Transformers documentation
Text to speech
Text to speech
テキスト読み上げ (TTS) は、テキストから自然な音声を作成するタスクです。音声は複数の形式で生成できます。 言語と複数の話者向け。現在、いくつかのテキスト読み上げモデルが 🤗 Transformers で利用可能です。 Bark、MMS、VITS、および SpeechT5。
text-to-audioパイプライン (またはその別名 - text-to-speech) を使用して、音声を簡単に生成できます。 Bark などの一部のモデルは、
笑い、ため息、泣きなどの非言語コミュニケーションを生成したり、音楽を追加したりするように条件付けすることもできます。
Bark でtext-to-speechパイプラインを使用する方法の例を次に示します。
>>> from transformers import pipeline
>>> pipe = pipeline("text-to-speech", model="suno/bark-small")
>>> text = "[clears throat] This is a test ... and I just took a long pause."
>>> output = pipe(text)ノートブックで結果の音声を聞くために使用できるコード スニペットを次に示します。
>>> from IPython.display import Audio
>>> Audio(output["audio"], rate=output["sampling_rate"])Bark およびその他の事前トレーニングされた TTS モデルができることの詳細な例については、次のドキュメントを参照してください。 音声コース。
TTS モデルを微調整する場合、現在微調整できるのは SpeechT5 のみです。 SpeechT5 は、次の組み合わせで事前トレーニングされています。 音声からテキストへのデータとテキストから音声へのデータ。両方のテキストに共有される隠された表現の統一された空間を学習できるようにします。 そしてスピーチ。これは、同じ事前トレーニング済みモデルをさまざまなタスクに合わせて微調整できることを意味します。さらに、SpeechT5 X ベクトル スピーカーの埋め込みを通じて複数のスピーカーをサポートします。
このガイドの残りの部分では、次の方法を説明します。
- VoxPopuli のオランダ語 (
nl) 言語サブセット上の英語音声で元々トレーニングされた SpeechT5 を微調整します。 データセット。 - パイプラインを使用するか直接使用するかの 2 つの方法のいずれかで、洗練されたモデルを推論に使用します。
始める前に、必要なライブラリがすべてインストールされていることを確認してください。
pip install datasets soundfile speechbrain accelerate
SpeechT5 のすべての機能がまだ正式リリースにマージされていないため、ソースから 🤗Transformers をインストールします。
pip install git+https://github.com/huggingface/transformers.git
このガイドに従うには、GPU が必要です。ノートブックで作業している場合は、次の行を実行して GPU が利用可能かどうかを確認します。
!nvidia-smi
Hugging Face アカウントにログインして、モデルをアップロードしてコミュニティと共有することをお勧めします。プロンプトが表示されたら、トークンを入力してログインします。
>>> from huggingface_hub import notebook_login
>>> notebook_login()Load the dataset
VoxPopuli は、以下で構成される大規模な多言語音声コーパスです。 データは 2009 年から 2020 年の欧州議会のイベント記録をソースとしています。 15 件分のラベル付き音声文字起こしデータが含まれています。 ヨーロッパの言語。このガイドではオランダ語のサブセットを使用していますが、自由に別のサブセットを選択してください。
VoxPopuli またはその他の自動音声認識 (ASR) データセットは最適ではない可能性があることに注意してください。 TTS モデルをトレーニングするためのオプション。過剰なバックグラウンドノイズなど、ASR にとって有益となる機能は次のとおりです。 通常、TTS では望ましくありません。ただし、最高品質、多言語、マルチスピーカーの TTS データセットを見つけるのは非常に困難な場合があります。 挑戦的。
データをロードしましょう:
>>> from datasets import load_dataset, Audio
>>> dataset = load_dataset("facebook/voxpopuli", "nl", split="train")
>>> len(dataset)
20968微調整には 20968 個の例で十分です。 SpeechT5 はオーディオ データのサンプリング レートが 16 kHz であることを想定しているため、 データセット内の例がこの要件を満たしていることを確認してください。
