Diffusers documentation
ControlNet with Stable Diffusion XL
ControlNet with Stable Diffusion XL
Adding Conditional Control to Text-to-Image Diffusion Models by Lvmin Zhang and Maneesh Agrawala.
Using a pretrained model, we can provide control images (for example, a depth map) to control Stable Diffusion text-to-image generation so that it follows the structure of the depth image and fills in the details.
The abstract from the paper is:
We present a neural network structure, ControlNet, to control pretrained large diffusion models to support additional input conditions. The ControlNet learns task-specific conditions in an end-to-end way, and the learning is robust even when the training dataset is small (< 50k). Moreover, training a ControlNet is as fast as fine-tuning a diffusion model, and the model can be trained on a personal devices. Alternatively, if powerful computation clusters are available, the model can scale to large amounts (millions to billions) of data. We report that large diffusion models like Stable Diffusion can be augmented with ControlNets to enable conditional inputs like edge maps, segmentation maps, keypoints, etc. This may enrich the methods to control large diffusion models and further facilitate related applications.
We provide support using ControlNets with Stable Diffusion XL (SDXL).
You can find numerous SDXL ControlNet checkpoints from this link. There are some smaller ControlNet checkpoints too:
- controlnet-canny-sdxl-1.0-small
- controlnet-canny-sdxl-1.0-mid
- controlnet-depth-sdxl-1.0-small
- controlnet-depth-sdxl-1.0-mid
We also encourage you to train custom ControlNets; we provide a training script for this.
You can find some results below:

🚨 At the time of this writing, many of these SDXL ControlNet checkpoints are experimental and there is a lot of room for improvement. We encourage our users to provide feedback. 🚨
MultiControlNet
You can compose multiple ControlNet conditionings from different image inputs to create a MultiControlNet. To get better results, it is often helpful to:
- mask conditionings such that they don’t overlap (for example, mask the area of a canny image where the pose conditioning is located)
- experiment with the
controlnet_conditioning_scaleparameter to determine how much weight to assign to each conditioning input
In this example, you’ll combine a canny image and a human pose estimation image to generate a new image.
Prepare the canny image conditioning:
from diffusers.utils import load_image
from PIL import Image
import numpy as np
import cv2
canny_image = load_image(
"https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/landscape.png"
)
canny_image = np.array(canny_image)
low_threshold = 100
high_threshold = 200
canny_image = cv2.Canny(canny_image, low_threshold, high_threshold)
# zero out middle columns of image where pose will be overlayed
zero_start = canny_image.shape[1] // 4
zero_end = zero_start + canny_image.shape[1] // 2
canny_image[:, zero_start:zero_end] = 0
canny_image = canny_image[:, :, None]
canny_image = np.concatenate([canny_image, canny_image, canny_image], axis=2)
canny_image = Image.fromarray(canny_image).resize((1024, 1024))

Prepare the human pose estimation conditioning:
from controlnet_aux import OpenposeDetector
from diffusers.utils import load_image
openpose = OpenposeDetector.from_pretrained("lllyasviel/ControlNet")
openpose_image = load_image(
"https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/person.png"
)
openpose_image = openpose(openpose_image).resize((1024, 1024))
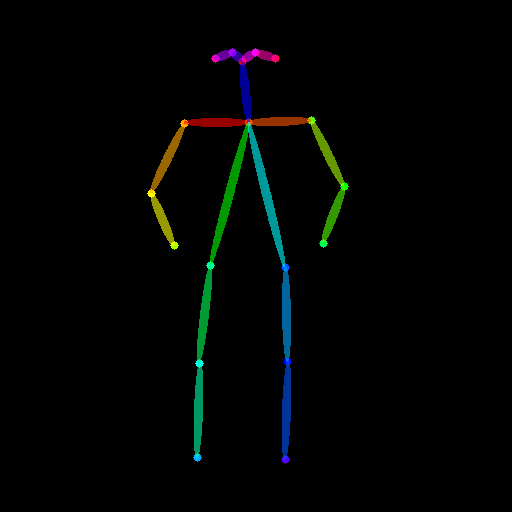
Load a list of ControlNet models that correspond to each conditioning, and pass them to the StableDiffusionXLControlNetPipeline. Use the faster UniPCMultistepScheduler and nable model offloading to reduce memory usage.
