
H2OVL Mississippi
Collection
H2O Multimodal models
•
9 items
•
Updated
•
7
[📜 H2OVL-Mississippi Paper] [🤗 HF Demo] [🚀 Quick Start]
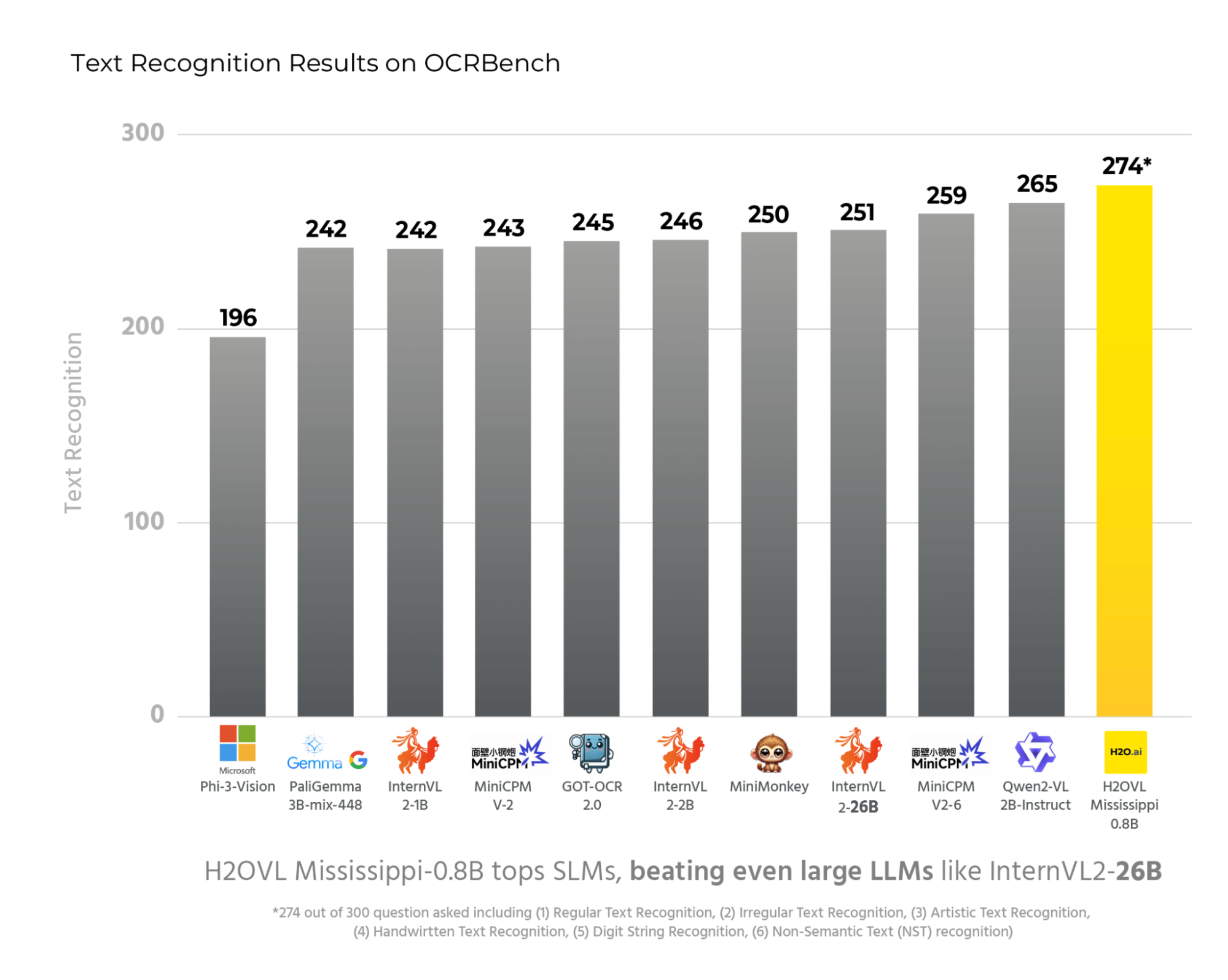
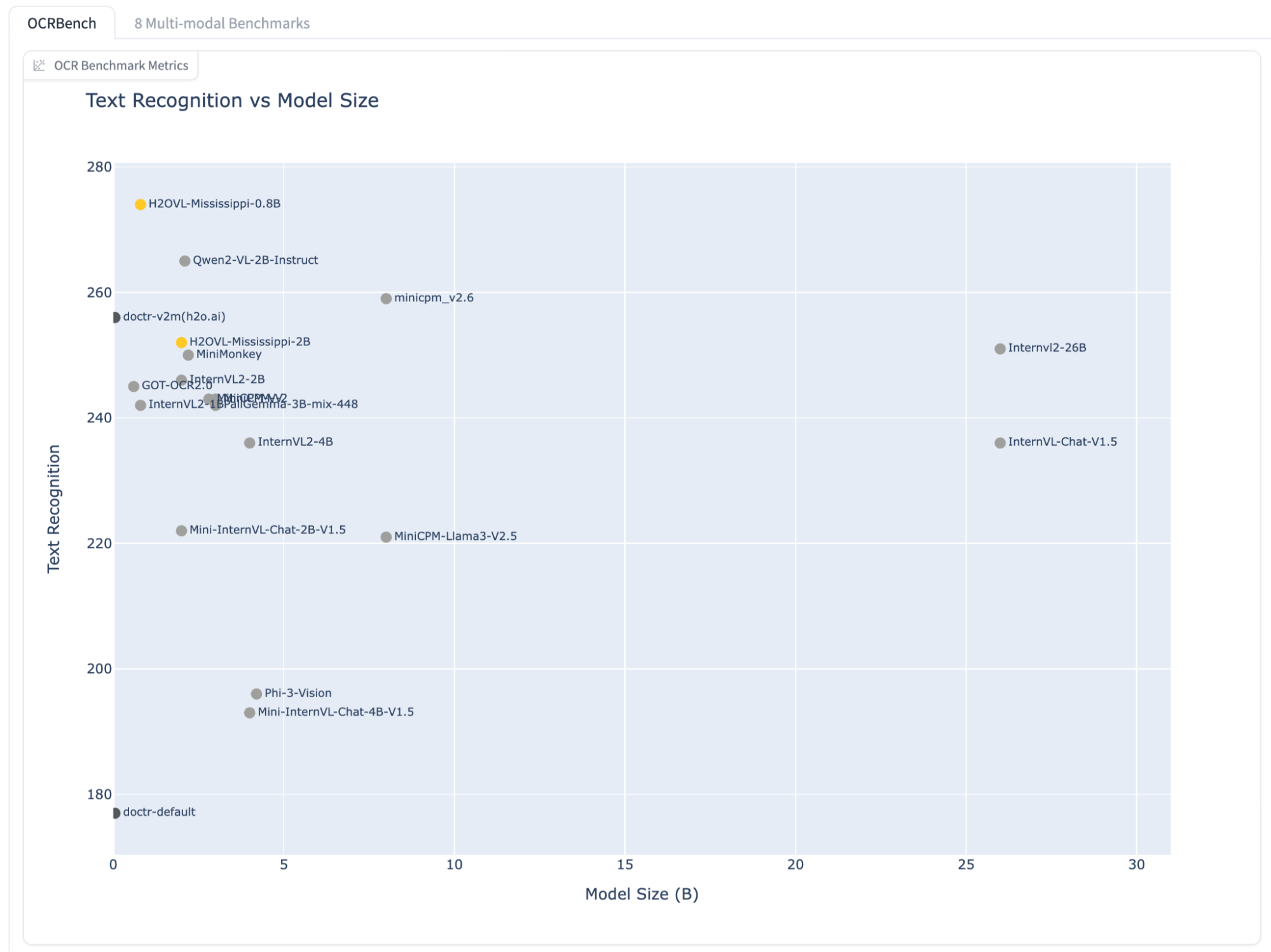
The H2OVL-Mississippi-800M is a compact yet powerful vision-language model from H2O.ai, featuring 0.8 billion parameters. Despite its small size, it delivers state-of-the-art performance in text recognition, excelling in the Text Recognition segment of OCRBench and outperforming much larger models in this domain. Built upon the robust architecture of our H2O-Danube language models, the Mississippi-800M extends their capabilities by seamlessly integrating vision and language tasks.
