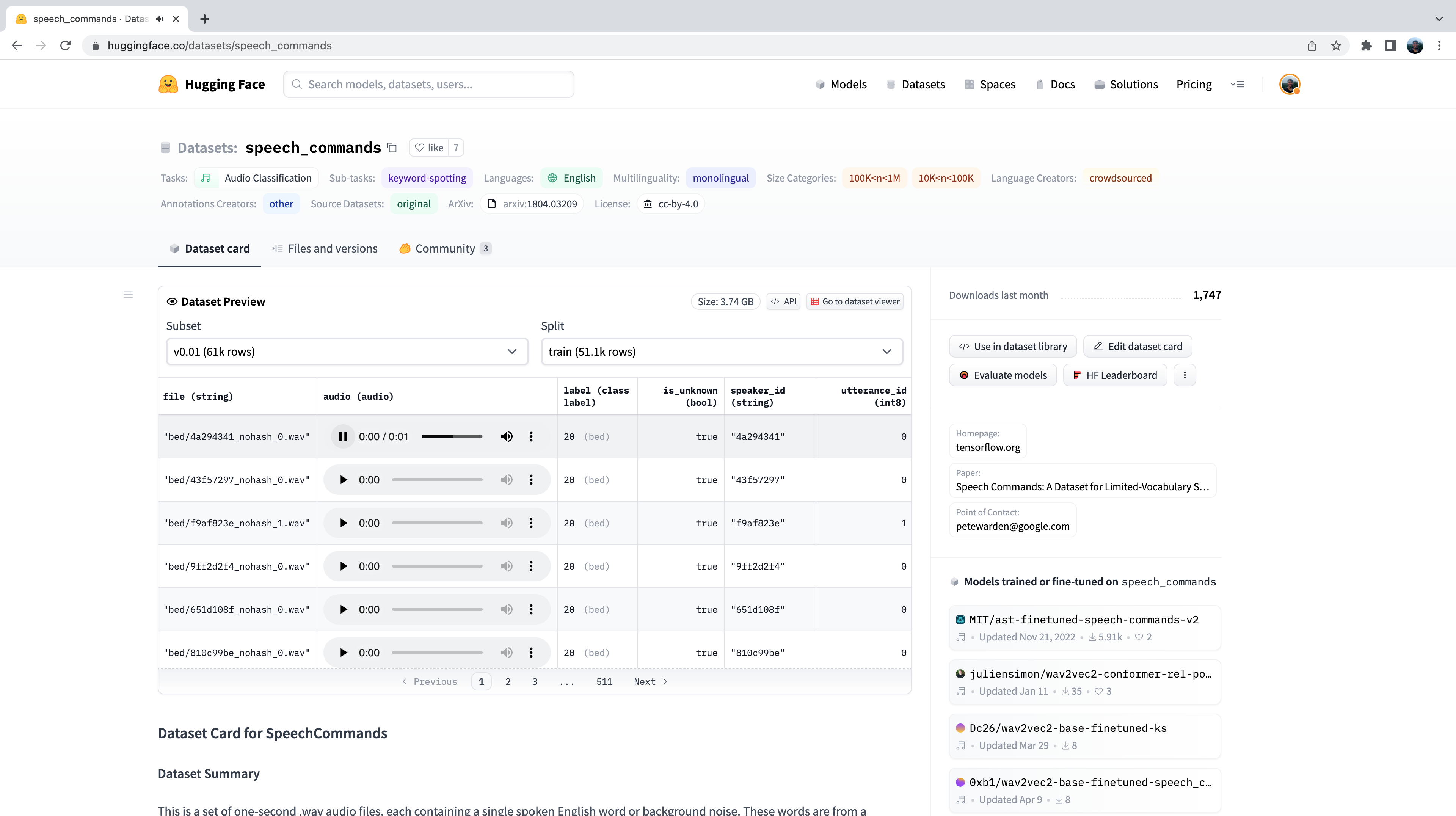
Предварительный просмотр данных - это отличный способ ознакомиться с наборами аудиоданных, прежде чем приступить к их использованию. Вы можете выбрать любой набор данных на Hugging Face Hub, пролистать примеры и прослушать аудиозаписи для различных подмножеств и разбиений, чтобы понять, подходит ли этот набор данных для ваших нужд. Выбрав набор данных, несложно загрузить данные, чтобы начать их использовать.
