
url
stringlengths 58
61
| repository_url
stringclasses 1
value | labels_url
stringlengths 72
75
| comments_url
stringlengths 67
70
| events_url
stringlengths 65
68
| html_url
stringlengths 46
51
| id
int64 599M
1.07B
| node_id
stringlengths 18
32
| number
int64 1
3.41k
| title
stringlengths 1
276
| user
dict | labels
list | state
stringclasses 2
values | locked
bool 1
class | assignee
dict | assignees
list | milestone
null | comments
sequence | created_at
int64 1,587B
1,639B
| updated_at
int64 1,587B
1,639B
| closed_at
int64 1,587B
1,639B
⌀ | author_association
stringclasses 3
values | active_lock_reason
null | draft
bool 2
classes | pull_request
dict | body
stringlengths 0
228k
⌀ | reactions
dict | timeline_url
stringlengths 67
70
| performed_via_github_app
null | is_pull_request
bool 2
classes |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
https://api.github.com/repos/huggingface/datasets/issues/3407 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3407/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3407/comments | https://api.github.com/repos/huggingface/datasets/issues/3407/events | https://github.com/huggingface/datasets/pull/3407 | 1,074,502,225 | PR_kwDODunzps4vjyrB | 3,407 | Use max number of data files to infer module | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | [] | 1,638,975,523,000 | 1,638,975,523,000 | null | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3407",
"html_url": "https://github.com/huggingface/datasets/pull/3407",
"diff_url": "https://github.com/huggingface/datasets/pull/3407.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3407.patch",
"merged_at": null
} | When inferring the module for datasets without script, set a maximum number of iterations over data files.
This PR fixes the issue of taking too long when hundred of data files present.
Please, feel free to agree on both numbers:
```
# Datasets without script
DATA_FILES_MAX_NUMBER = 10
ARCHIVED_DATA_FILES_MAX_NUMBER = 5
```
Fix #3404. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3407/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3407/timeline | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3406 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3406/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3406/comments | https://api.github.com/repos/huggingface/datasets/issues/3406/events | https://github.com/huggingface/datasets/pull/3406 | 1,074,366,050 | PR_kwDODunzps4vjV21 | 3,406 | Fix module inference for archive with a directory | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,638,967,152,000 | 1,638,968,610,000 | 1,638,968,609,000 | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3406",
"html_url": "https://github.com/huggingface/datasets/pull/3406",
"diff_url": "https://github.com/huggingface/datasets/pull/3406.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3406.patch",
"merged_at": 1638968608000
} | Fix module inference for an archive file that contains files within a directory.
Fix #3405. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3406/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3406/timeline | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3405 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3405/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3405/comments | https://api.github.com/repos/huggingface/datasets/issues/3405/events | https://github.com/huggingface/datasets/issues/3405 | 1,074,360,362 | I_kwDODunzps5ACXAq | 3,405 | ZIP format inference does not work when files located in a dir inside the archive | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
}
] | null | [] | 1,638,966,735,000 | 1,638,968,609,000 | 1,638,968,609,000 | MEMBER | null | null | null | ## Describe the bug
When a zipped file contains archived files within a directory, the function `infer_module_for_data_files_in_archives` does not work.
It only works for files located in the root directory of the ZIP file.
## Steps to reproduce the bug
```python
infer_module_for_data_files_in_archives(["path/to/zip/file.zip"], False)
``` | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3405/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3405/timeline | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3404 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3404/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3404/comments | https://api.github.com/repos/huggingface/datasets/issues/3404/events | https://github.com/huggingface/datasets/issues/3404 | 1,073,657,561 | I_kwDODunzps4__rbZ | 3,404 | Optimize ZIP format inference | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
}
] | open | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
}
] | null | [] | 1,638,902,689,000 | 1,638,902,689,000 | null | MEMBER | null | null | null | **Is your feature request related to a problem? Please describe.**
When hundreds of ZIP files are present in a dataset, format inference takes too long.
See: https://github.com/bigscience-workshop/data_tooling/issues/232#issuecomment-986685497
**Describe the solution you'd like**
Iterate over a maximum number of files.
CC: @lhoestq
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3404/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3404/timeline | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3403 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3403/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3403/comments | https://api.github.com/repos/huggingface/datasets/issues/3403/events | https://github.com/huggingface/datasets/issues/3403 | 1,073,622,120 | I_kwDODunzps4__ixo | 3,403 | Cannot import name 'maybe_sync' | {
"login": "KMFODA",
"id": 35491698,
"node_id": "MDQ6VXNlcjM1NDkxNjk4",
"avatar_url": "https://avatars.githubusercontent.com/u/35491698?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/KMFODA",
"html_url": "https://github.com/KMFODA",
"followers_url": "https://api.github.com/users/KMFODA/followers",
"following_url": "https://api.github.com/users/KMFODA/following{/other_user}",
"gists_url": "https://api.github.com/users/KMFODA/gists{/gist_id}",
"starred_url": "https://api.github.com/users/KMFODA/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/KMFODA/subscriptions",
"organizations_url": "https://api.github.com/users/KMFODA/orgs",
"repos_url": "https://api.github.com/users/KMFODA/repos",
"events_url": "https://api.github.com/users/KMFODA/events{/privacy}",
"received_events_url": "https://api.github.com/users/KMFODA/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | open | false | null | [] | null | [] | 1,638,899,879,000 | 1,638,899,879,000 | null | CONTRIBUTOR | null | null | null | ## Describe the bug
Cannot seem to import datasets when running run_summarizer.py script on a VM set up on ovhcloud
## Steps to reproduce the bug
```python
from datasets import load_dataset
```
## Expected results
No error
## Actual results
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/opt/conda/lib/python3.7/site-packages/datasets/__init__.py", line 34, in <module>
from .arrow_dataset import Dataset, concatenate_datasets
File "/opt/conda/lib/python3.7/site-packages/datasets/arrow_dataset.py", line 48, in <module>
from .arrow_writer import ArrowWriter, OptimizedTypedSequence
File "/opt/conda/lib/python3.7/site-packages/datasets/arrow_writer.py", line 27, in <module>
from .features import (
File "/opt/conda/lib/python3.7/site-packages/datasets/features/__init__.py", line 2, in <module>
from .audio import Audio
File "/opt/conda/lib/python3.7/site-packages/datasets/features/audio.py", line 8, in <module>
from ..utils.streaming_download_manager import xopen
File "/opt/conda/lib/python3.7/site-packages/datasets/utils/streaming_download_manager.py", line 16, in <module>
from ..filesystems import COMPRESSION_FILESYSTEMS
File "/opt/conda/lib/python3.7/site-packages/datasets/filesystems/__init__.py", line 13, in <module>
from .s3filesystem import S3FileSystem # noqa: F401
File "/opt/conda/lib/python3.7/site-packages/datasets/filesystems/s3filesystem.py", line 1, in <module>
import s3fs
File "/opt/conda/lib/python3.7/site-packages/s3fs/__init__.py", line 1, in <module>
from .core import S3FileSystem, S3File
File "/opt/conda/lib/python3.7/site-packages/s3fs/core.py", line 11, in <module>
from fsspec.asyn import AsyncFileSystem, sync, sync_wrapper, maybe_sync
ImportError: cannot import name 'maybe_sync' from 'fsspec.asyn' (/opt/conda/lib/python3.7/site-packages/fsspec/asyn.py)
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.16.0
- Platform: OVH Cloud Tesla V100 Machine
- Python version: 3.7.9
- PyArrow version: 6.0.1
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3403/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3403/timeline | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3402 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3402/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3402/comments | https://api.github.com/repos/huggingface/datasets/issues/3402/events | https://github.com/huggingface/datasets/pull/3402 | 1,073,614,815 | PR_kwDODunzps4vg5Ff | 3,402 | More robust first elem check in encode/cast example | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,638,899,296,000 | 1,638,968,536,000 | 1,638,968,535,000 | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3402",
"html_url": "https://github.com/huggingface/datasets/pull/3402",
"diff_url": "https://github.com/huggingface/datasets/pull/3402.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3402.patch",
"merged_at": 1638968535000
} | Fix #3306 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3402/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3402/timeline | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3401 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3401/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3401/comments | https://api.github.com/repos/huggingface/datasets/issues/3401/events | https://github.com/huggingface/datasets/issues/3401 | 1,073,603,508 | I_kwDODunzps4__eO0 | 3,401 | Add Wikimedia pre-processed datasets | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 2067376369,
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request",
"name": "dataset request",
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset"
}
] | open | false | null | [] | null | [] | 1,638,898,399,000 | 1,638,899,017,000 | null | MEMBER | null | null | null | ## Adding a Dataset
- **Name:** Add pre-processed data to:
- *wikimedia/wikipedia*: https://huggingface.co/datasets/wikimedia/wikipedia
- *wikimedia/wikisource*: https://huggingface.co/datasets/wikimedia/wikisource
- **Description:** Add pre-processed data to the Hub for all languages
- **Paper:** *link to the dataset paper if available*
- **Data:** *link to the Github repository or current dataset location*
- **Motivation:** This will be very useful for the NLP community, as the pre-processing has a high cost for lot of researchers (both in computation and in knowledge)
Instructions to add a new dataset can be found [here](https://github.com/huggingface/datasets/blob/master/ADD_NEW_DATASET.md).
CC: @geohci, @yjernite | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3401/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3401/timeline | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3400 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3400/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3400/comments | https://api.github.com/repos/huggingface/datasets/issues/3400/events | https://github.com/huggingface/datasets/issues/3400 | 1,073,600,382 | I_kwDODunzps4__dd- | 3,400 | Improve Wikipedia loading script | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 2067376369,
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request",
"name": "dataset request",
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset"
}
] | open | false | null | [] | null | [
"Thanks! See https://public.paws.wmcloud.org/User:Isaac_(WMF)/HuggingFace%20Wikipedia%20Processing.ipynb for more implementation details / some data around the overhead induced by adding the extra preprocessing steps (stripping link prefixes and magic words)"
] | 1,638,898,165,000 | 1,638,908,751,000 | null | MEMBER | null | null | null | As reported by @geohci, the "wikipedia" processing/loading script could be improved by some additional small suggested processing functions:
- _extract_content(filepath):
- Replace .startswith("#redirect") with more structured approach: if elem.find(f"./{namespace}redirect") is None: continue
- _parse_and_clean_wikicode(raw_content, parser):
- Remove rm_template from cleaning -- this is redundant with .strip_code() from mwparserformhell
- Build a language-specific list of namespace prefixes to filter out per below get_namespace_prefixes
- Optional: strip prefixes like categories -- e.g., Category:Towns in Tianjin becomes Towns in Tianjin
- Optional: strip magic words
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3400/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3400/timeline | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3399 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3399/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3399/comments | https://api.github.com/repos/huggingface/datasets/issues/3399/events | https://github.com/huggingface/datasets/issues/3399 | 1,073,593,861 | I_kwDODunzps4__b4F | 3,399 | Add Wikisource dataset | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 2067376369,
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request",
"name": "dataset request",
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset"
}
] | open | false | null | [] | null | [] | 1,638,897,691,000 | 1,638,898,081,000 | null | MEMBER | null | null | null | ## Adding a Dataset
- **Name:** *wikisource*
- **Description:** *short description of the dataset (or link to social media or blog post)*
- **Paper:** *link to the dataset paper if available*
- **Data:** *link to the Github repository or current dataset location*
- **Motivation:** Additional high quality textual data, besides Wikipedia.
Add loading script as "canonical" dataset (as it is the case for ""wikipedia").
Instructions to add a new dataset can be found [here](https://github.com/huggingface/datasets/blob/master/ADD_NEW_DATASET.md).
