
Dataset Viewer
url
stringlengths 58
61
| repository_url
stringclasses 1
value | labels_url
stringlengths 72
75
| comments_url
stringlengths 67
70
| events_url
stringlengths 65
68
| html_url
stringlengths 46
51
| id
int64 599M
1.13B
| node_id
stringlengths 18
32
| number
int64 1
3.71k
| title
stringlengths 1
276
| user
dict | labels
list | state
stringclasses 2
values | locked
bool 1
class | assignee
null | assignees
sequence | milestone
null | comments
int64 0
42
| created_at
timestamp[us] | updated_at
timestamp[us] | closed_at
timestamp[us] | author_association
stringclasses 3
values | active_lock_reason
null | draft
bool 2
classes | pull_request
dict | body
stringlengths 0
228k
⌀ | reactions
dict | timeline_url
stringlengths 67
70
| performed_via_github_app
null |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
https://api.github.com/repos/huggingface/datasets/issues/3712 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3712/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3712/comments | https://api.github.com/repos/huggingface/datasets/issues/3712/events | https://github.com/huggingface/datasets/pull/3712 | 1,134,252,505 | PR_kwDODunzps4ynVYy | 3,712 | Fix the error of msr_sqa dataset | {
"login": "Timothyxxx",
"id": 47296835,
"node_id": "MDQ6VXNlcjQ3Mjk2ODM1",
"avatar_url": "https://avatars.githubusercontent.com/u/47296835?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Timothyxxx",
"html_url": "https://github.com/Timothyxxx",
"followers_url": "https://api.github.com/users/Timothyxxx/followers",
"following_url": "https://api.github.com/users/Timothyxxx/following{/other_user}",
"gists_url": "https://api.github.com/users/Timothyxxx/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Timothyxxx/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Timothyxxx/subscriptions",
"organizations_url": "https://api.github.com/users/Timothyxxx/orgs",
"repos_url": "https://api.github.com/users/Timothyxxx/repos",
"events_url": "https://api.github.com/users/Timothyxxx/events{/privacy}",
"received_events_url": "https://api.github.com/users/Timothyxxx/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | 0 | 2022-02-12T16:27:54 | 2022-02-12T16:27:54 | null | NONE | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3712",
"html_url": "https://github.com/huggingface/datasets/pull/3712",
"diff_url": "https://github.com/huggingface/datasets/pull/3712.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3712.patch",
"merged_at": null
} | Fix the error of _load_table_data function in msr_sqa dataset, it is wrong to use comma to split each row. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3712/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3712/timeline | null |
https://api.github.com/repos/huggingface/datasets/issues/3711 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3711/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3711/comments | https://api.github.com/repos/huggingface/datasets/issues/3711/events | https://github.com/huggingface/datasets/pull/3711 | 1,134,050,545 | PR_kwDODunzps4ymmlK | 3,711 | Fix the error of _load_table_data function in msr_sqa dataset | {
"login": "Timothyxxx",
"id": 47296835,
"node_id": "MDQ6VXNlcjQ3Mjk2ODM1",
"avatar_url": "https://avatars.githubusercontent.com/u/47296835?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Timothyxxx",
"html_url": "https://github.com/Timothyxxx",
"followers_url": "https://api.github.com/users/Timothyxxx/followers",
"following_url": "https://api.github.com/users/Timothyxxx/following{/other_user}",
"gists_url": "https://api.github.com/users/Timothyxxx/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Timothyxxx/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Timothyxxx/subscriptions",
"organizations_url": "https://api.github.com/users/Timothyxxx/orgs",
"repos_url": "https://api.github.com/users/Timothyxxx/repos",
"events_url": "https://api.github.com/users/Timothyxxx/events{/privacy}",
"received_events_url": "https://api.github.com/users/Timothyxxx/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | 0 | 2022-02-12T13:20:53 | 2022-02-12T13:30:43 | 2022-02-12T13:30:43 | NONE | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3711",
"html_url": "https://github.com/huggingface/datasets/pull/3711",
"diff_url": "https://github.com/huggingface/datasets/pull/3711.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3711.patch",
"merged_at": null
} | The _load_table_data function from the last version is wrong, it is wrong to use comma to split each row. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3711/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3711/timeline | null |
https://api.github.com/repos/huggingface/datasets/issues/3710 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3710/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3710/comments | https://api.github.com/repos/huggingface/datasets/issues/3710/events | https://github.com/huggingface/datasets/pull/3710 | 1,133,955,393 | PR_kwDODunzps4ymQMQ | 3,710 | Fix CI code quality issue | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | 0 | 2022-02-12T12:05:39 | 2022-02-12T12:58:05 | 2022-02-12T12:58:04 | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3710",
"html_url": "https://github.com/huggingface/datasets/pull/3710",
"diff_url": "https://github.com/huggingface/datasets/pull/3710.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3710.patch",
