Diffusers documentation
Text-to-Image Generation with Adapter Conditioning
Text-to-Image Generation with Adapter Conditioning
Overview
T2I-Adapter: Learning Adapters to Dig out More Controllable Ability for Text-to-Image Diffusion Models by Chong Mou, Xintao Wang, Liangbin Xie, Jian Zhang, Zhongang Qi, Ying Shan, Xiaohu Qie.
Using the pretrained models we can provide control images (for example, a depth map) to control Stable Diffusion text-to-image generation so that it follows the structure of the depth image and fills in the details.
The abstract of the paper is the following:
The incredible generative ability of large-scale text-to-image (T2I) models has demonstrated strong power of learning complex structures and meaningful semantics. However, relying solely on text prompts cannot fully take advantage of the knowledge learned by the model, especially when flexible and accurate structure control is needed. In this paper, we aim to “dig out” the capabilities that T2I models have implicitly learned, and then explicitly use them to control the generation more granularly. Specifically, we propose to learn simple and small T2I-Adapters to align internal knowledge in T2I models with external control signals, while freezing the original large T2I models. In this way, we can train various adapters according to different conditions, and achieve rich control and editing effects. Further, the proposed T2I-Adapters have attractive properties of practical value, such as composability and generalization ability. Extensive experiments demonstrate that our T2I-Adapter has promising generation quality and a wide range of applications.
This model was contributed by the community contributor HimariO ❤️ .
Available Pipelines:
| Pipeline | Tasks | Demo |
|---|---|---|
| StableDiffusionAdapterPipeline | Text-to-Image Generation with T2I-Adapter Conditioning | - |
Usage example
In the following we give a simple example of how to use a T2IAdapter checkpoint with Diffusers for inference. All adapters use the same pipeline.
- Images are first converted into the appropriate control image format.
- The control image and prompt are passed to the StableDiffusionAdapterPipeline.
Let’s have a look at a simple example using the Color Adapter.
from diffusers.utils import load_image
image = load_image("https://huggingface.co/datasets/diffusers/docs-images/resolve/main/t2i-adapter/color_ref.png")
Then we can create our color palette by simply resizing it to 8 by 8 pixels and then scaling it back to original size.
from PIL import Image
color_palette = image.resize((8, 8))
color_palette = color_palette.resize((512, 512), resample=Image.Resampling.NEAREST)Let’s take a look at the processed image.

Next, create the adapter pipeline
import torch
from diffusers import StableDiffusionAdapterPipeline, T2IAdapter
adapter = T2IAdapter.from_pretrained("TencentARC/t2iadapter_color_sd14v1", torch_dtype=torch.float16)
pipe = StableDiffusionAdapterPipeline.from_pretrained(
"CompVis/stable-diffusion-v1-4",
adapter=adapter,
torch_dtype=torch.float16,
)
pipe.to("cuda")Finally, pass the prompt and control image to the pipeline
# fix the random seed, so you will get the same result as the example
generator = torch.manual_seed(7)
out_image = pipe(
"At night, glowing cubes in front of the beach",
image=color_palette,
generator=generator,
).images[0]
Available checkpoints
Non-diffusers checkpoints can be found under TencentARC/T2I-Adapter.
T2I-Adapter with Stable Diffusion 1.4
| Model Name | Control Image Overview | Control Image Example | Generated Image Example |
|---|---|---|---|
| TencentARC/t2iadapter_color_sd14v1 Trained with spatial color palette |
A image with 8x8 color palette. |  |
 |
| TencentARC/t2iadapter_canny_sd14v1 Trained with canny edge detection |
A monochrome image with white edges on a black background. |  |
 |
| TencentARC/t2iadapter_sketch_sd14v1 Trained with PidiNet edge detection |
A hand-drawn monochrome image with white outlines on a black background. |  |
 |
| TencentARC/t2iadapter_depth_sd14v1 Trained with Midas depth estimation |
A grayscale image with black representing deep areas and white representing shallow areas. |  |
 |
| TencentARC/t2iadapter_openpose_sd14v1 Trained with OpenPose bone image |
A OpenPose bone image. | 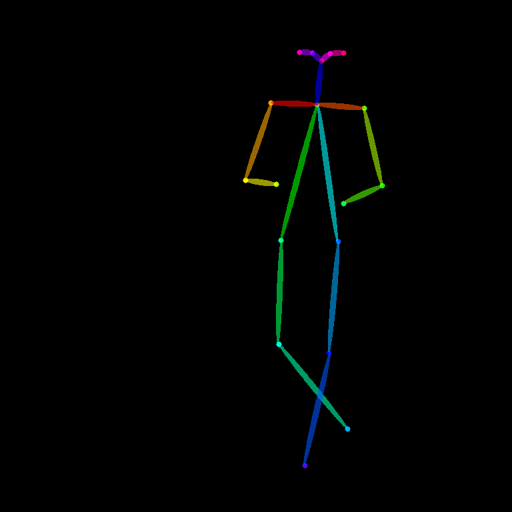 |
 |
| TencentARC/t2iadapter_keypose_sd14v1 Trained with mmpose skeleton image |
A mmpose skeleton image. |  |
 |
| TencentARC/t2iadapter_seg_sd14v1 Trained with semantic segmentation |
An custom segmentation protocol image. |  |
 |
| TencentARC/t2iadapter_canny_sd15v2 | |||
| TencentARC/t2iadapter_depth_sd15v2 | |||
| TencentARC/t2iadapter_sketch_sd15v2 | |||
| TencentARC/t2iadapter_zoedepth_sd15v1 |
Combining multiple adapters
MultiAdapter can be used for applying multiple conditionings at once.