CC: @geohci, @yjernite | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3399/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3399/timeline | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3398 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3398/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3398/comments | https://api.github.com/repos/huggingface/datasets/issues/3398/events | https://github.com/huggingface/datasets/issues/3398 | 1,073,590,384 | I_kwDODunzps4__bBw | 3,398 | Add URL field to Wikimedia dataset instances: wikipedia,... | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 2067376369,
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request",
"name": "dataset request",
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset"
}
] | open | false | null | [] | null | [] | 1,638,897,447,000 | 1,638,898,092,000 | null | MEMBER | null | null | null | As reported by @geohci, once we will host pre-processed data in the Hub, we should add the full URL to data instances (new field "url") in order to conform to proper attribution from license requirement. See, e.g.: https://fair-trec.github.io/docs/Fair_Ranking_2021_Participant_Instructions.pdf#subsection.3.2
This should be done for all pre-processed datasets under "wikimedia" org in the Hub: https://huggingface.co/wikimedia
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3398/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3398/timeline | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3397 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3397/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3397/comments | https://api.github.com/repos/huggingface/datasets/issues/3397/events | https://github.com/huggingface/datasets/pull/3397 | 1,073,502,444 | PR_kwDODunzps4vgh1U | 3,397 | add BNL processed newspapers | {
"login": "davanstrien",
"id": 8995957,
"node_id": "MDQ6VXNlcjg5OTU5NTc=",
"avatar_url": "https://avatars.githubusercontent.com/u/8995957?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/davanstrien",
"html_url": "https://github.com/davanstrien",
"followers_url": "https://api.github.com/users/davanstrien/followers",
"following_url": "https://api.github.com/users/davanstrien/following{/other_user}",
"gists_url": "https://api.github.com/users/davanstrien/gists{/gist_id}",
"starred_url": "https://api.github.com/users/davanstrien/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/davanstrien/subscriptions",
"organizations_url": "https://api.github.com/users/davanstrien/orgs",
"repos_url": "https://api.github.com/users/davanstrien/repos",
"events_url": "https://api.github.com/users/davanstrien/events{/privacy}",
"received_events_url": "https://api.github.com/users/davanstrien/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | [] | 1,638,891,801,000 | 1,638,962,131,000 | null | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3397",
"html_url": "https://github.com/huggingface/datasets/pull/3397",
"diff_url": "https://github.com/huggingface/datasets/pull/3397.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3397.patch",
"merged_at": null
} | This pull request adds the BNL's [processed newspaper collections](https://data.bnl.lu/data/historical-newspapers/) as a dataset. This is partly done to support BigScience see: https://github.com/bigscience-workshop/data_tooling/issues/192.
The Datacard is more sparse than I would like but I plan to make a separate pull request to try and make this more complete at a later date.
I had to manually add the `dummy_data` but I believe I've done this correctly (the tests pass locally).
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3397/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3397/timeline | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3396 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3396/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3396/comments | https://api.github.com/repos/huggingface/datasets/issues/3396/events | https://github.com/huggingface/datasets/issues/3396 | 1,073,467,183 | I_kwDODunzps4_-88v | 3,396 | Install Audio dependencies to support audio decoding | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 3470211881,
"node_id": "LA_kwDODunzps7O1zsp",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset-viewer",
"name": "dataset-viewer",
"color": "E5583E",
"default": false,
"description": "Related to the dataset viewer on huggingface.co"
}
] | open | false | null | [] | null | [] | 1,638,889,896,000 | 1,638,890,750,000 | null | MEMBER | null | null | null | ## Dataset viewer issue for '*openslr*', '*projecte-aina/parlament_parla*'
**Link:** *https://huggingface.co/datasets/openslr*
**Link:** *https://huggingface.co/datasets/projecte-aina/parlament_parla*
Error:
```
Status code: 400
Exception: ImportError
Message: To support decoding audio files, please install 'librosa'.
```
Am I the one who added this dataset ? Yes-No
- openslr: No
- projecte-aina/parlament_parla: Yes
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3396/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3396/timeline | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3395 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3395/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3395/comments | https://api.github.com/repos/huggingface/datasets/issues/3395/events | https://github.com/huggingface/datasets/pull/3395 | 1,073,432,650 | PR_kwDODunzps4vgTKG | 3,395 | Fix formatting in IterableDataset.map docs | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,638,888,061,000 | 1,638,958,293,000 | 1,638,958,293,000 | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3395",
"html_url": "https://github.com/huggingface/datasets/pull/3395",
"diff_url": "https://github.com/huggingface/datasets/pull/3395.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3395.patch",
"merged_at": 1638958292000
} | Fix formatting in the recently added `Map` section of the streaming docs. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3395/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3395/timeline | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3394 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3394/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3394/comments | https://api.github.com/repos/huggingface/datasets/issues/3394/events | https://github.com/huggingface/datasets/issues/3394 | 1,073,396,308 | I_kwDODunzps4_-rpU | 3,394 | Preserve all feature types when saving a dataset on the Hub with `push_to_hub` | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | open | false | null | [] | null | [] | 1,638,886,110,000 | 1,638,886,145,000 | null | CONTRIBUTOR | null | null | null | Currently, if one of the dataset features is of type `ClassLabel`, saving the dataset with `push_to_hub` and reloading the dataset with `load_dataset` will return the feature of type `Value`. To fix this, we should do something similar to `save_to_disk` (which correctly preserves the types) and not only push the parquet files in `push_to_hub`, but also the dataset `info` (stored in a JSON file). | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3394/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3394/timeline | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3393 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3393/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3393/comments | https://api.github.com/repos/huggingface/datasets/issues/3393/events | https://github.com/huggingface/datasets/issues/3393 | 1,073,189,777 | I_kwDODunzps4_95OR | 3,393 | Common Voice Belarusian Dataset | {
"login": "wiedymi",
"id": 42713027,
"node_id": "MDQ6VXNlcjQyNzEzMDI3",
"avatar_url": "https://avatars.githubusercontent.com/u/42713027?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/wiedymi",
"html_url": "https://github.com/wiedymi",
"followers_url": "https://api.github.com/users/wiedymi/followers",
"following_url": "https://api.github.com/users/wiedymi/following{/other_user}",
"gists_url": "https://api.github.com/users/wiedymi/gists{/gist_id}",
"starred_url": "https://api.github.com/users/wiedymi/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/wiedymi/subscriptions",
"organizations_url": "https://api.github.com/users/wiedymi/orgs",
"repos_url": "https://api.github.com/users/wiedymi/repos",
"events_url": "https://api.github.com/users/wiedymi/events{/privacy}",
"received_events_url": "https://api.github.com/users/wiedymi/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 2067376369,
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request",
"name": "dataset request",
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset"
}
] | open | false | null | [] | null | [] | 1,638,873,422,000 | 1,638,873,422,000 | null | NONE | null | null | null | ## Adding a Dataset
- **Name:** *Common Voice Belarusian Dataset*
- **Description:** *[commonvoice.mozilla.org/be](https://commonvoice.mozilla.org/be)*
- **Data:** *[commonvoice.mozilla.org/be/datasets](https://commonvoice.mozilla.org/be/datasets)*
- **Motivation:** *It has more than 7GB of data, so it will be great to have it in this package so anyone can try to train something for Belarusian language.*
Instructions to add a new dataset can be found [here](https://github.com/huggingface/datasets/blob/master/ADD_NEW_DATASET.md).
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3393/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3393/timeline | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3392 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3392/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3392/comments | https://api.github.com/repos/huggingface/datasets/issues/3392/events | https://github.com/huggingface/datasets/issues/3392 | 1,073,073,408 | I_kwDODunzps4_9c0A | 3,392 | Dataset viewer issue for `dansbecker/hackernews_hiring_posts` | {
"login": "severo",
"id": 1676121,
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/severo",
"html_url": "https://github.com/severo",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://api.github.com/users/severo/gists{/gist_id}",
"starred_url": "https://api.github.com/users/severo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/severo/subscriptions",
"organizations_url": "https://api.github.com/users/severo/orgs",
"repos_url": "https://api.github.com/users/severo/repos",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"received_events_url": "https://api.github.com/users/severo/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 3470211881,
"node_id": "LA_kwDODunzps7O1zsp",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset-viewer",
"name": "dataset-viewer",
"color": "E5583E",
"default": false,
"description": "Related to the dataset viewer on huggingface.co"
}
] | closed | false | null | [] | null | [
"This issue was fixed by me calling `all_datasets.push_to_hub(\"hackernews_hiring_posts\")`.\r\n\r\nThe previous problems were from calling `all_datasets.save_to_disk` and then pushing with `my_repo.git_add` and `my_repo.push_to_hub`.\r\n"
] | 1,638,866,461,000 | 1,638,885,868,000 | 1,638,885,868,000 | CONTRIBUTOR | null | null | null | ## Dataset viewer issue for `dansbecker/hackernews_hiring_posts`
**Link:** https://huggingface.co/datasets/dansbecker/hackernews_hiring_posts
*short description of the issue*
Dataset preview not showing for uploaded DatasetDict. See https://discuss.huggingface.co/t/dataset-preview-not-showing-for-uploaded-datasetdict/12603
Am I the one who added this dataset ?
No -> @dansbecker | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3392/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3392/timeline | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3391 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3391/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3391/comments | https://api.github.com/repos/huggingface/datasets/issues/3391/events | https://github.com/huggingface/datasets/issues/3391 | 1,072,849,055 | I_kwDODunzps4_8mCf | 3,391 | method to select columns | {
"login": "cccntu",
"id": 31893406,
"node_id": "MDQ6VXNlcjMxODkzNDA2",
"avatar_url": "https://avatars.githubusercontent.com/u/31893406?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/cccntu",
"html_url": "https://github.com/cccntu",
"followers_url": "https://api.github.com/users/cccntu/followers",
"following_url": "https://api.github.com/users/cccntu/following{/other_user}",
"gists_url": "https://api.github.com/users/cccntu/gists{/gist_id}",
"starred_url": "https://api.github.com/users/cccntu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/cccntu/subscriptions",
"organizations_url": "https://api.github.com/users/cccntu/orgs",
"repos_url": "https://api.github.com/users/cccntu/repos",
"events_url": "https://api.github.com/users/cccntu/events{/privacy}",
"received_events_url": "https://api.github.com/users/cccntu/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
}
] | closed | false | null | [] | null | [
"duplicate of #2655"
] | 1,638,845,059,000 | 1,638,845,127,000 | 1,638,845,127,000 | CONTRIBUTOR | null | null | null | **Is your feature request related to a problem? Please describe.**
* There is currently no way to select some columns of a dataset. In pandas, one can use `df[['col1', 'col2']]` to select columns, but in `datasets`, it results in error.
**Describe the solution you'd like**
* A new method that can be used to create a new dataset with only a list of specified columns.