"merged_at": "2022-02-12T12:58:04"
} | Fix CI code quality issue introduced by #3695. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3710/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3710/timeline | null |
https://api.github.com/repos/huggingface/datasets/issues/3709 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3709/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3709/comments | https://api.github.com/repos/huggingface/datasets/issues/3709/events | https://github.com/huggingface/datasets/pull/3709 | 1,132,997,904 | PR_kwDODunzps4yi0J4 | 3,709 | Set base path to hub url for canonical datasets | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | 0 | 2022-02-11T19:23:20 | 2022-02-11T19:23:20 | null | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3709",
"html_url": "https://github.com/huggingface/datasets/pull/3709",
"diff_url": "https://github.com/huggingface/datasets/pull/3709.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3709.patch",
"merged_at": null
} | This should allow canonical datasets to use relative paths to download data files from the Hub
cc @polinaeterna this will be useful if we have audio datasets that are canonical and for which you'd like to host data files | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3709/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 1,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3709/timeline | null |
https://api.github.com/repos/huggingface/datasets/issues/3708 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3708/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3708/comments | https://api.github.com/repos/huggingface/datasets/issues/3708/events | https://github.com/huggingface/datasets/issues/3708 | 1,132,968,402 | I_kwDODunzps5Dh7nS | 3,708 | Loading JSON gets stuck with many workers/threads | {
"login": "lvwerra",
"id": 8264887,
"node_id": "MDQ6VXNlcjgyNjQ4ODc=",
"avatar_url": "https://avatars.githubusercontent.com/u/8264887?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lvwerra",
"html_url": "https://github.com/lvwerra",
"followers_url": "https://api.github.com/users/lvwerra/followers",
"following_url": "https://api.github.com/users/lvwerra/following{/other_user}",
"gists_url": "https://api.github.com/users/lvwerra/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lvwerra/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lvwerra/subscriptions",
"organizations_url": "https://api.github.com/users/lvwerra/orgs",
"repos_url": "https://api.github.com/users/lvwerra/repos",
"events_url": "https://api.github.com/users/lvwerra/events{/privacy}",
"received_events_url": "https://api.github.com/users/lvwerra/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | open | false | null | [] | null | 2 | 2022-02-11T18:50:48 | 2022-02-11T20:57:53 | null | CONTRIBUTOR | null | null | null | ## Describe the bug
Loading a JSON dataset with `load_dataset` can get stuck when running on a machine with many CPUs. This is especially an issue when loading a large dataset on a large machine.
## Steps to reproduce the bug
I originally created the following script to reproduce the issue:
```python
from datasets import load_dataset
from multiprocessing import Process
from tqdm import tqdm
import datasets
from transformers import set_seed
def run_tasks_in_parallel(tasks, ds_list):
for _ in tqdm(range(1000)):
print('new batch')
running_tasks = [Process(target=task, args=(ds, i)) for i, (task, ds) in enumerate(zip(tasks, ds_list))]
for running_task in running_tasks:
running_task.start()
for running_task in running_tasks:
running_task.join()
def get_dataset():
dataset_name = 'transformersbook/codeparrot'
ds = load_dataset(dataset_name+'-train', split="train", streaming=True)
ds = ds.shuffle(buffer_size=1000, seed=1)
return iter(ds)
def get_next_element(ds, process_id, N=10000):
for _ in range(N):
_ = next(ds)['content']
print(f'process {process_id} done')
return
set_seed(1)
datasets.utils.logging.set_verbosity_debug()
n_processes = 8
tasks = [get_next_element for _ in range(n_processes)]
args = [get_dataset() for _ in range(n_processes)]
run_tasks_in_parallel(tasks, args)
```
Today I noticed that it can happen when running it on a single process on a machine with many cores without streaming. So just `load_dataset("transformersbook/codeparrot-train")` alone might cause the issue after waiting long enough or trying many times. It's a slightly random process which makes it especially hard to track down. When I encountered it today it had already processed 17GB of data (the size of the cache folder when it got stuck) before getting stuck.
Here's my current understanding of the error. As far as I can tell it happens in the following block: https://github.com/huggingface/datasets/blob/be701e9e89ab38022612c7263edc015bc7feaff9/src/datasets/packaged_modules/json/json.py#L119-L139
When the try on line 121 fails and the `block_size` is increased it can happen that it can't read the JSON again and gets stuck indefinitely. A hint that points in that direction is that increasing the `chunksize` argument decreases the chance of getting stuck and vice versa. Maybe it is an issue with a lock on the file that is not properly released.
## Expected results
Read a JSON before the end of the universe.
## Actual results
Read a JSON not before the end of the universe.