Here we use the keypose adapter for the character posture and the depth adapter for creating the scene.
import torch
from PIL import Image
from diffusers.utils import load_image
cond_keypose = load_image(
"https://huggingface.co/datasets/diffusers/docs-images/resolve/main/t2i-adapter/keypose_sample_input.png"
)
cond_depth = load_image(
"https://huggingface.co/datasets/diffusers/docs-images/resolve/main/t2i-adapter/depth_sample_input.png"
)
cond = [[cond_keypose, cond_depth]]
prompt = ["A man walking in an office room with a nice view"]The two control images look as such:
MultiAdapter combines keypose and depth adapters.
adapter_conditioning_scale balances the relative influence of the different adapters.
from diffusers import StableDiffusionAdapterPipeline, MultiAdapter
adapters = MultiAdapter(
[
T2IAdapter.from_pretrained("TencentARC/t2iadapter_keypose_sd14v1"),
T2IAdapter.from_pretrained("TencentARC/t2iadapter_depth_sd14v1"),
]
)
adapters = adapters.to(torch.float16)
pipe = StableDiffusionAdapterPipeline.from_pretrained(
"CompVis/stable-diffusion-v1-4",
torch_dtype=torch.float16,
adapter=adapters,
)
images = pipe(prompt, cond, adapter_conditioning_scale=[0.8, 0.8])
T2I Adapter vs ControlNet
T2I-Adapter is similar to ControlNet. T2i-Adapter uses a smaller auxiliary network which is only run once for the entire diffusion process. However, T2I-Adapter performs slightly worse than ControlNet.
StableDiffusionAdapterPipeline
class diffusers.StableDiffusionAdapterPipeline
< source >( vae: AutoencoderKL text_encoder: CLIPTextModel tokenizer: CLIPTokenizer unet: UNet2DConditionModel adapter: typing.Union[diffusers.models.adapter.T2IAdapter, diffusers.models.adapter.MultiAdapter, typing.List[diffusers.models.adapter.T2IAdapter]] scheduler: KarrasDiffusionSchedulers safety_checker: StableDiffusionSafetyChecker feature_extractor: CLIPFeatureExtractor adapter_weights: typing.Optional[typing.List[float]] = None requires_safety_checker: bool = True )
Parameters
-
adapter (
T2IAdapterorMultiAdapterorList[T2IAdapter]) — Provides additional conditioning to the unet during the denoising process. If you set multiple Adapter as a list, the outputs from each Adapter are added together to create one combined additional conditioning. -
adapter_weights (
List[float], optional, defaults to None) — List of floats representing the weight which will be multiply to each adapter’s output before adding them together. - vae (AutoencoderKL) — Variational Auto-Encoder (VAE) Model to encode and decode images to and from latent representations.
-
text_encoder (
CLIPTextModel) — Frozen text-encoder. Stable Diffusion uses the text portion of CLIP, specifically the clip-vit-large-patch14 variant. -
tokenizer (
CLIPTokenizer) — Tokenizer of class CLIPTokenizer. - unet (UNet2DConditionModel) — Conditional U-Net architecture to denoise the encoded image latents.
-
scheduler (SchedulerMixin) —
A scheduler to be used in combination with
unetto denoise the encoded image latents. Can be one of DDIMScheduler, LMSDiscreteScheduler, or PNDMScheduler. -
safety_checker (
StableDiffusionSafetyChecker) — Classification module that estimates whether generated images could be considered offensive or harmful. Please, refer to the model card for details. -
feature_extractor (
CLIPFeatureExtractor) — Model that extracts features from generated images to be used as inputs for thesafety_checker.