dataset = dataset.cast_column("audio", Audio(sampling_rate=16000))Preprocess the data
使用するモデル チェックポイントを定義し、適切なプロセッサをロードすることから始めましょう。
>>> from transformers import SpeechT5Processor
>>> checkpoint = "microsoft/speecht5_tts"
>>> processor = SpeechT5Processor.from_pretrained(checkpoint)Text cleanup for SpeechT5 tokenization
まずはテキストデータをクリーンアップすることから始めます。テキストを処理するには、プロセッサのトークナイザー部分が必要です。
>>> tokenizer = processor.tokenizerデータセットの例には、raw_text機能と normalized_text機能が含まれています。テキスト入力としてどの機能を使用するかを決めるときは、
SpeechT5 トークナイザーには数値のトークンがないことを考慮してください。 normalized_textには数字が書かれています
テキストとして出力します。したがって、これはより適切であり、入力テキストとして normalized_text を使用することをお勧めします。
SpeechT5 は英語でトレーニングされているため、オランダ語のデータセット内の特定の文字を認識しない可能性があります。もし
残っているように、これらの文字は <unk>トークンに変換されます。ただし、オランダ語では、àなどの特定の文字は
音節を強調することに慣れています。テキストの意味を保持するために、この文字を通常のaに置き換えることができます。
サポートされていないトークンを識別するには、SpeechT5Tokenizerを使用してデータセット内のすべての一意の文字を抽出します。
文字をトークンとして扱います。これを行うには、以下を連結する extract_all_chars マッピング関数を作成します。
すべての例からの転写を 1 つの文字列にまとめ、それを文字セットに変換します。
すべての文字起こしが一度に利用できるように、dataset.map()でbatched=Trueとbatch_size=-1を必ず設定してください。
マッピング機能。
>>> def extract_all_chars(batch):
... all_text = " ".join(batch["normalized_text"])
... vocab = list(set(all_text))
... return {"vocab": [vocab], "all_text": [all_text]}
>>> vocabs = dataset.map(
... extract_all_chars,
... batched=True,
... batch_size=-1,
... keep_in_memory=True,
... remove_columns=dataset.column_names,
... )
>>> dataset_vocab = set(vocabs["vocab"][0])
>>> tokenizer_vocab = {k for k, _ in tokenizer.get_vocab().items()}これで、2 つの文字セットができました。1 つはデータセットの語彙を持ち、もう 1 つはトークナイザーの語彙を持ちます。 データセット内でサポートされていない文字を特定するには、これら 2 つのセットの差分を取ることができます。結果として set には、データセットにはあるがトークナイザーには含まれていない文字が含まれます。
>>> dataset_vocab - tokenizer_vocab
{' ', 'à', 'ç', 'è', 'ë', 'í', 'ï', 'ö', 'ü'}前の手順で特定されたサポートされていない文字を処理するには、これらの文字を
有効なトークン。スペースはトークナイザーですでに ▁ に置き換えられているため、個別に処理する必要がないことに注意してください。
>>> replacements = [
... ("à", "a"),
... ("ç", "c"),
... ("è", "e"),
... ("ë", "e"),
... ("í", "i"),
... ("ï", "i"),
... ("ö", "o"),
... ("ü", "u"),
... ]
>>> def cleanup_text(inputs):
... for src, dst in replacements:
... inputs["normalized_text"] = inputs["normalized_text"].replace(src, dst)
... return inputs
>>> dataset = dataset.map(cleanup_text)テキスト内の特殊文字を扱ったので、今度は音声データに焦点を移します。
Speakers
