
SpeechTokenizer: Unified Speech Tokenizer for Speech Large Language Models
Introduction
This is the code for the SpeechTokenizer presented in the SpeechTokenizer: Unified Speech Tokenizer for Speech Large Language Models. SpeechTokenizer is a unified speech tokenizer for speech large language models, which adopts the Encoder-Decoder architecture with residual vector quantization (RVQ). Unifying semantic and acoustic tokens, SpeechTokenizer disentangles different aspects of speech information hierarchically across different RVQ layers. Specifically, The code indices that the first quantizer of RVQ outputs can be considered as semantic tokens and the output of the remaining quantizers can be regarded as acoustic tokens, which serve as supplements for the information lost by the first quantizer. We provide our models:
- A model operated at 16khz on monophonic speech trained on Librispeech with average representation across all HuBERT layers as semantic teacher.
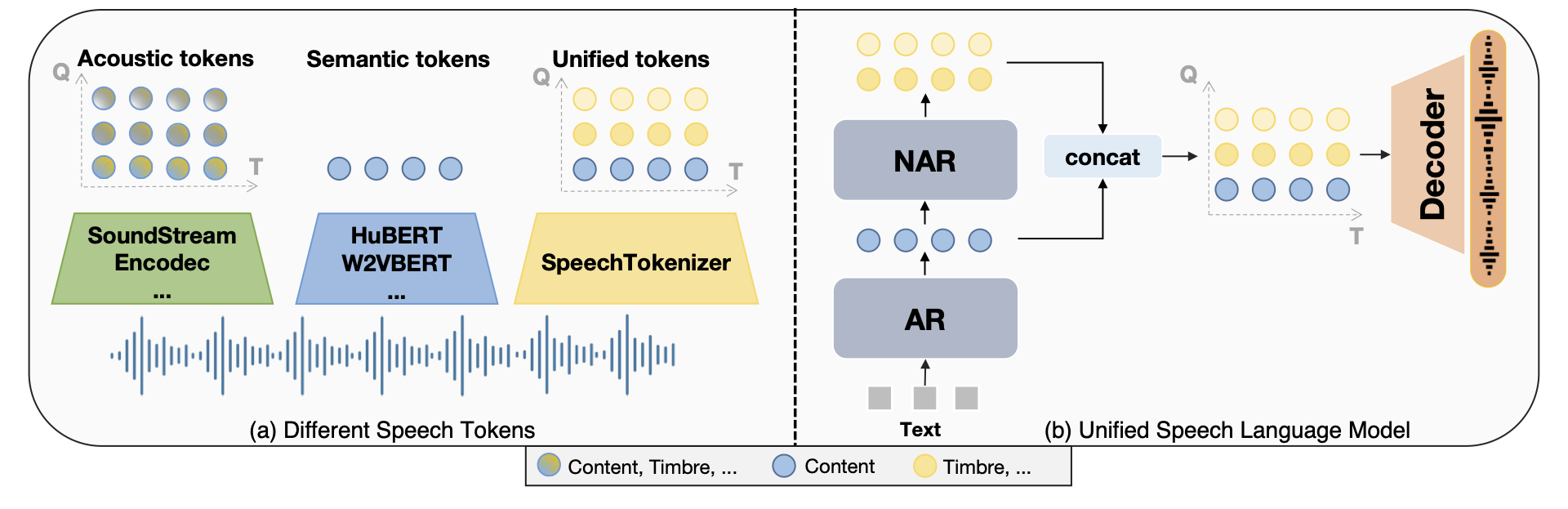
Overview

The SpeechTokenizer framework.
Welcome to try our SLMTokBench and we will also open source our USLM !!
Samples
Samples are provided on our demo page.
Installation
SpeechTokenizer requires Python>=3.8, and a reasonly recent version of PyTorch. To install SpeechTokenizer, you can run from this repository:
pip install -U speechtokenizer
# or you can clone the repo and install locally
git clone https://github.com/ZhangXInFD/SpeechTokenizer.git
cd SpeechTokenizer
pip install .
Usage
Model storage
| Model | Discription |
|---|---|
| speechtokenizer_hubert_avg | Adopt average representation across all HuBERT layers as semantic teacher |
load model
from speechtokenizer import SpeechTokenizer
config_path = '/path/config.json'
ckpt_path = '/path/SpeechTokenizer.pt'
model = SpeechTokenizer.load_from_checkpoint(config_path, ckpt_path)
model.eval()
Extracting discrete representions
import torchaudio
import torch
# Load and pre-process speech waveform
wav, sr = torchaudio.load('<SPEECH_FILE_PATH>')
if sr != model.sample_rate:
wav = torchaudio.functional.resample(wav, sr, model.sample_rate)
wav = wav.unsqueeze(0)
# Extract discrete codes from SpeechTokenizer
with torch.no_grad():
codes = model.encode(wav) # codes: (n_q, B, T)
semantic_tokens = codes[0, :, :]
acoustic_tokens = codes[1:, :, :]
Decoding discrete representions
# Decoding from the first quantizers to ith quantizers
wav = model.decode(codes[:(i + 1)]) # wav: (B, 1, T)
# Decoding from ith quantizers to jth quantizers
wav = model.decode(codes[i: (j + 1)], st=i)
# Cancatenating semantic tokens and acoustic tokens and then decoding
semantic_tokens = ... # (..., B, T)
acoustic_tokens = ... # (..., B, T)
wav = model.decode(torch.cat([semantic_tokens, acoustic_tokens], axis=0))
Citation
If you use this code or result in your paper, please cite our work as:
@misc{zhang2023speechtokenizer,
title={SpeechTokenizer: Unified Speech Tokenizer for Speech Large Language Models},
author={Xin Zhang and Dong Zhang and Shimin Li and Yaqian Zhou and Xipeng Qiu},
year={2023},
eprint={2308.16692},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
License
The code in this repository is released under the Apache 2.0 license as found in the LICENSE file.