**Describe alternatives you've considered**
`.remove_columns(self, columns: Union[str, List[str]], inverse: bool = False)`
Or
`.select(self, indices: Iterable = None, columns: List[str] = None)`
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3391/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3391/timeline | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3390 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3390/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3390/comments | https://api.github.com/repos/huggingface/datasets/issues/3390/events | https://github.com/huggingface/datasets/issues/3390 | 1,072,462,456 | I_kwDODunzps4_7Hp4 | 3,390 | Loading dataset throws "KeyError: 'Field "builder_name" does not exist in table schema'" | {
"login": "R4ZZ3",
"id": 25264037,
"node_id": "MDQ6VXNlcjI1MjY0MDM3",
"avatar_url": "https://avatars.githubusercontent.com/u/25264037?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/R4ZZ3",
"html_url": "https://github.com/R4ZZ3",
"followers_url": "https://api.github.com/users/R4ZZ3/followers",
"following_url": "https://api.github.com/users/R4ZZ3/following{/other_user}",
"gists_url": "https://api.github.com/users/R4ZZ3/gists{/gist_id}",
"starred_url": "https://api.github.com/users/R4ZZ3/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/R4ZZ3/subscriptions",
"organizations_url": "https://api.github.com/users/R4ZZ3/orgs",
"repos_url": "https://api.github.com/users/R4ZZ3/repos",
"events_url": "https://api.github.com/users/R4ZZ3/events{/privacy}",
"received_events_url": "https://api.github.com/users/R4ZZ3/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | null | [] | null | [
"Got solved it with push_to_hub, closing"
] | 1,638,814,969,000 | 1,638,822,125,000 | 1,638,822,125,000 | NONE | null | null | null | ## Describe the bug
I have prepared dataset to datasets and now I am trying to load it back Finnish-NLP/voxpopuli_fi
I get "KeyError: 'Field "builder_name" does not exist in table schema'"
My dataset folder and files should be like @patrickvonplaten has here https://huggingface.co/datasets/flax-community/german-common-voice-processed
How my voxpopuli dataset looks like:

Part of the processing (path column is the absolute path to audio files)
```
def add_audio_column(example):
example['audio'] = example['path']
return example
voxpopuli = voxpopuli.map(add_audio_column)
voxpopuli.cast_column("audio", Audio())
voxpopuli["audio"] <-- to my knowledge this does load the local files and prepares those arrays
voxpopuli = voxpopuli.cast_column("audio", Audio(sampling_rate=16_000)) resampling 16kHz
```
I have then saved it to disk_
`voxpopuli.save_to_disk('/asr_disk/datasets_processed_new/voxpopuli')`
and made folder structure same as @patrickvonplaten
I also get same error while trying to load_dataset from his repo:

## Steps to reproduce the bug
```python
dataset = load_dataset("Finnish-NLP/voxpopuli_fi")
```
## Expected results
Dataset is loaded correctly and looks like in the first picture
## Actual results
Loading throws keyError:
KeyError: 'Field "builder_name" does not exist in table schema'
Resources I have been trying to follow:
https://huggingface.co/docs/datasets/audio_process.html
https://huggingface.co/docs/datasets/share_dataset.html
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.16.2.dev0
- Platform: Ubuntu 20.04.2 LTS
- Python version: 3.8.12
- PyArrow version: 6.0.1
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3390/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3390/timeline | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3389 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3389/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3389/comments | https://api.github.com/repos/huggingface/datasets/issues/3389/events | https://github.com/huggingface/datasets/issues/3389 | 1,072,191,865 | I_kwDODunzps4_6Fl5 | 3,389 | Add EDGAR | {
"login": "philschmid",
"id": 32632186,
"node_id": "MDQ6VXNlcjMyNjMyMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/32632186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/philschmid",
"html_url": "https://github.com/philschmid",
"followers_url": "https://api.github.com/users/philschmid/followers",
"following_url": "https://api.github.com/users/philschmid/following{/other_user}",
"gists_url": "https://api.github.com/users/philschmid/gists{/gist_id}",
"starred_url": "https://api.github.com/users/philschmid/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/philschmid/subscriptions",
"organizations_url": "https://api.github.com/users/philschmid/orgs",
"repos_url": "https://api.github.com/users/philschmid/repos",
"events_url": "https://api.github.com/users/philschmid/events{/privacy}",
"received_events_url": "https://api.github.com/users/philschmid/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 2067376369,
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request",
"name": "dataset request",
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset"
}
] | open | false | null | [] | null | [
"cc @juliensimon "
] | 1,638,799,571,000 | 1,638,799,581,000 | null | MEMBER | null | null | null | ## Adding a Dataset
- **Name:** EDGAR Database
- **Description:** https://www.sec.gov/edgar/about EDGAR, the Electronic Data Gathering, Analysis, and Retrieval system, is the primary system for companies and others submitting documents under the Securities Act of 1933, the Securities Exchange Act of 1934, the Trust Indenture Act of 1939, and the Investment Company Act of 1940. Containing millions of company and individual filings, EDGAR benefits investors, corporations, and the U.S. economy overall by increasing the efficiency, transparency, and fairness of the securities markets. The system processes about 3,000 filings per day, serves up 3,000 terabytes of data to the public annually, and accommodates 40,000 new filers per year on average. EDGAR® and EDGARLink® are registered trademarks of the SEC.
- **Data:** https://www.sec.gov/os/accessing-edgar-data
- **Motivation:** Enabling and improving FSI (Financial Services Industry) datasets to increase ease of use
Instructions to add a new dataset can be found [here](https://github.com/huggingface/datasets/blob/master/ADD_NEW_DATASET.md).
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3389/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3389/timeline | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3388 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3388/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3388/comments | https://api.github.com/repos/huggingface/datasets/issues/3388/events | https://github.com/huggingface/datasets/pull/3388 | 1,072,022,021 | PR_kwDODunzps4vbnyY | 3,388 | Fix flaky test of the temporary directory used by load_from_disk | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"CI failed because of a server error - merging"
] | 1,638,788,971,000 | 1,638,789,903,000 | 1,638,789,889,000 | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3388",
"html_url": "https://github.com/huggingface/datasets/pull/3388",
"diff_url": "https://github.com/huggingface/datasets/pull/3388.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3388.patch",
"merged_at": 1638789889000
} | The test is flaky, here is an example of random CI failure:
https://github.com/huggingface/datasets/commit/73ed6615b4b3eb74d5311684f7b9e05cdb76c989
I fixed that by not checking the content of the random part of the temporary directory name | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3388/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3388/timeline | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3387 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3387/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3387/comments | https://api.github.com/repos/huggingface/datasets/issues/3387/events | https://github.com/huggingface/datasets/pull/3387 | 1,071,836,456 | PR_kwDODunzps4vbAyC | 3,387 | Create Language Modeling task | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | [] | 1,638,777,367,000 | 1,638,777,367,000 | null | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3387",
"html_url": "https://github.com/huggingface/datasets/pull/3387",
"diff_url": "https://github.com/huggingface/datasets/pull/3387.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3387.patch",
"merged_at": null
} | Create Language Modeling task to be able to specify the input "text" column in a dataset.
This can be useful for datasets which are not exclusively used for language modeling and have more than one column:
- for text classification datasets (with columns "review" and "rating", for example), the Language Modeling task can be used to specify the "text" column ("review" in this case).
TODO:
- [ ] Add the LanguageModeling task to all dataset scripts which can be used for language modeling | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3387/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3387/timeline | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3386 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3386/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3386/comments | https://api.github.com/repos/huggingface/datasets/issues/3386/events | https://github.com/huggingface/datasets/pull/3386 | 1,071,813,141 | PR_kwDODunzps4va7-2 | 3,386 | Fix typos in dataset cards | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,638,775,240,000 | 1,638,783,055,000 | 1,638,783,054,000 | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3386",
"html_url": "https://github.com/huggingface/datasets/pull/3386",
"diff_url": "https://github.com/huggingface/datasets/pull/3386.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3386.patch",
"merged_at": 1638783054000
} | This PR:
- Fix typos in dataset cards
- Fix Papers With Code ID for:
- Bilingual Corpus of Arabic-English Parallel Tweets
- Tweets Hate Speech Detection
- Add pretty name tags | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3386/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3386/timeline | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3385 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3385/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3385/comments | https://api.github.com/repos/huggingface/datasets/issues/3385/events | https://github.com/huggingface/datasets/issues/3385 | 1,071,742,310 | I_kwDODunzps4_4X1m | 3,385 | None batched `with_transform`, `set_transform` | {
"login": "cccntu",
"id": 31893406,
"node_id": "MDQ6VXNlcjMxODkzNDA2",
"avatar_url": "https://avatars.githubusercontent.com/u/31893406?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/cccntu",
"html_url": "https://github.com/cccntu",
"followers_url": "https://api.github.com/users/cccntu/followers",
"following_url": "https://api.github.com/users/cccntu/following{/other_user}",
"gists_url": "https://api.github.com/users/cccntu/gists{/gist_id}",
"starred_url": "https://api.github.com/users/cccntu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/cccntu/subscriptions",
"organizations_url": "https://api.github.com/users/cccntu/orgs",
"repos_url": "https://api.github.com/users/cccntu/repos",
"events_url": "https://api.github.com/users/cccntu/events{/privacy}",
"received_events_url": "https://api.github.com/users/cccntu/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
}
] | open | false | null | [] | null | [] | 1,638,768,054,000 | 1,638,768,054,000 | null | CONTRIBUTOR | null | null | null | **Is your feature request related to a problem? Please describe.**
A `torch.utils.data.Dataset.__getitem__` operates on a single example.
But 🤗 `Datasets.with_transform` doesn't seem to allow non-batched transform.
**Describe the solution you'd like**
Have a `batched=True` argument in `Datasets.with_transform`
**Describe alternatives you've considered**
* Convert a non-batched transform function to batched one myself.
* Wrap a 🤗 Dataset with torch Dataset, and add a `__getitem__`. 🙄
* Have `lazy=False` in `Dataset.map`, and returns a `LazyDataset` if `lazy=True`. This way the same `map` interface can be used, and existing code can be updated with one argument change. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3385/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3385/timeline | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3384 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3384/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3384/comments | https://api.github.com/repos/huggingface/datasets/issues/3384/events | https://github.com/huggingface/datasets/pull/3384 | 1,071,594,165 | PR_kwDODunzps4vaNwL | 3,384 | Adding mMARCO dataset | {
"login": "lhbonifacio",
"id": 17603035,
"node_id": "MDQ6VXNlcjE3NjAzMDM1",
"avatar_url": "https://avatars.githubusercontent.com/u/17603035?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhbonifacio",
"html_url": "https://github.com/lhbonifacio",
"followers_url": "https://api.github.com/users/lhbonifacio/followers",
"following_url": "https://api.github.com/users/lhbonifacio/following{/other_user}",
"gists_url": "https://api.github.com/users/lhbonifacio/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhbonifacio/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhbonifacio/subscriptions",
"organizations_url": "https://api.github.com/users/lhbonifacio/orgs",
"repos_url": "https://api.github.com/users/lhbonifacio/repos",
"events_url": "https://api.github.com/users/lhbonifacio/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhbonifacio/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | [] | 1,638,748,751,000 | 1,638,748,751,000 | null | NONE | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3384",
"html_url": "https://github.com/huggingface/datasets/pull/3384",
"diff_url": "https://github.com/huggingface/datasets/pull/3384.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3384.patch",
"merged_at": null
} | We are adding mMARCO dataset to HuggingFace datasets repo.
This way, all the languages covered in the translation are available in a easy way. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3384/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3384/timeline | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3383 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3383/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3383/comments | https://api.github.com/repos/huggingface/datasets/issues/3383/events | https://github.com/huggingface/datasets/pull/3383 | 1,071,551,884 | PR_kwDODunzps4vaFpm | 3,383 | add Georgian data in cc100. | {
"login": "AnzorGozalishvili",
"id": 55232459,
"node_id": "MDQ6VXNlcjU1MjMyNDU5",
"avatar_url": "https://avatars.githubusercontent.com/u/55232459?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/AnzorGozalishvili",
"html_url": "https://github.com/AnzorGozalishvili",
"followers_url": "https://api.github.com/users/AnzorGozalishvili/followers",
"following_url": "https://api.github.com/users/AnzorGozalishvili/following{/other_user}",
"gists_url": "https://api.github.com/users/AnzorGozalishvili/gists{/gist_id}",
"starred_url": "https://api.github.com/users/AnzorGozalishvili/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/AnzorGozalishvili/subscriptions",
"organizations_url": "https://api.github.com/users/AnzorGozalishvili/orgs",
"repos_url": "https://api.github.com/users/AnzorGozalishvili/repos",
"events_url": "https://api.github.com/users/AnzorGozalishvili/events{/privacy}",
"received_events_url": "https://api.github.com/users/AnzorGozalishvili/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | [] | 1,638,736,689,000 | 1,638,736,689,000 | null | NONE | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3383",
"html_url": "https://github.com/huggingface/datasets/pull/3383",
"diff_url": "https://github.com/huggingface/datasets/pull/3383.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3383.patch",
"merged_at": null
} | update cc100 dataset to support loading Georgian (ka) data which is originally available in CC100 dataset source.
All tests are passed.
