Transformers documentation
Trainer
Trainer
Trainer 类提供了一个 PyTorch 的 API,用于处理大多数标准用例的全功能训练。它在大多数示例脚本中被使用。
如果你想要使用自回归技术在文本数据集上微调像 Llama-2 或 Mistral 这样的语言模型,考虑使用 trl 的 SFTTrainer。SFTTrainer 封装了 Trainer,专门针对这个特定任务进行了优化,并支持序列打包、LoRA、量化和 DeepSpeed,以有效扩展到任何模型大小。另一方面,Trainer 是一个更通用的选项,适用于更广泛的任务。
在实例化你的 Trainer 之前,创建一个 TrainingArguments,以便在训练期间访问所有定制点。
这个 API 支持在多个 GPU/TPU 上进行分布式训练,支持 NVIDIA Apex 的混合精度和 PyTorch 的原生 AMP。
Trainer 包含基本的训练循环,支持上述功能。如果需要自定义训练,你可以继承 Trainer 并覆盖以下方法:
- get_train_dataloader — 创建训练 DataLoader。
- get_eval_dataloader — 创建评估 DataLoader。
- get_test_dataloader — 创建测试 DataLoader。
- log — 记录观察训练的各种对象的信息。
- create_optimizer_and_scheduler — 如果它们没有在初始化时传递,请设置优化器和学习率调度器。请注意,你还可以单独继承或覆盖
create_optimizer和create_scheduler方法。 - create_optimizer — 如果在初始化时没有传递,则设置优化器。
- create_scheduler — 如果在初始化时没有传递,则设置学习率调度器。
- compute_loss - 计算单批训练输入的损失。
- training_step — 执行一步训练。
- prediction_step — 执行一步评估/测试。
- evaluate — 运行评估循环并返回指标。
- predict — 返回在测试集上的预测(如果有标签,则包括指标)。
Trainer 类被优化用于 🤗 Transformers 模型,并在你在其他模型上使用时可能会有一些令人惊讶的结果。当在你自己的模型上使用时,请确保:
- 你的模型始终返回元组或 ModelOutput 的子类。
- 如果提供了
labels参数,你的模型可以计算损失,并且损失作为元组的第一个元素返回(如果你的模型返回元组)。 - 你的模型可以接受多个标签参数(在
TrainingArguments中使用label_names将它们的名称指示给Trainer),但它们中没有一个应该被命名为"label"。
以下是如何自定义 Trainer 以使用加权损失的示例(在训练集不平衡时很有用):
from torch import nn
from transformers import Trainer
class CustomTrainer(Trainer):
def compute_loss(self, model, inputs, return_outputs=False):
labels = inputs.pop("labels")
# forward pass
outputs = model(**inputs)
logits = outputs.get("logits")
# compute custom loss (suppose one has 3 labels with different weights)
loss_fct = nn.CrossEntropyLoss(weight=torch.tensor([1.0, 2.0, 3.0], device=model.device))
loss = loss_fct(logits.view(-1, self.model.config.num_labels), labels.view(-1))
return (loss, outputs) if return_outputs else loss在 PyTorch Trainer 中自定义训练循环行为的另一种方法是使用 callbacks,这些回调可以检查训练循环状态(用于进度报告、在 TensorBoard 或其他 ML 平台上记录日志等)并做出决策(比如提前停止)。
Trainer
[[autodoc]] Trainer - all
Seq2SeqTrainer
[[autodoc]] Seq2SeqTrainer - evaluate - predict
TrainingArguments
[[autodoc]] TrainingArguments - all
Seq2SeqTrainingArguments
[[autodoc]] Seq2SeqTrainingArguments - all
Checkpoints
默认情况下,Trainer 会将所有checkpoints保存在你使用的 TrainingArguments 中设置的 output_dir 中。这些checkpoints将位于名为 checkpoint-xxx 的子文件夹中,xxx 是训练的步骤。
从checkpoints恢复训练可以通过调用 Trainer.train() 时使用以下任一方式进行:
resume_from_checkpoint=True,这将从最新的checkpoint恢复训练。resume_from_checkpoint=checkpoint_dir,这将从指定目录中的特定checkpoint恢复训练。