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.18.3
- Platform: Linux-4.19.0-18-cloud-amd64-x86_64-with-glibc2.28
- Python version: 3.9.10
- PyArrow version: 7.0.0
@lhoestq we dicsussed this a while ago. @albertvillanova we discussed this today :)
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3708/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3708/timeline | null |
https://api.github.com/repos/huggingface/datasets/issues/3707 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3707/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3707/comments | https://api.github.com/repos/huggingface/datasets/issues/3707/events | https://github.com/huggingface/datasets/issues/3707 | 1,132,741,903 | I_kwDODunzps5DhEUP | 3,707 | `.select`: unexpected behavior with `indices` | {
"login": "gabegma",
"id": 36087158,
"node_id": "MDQ6VXNlcjM2MDg3MTU4",
"avatar_url": "https://avatars.githubusercontent.com/u/36087158?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/gabegma",
"html_url": "https://github.com/gabegma",
"followers_url": "https://api.github.com/users/gabegma/followers",
"following_url": "https://api.github.com/users/gabegma/following{/other_user}",
"gists_url": "https://api.github.com/users/gabegma/gists{/gist_id}",
"starred_url": "https://api.github.com/users/gabegma/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/gabegma/subscriptions",
"organizations_url": "https://api.github.com/users/gabegma/orgs",
"repos_url": "https://api.github.com/users/gabegma/repos",
"events_url": "https://api.github.com/users/gabegma/events{/privacy}",
"received_events_url": "https://api.github.com/users/gabegma/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | open | false | null | [] | null | 2 | 2022-02-11T15:20:01 | 2022-02-11T20:53:53 | null | NONE | null | null | null | ## Describe the bug
The `.select` method will not throw when sending `indices` bigger than the dataset length; `indices` will be wrapped instead. This behavior is not documented anywhere, and is not intuitive.
## Steps to reproduce the bug
```python
from datasets import Dataset
ds = Dataset.from_dict({"text": ["d", "e", "f"], "label": [4, 5, 6]})
res1 = ds.select([1, 2, 3])['text']
res2 = ds.select([1000])['text']
```
## Expected results
Both results should throw an `Error`.
## Actual results
`res1` will give `['e', 'f', 'd']`
`res2` will give `['e']`
## Environment info
Bug found from this environment:
- `datasets` version: 1.16.1
- Platform: macOS-10.16-x86_64-i386-64bit
- Python version: 3.8.7
- PyArrow version: 6.0.1
It was also replicated on `master`.
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3707/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3707/timeline | null |
https://api.github.com/repos/huggingface/datasets/issues/3706 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3706/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3706/comments | https://api.github.com/repos/huggingface/datasets/issues/3706/events | https://github.com/huggingface/datasets/issues/3706 | 1,132,218,874 | I_kwDODunzps5DfEn6 | 3,706 | Unable to load dataset 'big_patent' | {
"login": "ankitk2109",
"id": 26432753,
"node_id": "MDQ6VXNlcjI2NDMyNzUz",
"avatar_url": "https://avatars.githubusercontent.com/u/26432753?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ankitk2109",
"html_url": "https://github.com/ankitk2109",
"followers_url": "https://api.github.com/users/ankitk2109/followers",
"following_url": "https://api.github.com/users/ankitk2109/following{/other_user}",
"gists_url": "https://api.github.com/users/ankitk2109/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ankitk2109/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ankitk2109/subscriptions",
"organizations_url": "https://api.github.com/users/ankitk2109/orgs",
"repos_url": "https://api.github.com/users/ankitk2109/repos",
"events_url": "https://api.github.com/users/ankitk2109/events{/privacy}",
"received_events_url": "https://api.github.com/users/ankitk2109/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | open | false | null | [] | null | 4 | 2022-02-11T09:48:34 | 2022-02-11T14:28:20 | null | NONE | null | null | null | ## Describe the bug
Unable to load the "big_patent" dataset
## Steps to reproduce the bug
```python
load_dataset('big_patent', 'd', 'validation')
```
## Expected results
Download big_patents' validation split from the 'd' subset
## Getting an error saying:
{FileNotFoundError}Local file ..\huggingface\datasets\downloads\6159313604f4f2c01e7d1cac52139343b6c07f73f6de348d09be6213478455c5\bigPatentData\train.tar.gz doesn't exist
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version:1.18.3
- Platform: Windows
- Python version:3.8
- PyArrow version:7.0.0
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3706/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3706/timeline | null |
https://api.github.com/repos/huggingface/datasets/issues/3705 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3705/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3705/comments | https://api.github.com/repos/huggingface/datasets/issues/3705/events | https://github.com/huggingface/datasets/pull/3705 | 1,132,053,226 | PR_kwDODunzps4yfhyj | 3,705 | Raise informative error when loading a save_to_disk dataset | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | 0 | 2022-02-11T08:21:03 | 2022-02-11T22:56:40 | 2022-02-11T22:56:39 | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3705",
"html_url": "https://github.com/huggingface/datasets/pull/3705",
"diff_url": "https://github.com/huggingface/datasets/pull/3705.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3705.patch",
"merged_at": "2022-02-11T22:56:39"
} | People recurrently report error when trying to load a dataset (using `load_dataset`) that was previously saved using `save_to_disk`.
This PR raises an informative error message telling them they should use `load_from_disk` instead.