Dummy data generated.
metadata generated. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3383/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3383/timeline | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3382 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3382/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3382/comments | https://api.github.com/repos/huggingface/datasets/issues/3382/events | https://github.com/huggingface/datasets/pull/3382 | 1,071,293,299 | PR_kwDODunzps4vZT2K | 3,382 | #3337 Add typing overloads to Dataset.__getitem__ for mypy | {
"login": "Dref360",
"id": 8976546,
"node_id": "MDQ6VXNlcjg5NzY1NDY=",
"avatar_url": "https://avatars.githubusercontent.com/u/8976546?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Dref360",
"html_url": "https://github.com/Dref360",
"followers_url": "https://api.github.com/users/Dref360/followers",
"following_url": "https://api.github.com/users/Dref360/following{/other_user}",
"gists_url": "https://api.github.com/users/Dref360/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Dref360/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Dref360/subscriptions",
"organizations_url": "https://api.github.com/users/Dref360/orgs",
"repos_url": "https://api.github.com/users/Dref360/repos",
"events_url": "https://api.github.com/users/Dref360/events{/privacy}",
"received_events_url": "https://api.github.com/users/Dref360/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | [
"Locally the `make quality` passes with the same dependencies. I would suggest upgrading flake8. (I can take care of it in another PR)\r\ncc @lhoestq "
] | 1,638,651,289,000 | 1,638,979,150,000 | null | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3382",
"html_url": "https://github.com/huggingface/datasets/pull/3382",
"diff_url": "https://github.com/huggingface/datasets/pull/3382.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3382.patch",
"merged_at": null
} | Add typing overloads to Dataset.__getitem__ for mypy
Fixes #3337
**Iterable**
Iterable from `collections` cannot have a type, so you can't do `Iterable[int]` for example. `typing` has a Generic version that builds upon the one from `collections`.
**Flake8**
I had to add `# noqa: F811`, this is a bug from Flake8.
datasets uses flake8==3.7.9 which released in October 2019 if I update flake8 (4.0.1), I no longer get these errors, but I did not want to make the update without your approval. (It also triggers other errors like no args in f-strings.) | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3382/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3382/timeline | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3381 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3381/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3381/comments | https://api.github.com/repos/huggingface/datasets/issues/3381/events | https://github.com/huggingface/datasets/issues/3381 | 1,071,283,879 | I_kwDODunzps4_2n6n | 3,381 | Unable to load audio_features from common_voice dataset | {
"login": "ashu5644",
"id": 8268102,
"node_id": "MDQ6VXNlcjgyNjgxMDI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8268102?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ashu5644",
"html_url": "https://github.com/ashu5644",
"followers_url": "https://api.github.com/users/ashu5644/followers",
"following_url": "https://api.github.com/users/ashu5644/following{/other_user}",
"gists_url": "https://api.github.com/users/ashu5644/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ashu5644/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ashu5644/subscriptions",
"organizations_url": "https://api.github.com/users/ashu5644/orgs",
"repos_url": "https://api.github.com/users/ashu5644/repos",
"events_url": "https://api.github.com/users/ashu5644/events{/privacy}",
"received_events_url": "https://api.github.com/users/ashu5644/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | null | [] | null | [
"Hi ! Feel free to access `batch[\"audio\"][\"array\"]` and `batch[\"audio\"][\"sampling_rate\"]` instead\r\n\r\n`datasets` 1.16 introduced some changes in `common_voice` and now the `path` field is no longer a path to a local file (but rather the path to the file in the archive it's extracted from)",
"Thanks for the information. It works.",
"Cool ! Closing this issue then"
] | 1,638,647,951,000 | 1,638,813,162,000 | 1,638,813,162,000 | NONE | null | null | null | ## Describe the bug
I am not able to load audio features from common_voice dataset
## Steps to reproduce the bug
```
from datasets import load_dataset
import torchaudio
test_dataset = load_dataset("common_voice", "hi", split="test[:2%]")
resampler = torchaudio.transforms.Resample(48_000, 16_000)
def speech_file_to_array_fn(batch):
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
```
## Expected results
This piece of code should return test_dataset after loading audio features.
## Actual results
Reusing dataset common_voice (/home/jovyan/.cache/huggingface/datasets/common_voice/hi/6.1.0/b879a355caa529b11f2249400b61cadd0d9433f334d5c60f8c7216ccedfecfe1)
/opt/conda/lib/python3.7/site-packages/transformers/configuration_utils.py:341: UserWarning: Passing `gradient_checkpointing` to a config initialization is deprecated and will be removed in v5 Transformers. Using `model.gradient_checkpointing_enable()` instead, or if you are using the `Trainer` API, pass `gradient_checkpointing=True` in your `TrainingArguments`.
"Passing `gradient_checkpointing` to a config initialization is deprecated and will be removed in v5 "
Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained.
0%| | 0/3 [00:00<?, ?ex/s]formats: can't open input file `common_voice_hi_23795358.mp3': No such file or directory
0%| | 0/3 [00:00<?, ?ex/s]
Traceback (most recent call last):
File "demo_file.py", line 23, in <module>
test_dataset = test_dataset.map(speech_file_to_array_fn)
File "/opt/conda/lib/python3.7/site-packages/datasets/arrow_dataset.py", line 2036, in map
desc=desc,
File "/opt/conda/lib/python3.7/site-packages/datasets/arrow_dataset.py", line 518, in wrapper
out: Union["Dataset", "DatasetDict"] = func(self, *args, **kwargs)
File "/opt/conda/lib/python3.7/site-packages/datasets/arrow_dataset.py", line 485, in wrapper
out: Union["Dataset", "DatasetDict"] = func(self, *args, **kwargs)
File "/opt/conda/lib/python3.7/site-packages/datasets/fingerprint.py", line 411, in wrapper
out = func(self, *args, **kwargs)
File "/opt/conda/lib/python3.7/site-packages/datasets/arrow_dataset.py", line 2368, in _map_single
example = apply_function_on_filtered_inputs(example, i, offset=offset)
File "/opt/conda/lib/python3.7/site-packages/datasets/arrow_dataset.py", line 2277, in apply_function_on_filtered_inputs
processed_inputs = function(*fn_args, *additional_args, **fn_kwargs)
File "/opt/conda/lib/python3.7/site-packages/datasets/arrow_dataset.py", line 1978, in decorated
result = f(decorated_item, *args, **kwargs)
File "demo_file.py", line 19, in speech_file_to_array_fn
speech_array, sampling_rate = torchaudio.load(batch["path"])
File "/opt/conda/lib/python3.7/site-packages/torchaudio/backend/sox_io_backend.py", line 154, in load
filepath, frame_offset, num_frames, normalize, channels_first, format)
RuntimeError: Error loading audio file: failed to open file common_voice_hi_23795358.mp3
## Environment info
- `datasets` version: 1.16.1
- Platform: Linux-4.14.243 with-debian-bullseye-sid
- Python version: 3.7.9
- PyArrow version: 6.0.1
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3381/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3381/timeline | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3380 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3380/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3380/comments | https://api.github.com/repos/huggingface/datasets/issues/3380/events | https://github.com/huggingface/datasets/issues/3380 | 1,071,166,270 | I_kwDODunzps4_2LM- | 3,380 | [Quick poll] Give your opinion on the future of the Hugging Face Open Source ecosystem! | {
"login": "LysandreJik",
"id": 30755778,
"node_id": "MDQ6VXNlcjMwNzU1Nzc4",
"avatar_url": "https://avatars.githubusercontent.com/u/30755778?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/LysandreJik",
"html_url": "https://github.com/LysandreJik",
"followers_url": "https://api.github.com/users/LysandreJik/followers",
"following_url": "https://api.github.com/users/LysandreJik/following{/other_user}",
"gists_url": "https://api.github.com/users/LysandreJik/gists{/gist_id}",
"starred_url": "https://api.github.com/users/LysandreJik/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/LysandreJik/subscriptions",
"organizations_url": "https://api.github.com/users/LysandreJik/orgs",
"repos_url": "https://api.github.com/users/LysandreJik/repos",
"events_url": "https://api.github.com/users/LysandreJik/events{/privacy}",
"received_events_url": "https://api.github.com/users/LysandreJik/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | [] | 1,638,609,513,000 | 1,638,609,513,000 | null | MEMBER | null | null | null | Thanks to all of you, `datasets` will pass 11.5k stars :star2: this week!
If you have a couple of minutes and want to participate in shaping the future of the ecosystem, please share your thoughts:
[**hf.co/oss-survey**](https://hf.co/oss-survey)
(please reply in the above feedback form rather than to this thread)
Thank you all on behalf of the HuggingFace team! 🤗 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3380/reactions",
"total_count": 3,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 2,
"rocket": 1,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3380/timeline | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3379 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3379/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3379/comments | https://api.github.com/repos/huggingface/datasets/issues/3379/events | https://github.com/huggingface/datasets/pull/3379 | 1,071,079,146 | PR_kwDODunzps4vYr7K | 3,379 | iter_archive on zipfiles with better compression type check | {
"login": "Mehdi2402",
"id": 56029953,
"node_id": "MDQ6VXNlcjU2MDI5OTUz",
"avatar_url": "https://avatars.githubusercontent.com/u/56029953?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Mehdi2402",
"html_url": "https://github.com/Mehdi2402",
"followers_url": "https://api.github.com/users/Mehdi2402/followers",
"following_url": "https://api.github.com/users/Mehdi2402/following{/other_user}",
"gists_url": "https://api.github.com/users/Mehdi2402/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Mehdi2402/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Mehdi2402/subscriptions",
"organizations_url": "https://api.github.com/users/Mehdi2402/orgs",
"repos_url": "https://api.github.com/users/Mehdi2402/repos",
"events_url": "https://api.github.com/users/Mehdi2402/events{/privacy}",
"received_events_url": "https://api.github.com/users/Mehdi2402/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | [
"Hello @lhoestq, thank you for your answer.\r\n\r\nI don't use pytest a lot so I think I might need some help on it :) but I tried some tests for `streaming_download_manager.py` only. I don't know how to test `download_manager.py` since we need to use local files.\r\n\r\n# Comments : \r\n* In **download_manager.py** I removed some unnecessary imports after the simplification of `_get_extraction_protocol_local`.\r\n* In **streaming_download_manager** I moved the raised Error as suggested.\r\n \r\n### I also started some tests on `StreamingDownloadManager()` :\r\n* Used an existing zipfile url and added a new one that has a folder and many files : \r\n```python\r\nTEST_GG_DRIVE_ZIPPED_URL = \"https://drive.google.com/uc?export=download&id=1k92sUfpHxKq8PXWRr7Y5aNHXwOCNUmqh\"\r\nTEST_GG_DRIVE2_ZIPPED_URL = \"https://drive.google.com/uc?export=download&id=1X4jyUBBbShyCRfD-vCO1ZvfqFXP3NEeU\"\r\n``` \r\n* **For now is being tested :**\r\n * Return type of the function : should be tuple\r\n * Files names\r\n * Files content\r\n * Added an `xfail` test for the gzip file, because I get a `zipfile.BadZipFile exception`.\r\n\r\n\r\n * And lastly, changed the test for `_get_extraction_protocol_throws` since it was moved to `_extract` : \r\n ```diff\r\n@pytest.mark.xfail(raises=NotImplementedError)\r\ndef test_streaming_dl_manager_get_extraction_protocol_throws(urlpath):\r\n- _get_extraction_protocol(urlpath)\r\n\r\n@pytest.mark.xfail(raises=NotImplementedError)\r\ndef test_streaming_dl_manager_get_extraction_protocol_throws(urlpath):\r\n+ StreamingDownloadManager()._extract(urlpath)\r\n```\r\n\r\n\r\n"
] | 1,638,579,888,000 | 1,638,926,631,000 | null | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3379",
"html_url": "https://github.com/huggingface/datasets/pull/3379",
"diff_url": "https://github.com/huggingface/datasets/pull/3379.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3379.patch",
"merged_at": null
} | Hello @lhoestq , thank you for your detailed answer on previous PR !
I made this new PR because I misused git on the previous one #3347.
Related issue #3272.
# Comments :
* For extension check I used the `_get_extraction_protocol` function in **download_manager.py** with a slight change and called it `_get_extraction_protocol_local`:
**I removed this part :**
```python
elif path.endswith(".tar.gz") or path.endswith(".tgz"):
raise NotImplementedError(
f"Extraction protocol for TAR archives like '{urlpath}' is not implemented in streaming mode. Please use `dl_manager.iter_archive` instead."
)
```
**And also changed :**
```diff
- extension = path.split(".")[-1]
+ extension = "tar" if path.endswith(".tar.gz") else path.split(".")[-1]
```
The reason for this is a compression like **.tar.gz** will be considered a **.gz** which is handled with **zipfile**, though **tar.gz** can only be opened using **tarfile**.