Давайте сделаем именно это и загрузим образец набора данных Speech Commands в потоковом режиме:
speech_commands = load_dataset(
"speech_commands", "v0.02", split="validation", streaming=True
)
sample = next(iter(speech_commands))Загрузим официальную контрольную точку Audio Spectrogram Transformer,
прошедшую дообучение на наборе данных Speech Commands, в пространстве имен "MIT/ast-finetuned-speech-commands-v2":
classifier = pipeline(
"audio-classification", model="MIT/ast-finetuned-speech-commands-v2"
)
classifier(sample["audio"].copy())Output:
[{'score': 0.9999892711639404, 'label': 'backward'},
{'score': 1.7504888774055871e-06, 'label': 'happy'},
{'score': 6.703040185129794e-07, 'label': 'follow'},
{'score': 5.805884484288981e-07, 'label': 'stop'},
{'score': 5.614546694232558e-07, 'label': 'up'}]Класс! Похоже, что пример с высокой вероятностью содержит слово “назад”. Мы можем прослушать пример и убедиться что это действительно так:
from IPython.display import Audio
Audio(sample["audio"]["array"], rate=sample["audio"]["sampling_rate"])Теперь вам, возможно, интересно, как мы выбрали эти предварительно обученные модели, чтобы показать их на этих примерах классификации звука. На самом деле, найти предварительно обученные модели для вашего набора данных и задачи очень просто! Первое, что нам нужно сделать, это зайти в Hugging Face Hub и перейти на вкладку “Models” (Модели): https://huggingface.co/models
В результате будут отображены все модели на Hugging Face Hub, отсортированные по количеству загрузок за последние 30 дней:
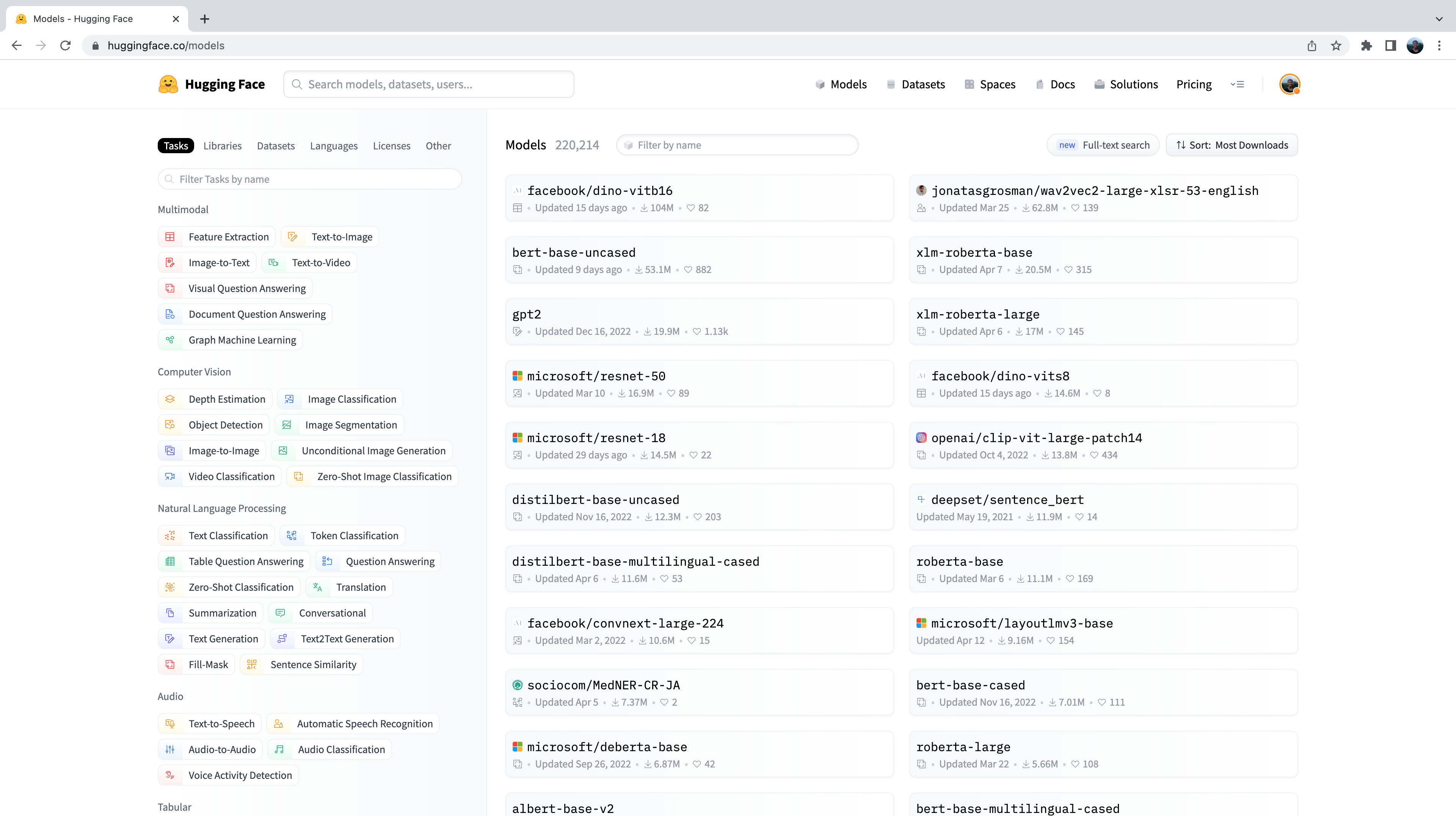
