
Tensorflow Keras Implementation of an Image Captioning Model with encoder-decoder network. 🌃🌅🎑
This repo contains the models and the notebook on Image captioning with visual attention.
Full credits to TensorFlow Team
Background Information
This notebook implements TensorFlow Keras implementation on Image captioning with visual attention.
Given an image like the example below, your goal is to generate a caption such as "a surfer riding on a wave".
 To accomplish this, you'll use an attention-based model, which enables us to see what parts of the image the model focuses on as it generates a caption.
To accomplish this, you'll use an attention-based model, which enables us to see what parts of the image the model focuses on as it generates a caption.
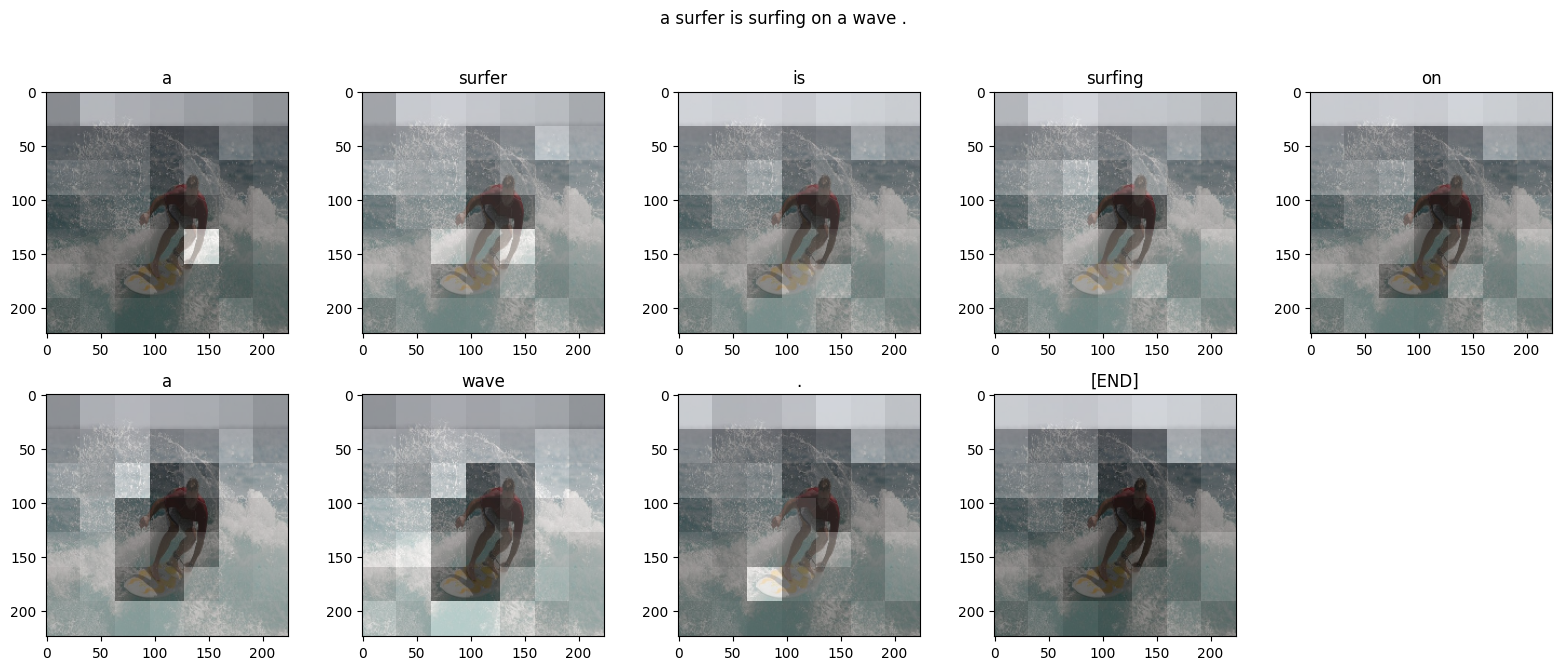 The model architecture is similar to Show, Attend and Tell: Neural Image Caption Generation with Visual Attention.
The model architecture is similar to Show, Attend and Tell: Neural Image Caption Generation with Visual Attention.
This notebook is an end-to-end example. When you run the notebook, it downloads the MS-COCO dataset, preprocesses and caches a subset of images using Inception V3, trains an encoder-decoder model, and generates captions on new images using the trained model.