Please tell me if there's anything to change.
# Tasks :
- [x] download_manager.py
- [x] streaming_download_manager.py | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3379/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3379/timeline | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3378 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3378/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3378/comments | https://api.github.com/repos/huggingface/datasets/issues/3378/events | https://github.com/huggingface/datasets/pull/3378 | 1,070,580,126 | PR_kwDODunzps4vXF1D | 3,378 | Add The Pile subsets | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | [] | 1,638,537,294,000 | 1,638,958,348,000 | null | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3378",
"html_url": "https://github.com/huggingface/datasets/pull/3378",
"diff_url": "https://github.com/huggingface/datasets/pull/3378.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3378.patch",
"merged_at": null
} | Add The Pile subsets:
- pubmed
- ubuntu_irc
- europarl
- hacker_news
- nih_exporter
Close bigscience-workshop/data_tooling#301.
CC: @StellaAthena | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3378/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3378/timeline | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3377 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3377/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3377/comments | https://api.github.com/repos/huggingface/datasets/issues/3377/events | https://github.com/huggingface/datasets/pull/3377 | 1,070,562,907 | PR_kwDODunzps4vXCHn | 3,377 | COCO 🥥 on the 🤗 Hub? | {
"login": "merveenoyan",
"id": 53175384,
"node_id": "MDQ6VXNlcjUzMTc1Mzg0",
"avatar_url": "https://avatars.githubusercontent.com/u/53175384?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/merveenoyan",
"html_url": "https://github.com/merveenoyan",
"followers_url": "https://api.github.com/users/merveenoyan/followers",
"following_url": "https://api.github.com/users/merveenoyan/following{/other_user}",
"gists_url": "https://api.github.com/users/merveenoyan/gists{/gist_id}",
"starred_url": "https://api.github.com/users/merveenoyan/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/merveenoyan/subscriptions",
"organizations_url": "https://api.github.com/users/merveenoyan/orgs",
"repos_url": "https://api.github.com/users/merveenoyan/repos",
"events_url": "https://api.github.com/users/merveenoyan/events{/privacy}",
"received_events_url": "https://api.github.com/users/merveenoyan/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | [
"@mariosasko I fixed couple of bugs",
"TO-DO: \r\n- [x] Add unlabeled 2017 splits, train and validation splits of 2015\r\n- [ ] Add Class Labels as list instead"
] | 1,638,536,127,000 | 1,638,543,147,000 | null | CONTRIBUTOR | null | true | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3377",
"html_url": "https://github.com/huggingface/datasets/pull/3377",
"diff_url": "https://github.com/huggingface/datasets/pull/3377.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3377.patch",
"merged_at": null
} | This is a draft PR since I ran into few small problems.
I referred to this TFDS code: https://github.com/tensorflow/datasets/blob/2538a08c184d53b37bfcf52cc21dd382572a88f4/tensorflow_datasets/object_detection/coco.py
cc: @mariosasko | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3377/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 1,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3377/timeline | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3376 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3376/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3376/comments | https://api.github.com/repos/huggingface/datasets/issues/3376/events | https://github.com/huggingface/datasets/pull/3376 | 1,070,522,979 | PR_kwDODunzps4vW5sB | 3,376 | Update clue benchmark | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"The CI error is due to missing tags in the CLUE dataset card - merging !"
] | 1,638,533,161,000 | 1,638,972,882,000 | 1,638,972,881,000 | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3376",
"html_url": "https://github.com/huggingface/datasets/pull/3376",
"diff_url": "https://github.com/huggingface/datasets/pull/3376.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3376.patch",
"merged_at": 1638972881000
} | Fix #3374 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3376/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3376/timeline | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3375 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3375/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3375/comments | https://api.github.com/repos/huggingface/datasets/issues/3375/events | https://github.com/huggingface/datasets/pull/3375 | 1,070,454,913 | PR_kwDODunzps4vWrXz | 3,375 | Support streaming zipped dataset repo by passing only repo name | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | [
"I just tested and I think this only opens one file ? If there are several files in the ZIP, only the first one is opened. To open several files from a ZIP, one has to call `open` several times.\r\n\r\nWhat about updating the CSV loader to make it `download_and_extract` zip files, and open each extracted file ?",
"I have implemented the glob of ZIP files in the packaged modules:\r\n- csv\r\n- json\r\n- text"
] | 1,638,528,185,000 | 1,638,972,227,000 | null | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3375",
"html_url": "https://github.com/huggingface/datasets/pull/3375",
"diff_url": "https://github.com/huggingface/datasets/pull/3375.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3375.patch",
"merged_at": null
} | Fix #3373. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3375/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3375/timeline | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3374 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3374/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3374/comments | https://api.github.com/repos/huggingface/datasets/issues/3374/events | https://github.com/huggingface/datasets/issues/3374 | 1,070,426,462 | I_kwDODunzps4_zWle | 3,374 | NonMatchingChecksumError for the CLUE:cluewsc2020, chid, c3 and tnews | {
"login": "Namco0816",
"id": 34687537,
"node_id": "MDQ6VXNlcjM0Njg3NTM3",
"avatar_url": "https://avatars.githubusercontent.com/u/34687537?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Namco0816",
"html_url": "https://github.com/Namco0816",
"followers_url": "https://api.github.com/users/Namco0816/followers",
"following_url": "https://api.github.com/users/Namco0816/following{/other_user}",
"gists_url": "https://api.github.com/users/Namco0816/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Namco0816/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Namco0816/subscriptions",
"organizations_url": "https://api.github.com/users/Namco0816/orgs",
"repos_url": "https://api.github.com/users/Namco0816/repos",
"events_url": "https://api.github.com/users/Namco0816/events{/privacy}",
"received_events_url": "https://api.github.com/users/Namco0816/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"type": "User",
"site_admin": false
}
] | null | [
"Seems like the issue still exists,:\r\n`Downloading and preparing dataset clue/chid (download: 127.15 MiB, generated: 259.71 MiB, post-processed: Unknown size, total: 386.86 MiB) to /mnt/cache/tanhaochen/.cache/huggingface/datasets/clue/chid/1.0.0/e55b490cb7809dcd8db31b9a87119f2e2ec87cdc060da8a9ac070b070ca3e379...\r\nTraceback (most recent call last):\r\n File \"/mnt/cache/tanhaochen/PromptCLUE/test_datasets.py\", line 3, in <module>\r\n cluewsc2020 = datasets.load_dataset(\"clue\",\"chid\")\r\n File \"/mnt/cache/tanhaochen/dependencies/datasets/src/datasets/load.py\", line 1667, in load_dataset\r\n builder_instance.download_and_prepare(\r\n File \"/mnt/cache/tanhaochen/dependencies/datasets/src/datasets/builder.py\", line 593, in download_and_prepare\r\n self._download_and_prepare(\r\n File \"/mnt/cache/tanhaochen/dependencies/datasets/src/datasets/builder.py\", line 663, in _download_and_prepare\r\n verify_checksums(\r\n File \"/mnt/cache/tanhaochen/dependencies/datasets/src/datasets/utils/info_utils.py\", line 40, in verify_checksums\r\n raise NonMatchingChecksumError(error_msg + str(bad_urls))\r\ndatasets.utils.info_utils.NonMatchingChecksumError: Checksums didn't match for dataset source files:\r\n['https://storage.googleapis.com/cluebenchmark/tasks/chid_public.zip']\r\n`",
"Hi,\r\n\r\nthe fix hasn't been merged yet (it should be merged early next week)."
] | 1,638,526,254,000 | 1,638,972,881,000 | 1,638,972,881,000 | NONE | null | null | null | Hi, it seems like there are updates in cluewsc2020, chid, c3 and tnews, since i could not load them due to the checksum error. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3374/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3374/timeline | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3373 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3373/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3373/comments | https://api.github.com/repos/huggingface/datasets/issues/3373/events | https://github.com/huggingface/datasets/issues/3373 | 1,070,406,391 | I_kwDODunzps4_zRr3 | 3,373 | Support streaming zipped CSV dataset repo by passing only repo name | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
}
] | open | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
}
] | null | [] | 1,638,524,904,000 | 1,638,526,949,000 | null | MEMBER | null | null | null | Given a community 🤗 dataset repository containing only a zipped CSV file (only raw data, no loading script), I would like to load it in streaming mode without passing `data_files`:
```
ds_name = "bigscience-catalogue-data/vietnamese_poetry_from_fsoft_ai_lab"
ds = load_dataset(ds_name, split="train", streaming=True, use_auth_token=True)
item = next(iter(ds))
```
Currently, it gives a `FileNotFoundError` because there is no glob (no "\*" after "zip://": "zip://*") in the passed URL:
```
'zip://::https://huggingface.co/datasets/bigscience-catalogue-data/vietnamese_poetry_from_fsoft_ai_lab/resolve/e5d45f1bd9a8a798cc14f0a45ebc1ce91907c792/poems_dataset.zip'
```
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3373/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3373/timeline | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3372 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3372/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3372/comments | https://api.github.com/repos/huggingface/datasets/issues/3372/events | https://github.com/huggingface/datasets/issues/3372 | 1,069,948,178 | I_kwDODunzps4_xh0S | 3,372 | [SEO improvement] Add Dataset Metadata to make datasets indexable | {
"login": "cakiki",
"id": 3664563,
"node_id": "MDQ6VXNlcjM2NjQ1NjM=",
"avatar_url": "https://avatars.githubusercontent.com/u/3664563?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/cakiki",
"html_url": "https://github.com/cakiki",
"followers_url": "https://api.github.com/users/cakiki/followers",
"following_url": "https://api.github.com/users/cakiki/following{/other_user}",
"gists_url": "https://api.github.com/users/cakiki/gists{/gist_id}",
"starred_url": "https://api.github.com/users/cakiki/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/cakiki/subscriptions",
"organizations_url": "https://api.github.com/users/cakiki/orgs",
"repos_url": "https://api.github.com/users/cakiki/repos",
"events_url": "https://api.github.com/users/cakiki/events{/privacy}",
"received_events_url": "https://api.github.com/users/cakiki/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
}
] | open | false | null | [] | null | [] | 1,638,476,467,000 | 1,638,476,467,000 | null | NONE | null | null | null | Some people who host datasets on github seem to include a table of metadata at the end of their README.md to make the dataset indexable by [Google Dataset Search](https://datasetsearch.research.google.com/) (See [here](https://github.com/google-research/google-research/tree/master/goemotions#dataset-metadata) and [here](https://github.com/cvdfoundation/google-landmark#dataset-metadata)). This could be a useful addition to canonical datasets; perhaps even community datasets.