VoxPopuli データセットには複数の話者の音声が含まれていますが、データセットには何人の話者が含まれているのでしょうか?に これを決定すると、一意の話者の数と、各話者がデータセットに寄与する例の数を数えることができます。 データセットには合計 20,968 個の例が含まれており、この情報により、分布をより深く理解できるようになります。 講演者とデータ内の例。
>>> from collections import defaultdict
>>> speaker_counts = defaultdict(int)
>>> for speaker_id in dataset["speaker_id"]:
... speaker_counts[speaker_id] += 1ヒストグラムをプロットすると、各話者にどれだけのデータがあるかを把握できます。
>>> import matplotlib.pyplot as plt
>>> plt.figure()
>>> plt.hist(speaker_counts.values(), bins=20)
>>> plt.ylabel("Speakers")
>>> plt.xlabel("Examples")
>>> plt.show()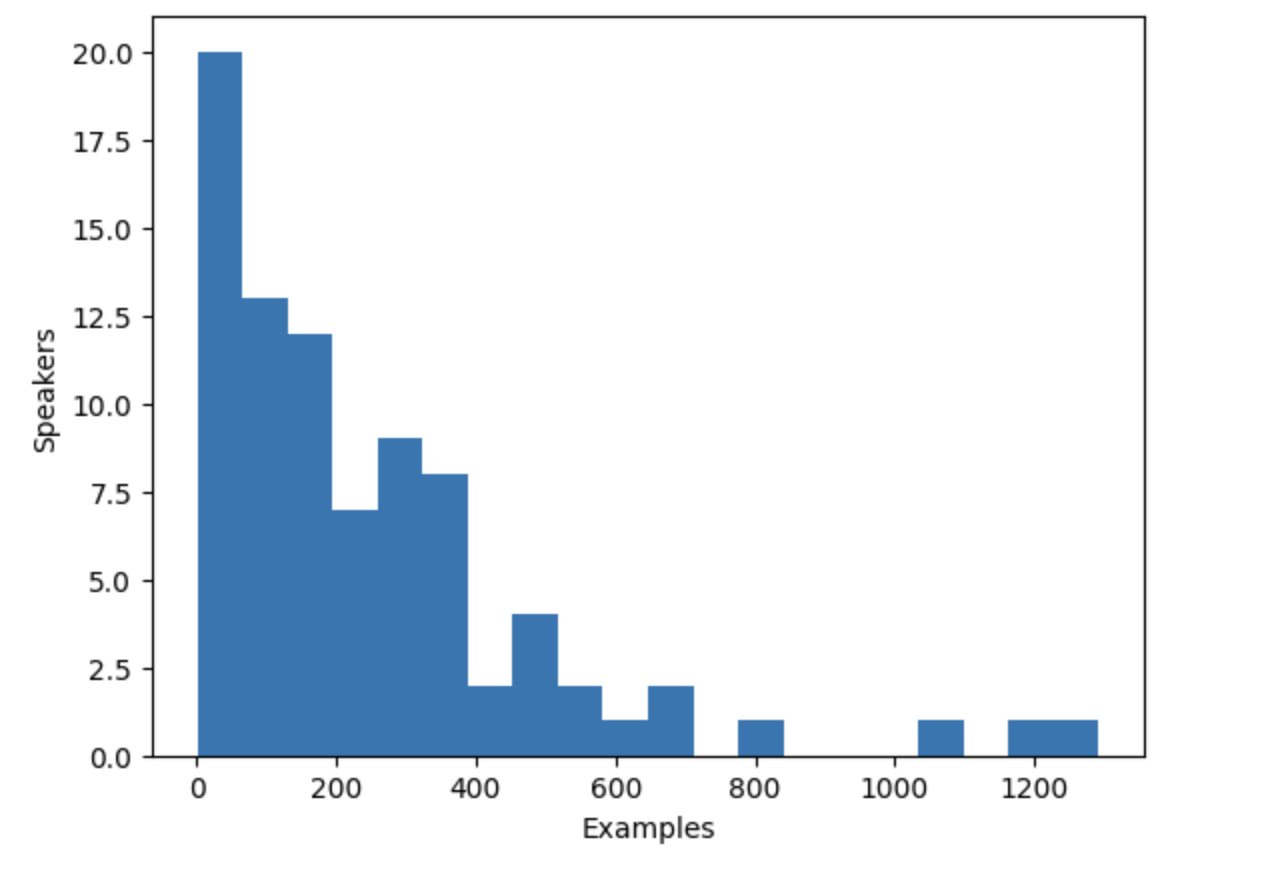
ヒストグラムから、データセット内の話者の約 3 分の 1 の例が 100 未満であることがわかります。 約 10 人の講演者が 500 以上の例を持っています。トレーニング効率を向上させ、データセットのバランスをとるために、次のことを制限できます。 100 ~ 400 個の例を含むデータを講演者に提供します。
>>> def select_speaker(speaker_id):
... return 100 <= speaker_counts[speaker_id] <= 400
>>> dataset = dataset.filter(select_speaker, input_columns=["speaker_id"])残りのスピーカーの数を確認してみましょう。
>>> len(set(dataset["speaker_id"]))
42残りの例がいくつあるか見てみましょう。
>>> len(dataset)
9973約 40 人のユニークな講演者からの 10,000 弱の例が残りますが、これで十分です。
例が少ないスピーカーの中には、例が長い場合、実際にはより多くの音声が利用できる場合があることに注意してください。しかし、 各話者の音声の合計量を決定するには、データセット全体をスキャンする必要があります。 各オーディオ ファイルのロードとデコードを伴う時間のかかるプロセス。そのため、ここではこのステップをスキップすることにしました。
Speaker embeddings
TTS モデルが複数のスピーカーを区別できるようにするには、サンプルごとにスピーカーの埋め込みを作成する必要があります。 スピーカーの埋め込みは、特定のスピーカーの音声特性をキャプチャするモデルへの追加入力です。 これらのスピーカー埋め込みを生成するには、事前トレーニングされた spkrec-xvect-voxceleb を使用します。 SpeechBrain のモデル。
入力オーディオ波形を受け取り、512 要素のベクトルを出力する関数 create_speaker_embedding() を作成します。
対応するスピーカー埋め込みが含まれます。
>>> import os
>>> import torch
>>> from speechbrain.pretrained import EncoderClassifier
>>> spk_model_name = "speechbrain/spkrec-xvect-voxceleb"
>>> device = "cuda" if torch.cuda.is_available() else "cpu"
>>> speaker_model = EncoderClassifier.from_hparams(
... source=spk_model_name,
... run_opts={"device": device},
... savedir=os.path.join("/tmp", spk_model_name),
... )
>>> def create_speaker_embedding(waveform):
... with torch.no_grad():
... speaker_embeddings = speaker_model.encode_batch(torch.tensor(waveform))
... speaker_embeddings = torch.nn.functional.normalize(speaker_embeddings, dim=2)
... speaker_embeddings = speaker_embeddings.squeeze().cpu().numpy()
... return speaker_embeddingsspeechbrain/spkrec-xvect-voxcelebモデルは、VoxCeleb からの英語音声でトレーニングされたことに注意することが重要です。
データセットですが、このガイドのトレーニング例はオランダ語です。このモデルは今後も生成されると信じていますが、
オランダ語のデータセットに適切な話者埋め込みを行っても、この仮定はすべての場合に当てはまらない可能性があります。