| Models | Params (B) | Avg. Score | MMBench | MMStar | MMMUVAL | Math Vista | Hallusion | AI2DTEST | OCRBench | MMVet |
|---|---|---|---|---|---|---|---|---|---|---|
| Qwen2-VL-2B | 2.1 | 57.2 | 72.2 | 47.5 | 42.2 | 47.8 | 42.4 | 74.7 | 797 | 51.5 |
| H2OVL-Mississippi-2B | 2.1 | 54.4 | 64.8 | 49.6 | 35.2 | 56.8 | 36.4 | 69.9 | 782 | 44.7 |
| InternVL2-2B | 2.1 | 53.9 | 69.6 | 49.8 | 36.3 | 46.0 | 38.0 | 74.1 | 781 | 39.7 |
| Phi-3-Vision | 4.2 | 53.6 | 65.2 | 47.7 | 46.1 | 44.6 | 39.0 | 78.4 | 637 | 44.1 |
| MiniMonkey | 2.2 | 52.7 | 68.9 | 48.1 | 35.7 | 45.3 | 30.9 | 73.7 | 794 | 39.8 |
| MiniCPM-V-2 | 2.8 | 47.9 | 65.8 | 39.1 | 38.2 | 39.8 | 36.1 | 62.9 | 605 | 41.0 |
| InternVL2-1B | 0.8 | 48.3 | 59.7 | 45.6 | 36.7 | 39.4 | 34.3 | 63.8 | 755 | 31.5 |
| PaliGemma-3B-mix-448 | 2.9 | 46.5 | 65.6 | 48.3 | 34.9 | 28.7 | 32.2 | 68.3 | 614 | 33.1 |
| H2OVL-Mississippi-0.8B | 0.8 | 43.5 | 47.7 | 39.1 | 34.0 | 39.0 | 29.6 | 53.6 | 751 | 30.0 |
| DeepSeek-VL-1.3B | 2.0 | 39.6 | 63.8 | 39.9 | 33.8 | 29.8 | 27.6 | 51.5 | 413 | 29.2 |
pip install transformers torch torchvision einops timm peft sentencepiece flash_attn
import torch
from transformers import AutoConfig, AutoModel, AutoTokenizer
# Set up the model and tokenizer
model_path = 'h2oai/h2ovl-mississippi-800m'
config = AutoConfig.from_pretrained(model_path, trust_remote_code=True)
config.llm_config._attn_implementation = 'flash_attention_2'
model = AutoModel.from_pretrained(
model_path,
torch_dtype=torch.bfloat16,
config=config,
low_cpu_mem_usage=True,
trust_remote_code=True).eval().cuda()
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True, use_fast=False)
generation_config = dict(max_new_tokens=2048, do_sample=True)
# pure-text conversation
question = 'Hello, how are you?'
response, history = model.chat(tokenizer, None, question, generation_config, history=None, return_history=True)
print(f'User: {question}\nAssistant: {response}')
# Example for single image
image_file = './examples/image.jpg'
question = '<image>\nRead the text in the image.'
response, history = model.chat(tokenizer, image_file, question, generation_config, history=None, return_history=True)
print(f'User: {question}\nAssistant: {response}')
This guide demonstrates how to create prompts for extracting information and converting it into structured JSON outputs. It starts with basic examples and progresses to more complex JSON structures, including handling data from images of tables and charts. The objective is to help users design effective prompts that can be used in various applications, such as natural language processing, chatbots, or data extraction from visual inputs.