I'll include a screenshot (as opposed to markdown) as an example so as not to have a github issue indexed as a dataset:
> 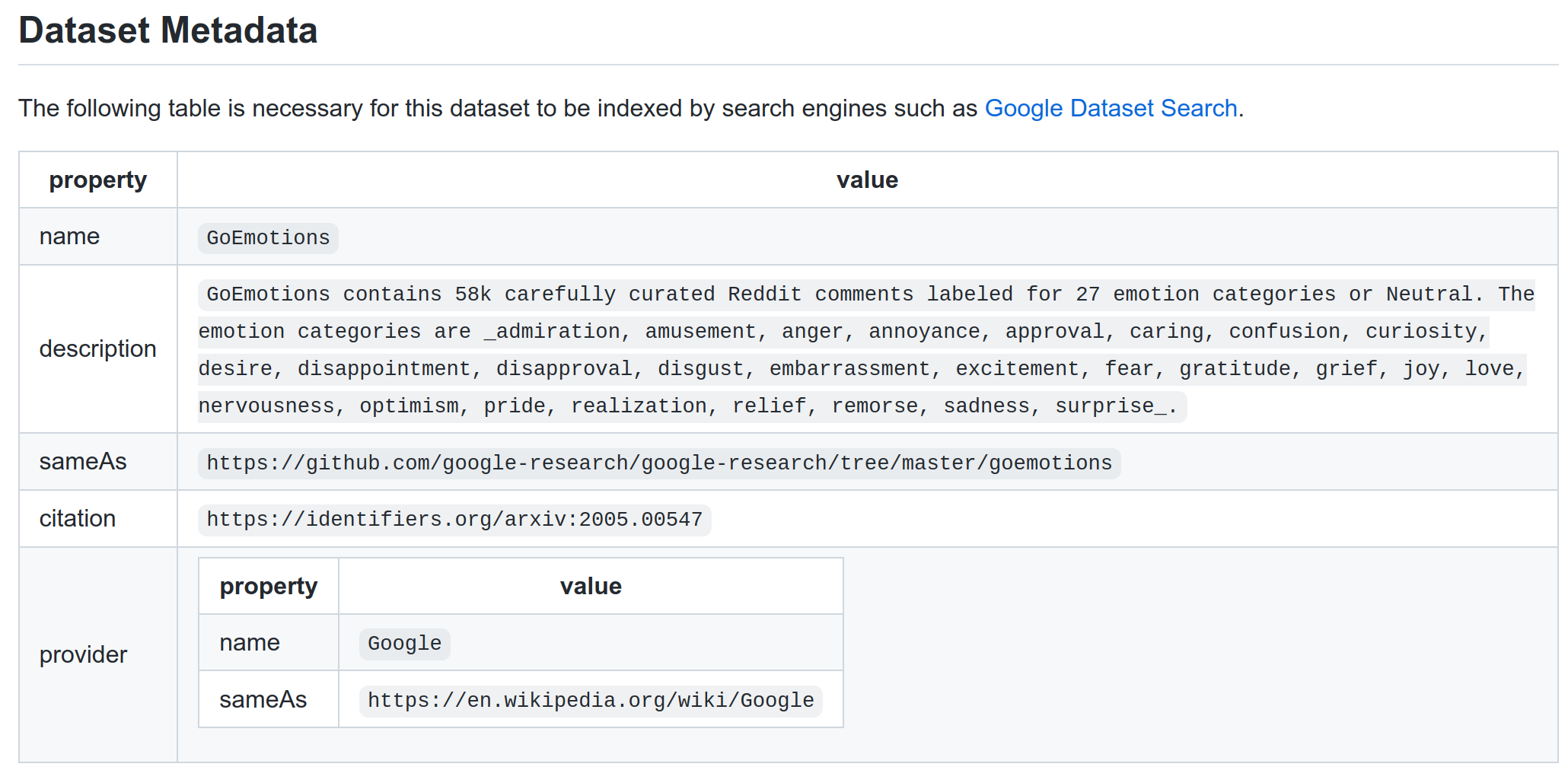
**_PS: It might very well be the case that this is already covered by some other markdown magic I'm not aware of._**
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3372/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3372/timeline | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3371 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3371/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3371/comments | https://api.github.com/repos/huggingface/datasets/issues/3371/events | https://github.com/huggingface/datasets/pull/3371 | 1,069,821,335 | PR_kwDODunzps4vUnbp | 3,371 | New: Americas NLI dataset | {
"login": "fdschmidt93",
"id": 39233597,
"node_id": "MDQ6VXNlcjM5MjMzNTk3",
"avatar_url": "https://avatars.githubusercontent.com/u/39233597?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/fdschmidt93",
"html_url": "https://github.com/fdschmidt93",
"followers_url": "https://api.github.com/users/fdschmidt93/followers",
"following_url": "https://api.github.com/users/fdschmidt93/following{/other_user}",
"gists_url": "https://api.github.com/users/fdschmidt93/gists{/gist_id}",
"starred_url": "https://api.github.com/users/fdschmidt93/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/fdschmidt93/subscriptions",
"organizations_url": "https://api.github.com/users/fdschmidt93/orgs",
"repos_url": "https://api.github.com/users/fdschmidt93/repos",
"events_url": "https://api.github.com/users/fdschmidt93/events{/privacy}",
"received_events_url": "https://api.github.com/users/fdschmidt93/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,638,467,099,000 | 1,638,971,892,000 | 1,638,971,891,000 | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3371",
"html_url": "https://github.com/huggingface/datasets/pull/3371",
"diff_url": "https://github.com/huggingface/datasets/pull/3371.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3371.patch",
"merged_at": 1638971891000
} | This PR adds the [Americas NLI](https://arxiv.org/abs/2104.08726) dataset, extension of XNLI to 10 low-resource indigenous languages spoken in the Americas: Ashaninka, Aymara, Bribri, Guarani, Nahuatl, Otomi, Quechua, Raramuri, Shipibo-Konibo, and Wixarika.
One odd thing (not sure) is that I had to set
`datasets-cli dummy_data ./datasets/americas_nli/ --auto_generate --n_lines 7500`
`n_lines` very large to successfully generate the dummy files for all the subsets. Happy to get some guidance here.
Otherwise, I hope everything is in order :)
e: missed a step, onto fixing the tests
e2: there you go -- hope it's ok to have added more languages with their ISO codes to `languages.json`, need those tests to pass :laughing: | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3371/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 1,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3371/timeline | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3370 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3370/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3370/comments | https://api.github.com/repos/huggingface/datasets/issues/3370/events | https://github.com/huggingface/datasets/pull/3370 | 1,069,735,423 | PR_kwDODunzps4vUVA3 | 3,370 | Document a training loop for streaming dataset | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,638,461,820,000 | 1,638,538,475,000 | 1,638,538,474,000 | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3370",
"html_url": "https://github.com/huggingface/datasets/pull/3370",
"diff_url": "https://github.com/huggingface/datasets/pull/3370.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3370.patch",
"merged_at": 1638538474000
} | I added some docs about streaming dataset. In particular I added two subsections:
- one on how to use `map` for preprocessing
- one on how to use a streaming dataset in a pytorch training loop
cc @patrickvonplaten @stevhliu if you have some comments
cc @Rocketknight1 later we can add the one for TF and I might need your help ^^' | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3370/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3370/timeline | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3369 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3369/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3369/comments | https://api.github.com/repos/huggingface/datasets/issues/3369/events | https://github.com/huggingface/datasets/issues/3369 | 1,069,587,674 | I_kwDODunzps4_wJza | 3,369 | [Audio] Allow resampling for audio datasets in streaming mode | {
"login": "patrickvonplaten",
"id": 23423619,
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patrickvonplaten",
"html_url": "https://github.com/patrickvonplaten",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
}
] | open | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
},
{
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
}
] | null | [] | 1,638,453,897,000 | 1,638,453,908,000 | null | MEMBER | null | null | null | Many audio datasets like Common Voice always need to be resampled. This can very easily be done in non-streaming mode as follows:
```python
from datasets import load_dataset
ds = load_dataset("common_voice", "ab", split="test")
ds = ds.cast_column("audio", Audio(sampling_rate=16_000))
```
However in streaming mode it fails currently:
```python
from datasets import load_dataset
ds = load_dataset("common_voice", "ab", split="test", streaming=True)
ds = ds.cast_column("audio", Audio(sampling_rate=16_000))
```
with the following error:
```
AttributeError: 'IterableDataset' object has no attribute 'cast_column'
```
It would be great if we could add such a feature (I'm not 100% sure though how complex this would be) | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3369/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3369/timeline | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3368 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3368/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3368/comments | https://api.github.com/repos/huggingface/datasets/issues/3368/events | https://github.com/huggingface/datasets/pull/3368 | 1,069,403,624 | PR_kwDODunzps4vTObo | 3,368 | Fix dict source_datasets tagset validator | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,638,442,340,000 | 1,638,460,118,000 | 1,638,460,117,000 | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3368",
"html_url": "https://github.com/huggingface/datasets/pull/3368",
"diff_url": "https://github.com/huggingface/datasets/pull/3368.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3368.patch",
"merged_at": 1638460117000
} | Currently, the `source_datasets` tag validation does not support passing a dict with configuration keys.
This PR:
- Extends `tagset_validator` to support regex tags
- Uses `tagset_validator` to validate dict `source_datasets` | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3368/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3368/timeline | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3367 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3367/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3367/comments | https://api.github.com/repos/huggingface/datasets/issues/3367/events | https://github.com/huggingface/datasets/pull/3367 | 1,069,241,274 | PR_kwDODunzps4vSsfk | 3,367 | Fix typo in other-structured-to-text task tag | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,638,432,147,000 | 1,638,461,234,000 | 1,638,461,233,000 | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3367",
"html_url": "https://github.com/huggingface/datasets/pull/3367",
"diff_url": "https://github.com/huggingface/datasets/pull/3367.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3367.patch",
"merged_at": 1638461233000
} | Fix typo in task tag:
- `other-stuctured-to-text` (before)
- `other-structured-to-text` (now) | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3367/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3367/timeline | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3366 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3366/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3366/comments | https://api.github.com/repos/huggingface/datasets/issues/3366/events | https://github.com/huggingface/datasets/issues/3366 | 1,069,214,022 | I_kwDODunzps4_uulG | 3,366 | Add multimodal datasets | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 2067376369,
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request",
"name": "dataset request",
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset"
}
] | open | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
}
] | null | [] | 1,638,429,844,000 | 1,638,430,413,000 | null | MEMBER | null | null | null | Epic issue to track the addition of multimodal datasets:
- [ ] #2526
- [ ] #1842
- [ ] #1810
Instructions to add a new dataset can be found [here](https://github.com/huggingface/datasets/blob/master/ADD_NEW_DATASET.md).
@VictorSanh feel free to add and sort by priority any interesting dataset. I have added the multimodal dataset requests which were already present as issues. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3366/reactions",
"total_count": 2,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 1,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 1
} | https://api.github.com/repos/huggingface/datasets/issues/3366/timeline | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3365 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3365/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3365/comments | https://api.github.com/repos/huggingface/datasets/issues/3365/events | https://github.com/huggingface/datasets/issues/3365 | 1,069,195,887 | I_kwDODunzps4_uqJv | 3,365 | Add task tags for multimodal datasets | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
}
] | open | false | null | [] | null | [] | 1,638,428,300,000 | 1,638,430,389,000 | null | MEMBER | null | null | null | ## **Is your feature request related to a problem? Please describe.**
Currently, task tags are either exclusively related to text or speech processing:
- https://github.com/huggingface/datasets/blob/master/src/datasets/utils/resources/tasks.json
## **Describe the solution you'd like**
We should also add tasks related to:
- multimodality
- image
- video
CC: @VictorSanh @lewtun @lhoestq @merveenoyan @SBrandeis | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3365/reactions",
"total_count": 3,
"+1": 3,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3365/timeline | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3364 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3364/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3364/comments | https://api.github.com/repos/huggingface/datasets/issues/3364/events | https://github.com/huggingface/datasets/pull/3364 | 1,068,851,196 | PR_kwDODunzps4vRaxq | 3,364 | Use the Audio feature in the AutomaticSpeechRecognition template | {
"login": "anton-l",
"id": 26864830,
"node_id": "MDQ6VXNlcjI2ODY0ODMw",
"avatar_url": "https://avatars.githubusercontent.com/u/26864830?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/anton-l",
"html_url": "https://github.com/anton-l",
"followers_url": "https://api.github.com/users/anton-l/followers",
"following_url": "https://api.github.com/users/anton-l/following{/other_user}",
"gists_url": "https://api.github.com/users/anton-l/gists{/gist_id}",
"starred_url": "https://api.github.com/users/anton-l/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/anton-l/subscriptions",
"organizations_url": "https://api.github.com/users/anton-l/orgs",
"repos_url": "https://api.github.com/users/anton-l/repos",
"events_url": "https://api.github.com/users/anton-l/events{/privacy}",
"received_events_url": "https://api.github.com/users/anton-l/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | [] | 1,638,391,346,000 | 1,638,449,170,000 | null | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3364",
"html_url": "https://github.com/huggingface/datasets/pull/3364",
"diff_url": "https://github.com/huggingface/datasets/pull/3364.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3364.patch",
"merged_at": null
} | This updates the ASR template and all supported datasets to use the `Audio` feature | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3364/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3364/timeline | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3363 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3363/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3363/comments | https://api.github.com/repos/huggingface/datasets/issues/3363/events | https://github.com/huggingface/datasets/pull/3363 | 1,068,824,340 | PR_kwDODunzps4vRVCl | 3,363 | Update URL of Jeopardy! dataset | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Closing this PR in favor of #3266."