最適な結果を得るには、最初にターゲット音声で X ベクトル モデルをトレーニングすることをお勧めします。これにより、モデルが確実に オランダ語に存在する独特の音声特徴をよりよく捉えることができます。
Processing the dataset
最後に、モデルが期待する形式にデータを処理しましょう。を取り込む prepare_dataset 関数を作成します。
これは 1 つの例であり、SpeechT5Processor オブジェクトを使用して入力テキストをトークン化し、ターゲット オーディオをログメル スペクトログラムにロードします。
また、追加の入力としてスピーカーの埋め込みも追加する必要があります。
>>> def prepare_dataset(example):
... audio = example["audio"]
... example = processor(
... text=example["normalized_text"],
... audio_target=audio["array"],
... sampling_rate=audio["sampling_rate"],
... return_attention_mask=False,
... )
... # strip off the batch dimension
... example["labels"] = example["labels"][0]
... # use SpeechBrain to obtain x-vector
... example["speaker_embeddings"] = create_speaker_embedding(audio["array"])
... return example単一の例を見て、処理が正しいことを確認します。
>>> processed_example = prepare_dataset(dataset[0])
>>> list(processed_example.keys())
['input_ids', 'labels', 'stop_labels', 'speaker_embeddings']スピーカーのエンベディングは 512 要素のベクトルである必要があります。
>>> processed_example["speaker_embeddings"].shape
(512,)ラベルは、80 メル ビンを含むログメル スペクトログラムである必要があります。
>>> import matplotlib.pyplot as plt
>>> plt.figure()
>>> plt.imshow(processed_example["labels"].T)
>>> plt.show()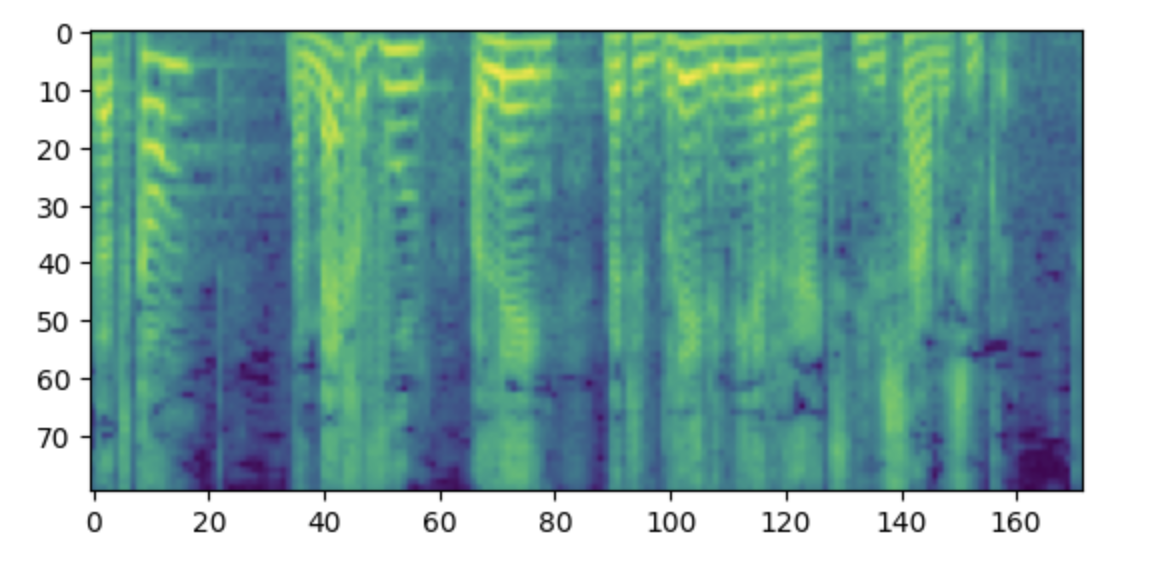
補足: このスペクトログラムがわかりにくいと感じる場合は、低周波を配置する規則に慣れていることが原因である可能性があります。 プロットの下部に高周波、上部に高周波が表示されます。ただし、matplotlib ライブラリを使用してスペクトログラムを画像としてプロットする場合、 Y 軸が反転され、スペクトログラムが上下逆に表示されます。
次に、処理関数をデータセット全体に適用します。これには 5 ~ 10 分かかります。
>>> dataset = dataset.map(prepare_dataset, remove_columns=dataset.column_names)データセット内の一部の例が、モデルが処理できる最大入力長 (600 トークン) を超えていることを示す警告が表示されます。 それらの例をデータセットから削除します。ここではさらに進んで、より大きなバッチ サイズを可能にするために、200 トークンを超えるものはすべて削除します。
>>> def is_not_too_long(input_ids):
... input_length = len(input_ids)
... return input_length < 200
>>> dataset = dataset.filter(is_not_too_long, input_columns=["input_ids"])
>>> len(dataset)
8259次に、基本的なトレーニング/テスト分割を作成します。
>>> dataset = dataset.train_test_split(test_size=0.1)Data collator
複数の例を 1 つのバッチに結合するには、カスタム データ照合器を定義する必要があります。このコレーターは、短いシーケンスをパディングで埋め込みます。
トークンを使用して、すべての例が同じ長さになるようにします。スペクトログラム ラベルの場合、埋め込まれた部分は特別な値 -100 に置き換えられます。この特別な価値は
スペクトログラム損失を計算するときに、スペクトログラムのその部分を無視するようにモデルに指示します。
>>> from dataclasses import dataclass
>>> from typing import Any, Dict, List, Union
>>> @dataclass
... class TTSDataCollatorWithPadding:
... processor: Any