Close #3700. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3705/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3705/timeline | null |
https://api.github.com/repos/huggingface/datasets/issues/3704 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3704/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3704/comments | https://api.github.com/repos/huggingface/datasets/issues/3704/events | https://github.com/huggingface/datasets/issues/3704 | 1,132,042,631 | I_kwDODunzps5DeZmH | 3,704 | OSCAR-2109 datasets are misaligned and truncated | {
"login": "adrianeboyd",
"id": 5794899,
"node_id": "MDQ6VXNlcjU3OTQ4OTk=",
"avatar_url": "https://avatars.githubusercontent.com/u/5794899?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/adrianeboyd",
"html_url": "https://github.com/adrianeboyd",
"followers_url": "https://api.github.com/users/adrianeboyd/followers",
"following_url": "https://api.github.com/users/adrianeboyd/following{/other_user}",
"gists_url": "https://api.github.com/users/adrianeboyd/gists{/gist_id}",
"starred_url": "https://api.github.com/users/adrianeboyd/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/adrianeboyd/subscriptions",
"organizations_url": "https://api.github.com/users/adrianeboyd/orgs",
"repos_url": "https://api.github.com/users/adrianeboyd/repos",
"events_url": "https://api.github.com/users/adrianeboyd/events{/privacy}",
"received_events_url": "https://api.github.com/users/adrianeboyd/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | open | false | null | [] | null | 4 | 2022-02-11T08:14:59 | 2022-02-11T10:41:41 | null | NONE | null | null | null | ## Describe the bug
The `oscar-corpus/OSCAR-2109` data appears to be misaligned and truncated by the dataset builder for subsets that contain more than one part and for cases where the texts contain non-unix newlines.
## Steps to reproduce the bug
A few examples, although I'm not sure how deterministic the particular (mis)alignment is in various configurations:
```python
from datasets import load_dataset
dataset = load_dataset("oscar-corpus/OSCAR-2109", "deduplicated_fi", split="train", use_auth_token=True)
entry = dataset[0]
# entry["text"] is from fi_part_3.txt.gz
# entry["meta"] is from fi_meta_part_2.jsonl.gz
dataset = load_dataset("oscar-corpus/OSCAR-2109", "deduplicated_no", split="train", use_auth_token=True)
entry = dataset[900000]
# entry["text"] is from no_part_3.txt.gz and contains a blank line
# entry["meta"] is from no_meta_part_1.jsonl.gz
dataset = load_dataset("oscar-corpus/OSCAR-2109", "deduplicated_mk", split="train", streaming=True, use_auth_token=True)
# 9088 texts in the dataset are empty
```
For `deduplicated_fi`, all exported raw texts from the dataset are 17GB rather than 20GB as reported in the data splits overview table. The token count with `wc -w` for the raw texts is 2,067,556,874 rather than the expected 2,357,264,196 from the data splits table.
For `deduplicated_no` all exported raw texts contain 624,040,887 rather than the expected 776,354,517 tokens.
For `deduplicated_mk` it is 122,236,936 rather than 134,544,934 tokens.
I'm not expecting the `wc -w` counts to line up exactly with the data splits table, but for comparison the `wc -w` count for `deduplicated_mk` on the raw texts is 134,545,424.
## Issues
* The meta / text files are not paired correctly when loading, so the extracted texts do not have the right offsets, the metadata is not associated with the correct text, and the text files may not be processed to the end or may be processed beyond the end (empty texts).
* The line count offset is not reset per file so the texts aren't aligned to the right offsets in any parts beyond the first part, leading to truncation when in effect blank lines are not skipped.
* Non-unix newline characters are treated as newlines when reading the text files while the metadata only counts unix newlines for its line offsets, leading to further misalignments between the metadata and the extracted texts, and which also results in truncation.
## Expected results
All texts from the OSCAR release are extracted according to the metadata and aligned with the correct metadata.
## Fixes
Not necessarily the exact fixes/checks you may want to use (I didn't test all languages or do any cross-platform testing, I'm not sure all the details are compatible with streaming), however to highlight the issues:
```diff
diff --git a/OSCAR-2109.py b/OSCAR-2109.py
index bbac1076..5eee8de7 100644
--- a/OSCAR-2109.py
+++ b/OSCAR-2109.py
@@ -20,6 +20,7 @@
import collections
import gzip
import json
+import os
import datasets
@@ -387,9 +388,20 @@ class Oscar2109(datasets.GeneratorBasedBuilder):
with open(checksum_file, encoding="utf-8") as f:
data_filenames = [line.split()[1] for line in f if line]
data_urls = [self.config.base_data_path + data_filename for data_filename in data_filenames]
- text_files = dl_manager.download([url for url in data_urls if url.endswith(".txt.gz")])
- metadata_files = dl_manager.download([url for url in data_urls if url.endswith(".jsonl.gz")])
+ # sort filenames so corresponding parts are aligned
+ text_files = sorted(dl_manager.download([url for url in data_urls if url.endswith(".txt.gz")]))
+ metadata_files = sorted(dl_manager.download([url for url in data_urls if url.endswith(".jsonl.gz")]))
+ assert len(text_files) == len(metadata_files)
metadata_and_text_files = list(zip(metadata_files, text_files))
+ for meta_path, text_path in metadata_and_text_files:
+ # check that meta/text part numbers are the same
+ if "part" in os.path.basename(text_path):
+ assert (
+ os.path.basename(text_path).replace(".txt.gz", "").split("_")[-1]
+ == os.path.basename(meta_path).replace(".jsonl.gz", "").split("_")[-1]
+ )
+ else:
+ assert len(metadata_and_text_files) == 1
return [
datasets.SplitGenerator(name=datasets.Split.TRAIN, gen_kwargs={"metadata_and_text_files": metadata_and_text_files}),
]
@@ -397,10 +409,14 @@ class Oscar2109(datasets.GeneratorBasedBuilder):
def _generate_examples(self, metadata_and_text_files):
"""This function returns the examples in the raw (text) form by iterating on all the files."""