С левой стороны можно заметить ряд вкладок, на которых можно отфильтровать модели по задачам, библиотекам, наборам данных и т.д. Прокрутите страницу вниз и выберите задачу “Audio Classification” (Классификация аудио) из списка задач аудио:
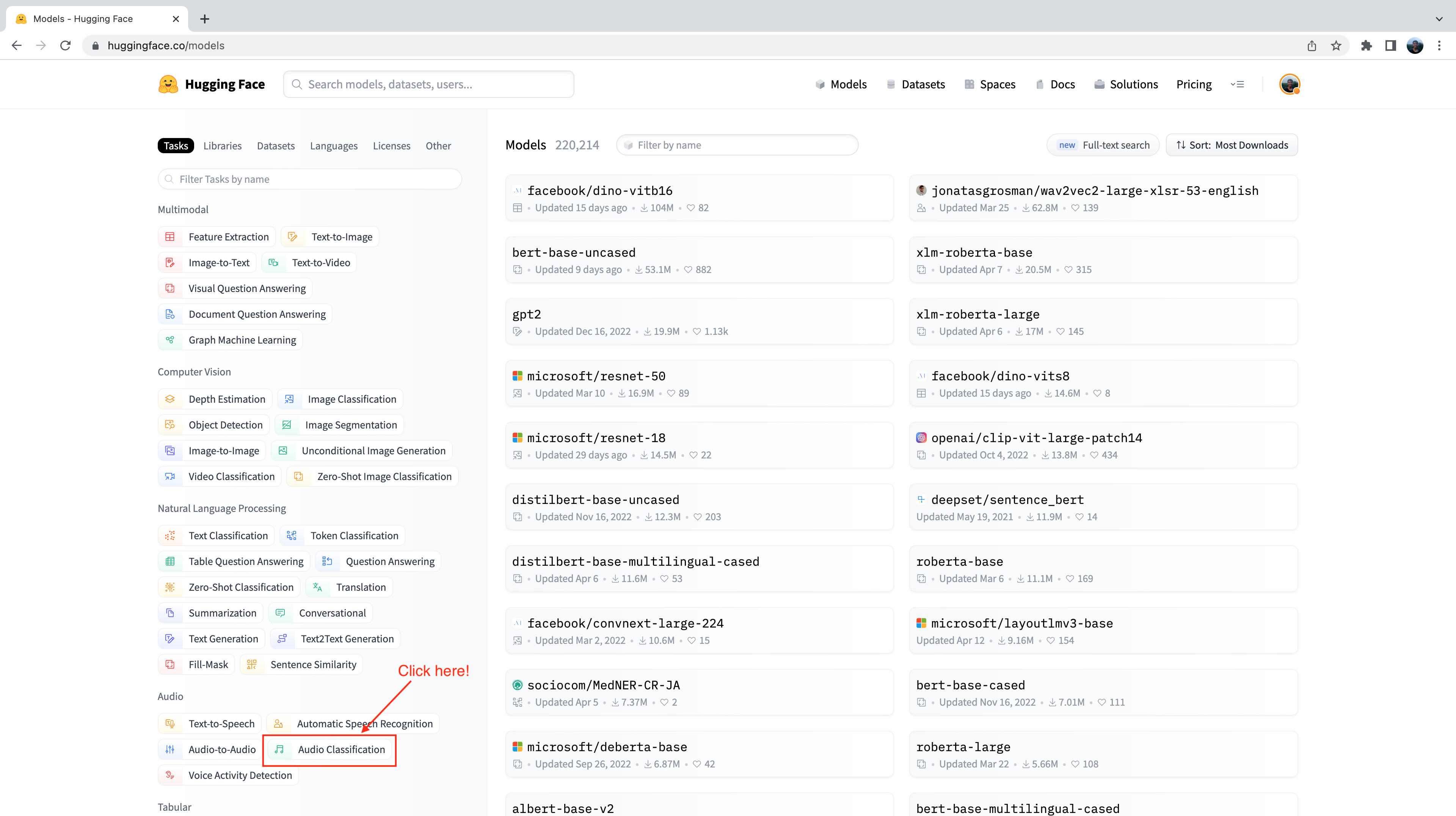
Теперь нам представлено подмножество из 500+ моделей классификации звука на хабе. Для дальнейшего уточнения этого отбора мы можем отфильтровать
модели по набору данных. Перейдите на вкладку “Datasets” и в строке поиска введите “speech_commands”. Когда вы начнете вводить текст, под
вкладкой поиска появится выбор для speech_commands. Нажав на эту кнопку, вы можете отфильтровать все модели классификации звука от тех,
которые были настроены на наборе данных Speech Commands:
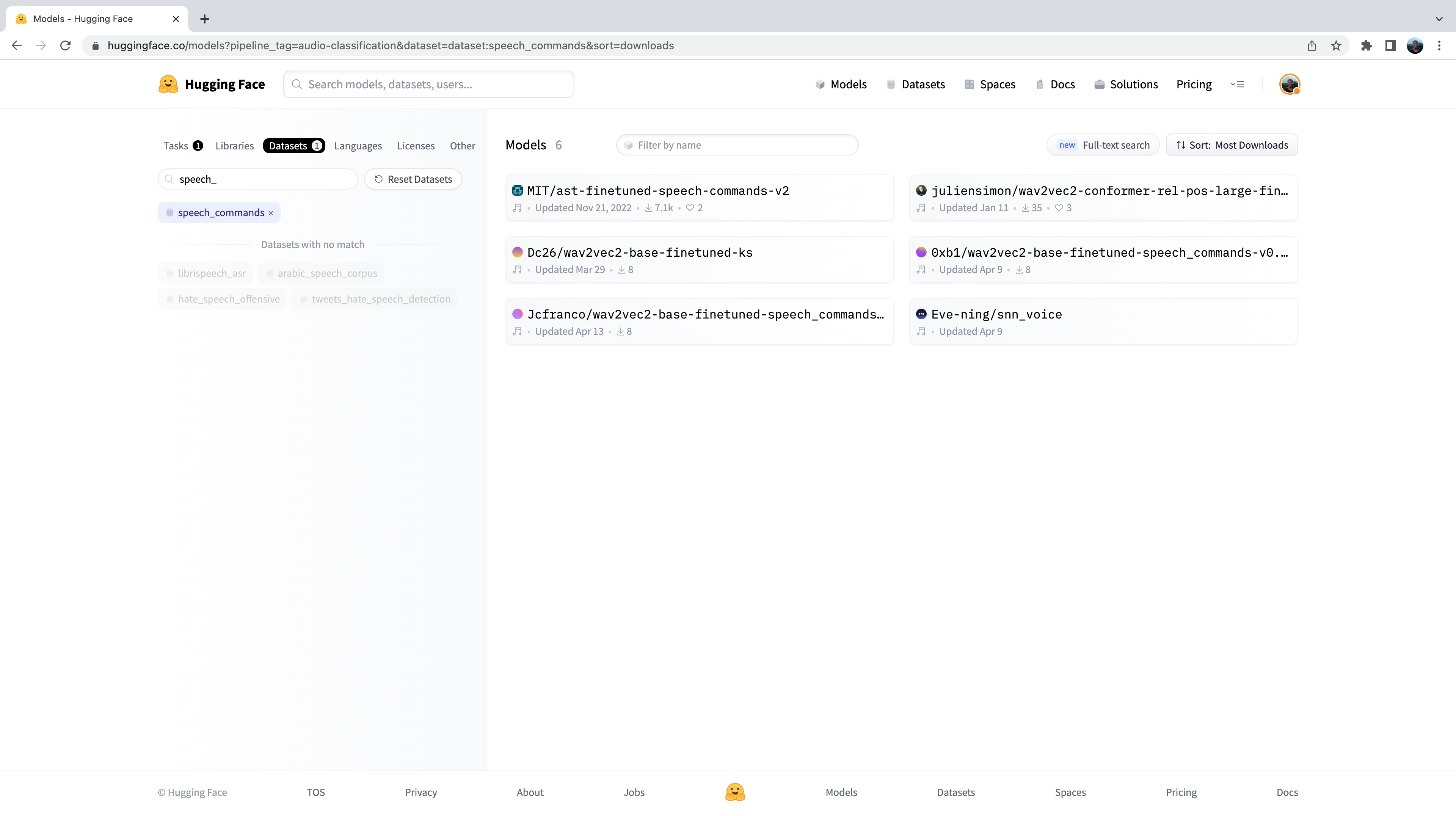
Отлично! Мы видим, что для данного набора данных и задачи нам доступны 6 предварительно обученных моделей. Вы заметите первую из этих моделей Audio Spectrogram Transformer, контрольную точку которой мы использовали в предыдущем примере. Этот процесс фильтрации моделей на Hugging Face Hub - именно то, как мы выбирали контрольную точку для показа вам!
Идентификация языка (Language Identification)
Идентификация языка (LID) - это задача определения языка, на котором говорят в аудиосэмпле, из списка языков-кандидатов. LID может стать важной частью многих речевых конвейеров. Например, при получении образца аудиозаписи на неизвестном языке модель LID может быть использована для классификации языка (языков), на котором разговаривают в аудиозаписи, и последующего выбора соответствующей модели распознавания речи, обученной на этом языке, для транскрибации аудиозаписи.