... def __call__(self, features: List[Dict[str, Union[List[int], torch.Tensor]]]) -> Dict[str, torch.Tensor]:
... input_ids = [{"input_ids": feature["input_ids"]} for feature in features]
... label_features = [{"input_values": feature["labels"]} for feature in features]
... speaker_features = [feature["speaker_embeddings"] for feature in features]
... # collate the inputs and targets into a batch
... batch = processor.pad(input_ids=input_ids, labels=label_features, return_tensors="pt")
... # replace padding with -100 to ignore loss correctly
... batch["labels"] = batch["labels"].masked_fill(batch.decoder_attention_mask.unsqueeze(-1).ne(1), -100)
... # not used during fine-tuning
... del batch["decoder_attention_mask"]
... # round down target lengths to multiple of reduction factor
... if model.config.reduction_factor > 1:
... target_lengths = torch.tensor([len(feature["input_values"]) for feature in label_features])
... target_lengths = target_lengths.new(
... [length - length % model.config.reduction_factor for length in target_lengths]
... )
... max_length = max(target_lengths)
... batch["labels"] = batch["labels"][:, :max_length]
... # also add in the speaker embeddings
... batch["speaker_embeddings"] = torch.tensor(speaker_features)
... return batchSpeechT5 では、モデルのデコーダ部分への入力が 2 分の 1 に削減されます。つまり、すべてのデータが破棄されます。 ターゲット シーケンスからの他のタイムステップ。次に、デコーダは 2 倍の長さのシーケンスを予測します。オリジナル以来 ターゲット シーケンスの長さが奇数である可能性がある場合、データ照合機能はバッチの最大長を切り捨てて、 2の倍数。
>>> data_collator = TTSDataCollatorWithPadding(processor=processor)Train the model
プロセッサのロードに使用したのと同じチェックポイントから事前トレーニングされたモデルをロードします。
>>> from transformers import SpeechT5ForTextToSpeech
>>> model = SpeechT5ForTextToSpeech.from_pretrained(checkpoint)use_cache=Trueオプションは、勾配チェックポイントと互換性がありません。トレーニングのために無効にします。
>>> model.config.use_cache = Falseトレーニング引数を定義します。ここでは、トレーニング プロセス中に評価メトリクスを計算していません。代わりに、 損失だけを見てください。
>>> from transformers import Seq2SeqTrainingArguments
>>> training_args = Seq2SeqTrainingArguments(
... output_dir="speecht5_finetuned_voxpopuli_nl", # change to a repo name of your choice
... per_device_train_batch_size=4,
... gradient_accumulation_steps=8,
... learning_rate=1e-5,
... warmup_steps=500,
... max_steps=4000,
... gradient_checkpointing=True,
... fp16=True,
... eval_strategy="steps",
... per_device_eval_batch_size=2,
... save_steps=1000,
... eval_steps=1000,