id_ = 0
- offset = 0
for meta_path, text_path in metadata_and_text_files:
+ # line offsets are per text file
+ offset = 0
logger.info("generating examples from = %s", text_path)
- with gzip.open(open(text_path, "rb"), "rt", encoding="utf-8") as text_f:
+ # some texts contain non-Unix newlines that should not be
+ # interpreted as line breaks for the line counts in the metadata
+ # with readline()
+ with gzip.open(open(text_path, "rb"), "rt", encoding="utf-8", newline="\n") as text_f:
with gzip.open(open(meta_path, "rb"), "rt", encoding="utf-8") as meta_f:
for line in meta_f:
# read meta
@@ -411,7 +427,12 @@ class Oscar2109(datasets.GeneratorBasedBuilder):
offset += 1
text_f.readline()
# read text
- text = "".join([text_f.readline() for _ in range(meta["nb_sentences"])]).rstrip()
+ text_lines = [text_f.readline() for _ in range(meta["nb_sentences"])]
+ # all lines contain text (no blank lines or EOF)
+ assert all(text_lines)
+ assert "\n" not in text_lines
offset += meta["nb_sentences"]
+ # only strip the trailing newline
+ text = "".join(text_lines).rstrip("\n")
yield id_, {"id": id_, "text": text, "meta": meta}
id_ += 1
```
I've tested this with a number of smaller deduplicated languages with 1-20 parts and the resulting datasets looked correct in terms of word count and size when compared to the data splits table and raw texts, and the text/metadata alignments were correct in all my spot checks. However, there are many many languages I didn't test and I'm not sure that there aren't any texts containing blank lines in the corpus, for instance. For the cases I tested, the assertions related to blank lines and EOF made it easier to verify that the text and metadata were aligned as intended, since there would be little chance of spurious alignments of variable-length texts across so much data. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3704/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3704/timeline | null |
https://api.github.com/repos/huggingface/datasets/issues/3703 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3703/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3703/comments | https://api.github.com/repos/huggingface/datasets/issues/3703/events | https://github.com/huggingface/datasets/issues/3703 | 1,131,882,772 | I_kwDODunzps5DdykU | 3,703 | ImportError: To be able to use this metric, you need to install the following dependencies['seqeval'] using 'pip install seqeval' for instance' | {
"login": "zhangyifei1",
"id": 28425091,
"node_id": "MDQ6VXNlcjI4NDI1MDkx",
"avatar_url": "https://avatars.githubusercontent.com/u/28425091?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/zhangyifei1",
"html_url": "https://github.com/zhangyifei1",
"followers_url": "https://api.github.com/users/zhangyifei1/followers",
"following_url": "https://api.github.com/users/zhangyifei1/following{/other_user}",
"gists_url": "https://api.github.com/users/zhangyifei1/gists{/gist_id}",
"starred_url": "https://api.github.com/users/zhangyifei1/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/zhangyifei1/subscriptions",
"organizations_url": "https://api.github.com/users/zhangyifei1/orgs",
"repos_url": "https://api.github.com/users/zhangyifei1/repos",
"events_url": "https://api.github.com/users/zhangyifei1/events{/privacy}",
"received_events_url": "https://api.github.com/users/zhangyifei1/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 3470211881,
"node_id": "LA_kwDODunzps7O1zsp",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset-viewer",
"name": "dataset-viewer",
"color": "E5583E",
"default": false,
"description": "Related to the dataset viewer on huggingface.co"
}
] | open | false | null | [] | null | 2 | 2022-02-11T06:38:42 | 2022-02-11T06:40:18 | null | NONE | null | null | null | hi :
I want to use the seqeval indicator because of direct load_ When metric ('seqeval '), it will prompt that the network connection fails. So I downloaded the seqeval Py to load locally. Loading code: metric = load_ metric(path='mymetric/seqeval/seqeval.py')
But tips:
Traceback (most recent call last):
File "/home/ubuntu/Python3.6_project/zyf_project/transformers/examples/pytorch/token-classification/run_ner.py", line 604, in <module>
main()
File "/home/ubuntu/Python3.6_project/zyf_project/transformers/examples/pytorch/token-classification/run_ner.py", line 481, in main
metric = load_metric(path='mymetric/seqeval/seqeval.py')
File "/home/ubuntu/Python3.6_project/zyf_project/transformers_venv_0209/lib/python3.7/site-packages/datasets/load.py", line 610, in load_metric
dataset=False,
File "/home/ubuntu/Python3.6_project/zyf_project/transformers_venv_0209/lib/python3.7/site-packages/datasets/load.py", line 450, in prepare_module
f"To be able to use this {module_type}, you need to install the following dependencies"