此外,当使用 push_to_hub=True 时,你可以轻松将checkpoints保存在 Model Hub 中。默认情况下,保存在训练中间过程的checkpoints中的所有模型都保存在不同的提交中,但不包括优化器状态。你可以根据需要调整 TrainingArguments 的 hub-strategy 值:
"checkpoint": 最新的checkpoint也被推送到一个名为 last-checkpoint 的子文件夹中,让你可以通过trainer.train(resume_from_checkpoint="output_dir/last-checkpoint")轻松恢复训练。"all_checkpoints": 所有checkpoints都像它们出现在输出文件夹中一样被推送(因此你将在最终存储库中的每个文件夹中获得一个checkpoint文件夹)。
Logging
默认情况下,Trainer 将对主进程使用 logging.INFO,对副本(如果有的话)使用 logging.WARNING。
可以通过 TrainingArguments 的参数覆盖这些默认设置,使用其中的 5 个 logging 级别:
log_level- 用于主进程log_level_replica- 用于副本
此外,如果 TrainingArguments 的 log_on_each_node 设置为 False,则只有主节点将使用其主进程的日志级别设置,所有其他节点将使用副本的日志级别设置。
请注意,Trainer 将在其 Trainer.__init__() 中分别为每个节点设置 transformers 的日志级别。因此,如果在创建 Trainer 对象之前要调用其他 transformers 功能,可能需要更早地设置这一点(请参见下面的示例)。
以下是如何在应用程序中使用的示例:
[...]
logger = logging.getLogger(__name__)
# Setup logging
logging.basicConfig(
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
datefmt="%m/%d/%Y %H:%M:%S",
handlers=[logging.StreamHandler(sys.stdout)],
)
# set the main code and the modules it uses to the same log-level according to the node
log_level = training_args.get_process_log_level()
logger.setLevel(log_level)
datasets.utils.logging.set_verbosity(log_level)
transformers.utils.logging.set_verbosity(log_level)
trainer = Trainer(...)然后,如果你只想在主节点上看到警告,并且所有其他节点不打印任何可能重复的警告,可以这样运行:
my_app.py ... --log_level warning --log_level_replica error
在多节点环境中,如果你也不希望每个节点的主进程的日志重复输出,你需要将上面的代码更改为:
my_app.py ... --log_level warning --log_level_replica error --log_on_each_node 0
然后,只有第一个节点的主进程将以 “warning” 级别记录日志,主节点上的所有其他进程和其他节点上的所有进程将以 “error” 级别记录日志。
如果你希望应用程序尽可能”安静“,可以执行以下操作:
my_app.py ... --log_level error --log_level_replica error --log_on_each_node 0
(如果在多节点环境,添加 --log_on_each_node 0)
随机性
当从 Trainer 生成的checkpoint恢复训练时,程序会尽一切努力将 python、numpy 和 pytorch 的 RNG(随机数生成器)状态恢复为保存检查点时的状态,这样可以使“停止和恢复”式训练尽可能接近“非停止式”训练。
然而,由于各种默认的非确定性 PyTorch 设置,这可能无法完全实现。如果你想要完全确定性,请参阅控制随机源。正如文档中所解释的那样,使事物变得确定的一些设置(例如 torch.backends.cudnn.deterministic)可能会减慢速度,因此不能默认执行,但如果需要,你可以自行启用这些设置。
特定GPU选择
让我们讨论一下如何告诉你的程序应该使用哪些 GPU 以及使用的顺序。
当使用 DistributedDataParallel 且仅使用部分 GPU 时,你只需指定要使用的 GPU 数量。例如,如果你有 4 个 GPU,但只想使用前 2 个,可以执行以下操作:
python -m torch.distributed.launch --nproc_per_node=2 trainer-program.py ...
如果你安装了 accelerate 或 deepspeed,你还可以通过以下任一方法实现相同的效果:
accelerate launch --num_processes 2 trainer-program.py ...
deepspeed --num_gpus 2 trainer-program.py ...