FLEURS
FLEURS (Few-shot Learning Evaluation of Universal Representations of Speech) - это набор данных для оценки систем распознавания речи на 102 языках, в том числе на многих языках, которые относятся к категории “малоресурсных”. Ознакомьтесь с карточкой набора данных FLEURS на Hugging Face Hub и изучите различные языки, которые в нем представлены: google/fleurs. Можете ли Вы найти здесь свой родной язык? Если нет, то какой язык наиболее близок к нему?
Загрузим выборку из валидационной части набора данных FLEURS в потоковом режиме:
fleurs = load_dataset("google/fleurs", "all", split="validation", streaming=True)
sample = next(iter(fleurs))Отлично! Теперь мы можем загрузить нашу модель классификации звука. Для этого мы будем использовать версию Whisper дообученный на наборе данных FLEURS, который в настоящее время является наиболее производительной моделью LID на Hugging Face Hub:
classifier = pipeline(
"audio-classification", model="sanchit-gandhi/whisper-medium-fleurs-lang-id"
)Затем мы можем пропустить звук через наш классификатор и сгенерировать предсказание:
classifier(sample["audio"])Output:
[{'score': 0.9999330043792725, 'label': 'Afrikaans'},
{'score': 7.093023668858223e-06, 'label': 'Northern-Sotho'},
{'score': 4.269149485480739e-06, 'label': 'Icelandic'},
{'score': 3.2661141631251667e-06, 'label': 'Danish'},
{'score': 3.2580724109720904e-06, 'label': 'Cantonese Chinese'}]Видно, что модель предсказала, что звук был на “Afrikaans” с очень высокой вероятностью (близкой к 1). Набор данных FLEURS содержит аудиоданные из широкого спектра языков - мы видим, что возможные метки классов включают “Northern-Sotho”, “Icelandic”, “Danish” и “Cantonese Chinese” языки, а также другие. Полный список языков, представленных в карточке набора данных, можно найти здесь: google/fleurs.
Посмотрите самостоятельно! Какие еще контрольные точки можно найти для FLEURS LID на хабе? Какие модели трансформаторов используются под капотом?
Zero-Shot Audio Classification
В традиционной парадигме классификации звука модель предсказывает метку класса из предварительно определенного набора возможных классов. Это создает препятствие для использования предварительно обученных моделей для классификации звука, поскольку набор меток предварительно обученной модели должен соответствовать набору меток последующей задачи. В предыдущем примере LID модель должна предсказать один из 102 языковых классов, на которых она была обучена. Если для решения поставленной задачи требуется 110 языков, то модель не сможет предсказать 8 из 110 языков, и для достижения полного покрытия потребуется повторное обучение. Это ограничивает эффективность применения трансферного обучения для задач классификации звука.
Zero-shot классификация звука это метод, позволяющий использовать предварительно обученную модель классификации аудиоданных, натренированную на множестве размеченных примеров, для классификации новых примеров из ранее не встречавшихся классов. Давайте рассмотрим, как этого можно добиться!
В настоящее время 🤗 Transformers поддерживает один вид модели для Zero-shot классификации звука: это CLAP model. CLAP - это модель, основанная на трансформации, которая принимает в качестве входных данных звук и текст и вычисляет сходство между ними. Если мы передаем текстовый ввод, который сильно коррелирует с аудиовводом, мы получим высокую оценку сходства. И наоборот, при передаче текстового ввода, совершенно не связанного с аудиовводом, будет получено низкое сходство.
Мы можем использовать это предсказание сходства для zero-shot классификации звука, передавая модели один аудиовход и несколько меток-кандидатов. Модель вернет оценку сходства для каждой из меток-кандидатов, и мы можем выбрать в качестве прогноза ту, которая имеет наибольшую оценку.