ImportError: To be able to use this metric, you need to install the following dependencies['seqeval'] using 'pip install seqeval' for instance'
**What should I do? Please help me, thank you**
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3703/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3703/timeline | null |
https://api.github.com/repos/huggingface/datasets/issues/3702 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3702/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3702/comments | https://api.github.com/repos/huggingface/datasets/issues/3702/events | https://github.com/huggingface/datasets/pull/3702 | 1,130,666,707 | PR_kwDODunzps4yahKc | 3,702 | Update the address to use https | {
"login": "yazdanbakhsh",
"id": 7105134,
"node_id": "MDQ6VXNlcjcxMDUxMzQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/7105134?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/yazdanbakhsh",
"html_url": "https://github.com/yazdanbakhsh",
"followers_url": "https://api.github.com/users/yazdanbakhsh/followers",
"following_url": "https://api.github.com/users/yazdanbakhsh/following{/other_user}",
"gists_url": "https://api.github.com/users/yazdanbakhsh/gists{/gist_id}",
"starred_url": "https://api.github.com/users/yazdanbakhsh/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/yazdanbakhsh/subscriptions",
"organizations_url": "https://api.github.com/users/yazdanbakhsh/orgs",
"repos_url": "https://api.github.com/users/yazdanbakhsh/repos",
"events_url": "https://api.github.com/users/yazdanbakhsh/events{/privacy}",
"received_events_url": "https://api.github.com/users/yazdanbakhsh/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | 0 | 2022-02-10T18:46:30 | 2022-02-10T18:46:30 | null | NONE | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3702",
"html_url": "https://github.com/huggingface/datasets/pull/3702",
"diff_url": "https://github.com/huggingface/datasets/pull/3702.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3702.patch",
"merged_at": null
} | The http address doesn't work anymore | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3702/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3702/timeline | null |
https://api.github.com/repos/huggingface/datasets/issues/3701 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3701/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3701/comments | https://api.github.com/repos/huggingface/datasets/issues/3701/events | https://github.com/huggingface/datasets/pull/3701 | 1,130,498,738 | PR_kwDODunzps4yZ8Dw | 3,701 | Pin ElasticSearch | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | 0 | 2022-02-10T17:15:26 | 2022-02-10T17:31:13 | 2022-02-10T17:31:12 | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3701",
"html_url": "https://github.com/huggingface/datasets/pull/3701",
"diff_url": "https://github.com/huggingface/datasets/pull/3701.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3701.patch",
"merged_at": "2022-02-10T17:31:12"
} | Until we manage to support ES 8.0, I'm setting the version to `<8.0.0`
Currently we're getting this error on 8.0:
```python
ValueError: Either 'hosts' or 'cloud_id' must be specified
```
When instantiating a `Elasticsearch()` object | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3701/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3701/timeline | null |
https://api.github.com/repos/huggingface/datasets/issues/3700 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3700/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3700/comments | https://api.github.com/repos/huggingface/datasets/issues/3700/events | https://github.com/huggingface/datasets/issues/3700 | 1,130,252,496 | I_kwDODunzps5DXkjQ | 3,700 | Unable to load a dataset | {
"login": "PaulchauvinAI",
"id": 97964230,
"node_id": "U_kgDOBdbQxg",
"avatar_url": "https://avatars.githubusercontent.com/u/97964230?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/PaulchauvinAI",
"html_url": "https://github.com/PaulchauvinAI",
"followers_url": "https://api.github.com/users/PaulchauvinAI/followers",
"following_url": "https://api.github.com/users/PaulchauvinAI/following{/other_user}",
"gists_url": "https://api.github.com/users/PaulchauvinAI/gists{/gist_id}",
"starred_url": "https://api.github.com/users/PaulchauvinAI/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/PaulchauvinAI/subscriptions",
"organizations_url": "https://api.github.com/users/PaulchauvinAI/orgs",
"repos_url": "https://api.github.com/users/PaulchauvinAI/repos",
"events_url": "https://api.github.com/users/PaulchauvinAI/events{/privacy}",
"received_events_url": "https://api.github.com/users/PaulchauvinAI/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | null | [] | null | 2 | 2022-02-10T15:05:53 | 2022-02-11T22:56:39 | 2022-02-11T22:56:39 | NONE | null | null | null | ## Describe the bug
Unable to load a dataset from Huggingface that I have just saved.