from diffusers import StableDiffusionXLControlNetPipeline, ControlNetModel, AutoencoderKL, UniPCMultistepScheduler
import torch
controlnets = [
ControlNetModel.from_pretrained(
"thibaud/controlnet-openpose-sdxl-1.0", torch_dtype=torch.float16, use_safetensors=True
),
ControlNetModel.from_pretrained("diffusers/controlnet-canny-sdxl-1.0", torch_dtype=torch.float16, use_safetensors=True),
]
vae = AutoencoderKL.from_pretrained("madebyollin/sdxl-vae-fp16-fix", torch_dtype=torch.float16, use_safetensors=True)
pipe = StableDiffusionXLControlNetPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0", controlnet=controlnets, vae=vae, torch_dtype=torch.float16, use_safetensors=True
)
pipe.scheduler = UniPCMultistepScheduler.from_config(pipe.scheduler.config)
pipe.enable_model_cpu_offload()Now you can pass your prompt (an optional negative prompt if you’re using one), canny image, and pose image to the pipeline:
prompt = "a giant standing in a fantasy landscape, best quality"
negative_prompt = "monochrome, lowres, bad anatomy, worst quality, low quality"
generator = torch.manual_seed(1)
images = [openpose_image, canny_image]
images = pipe(
prompt,
image=images,
num_inference_steps=25,
generator=generator,
negative_prompt=negative_prompt,
num_images_per_prompt=3,
controlnet_conditioning_scale=[1.0, 0.8],
).images[0]
StableDiffusionXLControlNetPipeline
class diffusers.StableDiffusionXLControlNetPipeline
< source >( vae: AutoencoderKL text_encoder: CLIPTextModel text_encoder_2: CLIPTextModelWithProjection tokenizer: CLIPTokenizer tokenizer_2: CLIPTokenizer unet: UNet2DConditionModel controlnet: typing.Union[diffusers.models.controlnet.ControlNetModel, typing.List[diffusers.models.controlnet.ControlNetModel], typing.Tuple[diffusers.models.controlnet.ControlNetModel], diffusers.pipelines.controlnet.multicontrolnet.MultiControlNetModel] scheduler: KarrasDiffusionSchedulers force_zeros_for_empty_prompt: bool = True add_watermarker: typing.Optional[bool] = None )
Parameters
- vae (AutoencoderKL) — Variational Auto-Encoder (VAE) Model to encode and decode images to and from latent representations.
-
text_encoder (
CLIPTextModel) — Frozen text-encoder. Stable Diffusion uses the text portion of CLIP, specifically the clip-vit-large-patch14 variant. -
text_encoder_2 (
CLIPTextModelWithProjection) — Second frozen text-encoder. Stable Diffusion XL uses the text and pool portion of CLIP, specifically the laion/CLIP-ViT-bigG-14-laion2B-39B-b160k variant. -
tokenizer (
CLIPTokenizer) — Tokenizer of class CLIPTokenizer. -
tokenizer_2 (
CLIPTokenizer) — Second Tokenizer of class CLIPTokenizer. - unet (UNet2DConditionModel) — Conditional U-Net architecture to denoise the encoded image latents.
-
controlnet (ControlNetModel or
List[ControlNetModel]) — Provides additional conditioning to the unet during the denoising process. If you set multiple ControlNets as a list, the outputs from each ControlNet are added together to create one combined additional conditioning. -
scheduler (SchedulerMixin) —
A scheduler to be used in combination with
unetto denoise the encoded image latents. Can be one of DDIMScheduler, LMSDiscreteScheduler, or PNDMScheduler.
Pipeline for text-to-image generation using Stable Diffusion XL with ControlNet guidance.