你不需要使用 Accelerate 或 Deepspeed 集成 功能来使用这些启动器。
到目前为止,你已经能够告诉程序要使用多少个 GPU。现在让我们讨论如何选择特定的 GPU 并控制它们的顺序。
以下环境变量可帮助你控制使用哪些 GPU 以及它们的顺序。
CUDA_VISIBLE_DEVICES
如果你有多个 GPU,想要仅使用其中的一个或几个 GPU,请将环境变量 CUDA_VISIBLE_DEVICES 设置为要使用的 GPU 列表。
例如,假设你有 4 个 GPU:0、1、2 和 3。要仅在物理 GPU 0 和 2 上运行,你可以执行以下操作:
CUDA_VISIBLE_DEVICES=0,2 python -m torch.distributed.launch trainer-program.py ...
现在,PyTorch 将只看到 2 个 GPU,其中你的物理 GPU 0 和 2 分别映射到 cuda:0 和 cuda:1。
你甚至可以改变它们的顺序:
CUDA_VISIBLE_DEVICES=2,0 python -m torch.distributed.launch trainer-program.py ...
这里,你的物理 GPU 0 和 2 分别映射到 cuda:1 和 cuda:0。
上面的例子都是针对 DistributedDataParallel 使用模式的,但同样的方法也适用于 DataParallel:
CUDA_VISIBLE_DEVICES=2,0 python trainer-program.py ...
为了模拟没有 GPU 的环境,只需将此环境变量设置为空值,如下所示:
CUDA_VISIBLE_DEVICES= python trainer-program.py ...
与任何环境变量一样,你当然可以将其export到环境变量而不是将其添加到命令行,如下所示:
export CUDA_VISIBLE_DEVICES=0,2
python -m torch.distributed.launch trainer-program.py ...这种方法可能会令人困惑,因为你可能会忘记之前设置了环境变量,进而不明白为什么会使用错误的 GPU。因此,在同一命令行中仅为特定运行设置环境变量是一种常见做法,正如本节大多数示例所示。
CUDA_DEVICE_ORDER
还有一个额外的环境变量 CUDA_DEVICE_ORDER,用于控制物理设备的排序方式。有两个选择:
- 按 PCIe 总线 ID 排序(与 nvidia-smi 的顺序相匹配)- 这是默认选项。
export CUDA_DEVICE_ORDER=PCI_BUS_ID- 按 GPU 计算能力排序。
export CUDA_DEVICE_ORDER=FASTEST_FIRST大多数情况下,你不需要关心这个环境变量,但如果你的设置不均匀,那么这将非常有用,例如,您的旧 GPU 和新 GPU 物理上安装在一起,但让速度较慢的旧卡排在运行的第一位。解决这个问题的一种方法是交换卡的位置。但如果不能交换卡(例如,如果设备的散热受到影响),那么设置 CUDA_DEVICE_ORDER=FASTEST_FIRST 将始终将较新、更快的卡放在第一位。但这可能会有点混乱,因为 nvidia-smi 仍然会按照 PCIe 顺序报告它们。
交换卡的顺序的另一种方法是使用:
export CUDA_VISIBLE_DEVICES=1,0在此示例中,我们只使用了 2 个 GPU,但是当然,对于计算机上有的任何数量的 GPU,都适用相同的方法。
此外,如果你设置了这个环境变量,最好将其设置在 ~/.bashrc 文件或其他启动配置文件中,然后就可以忘记它了。
Trainer集成
Trainer 已经被扩展,以支持可能显著提高训练时间并适应更大模型的库。
目前,它支持第三方解决方案 DeepSpeed 和 PyTorch FSDP,它们实现了论文 ZeRO: Memory Optimizations Toward Training Trillion Parameter Models, by Samyam Rajbhandari, Jeff Rasley, Olatunji Ruwase, Yuxiong He 的部分内容。
截至撰写本文,此提供的支持是新的且实验性的。尽管我们欢迎围绕 DeepSpeed 和 PyTorch FSDP 的issues,但我们不再支持 FairScale 集成,因为它已经集成到了 PyTorch 主线(参见 PyTorch FSDP 集成)。
CUDA拓展安装注意事项
撰写时,Deepspeed 需要在使用之前编译 CUDA C++ 代码。
虽然所有安装问题都应通过 Deepspeed 的 GitHub Issues处理,但在构建依赖CUDA 扩展的任何 PyTorch 扩展时,可能会遇到一些常见问题。
因此,如果在执行以下操作时遇到与 CUDA 相关的构建问题:
pip install deepspeed
请首先阅读以下说明。
