
TinyLlama 1.1B Instruct 3T

This is the 3T base model trained on openhermes instruct dataset for 4 epochs. It is intended to be used for further finetuning.
![]()
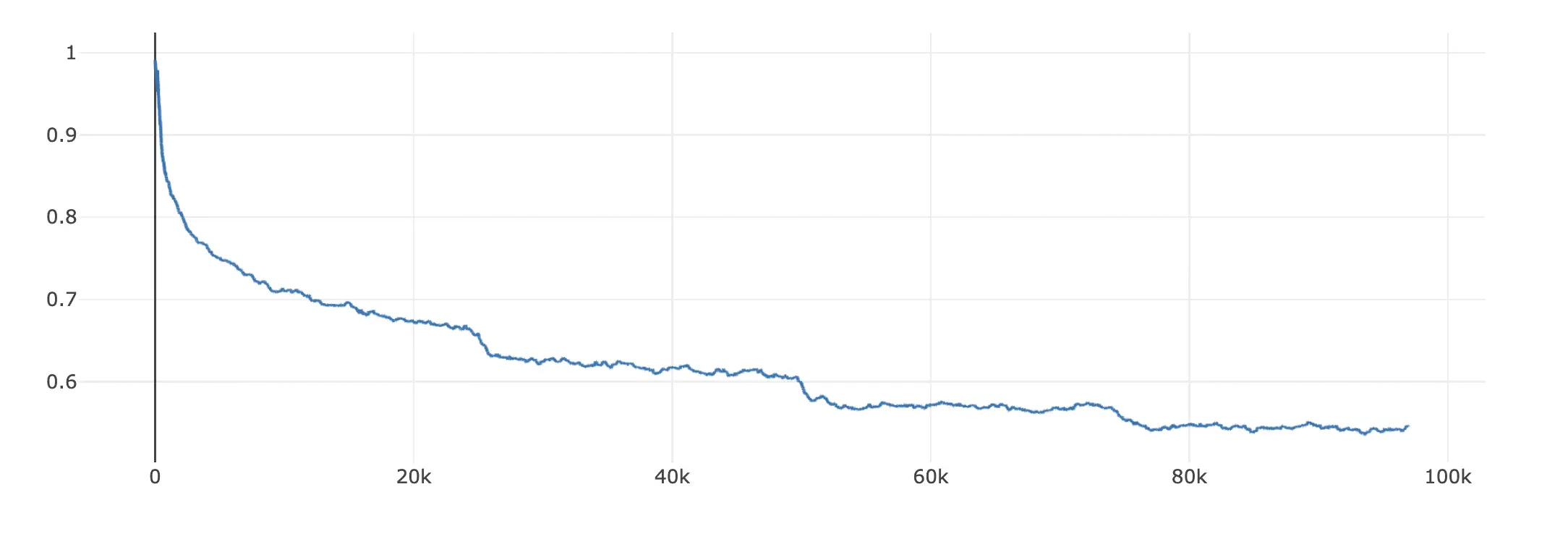
Loss
axolotl config file: lora.yml
base_model: TinyLlama/TinyLlama-1.1B-intermediate-step-1431k-3T
model_type: LlamaForCausalLM
tokenizer_type: LlamaTokenizer
is_llama_derived_model: true
load_in_8bit: true
load_in_4bit: false
strict: false
datasets:
- path: teknium/openhermes
type: alpaca
dataset_prepared_path:
val_set_size: 0.05
output_dir: ./tiny-llama-instruct-lora
sequence_len: 4096
sample_packing: true
pad_to_sequence_len: true
adapter: lora
lora_model_dir:
lora_r: 32
lora_alpha: 16
lora_dropout: 0.05
lora_target_linear: true
lora_fan_in_fan_out:
gradient_accumulation_steps: 4
micro_batch_size: 2
num_epochs: 4
optimizer: adamw_bnb_8bit
lr_scheduler: cosine
learning_rate: 0.0002
train_on_inputs: false
group_by_length: false
bf16: true
fp16: false
tf32: false
gradient_checkpointing: true
early_stopping_patience:
resume_from_checkpoint:
local_rank:
logging_steps: 1
xformers_attention:
flash_attention: true
warmup_steps: 10
evals_per_epoch: 4
saves_per_epoch: 1
debug:
deepspeed:
weight_decay: 0.0
fsdp:
fsdp_config:
special_tokens:
- Downloads last month
- 41
Inference Providers
NEW
This model isn't deployed by any Inference Provider.
🙋
Ask for provider support