This model inherits from DiffusionPipeline. Check the superclass documentation for the generic methods the library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
In addition the pipeline inherits the following loading methods:
- Textual-Inversion: loaders.TextualInversionLoaderMixin.load_textual_inversion()
- LoRA: loaders.LoraLoaderMixin.load_lora_weights()
__call__
< source >(
prompt: typing.Union[str, typing.List[str]] = None
prompt_2: typing.Union[str, typing.List[str], NoneType] = None
image: typing.Union[torch.FloatTensor, PIL.Image.Image, numpy.ndarray, typing.List[torch.FloatTensor], typing.List[PIL.Image.Image], typing.List[numpy.ndarray]] = None
height: typing.Optional[int] = None
width: typing.Optional[int] = None
num_inference_steps: int = 50
guidance_scale: float = 5.0
negative_prompt: typing.Union[str, typing.List[str], NoneType] = None
negative_prompt_2: typing.Union[str, typing.List[str], NoneType] = None
num_images_per_prompt: typing.Optional[int] = 1
eta: float = 0.0
generator: typing.Union[torch._C.Generator, typing.List[torch._C.Generator], NoneType] = None
latents: typing.Optional[torch.FloatTensor] = None
prompt_embeds: typing.Optional[torch.FloatTensor] = None
negative_prompt_embeds: typing.Optional[torch.FloatTensor] = None
pooled_prompt_embeds: typing.Optional[torch.FloatTensor] = None
negative_pooled_prompt_embeds: typing.Optional[torch.FloatTensor] = None
output_type: typing.Optional[str] = 'pil'
return_dict: bool = True
callback: typing.Union[typing.Callable[[int, int, torch.FloatTensor], NoneType], NoneType] = None
callback_steps: int = 1
cross_attention_kwargs: typing.Union[typing.Dict[str, typing.Any], NoneType] = None
controlnet_conditioning_scale: typing.Union[float, typing.List[float]] = 1.0
guess_mode: bool = False
control_guidance_start: typing.Union[float, typing.List[float]] = 0.0
control_guidance_end: typing.Union[float, typing.List[float]] = 1.0
original_size: typing.Tuple[int, int] = None
crops_coords_top_left: typing.Tuple[int, int] = (0, 0)
target_size: typing.Tuple[int, int] = None
)
→
StableDiffusionPipelineOutput or tuple
Parameters
-
prompt (
strorList[str], optional) — The prompt or prompts to guide the image generation. If not defined, one has to passprompt_embeds. instead. -
prompt_2 (
strorList[str], optional) — The prompt or prompts to be sent to thetokenizer_2andtext_encoder_2. If not defined,promptis used in both text-encoders -
image (
torch.FloatTensor,PIL.Image.Image,np.ndarray,List[torch.FloatTensor],List[PIL.Image.Image],List[np.ndarray], —List[List[torch.FloatTensor]],List[List[np.ndarray]]orList[List[PIL.Image.Image]]): The ControlNet input condition. ControlNet uses this input condition to generate guidance to Unet. If the type is specified asTorch.FloatTensor, it is passed to ControlNet as is.PIL.Image.Imagecan also be accepted as an image. The dimensions of the output image defaults toimage’s dimensions. If height and/or width are passed,imageis resized according to them. If multiple ControlNets are specified in init, images must be passed as a list such that each element of the list can be correctly batched for input to a single controlnet. -
height (
int, optional, defaults to self.unet.config.sample_size * self.vae_scale_factor) — The height in pixels of the generated image. -
width (
int, optional, defaults to self.unet.config.sample_size * self.vae_scale_factor) — The width in pixels of the generated image. -
num_inference_steps (
int, optional, defaults to 50) — The number of denoising steps. More denoising steps usually lead to a higher quality image at the expense of slower inference. -
guidance_scale (
float, optional, defaults to 7.5) — Guidance scale as defined in Classifier-Free Diffusion Guidance.guidance_scaleis defined aswof equation 2. of Imagen Paper. Guidance scale is enabled by settingguidance_scale > 1. Higher guidance scale encourages to generate images that are closely linked to the textprompt, usually at the expense of lower image quality. -
negative_prompt (
strorList[str], optional) — The prompt or prompts not to guide the image generation. If not defined, one has to passnegative_prompt_embedsinstead. Ignored when not using guidance (i.e., ignored ifguidance_scaleis less than1). -
negative_prompt_2 (
strorList[str], optional) — The prompt or prompts not to guide the image generation to be sent totokenizer_2andtext_encoder_2. If not defined,negative_promptis used in both text-encoders -
num_images_per_prompt (
int, optional, defaults to 1) — The number of images to generate per prompt. -
eta (
float, optional, defaults to 0.0) — Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to schedulers.DDIMScheduler, will be ignored for others. -
generator (
torch.GeneratororList[torch.Generator], optional) — One or a list of torch generator(s) to make generation deterministic. -
latents (
torch.FloatTensor, optional) — Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image generation. Can be used to tweak the same generation with different prompts. If not provided, a latents tensor will ge generated by sampling using the supplied randomgenerator. -
prompt_embeds (
torch.FloatTensor, optional) — Pre-generated text embeddings. Can be used to easily tweak text inputs, e.g. prompt weighting. If not provided, text embeddings will be generated frompromptinput argument. -
negative_prompt_embeds (