## Steps to reproduce the bug
On Google colab
`! pip install datasets `
`from datasets import load_dataset`
`my_path = "wiki_dataset"`
`dataset = load_dataset('wikipedia', "20200501.fr")`
`dataset.save_to_disk(my_path)`
`dataset = load_dataset(my_path)`
## Expected results
Loading the dataset
## Actual results
ValueError: Couldn't cast
_data_files: list<item: struct<filename: string>>
child 0, item: struct<filename: string>
child 0, filename: string
_fingerprint: string
_format_columns: null
_format_kwargs: struct<>
_format_type: null
_indexes: struct<>
_output_all_columns: bool
_split: string
to
{'builder_name': Value(dtype='string', id=None), 'citation': Value(dtype='string', id=None), 'config_name': Value(dtype='string', id=None), 'dataset_size': Value(dtype='int64', id=None), 'description': Value(dtype='string', id=None), 'download_checksums': {}, 'download_size': Value(dtype='int64', id=None), 'features': {'title': {'dtype': Value(dtype='string', id=None), 'id': Value(dtype='null', id=None), '_type': Value(dtype='string', id=None)}, 'text': {'dtype': Value(dtype='string', id=None), 'id': Value(dtype='null', id=None), '_type': Value(dtype='string', id=None)}}, 'homepage': Value(dtype='string', id=None), 'license': Value(dtype='string', id=None), 'post_processed': Value(dtype='null', id=None), 'post_processing_size': Value(dtype='null', id=None), 'size_in_bytes': Value(dtype='int64', id=None), 'splits': {'train': {'name': Value(dtype='string', id=None), 'num_bytes': Value(dtype='int64', id=None), 'num_examples': Value(dtype='int64', id=None), 'dataset_name': Value(dtype='string', id=None)}}, 'supervised_keys': Value(dtype='null', id=None), 'task_templates': Value(dtype='null', id=None), 'version': {'version_str': Value(dtype='string', id=None), 'description': Value(dtype='string', id=None), 'major': Value(dtype='int64', id=None), 'minor': Value(dtype='int64', id=None), 'patch': Value(dtype='int64', id=None)}}
because column names don't match
## Environment info
- `datasets` version: 1.18.3
- Platform: Linux-5.4.144+-x86_64-with-Ubuntu-18.04-bionic
- Python version: 3.7.12
- PyArrow version: 6.0.1
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3700/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3700/timeline | null |
https://api.github.com/repos/huggingface/datasets/issues/3699 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3699/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3699/comments | https://api.github.com/repos/huggingface/datasets/issues/3699/events | https://github.com/huggingface/datasets/pull/3699 | 1,130,200,593 | PR_kwDODunzps4yY49I | 3,699 | Add dev-only config to Natural Questions dataset | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | 2 | 2022-02-10T14:42:24 | 2022-02-11T09:50:22 | 2022-02-11T09:50:21 | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3699",
"html_url": "https://github.com/huggingface/datasets/pull/3699",
"diff_url": "https://github.com/huggingface/datasets/pull/3699.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3699.patch",
"merged_at": "2022-02-11T09:50:21"
} | As suggested by @lhoestq and @thomwolf, a new config has been added to Natural Questions dataset, so that only dev split can be downloaded.
Fix #413. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3699/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3699/timeline | null |
https://api.github.com/repos/huggingface/datasets/issues/3698 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3698/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3698/comments | https://api.github.com/repos/huggingface/datasets/issues/3698/events | https://github.com/huggingface/datasets/pull/3698 | 1,129,864,282 | PR_kwDODunzps4yXtyQ | 3,698 | Add finetune-data CodeFill | {
"login": "rgismondi",
"id": 49989029,
"node_id": "MDQ6VXNlcjQ5OTg5MDI5",
"avatar_url": "https://avatars.githubusercontent.com/u/49989029?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/rgismondi",
"html_url": "https://github.com/rgismondi",
"followers_url": "https://api.github.com/users/rgismondi/followers",
"following_url": "https://api.github.com/users/rgismondi/following{/other_user}",
"gists_url": "https://api.github.com/users/rgismondi/gists{/gist_id}",
"starred_url": "https://api.github.com/users/rgismondi/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/rgismondi/subscriptions",
"organizations_url": "https://api.github.com/users/rgismondi/orgs",
"repos_url": "https://api.github.com/users/rgismondi/repos",
"events_url": "https://api.github.com/users/rgismondi/events{/privacy}",
"received_events_url": "https://api.github.com/users/rgismondi/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | 0 | 2022-02-10T11:12:51 | 2022-02-10T11:12:51 | null | NONE | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3698",
"html_url": "https://github.com/huggingface/datasets/pull/3698",
"diff_url": "https://github.com/huggingface/datasets/pull/3698.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3698.patch",
"merged_at": null
} | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3698/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3698/timeline | null |
https://api.github.com/repos/huggingface/datasets/issues/3697 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3697/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3697/comments | https://api.github.com/repos/huggingface/datasets/issues/3697/events | https://github.com/huggingface/datasets/pull/3697 | 1,129,795,724 | PR_kwDODunzps4yXeXo | 3,697 | Add code-fill datasets for pretraining/finetuning/evaluating | {
"login": "rgismondi",
"id": 49989029,
"node_id": "MDQ6VXNlcjQ5OTg5MDI5",
"avatar_url": "https://avatars.githubusercontent.com/u/49989029?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/rgismondi",
"html_url": "https://github.com/rgismondi",
"followers_url": "https://api.github.com/users/rgismondi/followers",
"following_url": "https://api.github.com/users/rgismondi/following{/other_user}",
"gists_url": "https://api.github.com/users/rgismondi/gists{/gist_id}",
"starred_url": "https://api.github.com/users/rgismondi/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/rgismondi/subscriptions",
"organizations_url": "https://api.github.com/users/rgismondi/orgs",
"repos_url": "https://api.github.com/users/rgismondi/repos",
"events_url": "https://api.github.com/users/rgismondi/events{/privacy}",
"received_events_url": "https://api.github.com/users/rgismondi/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | 0 | 2022-02-10T10:31:48 | 2022-02-10T11:00:44 | null | NONE | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3697",
"html_url": "https://github.com/huggingface/datasets/pull/3697",
"diff_url": "https://github.com/huggingface/datasets/pull/3697.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3697.patch",
"merged_at": null
} | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3697/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3697/timeline | null |
https://api.github.com/repos/huggingface/datasets/issues/3696 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3696/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3696/comments | https://api.github.com/repos/huggingface/datasets/issues/3696/events | https://github.com/huggingface/datasets/pull/3696 | 1,129,764,534 | PR_kwDODunzps4yXXgH | 3,696 | Force unique keys in newsqa dataset | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | 0 | 2022-02-10T10:09:19 | 2022-02-10T10:09:19 | null | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3696",
"html_url": "https://github.com/huggingface/datasets/pull/3696",
"diff_url": "https://github.com/huggingface/datasets/pull/3696.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3696.patch",
"merged_at": null
} | Currently, it may raise `DuplicatedKeysError`.