] | 1,638,389,290,000 | 1,638,534,901,000 | 1,638,534,901,000 | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3363",
"html_url": "https://github.com/huggingface/datasets/pull/3363",
"diff_url": "https://github.com/huggingface/datasets/pull/3363.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3363.patch",
"merged_at": null
} | Updates the URL of the Jeopardy! dataset.
Fix #3361 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3363/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3363/timeline | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3362 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3362/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3362/comments | https://api.github.com/repos/huggingface/datasets/issues/3362/events | https://github.com/huggingface/datasets/pull/3362 | 1,068,809,768 | PR_kwDODunzps4vRR2r | 3,362 | Adapt image datasets | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | [
"This PR can be merged after #3163 is merged (this PR is pretty big because I was working on the forked branch).\r\n\r\n@lhoestq @albertvillanova Could you please take a look at the changes in `src/datasets/utils/streaming_download_manager.py`? These changes were required to support streaming of the `cats_vs_dogs` and the `beans` datasets.",
"The CI failures are due to the missing fields in the README files."
] | 1,638,388,321,000 | 1,638,887,142,000 | null | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3362",
"html_url": "https://github.com/huggingface/datasets/pull/3362",
"diff_url": "https://github.com/huggingface/datasets/pull/3362.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3362.patch",
"merged_at": null
} | This PR:
* adapts the ImageClassification template to use the new Image feature
* adapts the following datasets to use the new Image feature:
* beans (+ fixes streaming)
* cast_vs_dogs (+ fixes streaming)
* cifar10
* cifar100
* fashion_mnist
* mnist
* head_qa
cc @nateraw | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3362/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3362/timeline | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3361 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3361/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3361/comments | https://api.github.com/repos/huggingface/datasets/issues/3361/events | https://github.com/huggingface/datasets/issues/3361 | 1,068,736,268 | I_kwDODunzps4_s58M | 3,361 | Jeopardy _URL access denied | {
"login": "tianjianjiang",
"id": 4812544,
"node_id": "MDQ6VXNlcjQ4MTI1NDQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/4812544?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/tianjianjiang",
"html_url": "https://github.com/tianjianjiang",
"followers_url": "https://api.github.com/users/tianjianjiang/followers",
"following_url": "https://api.github.com/users/tianjianjiang/following{/other_user}",
"gists_url": "https://api.github.com/users/tianjianjiang/gists{/gist_id}",
"starred_url": "https://api.github.com/users/tianjianjiang/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/tianjianjiang/subscriptions",
"organizations_url": "https://api.github.com/users/tianjianjiang/orgs",
"repos_url": "https://api.github.com/users/tianjianjiang/repos",
"events_url": "https://api.github.com/users/tianjianjiang/events{/privacy}",
"received_events_url": "https://api.github.com/users/tianjianjiang/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | null | [] | null | [] | 1,638,382,893,000 | 1,638,789,391,000 | 1,638,789,391,000 | NONE | null | null | null | ## Describe the bug
http://skeeto.s3.amazonaws.com/share/JEOPARDY_QUESTIONS1.json.gz returns Access Denied now.
However, https://drive.google.com/file/d/0BwT5wj_P7BKXb2hfM3d2RHU1ckE/view?usp=sharing from the original Reddit post https://www.reddit.com/r/datasets/comments/1uyd0t/200000_jeopardy_questions_in_a_json_file/ may work.
## Steps to reproduce the bug
```shell
> python
Python 3.7.12 (default, Sep 5 2021, 08:34:29)
[Clang 11.0.3 (clang-1103.0.32.62)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
```
```python
>>> from datasets import load_dataset
>>> load_dataset("jeopardy")
```
## Expected results
The download completes.
## Actual results
```shell
Downloading: 4.18kB [00:00, 1.60MB/s]
Downloading: 2.03kB [00:00, 1.04MB/s]
Using custom data configuration default
Downloading and preparing dataset jeopardy/default (download: 12.13 MiB, generated: 34.46 MiB, post-processed: Unknown size, total: 46.59 MiB) to /Users/mike/.cache/huggingface/datasets/jeopardy/default/0.1.0/25ee3e4a73755e637b8810f6493fd36e4523dea3ca8a540529d0a6e24c7f9810...
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/Users/mike/Library/Caches/pypoetry/virtualenvs/promptsource-hsdAcWsQ-py3.7/lib/python3.7/site-packages/datasets/load.py", line 1632, in load_dataset
use_auth_token=use_auth_token,
File "/Users/mike/Library/Caches/pypoetry/virtualenvs/promptsource-hsdAcWsQ-py3.7/lib/python3.7/site-packages/datasets/builder.py", line 608, in download_and_prepare
dl_manager=dl_manager, verify_infos=verify_infos, **download_and_prepare_kwargs
File "/Users/mike/Library/Caches/pypoetry/virtualenvs/promptsource-hsdAcWsQ-py3.7/lib/python3.7/site-packages/datasets/builder.py", line 675, in _download_and_prepare
split_generators = self._split_generators(dl_manager, **split_generators_kwargs)
File "/Users/mike/.cache/huggingface/modules/datasets_modules/datasets/jeopardy/25ee3e4a73755e637b8810f6493fd36e4523dea3ca8a540529d0a6e24c7f9810/jeopardy.py", line 72, in _split_generators
filepath = dl_manager.download_and_extract(_DATA_URL)
File "/Users/mike/Library/Caches/pypoetry/virtualenvs/promptsource-hsdAcWsQ-py3.7/lib/python3.7/site-packages/datasets/utils/download_manager.py", line 284, in download_and_extract
return self.extract(self.download(url_or_urls))
File "/Users/mike/Library/Caches/pypoetry/virtualenvs/promptsource-hsdAcWsQ-py3.7/lib/python3.7/site-packages/datasets/utils/download_manager.py", line 197, in download
download_func, url_or_urls, map_tuple=True, num_proc=download_config.num_proc, disable_tqdm=False
File "/Users/mike/Library/Caches/pypoetry/virtualenvs/promptsource-hsdAcWsQ-py3.7/lib/python3.7/site-packages/datasets/utils/py_utils.py", line 197, in map_nested
return function(data_struct)
File "/Users/mike/Library/Caches/pypoetry/virtualenvs/promptsource-hsdAcWsQ-py3.7/lib/python3.7/site-packages/datasets/utils/download_manager.py", line 217, in _download
return cached_path(url_or_filename, download_config=download_config)
File "/Users/mike/Library/Caches/pypoetry/virtualenvs/promptsource-hsdAcWsQ-py3.7/lib/python3.7/site-packages/datasets/utils/file_utils.py", line 305, in cached_path
use_auth_token=download_config.use_auth_token,
File "/Users/mike/Library/Caches/pypoetry/virtualenvs/promptsource-hsdAcWsQ-py3.7/lib/python3.7/site-packages/datasets/utils/file_utils.py", line 594, in get_from_cache
raise ConnectionError("Couldn't reach {}".format(url))
ConnectionError: Couldn't reach http://skeeto.s3.amazonaws.com/share/JEOPARDY_QUESTIONS1.json.gz
```
---
```shell
> curl http://skeeto.s3.amazonaws.com/share/JEOPARDY_QUESTIONS1.json.gz
```
```xml
<?xml version="1.0" encoding="UTF-8"?>
<Error><Code>AccessDenied</Code><Message>Access Denied</Message><RequestId>70Y9R36XNPEQXMGV</RequestId><HostId>G6F5AK4qo7JdaEdKGMtS0P6gdLPeFOdEfSEfvTOZEfk9km0/jAfp08QLfKSTFFj1oWIKoAoBehM=</HostId></Error>
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.14.0
- Platform: macOS Catalina 10.15.7
- Python version: 3.7.12
- PyArrow version: 6.0.1
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3361/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3361/timeline | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3360 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3360/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3360/comments | https://api.github.com/repos/huggingface/datasets/issues/3360/events | https://github.com/huggingface/datasets/pull/3360 | 1,068,724,697 | PR_kwDODunzps4vQ_16 | 3,360 | Add The Pile USPTO subset | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,638,382,085,000 | 1,638,531,929,000 | 1,638,531,928,000 | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3360",
"html_url": "https://github.com/huggingface/datasets/pull/3360",
"diff_url": "https://github.com/huggingface/datasets/pull/3360.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3360.patch",
"merged_at": 1638531927000
} | Add:
- USPTO subset of The Pile: "uspto" config
Close bigscience-workshop/data_tooling#297.
CC: @StellaAthena | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3360/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3360/timeline | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3359 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3359/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3359/comments | https://api.github.com/repos/huggingface/datasets/issues/3359/events | https://github.com/huggingface/datasets/pull/3359 | 1,068,638,213 | PR_kwDODunzps4vQtI0 | 3,359 | Add The Pile Free Law subset | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"@albertvillanova Is there a specific reason you’re adding the Pile under “the” instead of under “pile”? That does not appear to be consistent with other datasets.",
"Hi @StellaAthena,\r\n\r\nI asked myself the same question, but at the end I decided to be consistent with previously added Pile subsets:\r\n- #2817\r\n\r\nI guess the reason is to stress that the definite article is always used before the name of the dataset (your site says: \"The Pile. An 800GB Dataset of Diverse Text for Language Modeling\"). Other datasets are not usually preceded by the definite article, like \"the SQuAD\" or \"the GLUE\" or \"the Common Voice\"...\r\n\r\nCC: @lhoestq ",
"> I guess the reason is to stress that the definite article is always used before the name of the dataset (your site says: \"The Pile. An 800GB Dataset of Diverse Text for Language Modeling\").\r\n\r\nYes that's because of this that it starts with \"the\""
] | 1,638,377,164,000 | 1,638,785,537,000 | 1,638,379,844,000 | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3359",
"html_url": "https://github.com/huggingface/datasets/pull/3359",
"diff_url": "https://github.com/huggingface/datasets/pull/3359.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3359.patch",
"merged_at": 1638379843000
} | Add:
- Free Law subset of The Pile: "free_law" config
Close bigscience-workshop/data_tooling#75.
CC: @StellaAthena | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3359/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3359/timeline | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3358 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3358/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3358/comments | https://api.github.com/repos/huggingface/datasets/issues/3358/events | https://github.com/huggingface/datasets/issues/3358 | 1,068,623,216 | I_kwDODunzps4_seVw | 3,358 | add new field, and get errors | {
"login": "yanllearnn",
"id": 38966558,
"node_id": "MDQ6VXNlcjM4OTY2NTU4",
"avatar_url": "https://avatars.githubusercontent.com/u/38966558?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/yanllearnn",
"html_url": "https://github.com/yanllearnn",
"followers_url": "https://api.github.com/users/yanllearnn/followers",
"following_url": "https://api.github.com/users/yanllearnn/following{/other_user}",
"gists_url": "https://api.github.com/users/yanllearnn/gists{/gist_id}",
"starred_url": "https://api.github.com/users/yanllearnn/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/yanllearnn/subscriptions",
"organizations_url": "https://api.github.com/users/yanllearnn/orgs",
"repos_url": "https://api.github.com/users/yanllearnn/repos",
"events_url": "https://api.github.com/users/yanllearnn/events{/privacy}",
"received_events_url": "https://api.github.com/users/yanllearnn/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Hi, \r\n\r\ncould you please post this question on our [Forum](https://discuss.huggingface.co/) as we keep issues for bugs and feature requests? ",
"> Hi,\r\n> \r\n> could you please post this question on our [Forum](https://discuss.huggingface.co/) as we keep issues for bugs and feature requests?\r\n\r\nok."