To get started with JSON extraction from images, it's essential to have a clear understanding of the visual content you want to extract and the structure of the desired JSON output. The following examples will guide you through crafting prompts to achieve this.
Hypothetical Scenario: You have an image of a form that contains basic details like "Name," "Date of Birth," and "Address."
Prompt:
Extract the details from the form image and structure them into JSON format:
{
"name": "",
"date_of_birth": "",
"address": ""
}
Expected Output:
{
"name": "John Doe",
"date_of_birth": "1990-01-01",
"address": "1234 Elm Street, Springfield"
}
Hypothetical Scenario: You have an image of a form that contains detailed personal information, including contact details and emergency contacts.
Prompt:
Extract the information from the form and format it as follows:
{
"personal_details": {
"name": "",
"age": 0,
"gender": ""
},
"contact": {
"phone": "",
"email": ""
},
"emergency_contact": {
"name": "",
"relation": "",
"phone": ""
}
}
Expected Output:
{
"personal_details": {
"name": "Sarah Connor",
"age": 35,
"gender": "Female"
},
"contact": {
"phone": "555-1234",
"email": "sarah.connor@example.com"
},
"emergency_contact": {
"name": "Kyle Reese",
"relation": "Friend",
"phone": "555-5678"
}
}
Hypothetical Scenario: You have an image of a schedule that lists several events, their times, and locations.
Prompt:
Extract the event details from the schedule image and structure them into JSON:
{
"events": [
{
"name": "",
"time": "",
"location": ""
}
]
}
Expected Output:
{
"events": [
{
"name": "Morning Meeting",
"time": "09:00 AM",
"location": "Conference Room 1"
},
{
"name": "Lunch Break",
"time": "12:00 PM",
"location": "Cafeteria"
},
{
"name": "Project Update",
"time": "02:00 PM",
"location": "Conference Room 2"
}
]
}
Images of tables often contain structured data that needs to be parsed and converted to JSON. The following example demonstrates how to handle tabular data extraction.
Hypothetical Scenario: You have an image of a table listing product names, prices, and quantities.
Prompt:
Extract the data from the table image and format it as JSON:
{
"products": [
{
"product_name": "",
"price": "",
"quantity": 0
}
]
}
Expected Output:
{
"products": [
{
"product_name": "Apples",
"price": "$2",
"quantity": 10
},
{
"product_name": "Bananas",
"price": "$1",
"quantity": 20
},
{
"product_name": "Oranges",
"price": "$3",
"quantity": 15
}
]
}
Charts include metadata and data points that need to be accurately extracted. Here's how to structure prompts to extract chart data from images.
Hypothetical Scenario: You have an image of a bar chart that shows monthly sales figures.
Prompt:
Extract the details of the bar chart from the image, including the title, axis labels, and data points and format it as JSON:
{
"chart": {
"title": "",
"x_axis": "",
"y_axis": "",
"data_points": [
{
"label": "",
"value": 0
}
]
}
}
Expected Output:
{
"chart": {
"title": "Monthly Sales Report",
"x_axis": "Months",
"y_axis": "Sales (in $)",
"data_points": [
{
"label": "January",
"value": 500
},
{
"label": "February",
"value": 600
},
{
"label": "March",
"value": 700
}
]
}
}
We would like to express our gratitude to the InternVL team at OpenGVLab for their research and codebases, upon which we have built and expanded. We also acknowledge the work of the LLaVA team and the Monkey team for their insights and techniques used in improving multimodal models.
Please read this disclaimer carefully before using the large language model provided in this repository. Your use of the model signifies your agreement to the following terms and conditions.
By using the large language model provided in this repository, you agree to accept and comply with the terms and conditions outlined in this disclaimer. If you do not agree with any part of this disclaimer, you should refrain from using the model and any content generated by it.