在这些说明中,我们提供了在 pytorch 使用 CUDA 10.2 构建时应采取的操作示例。如果你的情况有所不同,请记得将版本号调整为您所需的版本。
可能的问题 #1
尽管 PyTorch 自带了其自己的 CUDA 工具包,但要构建这两个项目,你必须在整个系统上安装相同版本的 CUDA。
例如,如果你在 Python 环境中使用 cudatoolkit==10.2 安装了 pytorch,你还需要在整个系统上安装 CUDA 10.2。
确切的位置可能因系统而异,但在许多 Unix 系统上,/usr/local/cuda-10.2 是最常见的位置。当 CUDA 正确设置并添加到 PATH 环境变量时,可以通过执行以下命令找到安装位置:
which nvcc如果你尚未在整个系统上安装 CUDA,请首先安装。你可以使用你喜欢的搜索引擎查找说明。例如,如果你使用的是 Ubuntu,你可能想搜索:ubuntu cuda 10.2 install。
可能的问题 #2
另一个可能的常见问题是你可能在整个系统上安装了多个 CUDA 工具包。例如,你可能有:
/usr/local/cuda-10.2 /usr/local/cuda-11.0
在这种情况下,你需要确保 PATH 和 LD_LIBRARY_PATH 环境变量包含所需 CUDA 版本的正确路径。通常,软件包安装程序将设置这些变量以包含最新安装的版本。如果遇到构建失败的问题,且是因为在整个系统安装但软件仍找不到正确的 CUDA 版本,这意味着你需要调整这两个环境变量。
首先,你以查看它们的内容:
echo $PATH
echo $LD_LIBRARY_PATH因此,您可以了解其中的内容。
LD_LIBRARY_PATH 可能是空的。
PATH 列出了可以找到可执行文件的位置,而 LD_LIBRARY_PATH 用于查找共享库。在这两种情况下,较早的条目优先于较后的条目。 : 用于分隔多个条目。
现在,为了告诉构建程序在哪里找到特定的 CUDA 工具包,请插入所需的路径,让其首先列出:
export PATH=/usr/local/cuda-10.2/bin:$PATH
export LD_LIBRARY_PATH=/usr/local/cuda-10.2/lib64:$LD_LIBRARY_PATH请注意,我们没有覆盖现有值,而是在前面添加新的值。
当然,根据需要调整版本号和完整路径。检查你分配的目录是否实际存在。lib64 子目录是各种 CUDA .so 对象(如 libcudart.so)的位置,这个名字可能在你的系统中是不同的,如果是,请调整以反映实际情况。
可能的问题 #3
一些较旧的 CUDA 版本可能会拒绝使用更新的编译器。例如,你可能有 gcc-9,但 CUDA 可能需要 gcc-7。
有各种方法可以解决这个问题。
如果你可以安装最新的 CUDA 工具包,通常它应该支持更新的编译器。
或者,你可以在已经拥有的编译器版本之外安装较低版本,或者你可能已经安装了它但它不是默认的编译器,因此构建系统无法找到它。如果你已经安装了 gcc-7 但构建系统找不到它,以下操作可能会解决问题:
sudo ln -s /usr/bin/gcc-7 /usr/local/cuda-10.2/bin/gcc
sudo ln -s /usr/bin/g++-7 /usr/local/cuda-10.2/bin/g++这里,我们正在从 /usr/local/cuda-10.2/bin/gcc 创建到 gcc-7 的软链接,由于 /usr/local/cuda-10.2/bin/ 应该在 PATH 环境变量中(参见前一个问题的解决方案),它应该能够找到 gcc-7(和 g++7),然后构建将成功。
与往常一样,请确保编辑示例中的路径以匹配你的情况。
PyTorch完全分片数据并行(FSDP)
为了加速在更大批次大小上训练庞大模型,我们可以使用完全分片的数据并行模型。这种数据并行范例通过对优化器状态、梯度和参数进行分片,实现了在更多数据和更大模型上的训练。要了解更多信息以及其优势,请查看完全分片的数据并行博客。我们已经集成了最新的PyTorch完全分片的数据并行(FSDP)训练功能。您只需通过配置启用它。
FSDP支持所需的PyTorch版本: PyTorch Nightly(或者如果你在发布后阅读这个,使用1.12.0版本,因为带有激活的FSDP的模型保存仅在最近的修复中可用。
用法:
如果你尚未使用过分布式启动器,确保你已经添加了它
-m torch.distributed.launch --nproc_per_node=NUMBER_OF_GPUS_YOU_HAVE。分片策略:
- FULL_SHARD:在数据并行线程/GPU之间,对优化器状态、梯度和模型参数进行分片。
为此,请在命令行参数中添加
--fsdp full_shard。 - SHARD_GRAD_OP:在数据并行线程/GPU之间对优化器状态和梯度进行分片。
为此,请在命令行参数中添加