Pipeline for text-to-image generation using Stable Diffusion augmented with T2I-Adapter https://arxiv.org/abs/2302.08453
This model inherits from DiffusionPipeline. Check the superclass documentation for the generic methods the library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
__call__
< source >(
prompt: typing.Union[str, typing.List[str]] = None
image: typing.Union[torch.Tensor, PIL.Image.Image, typing.List[PIL.Image.Image]] = None
height: typing.Optional[int] = None
width: typing.Optional[int] = None
num_inference_steps: int = 50
guidance_scale: float = 7.5
negative_prompt: typing.Union[str, typing.List[str], NoneType] = None
num_images_per_prompt: typing.Optional[int] = 1
eta: float = 0.0
generator: typing.Union[torch._C.Generator, typing.List[torch._C.Generator], NoneType] = None
latents: typing.Optional[torch.FloatTensor] = None
prompt_embeds: typing.Optional[torch.FloatTensor] = None
negative_prompt_embeds: typing.Optional[torch.FloatTensor] = None
output_type: typing.Optional[str] = 'pil'
return_dict: bool = True
callback: typing.Union[typing.Callable[[int, int, torch.FloatTensor], NoneType], NoneType] = None
callback_steps: int = 1
cross_attention_kwargs: typing.Union[typing.Dict[str, typing.Any], NoneType] = None
adapter_conditioning_scale: typing.Union[float, typing.List[float]] = 1.0
)
→
~pipelines.stable_diffusion.StableDiffusionAdapterPipelineOutput or tuple
Parameters
-
prompt (
strorList[str], optional) — The prompt or prompts to guide the image generation. If not defined, one has to passprompt_embeds. instead. -
image (
torch.FloatTensor,PIL.Image.Image,List[torch.FloatTensor]orList[PIL.Image.Image]orList[List[PIL.Image.Image]]) — The Adapter input condition. Adapter uses this input condition to generate guidance to Unet. If the type is specified asTorch.FloatTensor, it is passed to Adapter as is. PIL.Image.Image` can also be accepted as an image. The control image is automatically resized to fit the output image. -
height (
int, optional, defaults to self.unet.config.sample_size * self.vae_scale_factor) — The height in pixels of the generated image. -
width (
int, optional, defaults to self.unet.config.sample_size * self.vae_scale_factor) — The width in pixels of the generated image. -
num_inference_steps (
int, optional, defaults to 50) — The number of denoising steps. More denoising steps usually lead to a higher quality image at the expense of slower inference. -
guidance_scale (
float, optional, defaults to 7.5) — Guidance scale as defined in Classifier-Free Diffusion Guidance.guidance_scaleis defined aswof equation 2. of Imagen Paper. Guidance scale is enabled by settingguidance_scale > 1. Higher guidance scale encourages to generate images that are closely linked to the textprompt, usually at the expense of lower image quality. -
negative_prompt (
strorList[str], optional) — The prompt or prompts not to guide the image generation. If not defined, one has to passnegative_prompt_embeds. instead. If not defined, one has to passnegative_prompt_embeds. instead. Ignored when not using guidance (i.e., ignored ifguidance_scaleis less than1). -
num_images_per_prompt (
int, optional, defaults to 1) — The number of images to generate per prompt. -
eta (
float, optional, defaults to 0.0) — Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to schedulers.DDIMScheduler, will be ignored for others. -
generator (
torch.GeneratororList[torch.Generator], optional) — One or a list of torch generator(s) to make generation deterministic. -
latents (
torch.FloatTensor, optional) — Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image generation. Can be used to tweak the same generation with different prompts. If not provided, a latents tensor will ge generated by sampling using the supplied randomgenerator. -
prompt_embeds (
torch.FloatTensor, optional) — Pre-generated text embeddings. Can be used to easily tweak text inputs, e.g. prompt weighting. If not provided, text embeddings will be generated frompromptinput argument. -
negative_prompt_embeds (
torch.FloatTensor, optional) — Pre-generated negative text embeddings. Can be used to easily tweak text inputs, e.g. prompt weighting. If not provided, negative_prompt_embeds will be generated fromnegative_promptinput argument. -
output_type (
str, optional, defaults to"pil") — The output format of the generate image. Choose between PIL:PIL.Image.Imageornp.array. -
return_dict (
bool, optional, defaults toTrue) — Whether or not to return a~pipelines.stable_diffusion.StableDiffusionAdapterPipelineOutputinstead of a plain tuple. -
callback (
Callable, optional) — A function that will be called everycallback_stepssteps during inference. The function will be called with the following arguments:callback(step: int, timestep: int, latents: torch.FloatTensor). -
callback_steps (
int, optional, defaults to 1) — The frequency at which thecallbackfunction will be called. If not specified, the callback will be called at every step. -
cross_attention_kwargs (
dict, optional) — A kwargs dictionary that if specified is passed along to theAttnProcessoras defined underself.processorin diffusers.models.attention_processor. -
adapter_conditioning_scale (
floatorList[float], optional, defaults to 1.0) — The outputs of the adapter are multiplied byadapter_conditioning_scalebefore they are added to the residual in the original unet. If multiple adapters are specified in init, you can set the corresponding scale as a list.
