How to accelerate training with ONNX Runtime
Optimum integrates ONNX Runtime Training through an ORTTrainer API that extends Trainer in Transformers.
With this extension, training time can be reduced by more than 35% for many popular Hugging Face models compared to PyTorch under eager mode.
ORTTrainer and ORTSeq2SeqTrainer APIs make it easy to compose ONNX Runtime (ORT) with other features in Trainer.
It contains feature-complete training loop and evaluation loop, and supports hyperparameter search, mixed-precision training and distributed training with multiple NVIDIA
and AMD GPUs.
With the ONNX Runtime backend, ORTTrainer and ORTSeq2SeqTrainer take advantage of:
- Computation graph optimizations: constant foldings, node eliminations, node fusions
- Efficient memory planning
- Kernel optimization
- ORT fused Adam optimizer: batches the elementwise updates applied to all the model’s parameters into one or a few kernel launches
- More efficient FP16 optimizer: eliminates a great deal of device to host memory copies
- Mixed precision training
Test it out to achieve lower latency, higher throughput, and larger maximum batch size while training models in 🤗 Transformers!
Performance
The chart below shows impressive acceleration from 39% to 130% for Hugging Face models with Optimum when using ONNX Runtime and DeepSpeed ZeRO Stage 1 for training.
The performance measurements were done on selected Hugging Face models with PyTorch as the baseline run, only ONNX Runtime for training as the second run, and ONNX
Runtime + DeepSpeed ZeRO Stage 1 as the final run, showing maximum gains. The Optimizer used for the baseline PyTorch runs is the AdamW optimizer and the ORT Training
runs use the Fused Adam Optimizer(available in ORTTrainingArguments). The runs were performed on a single Nvidia A100 node with 8 GPUs.
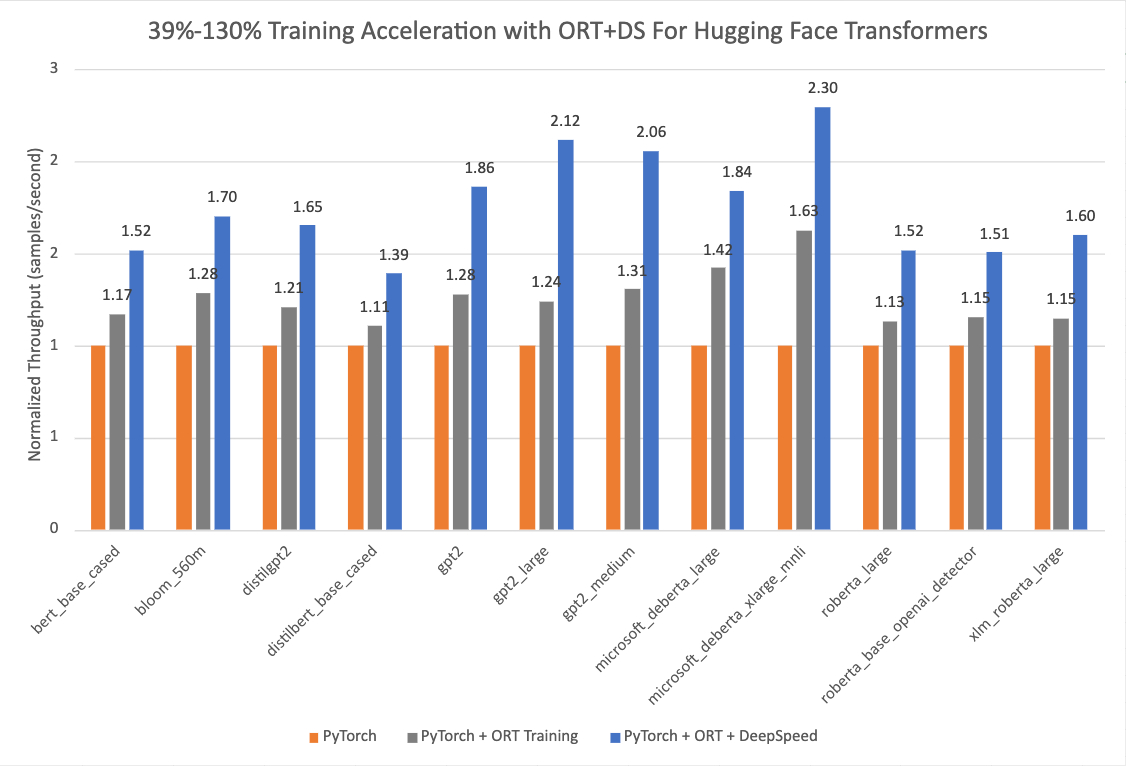
The version information used for these runs is as follows:
PyTorch: 1.14.0.dev20221103+cu116; ORT: 1.14.0.dev20221103001+cu116; DeepSpeed: 0.6.6; HuggingFace: 4.24.0.dev0; Optimum: 1.4.1.dev0; Cuda: 11.6.2Start by setting up the environment
To use ONNX Runtime for training, you need a machine with at least one NVIDIA or AMD GPU.