--fsdp shard_grad_op。 - NO_SHARD:不进行分片。为此,请在命令行参数中添加
--fsdp no_shard。
- FULL_SHARD:在数据并行线程/GPU之间,对优化器状态、梯度和模型参数进行分片。
为此,请在命令行参数中添加
要将参数和梯度卸载到CPU,添加
--fsdp "full_shard offload"或--fsdp "shard_grad_op offload"到命令行参数中。要使用
default_auto_wrap_policy自动递归地用FSDP包装层,请添加--fsdp "full_shard auto_wrap"或--fsdp "shard_grad_op auto_wrap"到命令行参数中。要同时启用CPU卸载和自动包装层工具,请添加
--fsdp "full_shard offload auto_wrap"或--fsdp "shard_grad_op offload auto_wrap"到命令行参数中。其余的FSDP配置通过
--fsdp_config <path_to_fsdp_config.json>传递。它可以是FSDP json配置文件的位置(例如,fsdp_config.json)或已加载的json文件作为dict。- 如果启用了自动包装,您可以使用基于transformer的自动包装策略或基于大小的自动包装策略。
- 对于基于transformer的自动包装策略,建议在配置文件中指定
fsdp_transformer_layer_cls_to_wrap。如果未指定,则默认值为model._no_split_modules(如果可用)。这将指定要包装的transformer层类名(区分大小写),例如BertLayer、GPTJBlock、T5Block等。这很重要,因为共享权重的子模块(例如,embedding层)不应最终出现在不同的FSDP包装单元中。使用此策略,每个包装的块将包含多头注意力和后面的几个MLP层。剩余的层,包括共享的embedding层,都将被方便地包装在同一个最外层的FSDP单元中。因此,对于基于transformer的模型,请使用这个方法。 - 对于基于大小的自动包装策略,请在配置文件中添加
fsdp_min_num_params。它指定了FSDP进行自动包装的最小参数数量。
- 对于基于transformer的自动包装策略,建议在配置文件中指定
- 可以在配置文件中指定
fsdp_backward_prefetch。它控制何时预取下一组参数。backward_pre和backward_pos是可用的选项。有关更多信息,请参阅torch.distributed.fsdp.fully_sharded_data_parallel.BackwardPrefetch - 可以在配置文件中指定
fsdp_forward_prefetch。它控制何时预取下一组参数。如果是"True",在执行前向传递时,FSDP明确地预取下一次即将发生的全局聚集。 - 可以在配置文件中指定
limit_all_gathers。如果是"True",FSDP明确地同步CPU线程,以防止太多的进行中的全局聚集。 - 可以在配置文件中指定
activation_checkpointing。如果是"True",FSDP activation checkpoint是一种通过清除某些层的激活值并在反向传递期间重新计算它们来减少内存使用的技术。实际上,这以更多的计算时间为代价减少了内存使用。
- 如果启用了自动包装,您可以使用基于transformer的自动包装策略或基于大小的自动包装策略。
需要注意几个注意事项
- 它与
generate不兼容,因此与所有seq2seq/clm脚本(翻译/摘要/clm等)中的--predict_with_generate不兼容。请参阅issue#21667。
PyTorch/XLA 完全分片数据并行
对于所有TPU用户,有个好消息!PyTorch/XLA现在支持FSDP。所有最新的完全分片数据并行(FSDP)训练都受支持。有关更多信息,请参阅在云端TPU上使用FSDP扩展PyTorch模型和PyTorch/XLA FSDP的实现。使用它只需通过配置启用。
需要的 PyTorch/XLA 版本以支持 FSDP:>=2.0
用法:
传递 --fsdp "full shard",同时对 --fsdp_config <path_to_fsdp_config.json> 进行以下更改:
xla应设置为True以启用 PyTorch/XLA FSDP。xla_fsdp_settings的值是一个字典,存储 XLA FSDP 封装参数。完整的选项列表,请参见此处。xla_fsdp_grad_ckpt。当True时,在每个嵌套的 XLA FSDP 封装层上使用梯度checkpoint。该设置只能在将 xla 标志设置为 true,并通过fsdp_min_num_params或fsdp_transformer_layer_cls_to_wrap指定自动包装策略时使用。- 您可以使用基于transformer的自动包装策略或基于大小的自动包装策略。