torch.FloatTensor, optional) — Pre-generated negative text embeddings. Can be used to easily tweak text inputs, e.g. prompt weighting. If not provided, negative_prompt_embeds will be generated fromnegative_promptinput argument. -
pooled_prompt_embeds (
torch.FloatTensor, optional) — Pre-generated pooled text embeddings. Can be used to easily tweak text inputs, e.g. prompt weighting. If not provided, pooled text embeddings will be generated frompromptinput argument. -
negative_pooled_prompt_embeds (
torch.FloatTensor, optional) — Pre-generated negative pooled text embeddings. Can be used to easily tweak text inputs, e.g. prompt weighting. If not provided, pooled negative_prompt_embeds will be generated fromnegative_promptinput argument. -
output_type (
str, optional, defaults to"pil") — The output format of the generate image. Choose between PIL:PIL.Image.Imageornp.array. -
return_dict (
bool, optional, defaults toTrue) — Whether or not to return a StableDiffusionPipelineOutput instead of a plain tuple. -
callback (
Callable, optional) — A function that will be called everycallback_stepssteps during inference. The function will be called with the following arguments:callback(step: int, timestep: int, latents: torch.FloatTensor). -
callback_steps (
int, optional, defaults to 1) — The frequency at which thecallbackfunction will be called. If not specified, the callback will be called at every step. -
cross_attention_kwargs (
dict, optional) — A kwargs dictionary that if specified is passed along to theAttentionProcessoras defined underself.processorin diffusers.models.attention_processor. -
controlnet_conditioning_scale (
floatorList[float], optional, defaults to 1.0) — The outputs of the controlnet are multiplied bycontrolnet_conditioning_scalebefore they are added to the residual in the original unet. If multiple ControlNets are specified in init, you can set the corresponding scale as a list. -
guess_mode (
bool, optional, defaults toFalse) — In this mode, the ControlNet encoder will try best to recognize the content of the input image even if you remove all prompts. Theguidance_scalebetween 3.0 and 5.0 is recommended. -
control_guidance_start (
floatorList[float], optional, defaults to 0.0) — The percentage of total steps at which the controlnet starts applying. -
control_guidance_end (
floatorList[float], optional, defaults to 1.0) — The percentage of total steps at which the controlnet stops applying. -
original_size (
Tuple[int], optional, defaults to (1024, 1024)) — Iforiginal_sizeis not the same astarget_sizethe image will appear to be down- or upsampled.original_sizedefaults to(width, height)if not specified. Part of SDXL’s micro-conditioning as explained in section 2.2 of https://huggingface.co/papers/2307.01952. -
crops_coords_top_left (
Tuple[int], optional, defaults to (0, 0)) —crops_coords_top_leftcan be used to generate an image that appears to be “cropped” from the positioncrops_coords_top_leftdownwards. Favorable, well-centered images are usually achieved by settingcrops_coords_top_leftto (0, 0). Part of SDXL’s micro-conditioning as explained in section 2.2 of https://huggingface.co/papers/2307.01952. -
target_size (
Tuple[int], optional, defaults to (1024, 1024)) — For most cases,target_sizeshould be set to the desired height and width of the generated image. If not specified it will default to(width, height). Part of SDXL’s micro-conditioning as explained in section 2.2 of https://huggingface.co/papers/2307.01952.
Returns
StableDiffusionPipelineOutput or tuple
StableDiffusionPipelineOutput if return_dict is True, otherwise a tuple
containing the output images.
Function invoked when calling the pipeline for generation.
Examples:
>>> # !pip install opencv-python transformers accelerate
>>> from diffusers import StableDiffusionXLControlNetPipeline, ControlNetModel, AutoencoderKL
>>> from diffusers.utils import load_image
>>> import numpy as np
>>> import torch
>>> import cv2
>>> from PIL import Image
>>> prompt = "aerial view, a futuristic research complex in a bright foggy jungle, hard lighting"
>>> negative_prompt = "low quality, bad quality, sketches"
>>> # download an image
>>> image = load_image(
... "https://hf.co/datasets/hf-internal-testing/diffusers-images/resolve/main/sd_controlnet/hf-logo.png"
... )
>>> # initialize the models and pipeline
>>> controlnet_conditioning_scale = 0.5 # recommended for good generalization
>>> controlnet = ControlNetModel.from_pretrained(
... "diffusers/controlnet-canny-sdxl-1.0", torch_dtype=torch.float16
... )
>>> vae = AutoencoderKL.from_pretrained("madebyollin/sdxl-vae-fp16-fix", torch_dtype=torch.float16)
>>> pipe = StableDiffusionXLControlNetPipeline.from_pretrained(
... "stabilityai/stable-diffusion-xl-base-1.0", controlnet=controlnet, vae=vae, torch_dtype=torch.float16
... )
>>> pipe.enable_model_cpu_offload()
>>> # get canny image
>>> image = np.array(image)
>>> image = cv2.Canny(image, 100, 200)
>>> image = image[:, :, None]
>>> image = np.concatenate([image, image, image], axis=2)
>>> canny_image = Image.fromarray(image)
>>> # generate image
>>> image = pipe(
... prompt, controlnet_conditioning_scale=controlnet_conditioning_scale, image=canny_image
... ).images[0]Disable sliced VAE decoding. If enable_vae_slicing was previously enabled, this method will go back to
computing decoding in one step.