... logging_steps=25,
... report_to=["tensorboard"],
... load_best_model_at_end=True,
... greater_is_better=False,
... label_names=["labels"],
... push_to_hub=True,
... )Trainerオブジェクトをインスタンス化し、モデル、データセット、データ照合器をそれに渡します。
>>> from transformers import Seq2SeqTrainer
>>> trainer = Seq2SeqTrainer(
... args=training_args,
... model=model,
... train_dataset=dataset["train"],
... eval_dataset=dataset["test"],
... data_collator=data_collator,
... tokenizer=processor,
... )これで、トレーニングを開始する準備が整いました。トレーニングには数時間かかります。 GPU に応じて、
トレーニングを開始するときに、CUDA の「メモリ不足」エラーが発生する可能性があります。この場合、減らすことができます
per_device_train_batch_sizeを 2 倍に増分し、gradient_accumulation_stepsを 2 倍に増やして補正します。
>>> trainer.train()パイプラインでチェックポイントを使用できるようにするには、必ずプロセッサをチェックポイントとともに保存してください。
>>> processor.save_pretrained("YOUR_ACCOUNT_NAME/speecht5_finetuned_voxpopuli_nl")最終モデルを 🤗 ハブにプッシュします。
>>> trainer.push_to_hub()Inference
Inference with a pipeline
モデルを微調整したので、それを推論に使用できるようになりました。
まず、対応するパイプラインでそれを使用する方法を見てみましょう。 "text-to-speech" パイプラインを作成しましょう
チェックポイント:
>>> from transformers import pipeline
>>> pipe = pipeline("text-to-speech", model="YOUR_ACCOUNT_NAME/speecht5_finetuned_voxpopuli_nl")ナレーションを希望するオランダ語のテキストを選択してください。例:
>>> text = "hallo allemaal, ik praat nederlands. groetjes aan iedereen!"パイプラインで SpeechT5 を使用するには、スピーカーの埋め込みが必要です。テスト データセットの例から取得してみましょう。
>>> example = dataset["test"][304]
>>> speaker_embeddings = torch.tensor(example["speaker_embeddings"]).unsqueeze(0)これで、テキストとスピーカーの埋め込みをパイプラインに渡すことができ、残りはパイプラインが処理します。
>>> forward_params = {"speaker_embeddings": speaker_embeddings}
>>> output = pipe(text, forward_params=forward_params)
>>> output
{'audio': array([-6.82714235e-05, -4.26525949e-04, 1.06134125e-04, ...,
-1.22392643e-03, -7.76011671e-04, 3.29112721e-04], dtype=float32),
'sampling_rate': 16000}その後、結果を聞くことができます。
>>> from IPython.display import Audio
>>> Audio(output['audio'], rate=output['sampling_rate']) Run inference manually
パイプラインを使用しなくても同じ推論結果を得ることができますが、より多くの手順が必要になります。
🤗 ハブからモデルをロードします。
>>> model = SpeechT5ForTextToSpeech.from_pretrained("YOUR_ACCOUNT/speecht5_finetuned_voxpopuli_nl")テスト データセットから例を選択して、スピーカーの埋め込みを取得します。
>>> example = dataset["test"][304]
>>> speaker_embeddings = torch.tensor(example["speaker_embeddings"]).unsqueeze(0)入力テキストを定義し、トークン化します。
>>> text = "hallo allemaal, ik praat nederlands. groetjes aan iedereen!"