To use ORTTrainer or ORTSeq2SeqTrainer, you need to install ONNX Runtime Training module and Optimum.
Install ONNX Runtime
To set up the environment, we strongly recommend you install the dependencies with Docker to ensure that the versions are correct and well configured. You can find dockerfiles with various combinations here.
Setup for NVIDIA GPU
Here below we take the installation of onnxruntime-training 1.14.0 as an example:
- If you want to install
onnxruntime-training 1.14.0via Dockerfile:
docker build -f Dockerfile-ort1.14.0-cu116 -t ort/train:1.14.0 .
- If you want to install the dependencies beyond in a local Python environment. You can pip install them once you have CUDA 11.6 and cuDNN 8 well installed.
pip install onnx ninja pip install torch==1.13.1+cu116 torchvision==0.14.1 -f https://download.pytorch.org/whl/cu116/torch_stable.html pip install onnxruntime-training==1.14.0 -f https://download.onnxruntime.ai/onnxruntime_stable_cu116.html pip install torch-ort pip install --upgrade protobuf==3.20.2
And run post-installation configuration:
python -m torch_ort.configure
Setup for AMD GPU
Here below we take the installation of onnxruntime-training nightly as an example:
- If you want to install
onnxruntime-trainingvia Dockerfile:
docker build -f Dockerfile-ort-nightly-rocm57 -t ort/train:nightly .
- If you want to install the dependencies beyond in a local Python environment. You can pip install them once you have ROCM 5.7 well installed.
pip install onnx ninja pip3 install --pre torch torchvision torchaudio --index-url https://download.pytorch.org/whl/nightly/rocm5.7 pip install pip install --pre onnxruntime-training -f https://download.onnxruntime.ai/onnxruntime_nightly_rocm57.html pip install torch-ort pip install --upgrade protobuf==3.20.2
And run post-installation configuration:
python -m torch_ort.configure
Install Optimum
You can install Optimum via pypi:
pip install optimum
Or install from source:
pip install git+https://github.com/huggingface/optimum.git
This command installs the current main dev version of Optimum, which could include latest developments(new features, bug fixes). However, the main version might not be very stable. If you run into any problem, please open an issue so that we can fix it as soon as possible.
ORTTrainer
The ORTTrainer class inherits the Trainer
of Transformers. You can easily adapt the codes by replacing Trainer of transformers with ORTTrainer to take advantage of the acceleration
empowered by ONNX Runtime. Here is an example of how to use ORTTrainer compared with Trainer:
-from transformers import Trainer, TrainingArguments
+from optimum.onnxruntime import ORTTrainer, ORTTrainingArguments
# Step 1: Define training arguments
-training_args = TrainingArguments(
+training_args = ORTTrainingArguments(
output_dir="path/to/save/folder/",
- optim = "adamw_hf",
+ optim="adamw_ort_fused",
...
)
# Step 2: Create your ONNX Runtime Trainer
-trainer = Trainer(
+trainer = ORTTrainer(
model=model,
args=training_args,
train_dataset=train_dataset,
+ feature="text-classification",
...
)
# Step 3: Use ONNX Runtime for training!🤗
trainer.train()Check out more detailed example scripts in the optimum repository.
ORTSeq2SeqTrainer
The ORTSeq2SeqTrainer class is similar to the Seq2SeqTrainer
of Transformers. You can easily adapt the codes by replacing Seq2SeqTrainer of transformers with ORTSeq2SeqTrainer to take advantage of the acceleration
empowered by ONNX Runtime. Here is an example of how to use ORTSeq2SeqTrainer compared with Seq2SeqTrainer:
-from transformers import Seq2SeqTrainer, Seq2SeqTrainingArguments
+from optimum.onnxruntime import ORTSeq2SeqTrainer, ORTSeq2SeqTrainingArguments
# Step 1: Define training arguments
-training_args = Seq2SeqTrainingArguments(
+training_args = ORTSeq2SeqTrainingArguments(
output_dir="path/to/save/folder/",
- optim = "adamw_hf",
+ optim="adamw_ort_fused",
...