Disable tiled VAE decoding. If enable_vae_tiling was previously enabled, this method will go back to
computing decoding in one step.
Offloads all models to CPU using accelerate, reducing memory usage with a low impact on performance. Compared
to enable_sequential_cpu_offload, this method moves one whole model at a time to the GPU when its forward
method is called, and the model remains in GPU until the next model runs. Memory savings are lower than with
enable_sequential_cpu_offload, but performance is much better due to the iterative execution of the unet.
Enable sliced VAE decoding. When this option is enabled, the VAE will split the input tensor in slices to compute decoding in several steps. This is useful to save some memory and allow larger batch sizes.
Enable tiled VAE decoding. When this option is enabled, the VAE will split the input tensor into tiles to compute decoding and encoding in several steps. This is useful for saving a large amount of memory and to allow processing larger images.
encode_prompt
< source >( prompt: str prompt_2: typing.Optional[str] = None device: typing.Optional[torch.device] = None num_images_per_prompt: int = 1 do_classifier_free_guidance: bool = True negative_prompt: typing.Optional[str] = None negative_prompt_2: typing.Optional[str] = None prompt_embeds: typing.Optional[torch.FloatTensor] = None negative_prompt_embeds: typing.Optional[torch.FloatTensor] = None pooled_prompt_embeds: typing.Optional[torch.FloatTensor] = None negative_pooled_prompt_embeds: typing.Optional[torch.FloatTensor] = None lora_scale: typing.Optional[float] = None )
Parameters
-
prompt (
strorList[str], optional) — prompt to be encoded -
prompt_2 (
strorList[str], optional) — The prompt or prompts to be sent to thetokenizer_2andtext_encoder_2. If not defined,promptis used in both text-encoders device — (torch.device): torch device -
num_images_per_prompt (
int) — number of images that should be generated per prompt -
do_classifier_free_guidance (
bool) — whether to use classifier free guidance or not -
negative_prompt (
strorList[str], optional) — The prompt or prompts not to guide the image generation. If not defined, one has to passnegative_prompt_embedsinstead. Ignored when not using guidance (i.e., ignored ifguidance_scaleis less than1). -
negative_prompt_2 (
strorList[str], optional) — The prompt or prompts not to guide the image generation to be sent totokenizer_2andtext_encoder_2. If not defined,negative_promptis used in both text-encoders -
prompt_embeds (
torch.FloatTensor, optional) — Pre-generated text embeddings. Can be used to easily tweak text inputs, e.g. prompt weighting. If not provided, text embeddings will be generated frompromptinput argument. -
negative_prompt_embeds (
torch.FloatTensor, optional) — Pre-generated negative text embeddings. Can be used to easily tweak text inputs, e.g. prompt weighting. If not provided, negative_prompt_embeds will be generated fromnegative_promptinput argument. -
pooled_prompt_embeds (
torch.FloatTensor, optional) — Pre-generated pooled text embeddings. Can be used to easily tweak text inputs, e.g. prompt weighting. If not provided, pooled text embeddings will be generated frompromptinput argument. -
negative_pooled_prompt_embeds (
torch.FloatTensor, optional) — Pre-generated negative pooled text embeddings. Can be used to easily tweak text inputs, e.g. prompt weighting. If not provided, pooled negative_prompt_embeds will be generated fromnegative_promptinput argument. -
lora_scale (
float, optional) — A lora scale that will be applied to all LoRA layers of the text encoder if LoRA layers are loaded.
Encodes the prompt into text encoder hidden states.