Рассмотрим пример, в котором мы используем один аудиовход от набора данных Environmental Speech Challenge (ESC):
dataset = load_dataset("ashraq/esc50", split="train", streaming=True)
audio_sample = next(iter(dataset))["audio"]["array"]Затем мы определяем наши метки-кандидаты, которые образуют набор возможных классификационных меток. Модель будет возвращать вероятность принадлежности к классу для каждой из заданных нами меток. Это означает, что нам необходимо знать априори набор возможных меток в нашей задаче классификации, причем так, чтобы правильная метка содержалась в этом наборе и, следовательно, ей была присвоена правильная вероятностная оценка. Обратите внимание, что мы можем передать модели либо полный набор меток, либо отобранное вручную подмножество, которое, по нашему мнению, содержит правильную метку. Передача полного набора меток будет более исчерпывающей, но за счет более низкой точности классификации, поскольку пространство классификации больше (при условии, что правильной меткой является выбранное нами подмножество меток):
candidate_labels = ["Sound of a dog", "Sound of vacuum cleaner"]Мы можем прогнать обе эти метки через модель, чтобы найти метку-кандидата, которая наиболее похожа на входной аудиосигнал:
classifier = pipeline(
task="zero-shot-audio-classification", model="laion/clap-htsat-unfused"
)
classifier(audio_sample, candidate_labels=candidate_labels)Output:
[{'score': 0.9997242093086243, 'label': 'Sound of a dog'}, {'score': 0.0002758323971647769, 'label': 'Sound of vacuum cleaner'}]Отлично! Модель, похоже, уверена, что у нас есть звук собаки - она предсказывает его с вероятностью 99,96%, так что мы примем это за наше предсказание. Убедимся в том, что мы не ошиблись, прослушав аудиопример (не увеличивайте громкость слишком сильно!):
Audio(audio_sample, rate=16000)Отлично! У нас есть звук лая собаки 🐕, что соответствует предсказанию модели. Поиграйте с разными аудиосэмплами и разными кандидатами на метки - сможете ли вы определить набор меток, которые дают хорошее обобщение по всему набору данных ESC? Подсказка: подумайте, где можно найти информацию о возможных звуках в ESC, и постройте свои метки соответствующим образом!
Возможно, вы зададитесь вопросом, почему мы не используем конвейер zero-shot классификации звука для всех задач классификации звука? Кажется, что мы можем делать предсказания для любой задачи классификации звука, определяя соответствующие метки классов априори, тем самым обходя ограничения, связанные с тем, что наша задача классификации должна соответствовать меткам, на которых была предварительно обучена модель. Это связано с характером модели CLAP, используемой в zero-shot конвейере: CLAP предварительно обучена на общих аудиоданных для классификации, таких как звуки окружающей среды в наборе данных ESC, а не на речевых данных, как в задаче LID. Если дать ему речь на английском и речь на испанском языках, CLAP поймет, что оба примера являются речевыми данными 🗣️. Но он не сможет различить языки так, как это может сделать специализированная LID-модель.
Что дальше?
Мы рассмотрели ряд различных задач классификации звука и представили наиболее актуальные наборы данных и модели, которые можно загрузить с
Hugging Face Hub и использовать всего в нескольких строках кода с помощью pipeline(). Эти задачи включали в себя выделение ключевых слов,
идентификацию языка и zero-shot классификацию аудиозаписей.
Но что, если мы хотим сделать что-то новое? Мы много работали над задачами обработки речи, но это лишь один из аспектов классификации аудио. Другая популярная область обработки звука связана с музыкой. Хотя музыка по своей сути отличается от речи, многие из тех же принципов, о которых мы уже узнали, могут быть применены и к музыке.
В следующем разделе мы рассмотрим пошаговое руководство по тонкой настройке модели трансформера с помощью 🤗 Transformers на задаче классификации музыки.
К концу этой работы у вас будет контрольная точка дообученной модели, которую вы сможете передать в pipeline(), что позволит вам классифицировать
песни точно так же, как мы классифицировали здесь речь!