Audio Course documentation
Pre-trained models for text-to-speech
Pre-trained models for text-to-speech
Compared to ASR (automatic speech recognition) and audio classification tasks, there are significantly fewer pre-trained model checkpoints available. On the 🤗 Hub, you’ll find close to 300 suitable checkpoints. Among these pre-trained models we’ll focus on two architectures that are readily available for you in the 🤗 Transformers library - SpeechT5 and Massive Multilingual Speech (MMS). In this section, we’ll explore how to use these pre-trained models in the Transformers library for TTS.
SpeechT5
SpeechT5 is a model published by Junyi Ao et al. from Microsoft that is capable of handling a range of speech tasks. While in this unit, we focus on the text-to-speech aspect, this model can be tailored to speech-to-text tasks (automatic speech recognition or speaker identification), as well as speech-to-speech (e.g. speech enhancement or converting between different voices). This is due to how the model is designed and pre-trained.
At the heart of SpeechT5 is a regular Transformer encoder-decoder model. Just like any other Transformer, the encoder-decoder network models a sequence-to-sequence transformation using hidden representations. This Transformer backbone is the same for all tasks SpeechT5 supports.
This Transformer is complemented with six modal-specific (speech/text) pre-nets and post-nets. The input speech or text (depending on the task) is preprocessed through a corresponding pre-net to obtain the hidden representations that Transformer can use. The Transformer’s output is then passed to a post-net that will use it to generate the output in the target modality.
This is what the architecture looks like (image from the original paper):
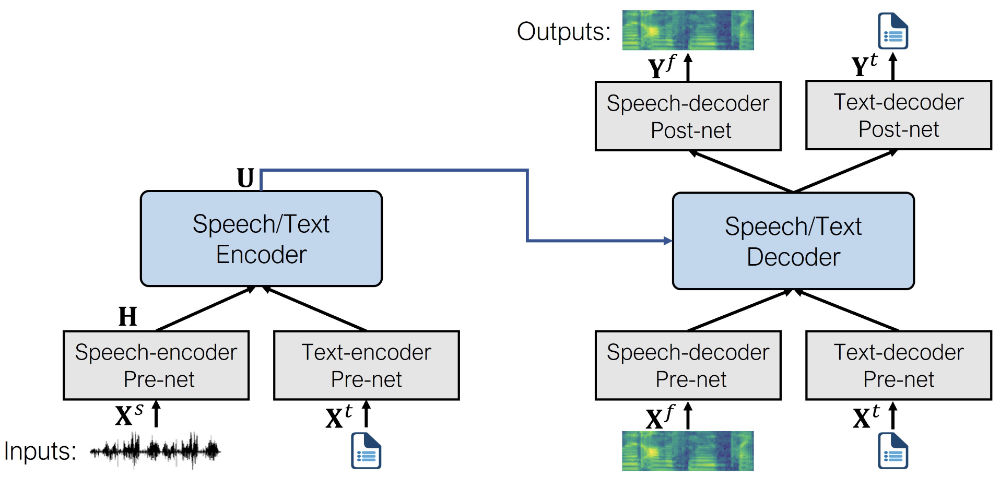
SpeechT5 is first pre-trained using large-scale unlabeled speech and text data, to acquire a unified representation of different modalities. During the pre-training phase all pre-nets and post-nets are used simultaneously.
After pre-training, the entire encoder-decoder backbone is fine-tuned for each individual task. At this step, only the pre-nets and post-nets relevant to the specific task are employed. For example, to use SpeechT5 for text-to-speech, you’d need the text encoder pre-net for the text inputs and the speech decoder pre- and post-nets for the speech outputs.
This approach allows to obtain several models fine-tuned for different speech tasks that all benefit from the initial pre-training on unlabeled data.
Even though the fine-tuned models start out using the same set of weights from the shared pre-trained model, the final versions are all quite different in the end. You can’t take a fine-tuned ASR model and swap out the pre-nets and post-net to get a working TTS model, for example. SpeechT5 is flexible, but not that flexible ;)
Let’s see what are the pre- and post-nets that SpeechT5 uses for the TTS task specifically:
- Text encoder pre-net: A text embedding layer that maps text tokens to the hidden representations that the encoder expects. This is similar to what happens in an NLP model such as BERT.
- Speech decoder pre-net: This takes a log mel spectrogram as input and uses a sequence of linear layers to compress the spectrogram into hidden representations.
- Speech decoder post-net: This predicts a residual to add to the output spectrogram and is used to refine the results.
