
RecurrentGemma Release
Collection
8 items
•
Updated
•
40
This repository is publicly accessible, but you have to accept the conditions to access its files and content.
To access RecurrentGemma on Hugging Face, you’re required to review and agree to Google’s usage license. To do this, please ensure you’re logged-in to Hugging Face and click below. Requests are processed immediately.
Log in or Sign Up to review the conditions and access this model content.
Model Page: RecurrentGemma
This model card corresponds to the 9B base version of the RecurrentGemma model. You can also visit the model card of the 9B instruct model.
Resources and technical documentation:
Terms of Use: Terms
Authors: Google
Below we share some code snippets on how to get quickly started with running the model.
First, make sure to pip install transformers, then copy the snippet from the section that is relevant for your usecase.
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("google/recurrentgemma-9b")
model = AutoModelForCausalLM.from_pretrained("google/recurrentgemma-9b", device_map="auto")
input_text = "Write me a poem about Machine Learning."
input_ids = tokenizer(input_text, return_tensors="pt").to("cuda")
outputs = model.generate(**input_ids)
print(tokenizer.decode(outputs[0]))
RecurrentGemma is a family of open language models built on a novel recurrent architecture developed at Google. Both pre-trained and instruction-tuned versions are available in English.
Like Gemma, RecurrentGemma models are well-suited for a variety of text generation tasks, including question answering, summarization, and reasoning. Because of its novel architecture, RecurrentGemma requires less memory than Gemma and achieves faster inference when generating long sequences.
@article{recurrentgemma_2024,
title={RecurrentGemma},
url={},
DOI={},
publisher={Kaggle},
author={Griffin Team, Alexsandar Botev and Soham De and Samuel L Smith and Anushan Fernando and George-Christian Muraru and Ruba Haroun and Leonard Berrada et al.},
year={2024}
}
RecurrentGemma uses the same training data and data processing as used by the Gemma model family. A full description can be found on the Gemma model card.
Like Gemma, RecurrentGemma was trained on TPUv5e, using JAX and ML Pathways.
These models were evaluated against a large collection of different datasets and metrics to cover different aspects of text generation:
| Benchmark | Metric | RecurrentGemma 9B |
|---|---|---|
| MMLU | 5-shot, top-1 | 60.5 |
| HellaSwag | 0-shot | 80.4 |
| PIQA | 0-shot | 81.3 |
| SocialIQA | 0-shot | 52.3 |
| BoolQ | 0-shot | 80.3 |
| WinoGrande | partial score | 73.6 |
| CommonsenseQA | 7-shot | 73.2 |
| OpenBookQA | 51.8 | |
| ARC-e | 78.8 | |
| ARC-c | 52.0 | |
| TriviaQA | 5-shot | 70.5 |
| Natural Questions | 5-shot | 21.7 |
| HumanEval | pass@1 | 31.1 |
| MBPP | 3-shot | 42.0 |
| GSM8K | maj@1 | 42.6 |
| MATH | 4-shot | 23.8 |
| AGIEval | 39.3 | |
| BIG-Bench | 55.2 | |
| Average | 56.1 |
RecurrentGemma provides improved sampling speeds, particularly for long sequences or large batch sizes. We compared the sampling speeds of RecurrentGemma-9B to Gemma-7B. Note that Gemma-7B uses Multi-Head Attention, and the speed improvements would be smaller when comparing against a transformer using Multi-Query Attention.