)
# Step 2: Create your ONNX Runtime Seq2SeqTrainer
-trainer = Seq2SeqTrainer(
+trainer = ORTSeq2SeqTrainer(
model=model,
args=training_args,
train_dataset=train_dataset,
+ feature="text2text-generation",
...
)
# Step 3: Use ONNX Runtime for training!🤗
trainer.train()Check out more detailed example scripts in the optimum repository.
ORTTrainingArguments
The ORTTrainingArguments class inherits the TrainingArguments
class in Transformers. Besides the optimizers implemented in Transformers, it allows you to use the optimizers implemented in ONNX Runtime.
Replace Seq2SeqTrainingArguments with ORTSeq2SeqTrainingArguments:
-from transformers import TrainingArguments
+from optimum.onnxruntime import ORTTrainingArguments
-training_args = TrainingArguments(
+training_args = ORTTrainingArguments(
output_dir="path/to/save/folder/",
num_train_epochs=1,
per_device_train_batch_size=8,
per_device_eval_batch_size=8,
warmup_steps=500,
weight_decay=0.01,
logging_dir="path/to/save/folder/",
- optim = "adamw_hf",
+ optim="adamw_ort_fused", # Fused Adam optimizer implemented by ORT
)DeepSpeed is supported by ONNX Runtime(only ZeRO stage 1 and 2 for the moment). You can find some DeepSpeed configuration examples in the Optimum repository.
ORTSeq2SeqTrainingArguments
The ORTSeq2SeqTrainingArguments class inherits the Seq2SeqTrainingArguments
class in Transformers. Besides the optimizers implemented in Transformers, it allows you to use the optimizers implemented in ONNX Runtime.
Replace Seq2SeqTrainingArguments with ORTSeq2SeqTrainingArguments:
-from transformers import Seq2SeqTrainingArguments
+from optimum.onnxruntime import ORTSeq2SeqTrainingArguments
-training_args = Seq2SeqTrainingArguments(
+training_args = ORTSeq2SeqTrainingArguments(
output_dir="path/to/save/folder/",
num_train_epochs=1,
per_device_train_batch_size=8,
per_device_eval_batch_size=8,
warmup_steps=500,
weight_decay=0.01,
logging_dir="path/to/save/folder/",
- optim = "adamw_hf",
+ optim="adamw_ort_fused", # Fused Adam optimizer implemented by ORT
)DeepSpeed is supported by ONNX Runtime(only ZeRO stage 1 and 2 for the moment). You can find some DeepSpeed configuration examples in the Optimum repository.
ORTModule+StableDiffusion
Optimum supports accelerating Hugging Face Diffusers with ONNX Runtime in this example. The core changes required to enable ONNX Runtime Training are summarized below:
import torch
from diffusers import AutoencoderKL, UNet2DConditionModel
from transformers import CLIPTextModel
+from onnxruntime.training.ortmodule import ORTModule
+from onnxruntime.training.optim.fp16_optimizer import FP16_Optimizer as ORT_FP16_Optimizer
unet = UNet2DConditionModel.from_pretrained(
"CompVis/stable-diffusion-v1-4",
subfolder="unet",
...
)
text_encoder = CLIPTextModel.from_pretrained(
"CompVis/stable-diffusion-v1-4",
subfolder="text_encoder",
...
)
vae = AutoencoderKL.from_pretrained(
"CompVis/stable-diffusion-v1-4",
subfolder="vae",
...
)
optimizer = torch.optim.AdamW(
unet.parameters(),
...
)
+vae = ORTModule(vae)
+text_encoder = ORTModule(text_encoder)
+unet = ORTModule(unet)
+optimizer = ORT_FP16_Optimizer(optimizer)Other Resources
- Blog posts
- Optimum github
- ONNX Runtime github
- Torch ORT github
- Download ONNX Runtime stable versions
If you have any problems or questions regarding ORTTrainer, please file an issue with Optimum Github
or discuss with us on HuggingFace’s community forum, cheers 🤗 !