When combined, this is what SpeechT5 architecture for text-to-speech looks like:
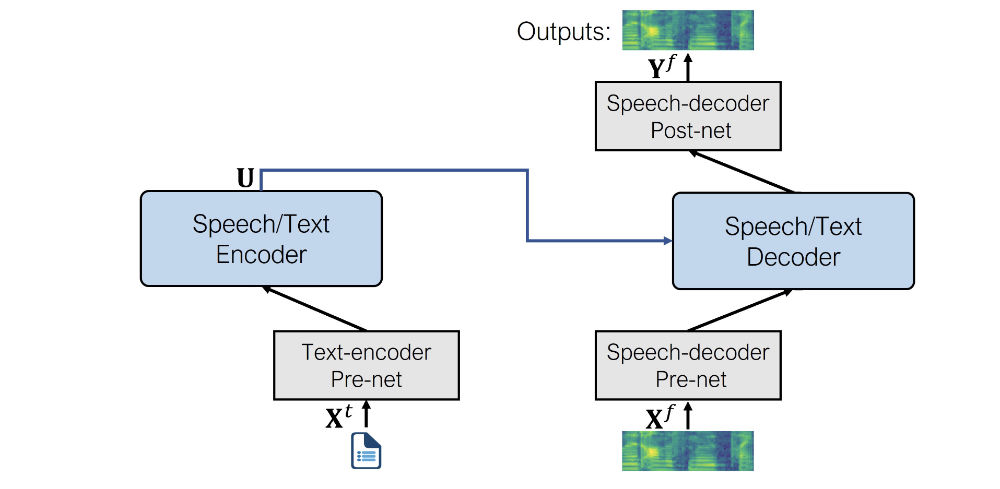
As you can see, the output is a log mel spectrogram and not a final waveform. If you recall, we briefly touched on this topic in Unit 3. It is common for models that generate audio to produce a log mel spectrogram, which needs to be converted to a waveform with an additional neural network known as a vocoder.
Let’s see how you could do that.
First, let’s load the fine-tuned TTS SpeechT5 model from the 🤗 Hub, along with the processor object used for tokenization and feature extraction:
from transformers import SpeechT5Processor, SpeechT5ForTextToSpeech
processor = SpeechT5Processor.from_pretrained("microsoft/speecht5_tts")
model = SpeechT5ForTextToSpeech.from_pretrained("microsoft/speecht5_tts")Next, tokenize the input text.
inputs = processor(text="Don't count the days, make the days count.", return_tensors="pt")The SpeechT5 TTS model is not limited to creating speech for a single speaker. Instead, it uses so-called speaker embeddings that capture a particular speaker’s voice characteristics.
Speaker embeddings is a method of representing a speaker’s identity in a compact way, as a vector of fixed size, regardless of the length of the utterance. These embeddings capture essential information about a speaker’s voice, accent, intonation, and other unique characteristics that distinguish one speaker from another. Such embeddings can be used for speaker verification, speaker diarization, speaker identification, and more. The most common techniques for generating speaker embeddings include:
- I-Vectors (identity vectors): I-Vectors are based on a Gaussian mixture model (GMM). They represent speakers as low-dimensional fixed-length vectors derived from the statistics of a speaker-specific GMM, and are obtained in unsupervised manner.
- X-Vectors: X-Vectors are derived using deep neural networks (DNNs) and capture frame-level speaker information by incorporating temporal context.
X-Vectors are a state-of-the-art method that shows superior performance on evaluation datasets compared to I-Vectors. The deep neural network is used to obtain X-Vectors: it trains to discriminate between speakers, and maps variable-length utterances to fixed-dimensional embeddings. You can also load an X-Vector speaker embedding that has been computed ahead of time, which will encapsulate the speaking characteristics of a particular speaker.
Let’s load such a speaker embedding from a dataset on the Hub. The embeddings were obtained from the CMU ARCTIC dataset using this script, but any X-Vector embedding should work.
from datasets import load_dataset
embeddings_dataset = load_dataset("Matthijs/cmu-arctic-xvectors", split="validation")
import torch
speaker_embeddings = torch.tensor(embeddings_dataset[7306]["xvector"]).unsqueeze(0)The speaker embedding is a tensor of shape (1, 512). This particular speaker embedding describes a female voice.