- 对于基于transformer的自动包装策略,建议在配置文件中指定
fsdp_transformer_layer_cls_to_wrap。如果未指定,默认值为model._no_split_modules(如果可用)。这指定了要包装的transformer层类名列表(区分大小写),例如BertLayer、GPTJBlock、T5Block等。这很重要,因为共享权重的子模块(例如,embedding层)不应最终出现在不同的FSDP包装单元中。使用此策略,每个包装的块将包含多头注意力和后面的几个MLP层。剩余的层,包括共享的embedding层,都将被方便地包装在同一个最外层的FSDP单元中。因此,对于基于transformer的模型,请使用这个方法。 - 对于基于大小的自动包装策略,请在配置文件中添加
fsdp_min_num_params。它指定了自动包装的 FSDP 的最小参数数量。
- 对于基于transformer的自动包装策略,建议在配置文件中指定
在 Mac 上使用 Trainer 进行加速的 PyTorch 训练
随着 PyTorch v1.12 版本的发布,开发人员和研究人员可以利用 Apple Silicon GPU 进行显著更快的模型训练。这使得可以在 Mac 上本地执行原型设计和微调等机器学习工作流程。Apple 的 Metal Performance Shaders(MPS)作为 PyTorch 的后端实现了这一点,并且可以通过新的 "mps" 设备来使用。
这将在 MPS 图形框架上映射计算图和神经图元,并使用 MPS 提供的优化内核。更多信息,请参阅官方文档 Introducing Accelerated PyTorch Training on Mac 和 MPS BACKEND。
我们强烈建议在你的 MacOS 机器上安装 PyTorch >= 1.13(在撰写本文时为最新版本)。对于基于 transformer 的模型, 它提供与模型正确性和性能改进相关的重大修复。有关更多详细信息,请参阅pytorch/pytorch#82707。
使用 Apple Silicon 芯片进行训练和推理的好处
- 使用户能够在本地训练更大的网络或批量数据。
- 由于统一内存架构,减少数据检索延迟,并为 GPU 提供对完整内存存储的直接访问。从而提高端到端性能。
- 降低与基于云的开发或需要额外本地 GPU 的成本。
先决条件:要安装带有 mps 支持的 torch,请按照这篇精彩的 Medium 文章操作 GPU-Acceleration Comes to PyTorch on M1 Macs。
用法:
如果可用,mps 设备将默认使用,类似于使用 cuda 设备的方式。因此,用户无需采取任何操作。例如,您可以使用以下命令在 Apple Silicon GPU 上运行官方的 Glue 文本分类任务(从根文件夹运行):
export TASK_NAME=mrpc
python examples/pytorch/text-classification/run_glue.py \
--model_name_or_path google-bert/bert-base-cased \
--task_name $TASK_NAME \
--do_train \
--do_eval \
--max_seq_length 128 \
--per_device_train_batch_size 32 \
--learning_rate 2e-5 \
--num_train_epochs 3 \
--output_dir /tmp/$TASK_NAME/ \
--overwrite_output_dir需要注意的一些注意事项
- 一些 PyTorch 操作尚未在 mps 中实现,将引发错误。解决此问题的一种方法是设置环境变量
PYTORCH_ENABLE_MPS_FALLBACK=1,它将把这些操作回退到 CPU 进行。然而,它仍然会抛出 UserWarning 信息。 - 分布式设置
gloo和nccl在mps设备上不起作用。这意味着当前只能使用mps设备类型的单个 GPU。
最后,请记住,🤗 Trainer 仅集成了 MPS 后端,因此如果你在使用 MPS 后端时遇到任何问题或有疑问,请在 PyTorch GitHub 上提交问题。
通过 Accelerate Launcher 使用 Trainer
Accelerate 现在支持 Trainer。用户可以期待以下内容:
- 他们可以继续使用 Trainer 的迭代,如 FSDP、DeepSpeed 等,而无需做任何更改。
- 现在可以在 Trainer 中使用 Accelerate Launcher(建议使用)。
通过 Accelerate Launcher 使用 Trainer 的步骤:
确保已安装 🤗 Accelerate,无论如何,如果没有它,你无法使用