] | 1,638,376,538,000 | 1,638,411,982,000 | 1,638,411,982,000 | NONE | null | null | null | after adding new field **tokenized_examples["example_id"]**, and get errors below,
I think it is due to changing data to tensor, and **tokenized_examples["example_id"]** is string list
**all fields**
```
***************** train_dataset 1: Dataset({
features: ['attention_mask', 'end_positions', 'example_id', 'input_ids', 'start_positions', 'token_type_ids'],
num_rows: 87714
})
```
**Errors**
```
Traceback (most recent call last):
File "/usr/local/lib/python3.7/site-packages/transformers/tokenization_utils_base.py", line 705, in convert_to_tensors
tensor = as_tensor(value)
ValueError: too many dimensions 'str'
``` | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3358/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3358/timeline | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3357 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3357/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3357/comments | https://api.github.com/repos/huggingface/datasets/issues/3357/events | https://github.com/huggingface/datasets/pull/3357 | 1,068,607,382 | PR_kwDODunzps4vQmcL | 3,357 | Update README.md | {
"login": "apergo-ai",
"id": 68908804,
"node_id": "MDQ6VXNlcjY4OTA4ODA0",
"avatar_url": "https://avatars.githubusercontent.com/u/68908804?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/apergo-ai",
"html_url": "https://github.com/apergo-ai",
"followers_url": "https://api.github.com/users/apergo-ai/followers",
"following_url": "https://api.github.com/users/apergo-ai/following{/other_user}",
"gists_url": "https://api.github.com/users/apergo-ai/gists{/gist_id}",
"starred_url": "https://api.github.com/users/apergo-ai/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/apergo-ai/subscriptions",
"organizations_url": "https://api.github.com/users/apergo-ai/orgs",
"repos_url": "https://api.github.com/users/apergo-ai/repos",
"events_url": "https://api.github.com/users/apergo-ai/events{/privacy}",
"received_events_url": "https://api.github.com/users/apergo-ai/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | [] | 1,638,375,646,000 | 1,638,375,646,000 | null | NONE | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3357",
"html_url": "https://github.com/huggingface/datasets/pull/3357",
"diff_url": "https://github.com/huggingface/datasets/pull/3357.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3357.patch",
"merged_at": null
} | After having worked a bit with the dataset.
As far as I know, it is solely in English (en-US). There are only a few mails in Spanish, French or German (less than a dozen I would estimate). | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3357/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3357/timeline | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3356 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3356/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3356/comments | https://api.github.com/repos/huggingface/datasets/issues/3356/events | https://github.com/huggingface/datasets/pull/3356 | 1,068,503,932 | PR_kwDODunzps4vQQLD | 3,356 | to_tf_dataset() refactor | {
"login": "Rocketknight1",
"id": 12866554,
"node_id": "MDQ6VXNlcjEyODY2NTU0",
"avatar_url": "https://avatars.githubusercontent.com/u/12866554?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Rocketknight1",
"html_url": "https://github.com/Rocketknight1",
"followers_url": "https://api.github.com/users/Rocketknight1/followers",
"following_url": "https://api.github.com/users/Rocketknight1/following{/other_user}",
"gists_url": "https://api.github.com/users/Rocketknight1/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Rocketknight1/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Rocketknight1/subscriptions",
"organizations_url": "https://api.github.com/users/Rocketknight1/orgs",
"repos_url": "https://api.github.com/users/Rocketknight1/repos",
"events_url": "https://api.github.com/users/Rocketknight1/events{/privacy}",
"received_events_url": "https://api.github.com/users/Rocketknight1/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | [
"Also, please don't merge yet - I need to make sure all the code samples and notebooks have a collate_fn specified, since we're removing the ability for this method to work without one!",
"Hi @lhoestq @mariosasko, the other PRs this was depending on in Transformers and huggingface/notebooks are now merged, so this is ready to go. Do you want to take one more look at it, or are you happy at this point?",
"The documentation for the method is fine, it doesn't need to be changed, but the tutorial notebook definitely looks a little out of date. Let me see what I can do!",
"@lhoestq I rewrote the last bit of the notebook - let me know what you think!"
] | 1,638,370,470,000 | 1,638,984,822,000 | null | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3356",
"html_url": "https://github.com/huggingface/datasets/pull/3356",
"diff_url": "https://github.com/huggingface/datasets/pull/3356.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3356.patch",
"merged_at": null
} | This is the promised cleanup to `to_tf_dataset()` now that the course is out of the way! The main changes are:
- A collator is always required (there was way too much hackiness making things like labels work without it)
- Lots of cleanup and a lot of code moved to `_get_output_signature`
- Should now handle it gracefully when the data collator adds unexpected columns | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3356/reactions",
"total_count": 3,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 3,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3356/timeline | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3355 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3355/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3355/comments | https://api.github.com/repos/huggingface/datasets/issues/3355/events | https://github.com/huggingface/datasets/pull/3355 | 1,068,468,573 | PR_kwDODunzps4vQIoy | 3,355 | Extend support for streaming datasets that use pd.read_excel | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | [] | 1,638,368,563,000 | 1,638,876,966,000 | null | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3355",
"html_url": "https://github.com/huggingface/datasets/pull/3355",
"diff_url": "https://github.com/huggingface/datasets/pull/3355.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3355.patch",
"merged_at": null
} | This PR fixes error:
```
ValueError: Cannot seek streaming HTTP file
```
CC: @severo | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3355/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3355/timeline | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3354 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3354/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3354/comments | https://api.github.com/repos/huggingface/datasets/issues/3354/events | https://github.com/huggingface/datasets/pull/3354 | 1,068,307,271 | PR_kwDODunzps4vPl9d | 3,354 | Remove duplicate name from dataset cards | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,638,359,140,000 | 1,638,364,470,000 | 1,638,364,469,000 | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3354",
"html_url": "https://github.com/huggingface/datasets/pull/3354",
"diff_url": "https://github.com/huggingface/datasets/pull/3354.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3354.patch",
"merged_at": 1638364469000
} | Remove duplicate name from dataset card for:
- ajgt_twitter_ar
- emotone_ar | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3354/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3354/timeline | null | true |
Dataset Card for GitHub Issues
Dataset Summary
GitHub Issues is a dataset consisting of GitHub issues and pull requests associated with the 🤗 Datasets repository. It is intended for educational purposes and can be used for semantic search or multilabel text classification. The contents of each GitHub issue are in English and concern the domain of datasets for NLP, computer vision, and beyond.
Supported Tasks and Leaderboards
For each of the tasks tagged for this dataset, give a brief description of the tag, metrics, and suggested models (with a link to their HuggingFace implementation if available). Give a similar description of tasks that were not covered by the structured tag set (repace the task-category-tag with an appropriate other:other-task-name).
task-category-tag: The dataset can be used to train a model for [TASK NAME], which consists in [TASK DESCRIPTION]. Success on this task is typically measured by achieving a high/low metric name. The (model name or model class) model currently achieves the following score. [IF A LEADERBOARD IS AVAILABLE]: This task has an active leaderboard which can be found at leaderboard url and ranks models based on metric name while also reporting other metric name.
Languages
Provide a brief overview of the languages represented in the dataset. Describe relevant details about specifics of the language such as whether it is social media text, African American English,...
When relevant, please provide BCP-47 codes, which consist of a primary language subtag, with a script subtag and/or region subtag if available.
Dataset Structure
Data Instances
Provide an JSON-formatted example and brief description of a typical instance in the dataset. If available, provide a link to further examples.
{
'example_field': ...,
...
}
Provide any additional information that is not covered in the other sections about the data here. In particular describe any relationships between data points and if these relationships are made explicit.
Data Fields
List and describe the fields present in the dataset. Mention their data type, and whether they are used as input or output in any of the tasks the dataset currently supports. If the data has span indices, describe their attributes, such as whether they are at the character level or word level, whether they are contiguous or not, etc. If the datasets contains example IDs, state whether they have an inherent meaning, such as a mapping to other datasets or pointing to relationships between data points.
example_field: description ofexample_field
Note that the descriptions can be initialized with the Show Markdown Data Fields output of the tagging app, you will then only need to refine the generated descriptions.
Data Splits
Describe and name the splits in the dataset if there are more than one.
Describe any criteria for splitting the data, if used. If their are differences between the splits (e.g. if the training annotations are machine-generated and the dev and test ones are created by humans, or if different numbers of annotators contributed to each example), describe them here.
Provide the sizes of each split. As appropriate, provide any descriptive statistics for the features, such as average length. For example:
| Tain | Valid | Test | |
|---|---|---|---|
| Input Sentences | |||
| Average Sentence Length |
Dataset Creation
Curation Rationale
What need motivated the creation of this dataset? What are some of the reasons underlying the major choices involved in putting it together?
Source Data
This section describes the source data (e.g. news text and headlines, social media posts, translated sentences,...)
Initial Data Collection and Normalization
Describe the data collection process. Describe any criteria for data selection or filtering. List any key words or search terms used. If possible, include runtime information for the collection process.
If data was collected from other pre-existing datasets, link to source here and to their Hugging Face version.
If the data was modified or normalized after being collected (e.g. if the data is word-tokenized), describe the process and the tools used.
Who are the source language producers?
State whether the data was produced by humans or machine generated. Describe the people or systems who originally created the data.
If available, include self-reported demographic or identity information for the source data creators, but avoid inferring this information. Instead state that this information is unknown. See Larson 2017 for using identity categories as a variables, particularly gender.
Describe the conditions under which the data was created (for example, if the producers were crowdworkers, state what platform was used, or if the data was found, what website the data was found on). If compensation was provided, include that information here.
Describe other people represented or mentioned in the data. Where possible, link to references for the information.
Annotations
If the dataset contains annotations which are not part of the initial data collection, describe them in the following paragraphs.
Annotation process
If applicable, describe the annotation process and any tools used, or state otherwise. Describe the amount of data annotated, if not all. Describe or reference annotation guidelines provided to the annotators. If available, provide interannotator statistics. Describe any annotation validation processes.
Who are the annotators?
If annotations were collected for the source data (such as class labels or syntactic parses), state whether the annotations were produced by humans or machine generated.
Describe the people or systems who originally created the annotations and their selection criteria if applicable.
If available, include self-reported demographic or identity information for the annotators, but avoid inferring this information. Instead state that this information is unknown. See Larson 2017 for using identity categories as a variables, particularly gender.
Describe the conditions under which the data was annotated (for example, if the annotators were crowdworkers, state what platform was used, or if the data was found, what website the data was found on). If compensation was provided, include that information here.
Personal and Sensitive Information
State whether the dataset uses identity categories and, if so, how the information is used. Describe where this information comes from (i.e. self-reporting, collecting from profiles, inferring, etc.). See Larson 2017 for using identity categories as a variables, particularly gender. State whether the data is linked to individuals and whether those individuals can be identified in the dataset, either directly or indirectly (i.e., in combination with other data).
State whether the dataset contains other data that might be considered sensitive (e.g., data that reveals racial or ethnic origins, sexual orientations, religious beliefs, political opinions or union memberships, or locations; financial or health data; biometric or genetic data; forms of government identification, such as social security numbers; criminal history).
If efforts were made to anonymize the data, describe the anonymization process.
Considerations for Using the Data
Social Impact of Dataset
Please discuss some of the ways you believe the use of this dataset will impact society.
The statement should include both positive outlooks, such as outlining how technologies developed through its use may improve people's lives, and discuss the accompanying risks. These risks may range from making important decisions more opaque to people who are affected by the technology, to reinforcing existing harmful biases (whose specifics should be discussed in the next section), among other considerations.
Also describe in this section if the proposed dataset contains a low-resource or under-represented language. If this is the case or if this task has any impact on underserved communities, please elaborate here.
Discussion of Biases
Provide descriptions of specific biases that are likely to be reflected in the data, and state whether any steps were taken to reduce their impact.
For Wikipedia text, see for example Dinan et al 2020 on biases in Wikipedia (esp. Table 1), or Blodgett et al 2020 for a more general discussion of the topic.
If analyses have been run quantifying these biases, please add brief summaries and links to the studies here.
Other Known Limitations
If studies of the datasets have outlined other limitations of the dataset, such as annotation artifacts, please outline and cite them here.
Additional Information
Dataset Curators
List the people involved in collecting the dataset and their affiliation(s). If funding information is known, include it here.
Licensing Information
Provide the license and link to the license webpage if available.
Citation Information
Provide the BibTex-formatted reference for the dataset. For example:
@article{article_id,
author = {Author List},
title = {Dataset Paper Title},
journal = {Publication Venue},
year = {2525}
}
If the dataset has a DOI, please provide it here.
Contributions
Thanks to @mbateman for adding this dataset.
- Downloads last month
- 31