We evaluated throughput, i.e., the maximum number of tokens produced per second by increasing the batch size, of RecurrentGemma-9B compared to Gemma-7B, using a prefill of 2K tokens.
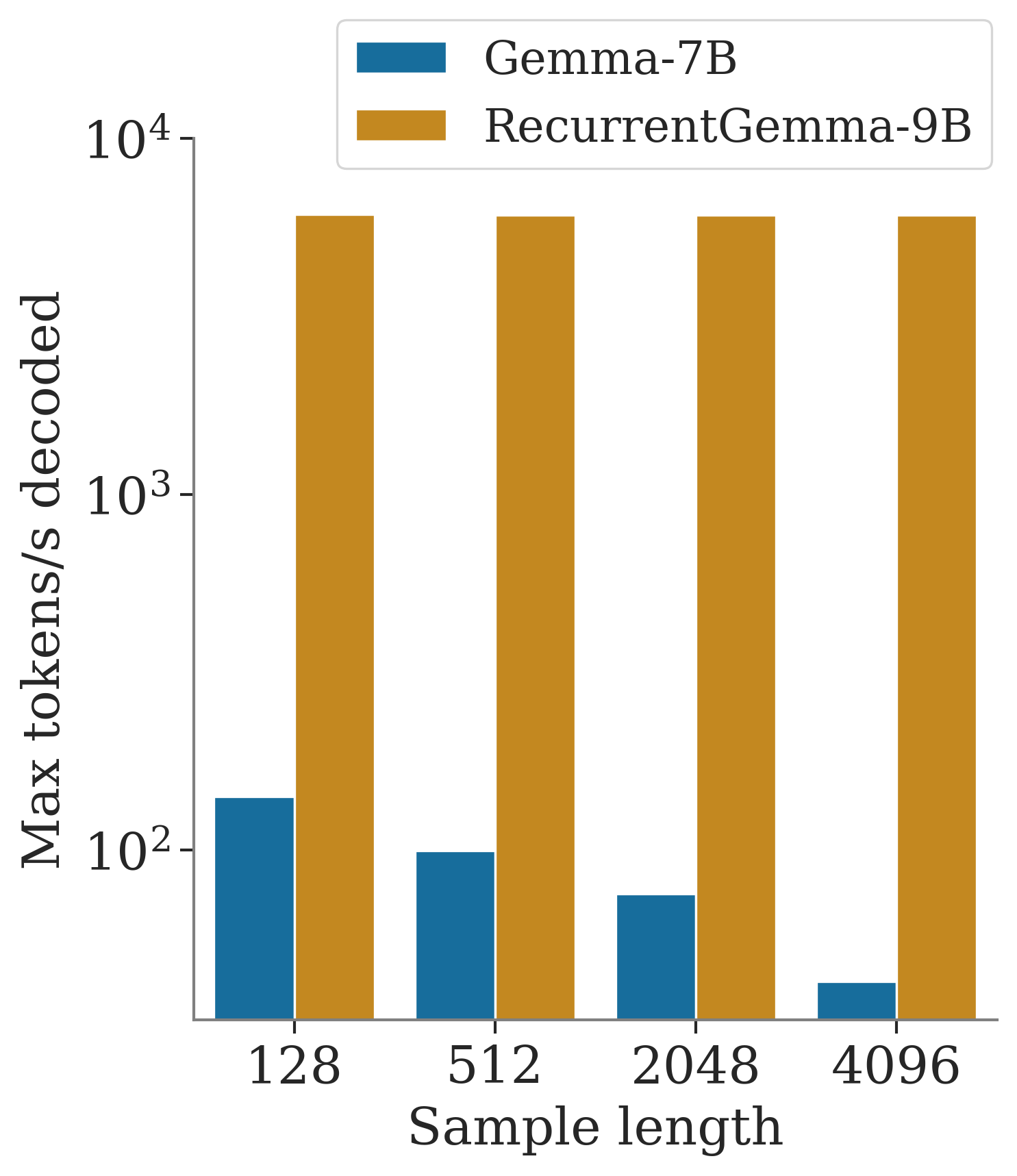
We also compared end-to-end speedups achieved by RecurrentGemma-9B over Gemma-7B when sampling a long sequence after a prefill of 4K tokens and using a batch size of 1.
| # Tokens Sampled | Gemma-7B (sec) | RecurrentGemma-9B (sec) | Improvement (%) |
|---|---|---|---|
| 128 | 3.1 | 2.8 | 9.2% |
| 256 | 5.9 | 5.4 | 9.7% |
| 512 | 11.6 | 10.5 | 10.7% |
| 1024 | 23.5 | 20.6 | 14.2% |
| 2048 | 48.2 | 40.9 | 17.7% |
| 4096 | 101.9 | 81.5 | 25.0% |
| 8192 | OOM | 162.8 | - |
| 16384 | OOM | 325.2 | - |
Our evaluation methods include structured evaluations and internal red-teaming testing of relevant content policies. Red-teaming was conducted by a number of different teams, each with different goals and human evaluation metrics. These models were evaluated against a number of different categories relevant to ethics and safety, including:
The results of ethics and safety evaluations are within acceptable thresholds for meeting internal policies for categories such as child safety, content safety, representational harms, memorization, large-scale harms. On top of robust internal evaluations, the results of well known safety benchmarks like BBQ, Winogender, Winobias, RealToxicity, and TruthfulQA are shown here.
| Benchmark | Metric | RecurrentGemma 9B | RecurrentGemma 9B IT |
|---|---|---|---|
| RealToxicity | avg | 10.3 | 8.8 |
| BOLD | 39.8 | 47.9 | |
| CrowS-Pairs | top-1 | 38.7 | 39.5 |
| BBQ Ambig | top-1 | 95.9 | 67.1 |
| BBQ Disambig | top-1 | 78.6 | 78.9 |
| Winogender | top-1 | 59.0 | 64.0 |
| TruthfulQA | 38.6 | 47.7 | |
| Winobias 1_2 | 61.5 | 60.6 | |
| Winobias 2_2 | 90.2 | 90.3 | |
| Toxigen | 58.8 | 64.5 |
These models have certain limitations that users should be aware of:
The development of large language models (LLMs) raises several ethical concerns. In creating an open model, we have carefully considered the following:
Risks Identified and Mitigations:
Open Large Language Models (LLMs) have a wide range of applications across various industries and domains. The following list of potential uses is not comprehensive. The purpose of this list is to provide contextual information about the possible use-cases that the model creators considered as part of model training and development.
At the time of release, this family of models provides high-performance open large language model implementations designed from the ground up for Responsible AI development compared to similarly sized models.
Using the benchmark evaluation metrics described in this document, these models have shown to provide superior performance to other, comparably-sized open model alternatives.
In particular, RecurrentGemma models achieve comparable performance to Gemma models but are faster during inference and require less memory, especially on long sequences.