Trainer。如果没有,请执行pip install accelerate。你可能还需要更新 Accelerate 的版本:pip install accelerate --upgrade。运行
accelerate config并填写问题。以下是一些加速配置的示例:a. DDP 多节点多 GPU 配置:
compute_environment: LOCAL_MACHINE distributed_type: MULTI_GPU downcast_bf16: 'no' gpu_ids: all machine_rank: 0 #change rank as per the node main_process_ip: 192.168.20.1 main_process_port: 9898 main_training_function: main mixed_precision: fp16 num_machines: 2 num_processes: 8 rdzv_backend: static same_network: true tpu_env: [] tpu_use_cluster: false tpu_use_sudo: false use_cpu: falseb. FSDP 配置:
compute_environment: LOCAL_MACHINE distributed_type: FSDP downcast_bf16: 'no' fsdp_config: fsdp_auto_wrap_policy: TRANSFORMER_BASED_WRAP fsdp_backward_prefetch_policy: BACKWARD_PRE fsdp_forward_prefetch: true fsdp_offload_params: false fsdp_sharding_strategy: 1 fsdp_state_dict_type: FULL_STATE_DICT fsdp_sync_module_states: true fsdp_transformer_layer_cls_to_wrap: BertLayer fsdp_use_orig_params: true machine_rank: 0 main_training_function: main mixed_precision: bf16 num_machines: 1 num_processes: 2 rdzv_backend: static same_network: true tpu_env: [] tpu_use_cluster: false tpu_use_sudo: false use_cpu: falsec. 指向文件的 DeepSpeed 配置:
compute_environment: LOCAL_MACHINE deepspeed_config: deepspeed_config_file: /home/user/configs/ds_zero3_config.json zero3_init_flag: true distributed_type: DEEPSPEED downcast_bf16: 'no' machine_rank: 0 main_training_function: main num_machines: 1 num_processes: 4 rdzv_backend: static same_network: true tpu_env: [] tpu_use_cluster: false tpu_use_sudo: false use_cpu: falsed. 使用 accelerate 插件的 DeepSpeed 配置:
compute_environment: LOCAL_MACHINE deepspeed_config: gradient_accumulation_steps: 1 gradient_clipping: 0.7 offload_optimizer_device: cpu offload_param_device: cpu zero3_init_flag: true zero_stage: 2 distributed_type: DEEPSPEED downcast_bf16: 'no' machine_rank: 0 main_training_function: main mixed_precision: bf16 num_machines: 1 num_processes: 4 rdzv_backend: static same_network: true tpu_env: [] tpu_use_cluster: false tpu_use_sudo: false use_cpu: false使用accelerate配置文件参数或启动器参数以外的参数运行Trainer脚本。以下是一个使用上述FSDP配置从accelerate启动器运行
run_glue.py的示例。
cd transformers
accelerate launch \