At this point we already have enough inputs to generate a log mel spectrogram as an output, you can do it like this:
spectrogram = model.generate_speech(inputs["input_ids"], speaker_embeddings)This outputs a tensor of shape (140, 80) containing a log mel spectrogram. The first dimension is the sequence length, and it may vary between runs as the speech decoder pre-net always applies dropout to the input sequence. This adds a bit of random variability to the generated speech.
However, if we are looking to generate speech waveform, we need to specify a vocoder to use for the spectrogram to waveform conversion. In theory, you can use any vocoder that works on 80-bin mel spectrograms. Conveniently, 🤗 Transformers offers a vocoder based on HiFi-GAN. Its weights were kindly provided by the original authors of SpeechT5.
HiFi-GAN is a state-of-the-art generative adversarial network (GAN) designed for high-fidelity speech synthesis. It is capable of generating high-quality and realistic audio waveforms from spectrogram inputs.
On a high level, HiFi-GAN consists of one generator and two discriminators. The generator is a fully convolutional neural network that takes a mel-spectrogram as input and learns to produce raw audio waveforms. The discriminators’ role is to distinguish between real and generated audio. The two discriminators focus on different aspects of the audio.
HiFi-GAN is trained on a large dataset of high-quality audio recordings. It uses a so-called adversarial training, where the generator and discriminator networks compete against each other. Initially, the generator produces low-quality audio, and the discriminator can easily differentiate it from real audio. As training progresses, the generator improves its output, aiming to fool the discriminator. The discriminator, in turn, becomes more accurate in distinguishing real and generated audio. This adversarial feedback loop helps both networks improve over time. Ultimately, HiFi-GAN learns to generate high-fidelity audio that closely resembles the characteristics of the training data.
Loading the vocoder is as easy as any other 🤗 Transformers model.
from transformers import SpeechT5HifiGan
vocoder = SpeechT5HifiGan.from_pretrained("microsoft/speecht5_hifigan")Now all you need to do is pass it as an argument when generating speech, and the outputs will be automatically converted to the speech waveform.
speech = model.generate_speech(inputs["input_ids"], speaker_embeddings, vocoder=vocoder)Let’s listen to the result. The sample rate used by SpeechT5 is always 16 kHz.
from IPython.display import Audio
Audio(speech, rate=16000)Neat!
Feel free to play with the SpeechT5 text-to-speech demo, explore other voices, experiment with inputs. Note that this pre-trained checkpoint only supports English language:
Bark
Bark is a transformer-based text-to-speech model proposed by Suno AI in suno-ai/bark.
Unlike SpeechT5, Bark generates raw speech waveforms directly, eliminating the need for a separate vocoder during inference – it’s already integrated. This efficiency is achieved through the utilization of Encodec, which serves as both a codec and a compression tool.
With Encodec, you can compress audio into a lightweight format to reduce memory usage and subsequently decompress it to restore the original audio. This compression process is facilitated by 8 codebooks, each consisting of integer vectors. Think of these codebooks as representations or embeddings of the audio in integer form. It’s important to note that each successive codebook improves the quality of the audio reconstruction from the previous codebooks. As codebooks are integer vectors, they can be learned by transformer models, which are very efficient in this task. This is what Bark was specifically trained to do.
To be more specific, Bark is made of 4 main models:
BarkSemanticModel(also referred to as the ‘text’ model): a causal auto-regressive transformer model that takes as input tokenized text, and predicts semantic text tokens that capture the meaning of the text.BarkCoarseModel(also referred to as the ‘coarse acoustics’ model): a causal autoregressive transformer, that takes as input the results of theBarkSemanticModelmodel. It aims at predicting the first two audio codebooks necessary for EnCodec.BarkFineModel(the ‘fine acoustics’ model), this time a non-causal autoencoder transformer, which iteratively predicts the last codebooks based on the sum of the previous codebooks embeddings.- having predicted all the codebook channels from the
EncodecModel, Bark uses it to decode the output audio array.
It should be noted that each of the first three modules can support conditional speaker embeddings to condition the output sound according to specific predefined voice.
Bark is an highly-controllable text-to-speech model, meaning you can use with various settings, as we are going to see.
Before everything, load the model and its processor.
The processor role here is two-sides:
- It is used to tokenize the input text, i.e. to cut it into small pieces that the model can understand.
- It stores speaker embeddings, i.e voice presets that can condition the generation.
from transformers import BarkModel, BarkProcessor
model = BarkModel.from_pretrained("suno/bark-small")
processor = BarkProcessor.from_pretrained("suno/bark-small")Bark is very versatile and can generate audio conditioned by a speaker embeddings library which can be loaded via the processor.