>>> inputs = processor(text=text, return_tensors="pt")モデルを使用してスペクトログラムを作成します。
>>> spectrogram = model.generate_speech(inputs["input_ids"], speaker_embeddings)次のことを行う場合は、スペクトログラムを視覚化します。
>>> plt.figure()
>>> plt.imshow(spectrogram.T)
>>> plt.show()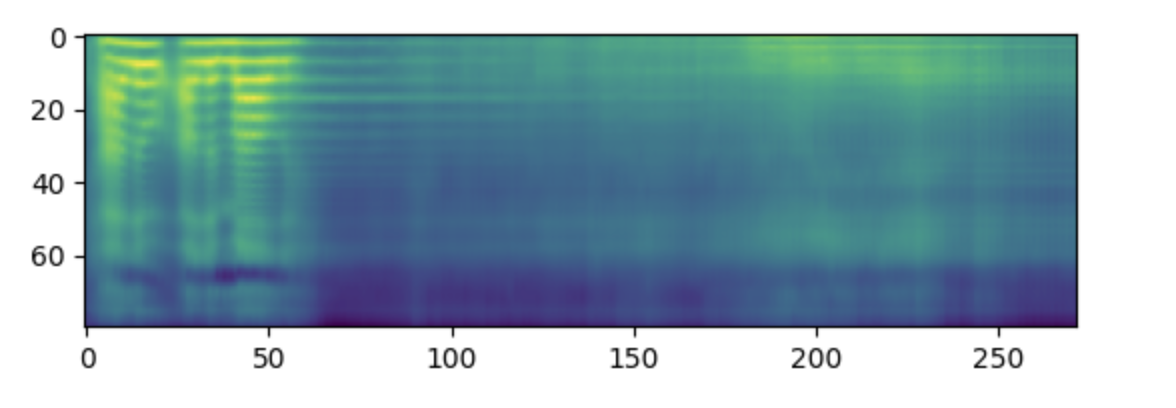
最後に、ボコーダーを使用してスペクトログラムをサウンドに変換します。
>>> with torch.no_grad():
... speech = vocoder(spectrogram)
>>> from IPython.display import Audio
>>> Audio(speech.numpy(), rate=16000)私たちの経験では、このモデルから満足のいく結果を得るのは難しい場合があります。スピーカーの品質 埋め込みは重要な要素であるようです。 SpeechT5 は英語の x ベクトルで事前トレーニングされているため、最高のパフォーマンスを発揮します 英語スピーカーの埋め込みを使用する場合。合成音声の音質が悪い場合は、別のスピーカー埋め込みを使用してみてください。
トレーニング期間を長くすると、結果の質も向上する可能性があります。それでも、そのスピーチは明らかに英語ではなくオランダ語です。
話者の音声特性をキャプチャします (例の元の音声と比較)。
もう 1 つ実験すべきことは、モデルの構成です。たとえば、config.reduction_factor = 1を使用してみてください。
これにより結果が改善されるかどうかを確認してください。
最後に、倫理的配慮を考慮することが不可欠です。 TTS テクノロジーには数多くの有用な用途がありますが、 また、知らないうちに誰かの声を偽装するなど、悪意のある目的に使用される可能性もあります。お願いします TTS は賢明かつ責任を持って使用してください。
< > Update on GitHub