
DistilBERT base uncased finetuned SST-2
Table of Contents
Model Details
Model Description: This model is a fine-tune checkpoint of DistilBERT-base-uncased, fine-tuned on SST-2. This model reaches an accuracy of 91.3 on the dev set (for comparison, Bert bert-base-uncased version reaches an accuracy of 92.7).
- Developed by: Hugging Face
- Model Type: Text Classification
- Language(s): English
- License: Apache-2.0
- Parent Model: For more details about DistilBERT, we encourage users to check out this model card.
- Resources for more information:
How to Get Started With the Model
Example of single-label classification:
import torch
from transformers import DistilBertTokenizer, DistilBertForSequenceClassification
tokenizer = DistilBertTokenizer.from_pretrained("distilbert-base-uncased-finetuned-sst-2-english")
model = DistilBertForSequenceClassification.from_pretrained("distilbert-base-uncased-finetuned-sst-2-english")
inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
with torch.no_grad():
logits = model(**inputs).logits
predicted_class_id = logits.argmax().item()
model.config.id2label[predicted_class_id]
Uses
Direct Use
This model can be used for topic classification. You can use the raw model for either masked language modeling or next sentence prediction, but it's mostly intended to be fine-tuned on a downstream task. See the model hub to look for fine-tuned versions on a task that interests you.
Misuse and Out-of-scope Use
The model should not be used to intentionally create hostile or alienating environments for people. In addition, the model was not trained to be factual or true representations of people or events, and therefore using the model to generate such content is out-of-scope for the abilities of this model.
Risks, Limitations and Biases
Based on a few experimentations, we observed that this model could produce biased predictions that target underrepresented populations.
For instance, for sentences like This film was filmed in COUNTRY, this binary classification model will give radically different probabilities for the positive label depending on the country (0.89 if the country is France, but 0.08 if the country is Afghanistan) when nothing in the input indicates such a strong semantic shift. In this colab, Aurélien Géron made an interesting map plotting these probabilities for each country.
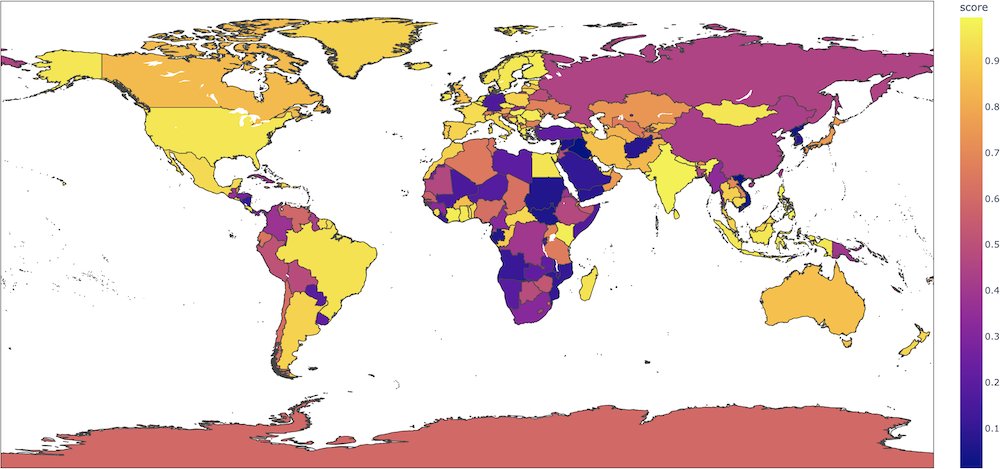
We strongly advise users to thoroughly probe these aspects on their use-cases in order to evaluate the risks of this model. We recommend looking at the following bias evaluation datasets as a place to start: WinoBias, WinoGender, Stereoset.
Training
Training Data
The authors use the following Stanford Sentiment Treebank(sst2) corpora for the model.
Training Procedure
Fine-tuning hyper-parameters
- learning_rate = 1e-5
- batch_size = 32
- warmup = 600
- max_seq_length = 128
- num_train_epochs = 3.0
- Downloads last month
- 7,645,801
Model tree for distilbert/distilbert-base-uncased-finetuned-sst-2-english
Datasets used to train distilbert/distilbert-base-uncased-finetuned-sst-2-english
Spaces using distilbert/distilbert-base-uncased-finetuned-sst-2-english 100
Evaluation results
- Accuracy on gluevalidation set verified0.911
- Precision on gluevalidation set verified0.898
- Recall on gluevalidation set verified0.930
- AUC on gluevalidation set verified0.972
- F1 on gluevalidation set verified0.914
- loss on gluevalidation set verified0.390
- Accuracy on sst2verified0.989
- Precision Macro on sst2verified0.988
- Precision Micro on sst2verified0.989
- Precision Weighted on sst2verified0.989