Returns
~pipelines.stable_diffusion.StableDiffusionAdapterPipelineOutput or tuple
~pipelines.stable_diffusion.StableDiffusionAdapterPipelineOutput if return_dict is True, otherwise a
tuple. When returning a tuple, the first element is a list with the generated images, and the second element is a list of bools denoting whether the corresponding generated image likely represents "not-safe-for-work" (nsfw) content, according to the safety_checker`.
Function invoked when calling the pipeline for generation.
Examples:
>>> from PIL import Image
>>> from diffusers.utils import load_image
>>> import torch
>>> from diffusers import StableDiffusionAdapterPipeline, T2IAdapter
>>> image = load_image(
... "https://huggingface.co/datasets/diffusers/docs-images/resolve/main/t2i-adapter/color_ref.png"
... )
>>> color_palette = image.resize((8, 8))
>>> color_palette = color_palette.resize((512, 512), resample=Image.Resampling.NEAREST)
>>> adapter = T2IAdapter.from_pretrained("TencentARC/t2iadapter_color_sd14v1", torch_dtype=torch.float16)
>>> pipe = StableDiffusionAdapterPipeline.from_pretrained(
... "CompVis/stable-diffusion-v1-4",
... adapter=adapter,
... torch_dtype=torch.float16,
... )
>>> pipe.to("cuda")
>>> out_image = pipe(
... "At night, glowing cubes in front of the beach",
... image=color_palette,
... ).images[0]enable_attention_slicing
< source >( slice_size: typing.Union[str, int, NoneType] = 'auto' )
Parameters
-
slice_size (
strorint, optional, defaults to"auto") — When"auto", halves the input to the attention heads, so attention will be computed in two steps. If"max", maximum amount of memory will be saved by running only one slice at a time. If a number is provided, uses as many slices asattention_head_dim // slice_size. In this case,attention_head_dimmust be a multiple ofslice_size.
Enable sliced attention computation. When this option is enabled, the attention module splits the input tensor in slices to compute attention in several steps. For more than one attention head, the computation is performed sequentially over each head. This is useful to save some memory in exchange for a small speed decrease.
⚠️ Don’t enable attention slicing if you’re already using scaled_dot_product_attention (SDPA) from PyTorch
2.0 or xFormers. These attention computations are already very memory efficient so you won’t need to enable
this function. If you enable attention slicing with SDPA or xFormers, it can lead to serious slow downs!
Examples:
>>> import torch
>>> from diffusers import StableDiffusionPipeline
>>> pipe = StableDiffusionPipeline.from_pretrained(
... "runwayml/stable-diffusion-v1-5",
... torch_dtype=torch.float16,
... use_safetensors=True,
... )
>>> prompt = "a photo of an astronaut riding a horse on mars"
>>> pipe.enable_attention_slicing()
>>> image = pipe(prompt).images[0]Disable sliced attention computation. If enable_attention_slicing was previously called, attention is
computed in one step.
Enable sliced VAE decoding. When this option is enabled, the VAE will split the input tensor in slices to compute decoding in several steps. This is useful to save some memory and allow larger batch sizes.
Disable sliced VAE decoding. If enable_vae_slicing was previously enabled, this method will go back to
computing decoding in one step.
enable_xformers_memory_efficient_attention
< source >( attention_op: typing.Optional[typing.Callable] = None )
Parameters
-
attention_op (
Callable, optional) — Override the defaultNoneoperator for use asopargument to thememory_efficient_attention()function of xFormers.
Enable memory efficient attention from xFormers. When this option is enabled, you should observe lower GPU memory usage and a potential speed up during inference. Speed up during training is not guaranteed.
⚠️ When memory efficient attention and sliced attention are both enabled, memory efficient attention takes precedent.
Examples:
>>> import torch
>>> from diffusers import DiffusionPipeline
>>> from xformers.ops import MemoryEfficientAttentionFlashAttentionOp
>>> pipe = DiffusionPipeline.from_pretrained("stabilityai/stable-diffusion-2-1", torch_dtype=torch.float16)
>>> pipe = pipe.to("cuda")
>>> pipe.enable_xformers_memory_efficient_attention(attention_op=MemoryEfficientAttentionFlashAttentionOp)
>>> # Workaround for not accepting attention shape using VAE for Flash Attention
>>> pipe.vae.enable_xformers_memory_efficient_attention(attention_op=None)Disable memory efficient attention from xFormers.
Offloads all models to CPU using accelerate, reducing memory usage with a low impact on performance. Compared
to enable_sequential_cpu_offload, this method moves one whole model at a time to the GPU when its forward
method is called, and the model remains in GPU until the next model runs. Memory savings are lower than with
enable_sequential_cpu_offload, but performance is much better due to the iterative execution of the unet.