./examples/pytorch/text-classification/run_glue.py \
--model_name_or_path google-bert/bert-base-cased \
--task_name $TASK_NAME \
--do_train \
--do_eval \
--max_seq_length 128 \
--per_device_train_batch_size 16 \
--learning_rate 5e-5 \
--num_train_epochs 3 \
--output_dir /tmp/$TASK_NAME/ \
--overwrite_output_dir- 你也可以直接使用
accelerate launch的cmd参数。上面的示例将映射到:
cd transformers
accelerate launch --num_processes=2 \
--use_fsdp \
--mixed_precision=bf16 \
--fsdp_auto_wrap_policy=TRANSFORMER_BASED_WRAP \
--fsdp_transformer_layer_cls_to_wrap="BertLayer" \
--fsdp_sharding_strategy=1 \
--fsdp_state_dict_type=FULL_STATE_DICT \
./examples/pytorch/text-classification/run_glue.py
--model_name_or_path google-bert/bert-base-cased \
--task_name $TASK_NAME \
--do_train \
--do_eval \
--max_seq_length 128 \
--per_device_train_batch_size 16 \
--learning_rate 5e-5 \
--num_train_epochs 3 \
--output_dir /tmp/$TASK_NAME/ \
--overwrite_output_dir有关更多信息,请参阅 🤗 Accelerate CLI 指南:启动您的 🤗 Accelerate 脚本。
已移动的部分:
[ DeepSpeed | Installation | Deployment with multiple GPUs | Deployment with one GPU | Deployment in Notebooks | Configuration | Passing Configuration | Shared Configuration | ZeRO | ZeRO-2 Config | ZeRO-3 Config | NVMe Support | ZeRO-2 vs ZeRO-3 Performance | ZeRO-2 Example | ZeRO-3 Example | Optimizer | Scheduler | fp32 Precision | Automatic Mixed Precision | Batch Size | Gradient Accumulation | Gradient Clipping | Getting The Model Weights Out]
通过 NEFTune 提升微调性能
NEFTune 是一种提升聊天模型性能的技术,由 Jain 等人在论文“NEFTune: Noisy Embeddings Improve Instruction Finetuning” 中引入。该技术在训练过程中向embedding向量添加噪音。根据论文摘要:
使用 Alpaca 对 LLaMA-2-7B 进行标准微调,可以在 AlpacaEval 上达到 29.79%,而使用带有噪音embedding的情况下,性能提高至 64.69%。NEFTune 还在modern instruction数据集上大大优于基线。Evol-Instruct 训练的模型表现提高了 10%,ShareGPT 提高了 8%,OpenPlatypus 提高了 8%。即使像 LLaMA-2-Chat 这样通过 RLHF 进一步细化的强大模型,通过 NEFTune 的额外训练也能受益。
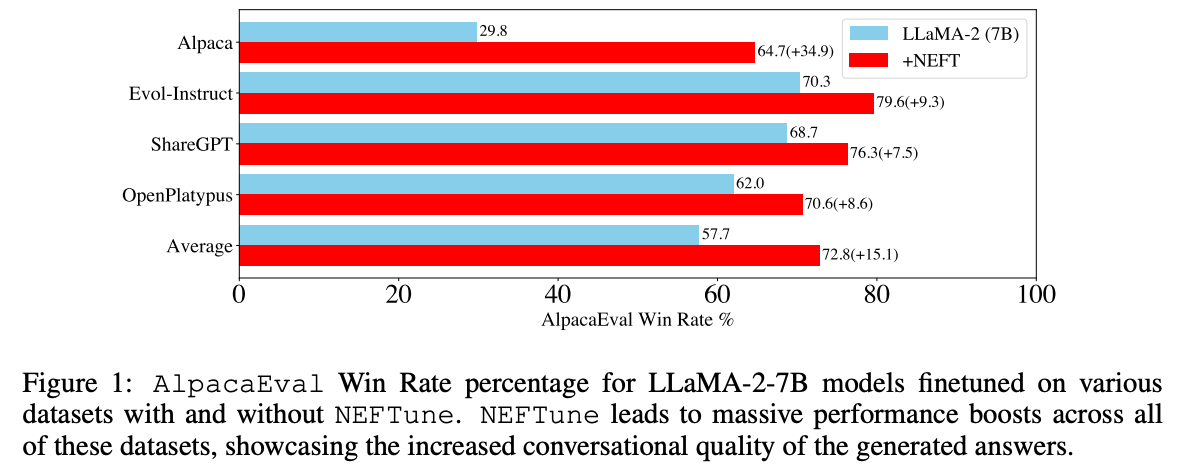
要在 Trainer 中使用它,只需在创建 TrainingArguments 实例时传递 neftune_noise_alpha。请注意,为了避免任何意外行为,NEFTune在训练后被禁止,以此恢复原始的embedding层。
from transformers import Trainer, TrainingArguments
args = TrainingArguments(..., neftune_noise_alpha=0.1)
trainer = Trainer(..., args=args)
...
trainer.train()