# add a speaker embedding
inputs = processor("This is a test!", voice_preset="v2/en_speaker_3")
speech_output = model.generate(**inputs).cpu().numpy()It can also generate ready-to-use multilingual speeches, such as French and Chinese. You can find a list of supported languages here. Unlike MMS, discussed below, it is not necessary to specify the language used, but simply adapt the input text to the corresponding language.
# try it in French, let's also add a French speaker embedding
inputs = processor("C'est un test!", voice_preset="v2/fr_speaker_1")
speech_output = model.generate(**inputs).cpu().numpy()The model can also generate non-verbal communications such as laughing, sighing and crying. You just have to modify the input text with corresponding cues such as [clears throat], [laughter], or ....
inputs = processor(
"[clears throat] This is a test ... and I just took a long pause.",
voice_preset="v2/fr_speaker_1",
)
speech_output = model.generate(**inputs).cpu().numpy()Bark can even generate music. You can help by adding ♪ musical notes ♪ around your words.
inputs = processor(
"♪ In the mighty jungle, I'm trying to generate barks.",
)
speech_output = model.generate(**inputs).cpu().numpy()In addition to all these features, Bark supports batch processing, which means you can process several text entries at the same time, at the expense of more intensive computation. On some hardware, such as GPUs, batching enables faster overall generation, which means it can be faster to generate samples all at once than to generate them one by one.
Let’s try generating a few examples:
input_list = [
"[clears throat] Hello uh ..., my dog is cute [laughter]",
"Let's try generating speech, with Bark, a text-to-speech model",
"♪ In the jungle, the mighty jungle, the lion barks tonight ♪",
]
# also add a speaker embedding
inputs = processor(input_list, voice_preset="v2/en_speaker_3")
speech_output = model.generate(**inputs).cpu().numpy()Let’s listen to the outputs one by one.
First one:
from IPython.display import Audio
sampling_rate = model.generation_config.sample_rate
Audio(speech_output[0], rate=sampling_rate)Second one:
Audio(speech_output[1], rate=sampling_rate)Third one:
Audio(speech_output[2], rate=sampling_rate)Bark, like other 🤗 Transformers models, can be optimized in just a few lines of code regarding speed and memory impact. To find out how, click on this colab demonstration notebook.
Massive Multilingual Speech (MMS)
What if you are looking for a pre-trained model in a language other than English? Massive Multilingual Speech (MMS) is another model that covers an array of speech tasks, however, it supports a large number of languages. For instance, it can synthesize speech in over 1,100 languages.
MMS for text-to-speech is based on VITS Kim et al., 2021, which is one of the state-of-the-art TTS approaches.
VITS is a speech generation network that converts text into raw speech waveforms. It works like a conditional variational auto-encoder, estimating audio features from the input text. First, acoustic features, represented as spectrograms, are generated. The waveform is then decoded using transposed convolutional layers adapted from HiFi-GAN. During inference, the text encodings are upsampled and transformed into waveforms using the flow module and HiFi-GAN decoder. Like Bark, there’s no need for a vocoder, as waveforms are generated directly.
MMS model has been added to 🤗 Transformers very recently, so you will have to install the library from source:pip install git+https://github.com/huggingface/transformers.git
Let’s give MMS a go, and see how we can synthesize speech in a language other than English, e.g. German. First, we’ll load the model checkpoint and the tokenizer for the correct language:
from transformers import VitsModel, VitsTokenizer
model = VitsModel.from_pretrained("facebook/mms-tts-deu")
tokenizer = VitsTokenizer.from_pretrained("facebook/mms-tts-deu")You may notice that to load the MMS model you need to use VitsModel and VitsTokenizer. This is because MMS for text-to-speech
is based on the VITS model as mentioned earlier.
Let’s pick an example text in German, like these first two lines from a children’s song:
text_example = (
"Ich bin Schnappi das kleine Krokodil, komm aus Ägypten das liegt direkt am Nil."
)To generate a waveform output, preprocess the text with the tokenizer, and pass it to the model:
import torch
inputs = tokenizer(text_example, return_tensors="pt")
input_ids = inputs["input_ids"]
with torch.no_grad():
outputs = model(input_ids)
speech = outputs["waveform"]Let’s listen to it:
from IPython.display import Audio
Audio(speech, rate=16000)Wunderbar! If you’d like to try MMS with another language, find other suitable vits checkpoints on 🤗 Hub.
Now let’s see how you can fine-tune a TTS model yourself!
Update on GitHub