Fix #3630. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3696/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3696/timeline | null |
https://api.github.com/repos/huggingface/datasets/issues/3695 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3695/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3695/comments | https://api.github.com/repos/huggingface/datasets/issues/3695/events | https://github.com/huggingface/datasets/pull/3695 | 1,129,730,148 | PR_kwDODunzps4yXP44 | 3,695 | Fix ClassLabel to/from dict when passed names_file | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | 0 | 2022-02-10T09:47:10 | 2022-02-11T23:02:32 | 2022-02-11T23:02:31 | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3695",
"html_url": "https://github.com/huggingface/datasets/pull/3695",
"diff_url": "https://github.com/huggingface/datasets/pull/3695.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3695.patch",
"merged_at": "2022-02-11T23:02:31"
} | Currently, `names_file` is a field of the data class `ClassLabel`, thus appearing when transforming it to dict (when saving infos). Afterwards, when trying to read it from infos, it conflicts with the other field `names`.
This PR, removes `names_file` as a field of the data class `ClassLabel`.
- it is only used at instantiation to generate the `labels` field
Fix #3631. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3695/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3695/timeline | null |
https://api.github.com/repos/huggingface/datasets/issues/3693 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3693/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3693/comments | https://api.github.com/repos/huggingface/datasets/issues/3693/events | https://github.com/huggingface/datasets/pull/3693 | 1,128,554,365 | PR_kwDODunzps4yTTcQ | 3,693 | Standardize to `Example::` | {
"login": "mishig25",
"id": 11827707,
"node_id": "MDQ6VXNlcjExODI3NzA3",
"avatar_url": "https://avatars.githubusercontent.com/u/11827707?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mishig25",
"html_url": "https://github.com/mishig25",
"followers_url": "https://api.github.com/users/mishig25/followers",
"following_url": "https://api.github.com/users/mishig25/following{/other_user}",
"gists_url": "https://api.github.com/users/mishig25/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mishig25/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mishig25/subscriptions",
"organizations_url": "https://api.github.com/users/mishig25/orgs",
"repos_url": "https://api.github.com/users/mishig25/repos",
"events_url": "https://api.github.com/users/mishig25/events{/privacy}",
"received_events_url": "https://api.github.com/users/mishig25/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | 0 | 2022-02-09T13:37:13 | 2022-02-09T13:37:13 | null | NONE | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3693",
"html_url": "https://github.com/huggingface/datasets/pull/3693",
"diff_url": "https://github.com/huggingface/datasets/pull/3693.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3693.patch",
"merged_at": null
} | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3693/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3693/timeline | null |
https://api.github.com/repos/huggingface/datasets/issues/3692 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3692/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3692/comments | https://api.github.com/repos/huggingface/datasets/issues/3692/events | https://github.com/huggingface/datasets/pull/3692 | 1,128,320,004 | PR_kwDODunzps4yShiu | 3,692 | Update data URL in pubmed dataset | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | 2 | 2022-02-09T10:06:21 | 2022-02-10T14:58:00 | null | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3692",
"html_url": "https://github.com/huggingface/datasets/pull/3692",
"diff_url": "https://github.com/huggingface/datasets/pull/3692.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3692.patch",
"merged_at": null
} | Fix #3655. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3692/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3692/timeline | null |
https://api.github.com/repos/huggingface/datasets/issues/3691 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3691/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3691/comments | https://api.github.com/repos/huggingface/datasets/issues/3691/events | https://github.com/huggingface/datasets/pull/3691 | 1,127,629,306 | PR_kwDODunzps4yQThV | 3,691 | Upgrade black to version ~=22.0 | {
"login": "LysandreJik",
"id": 30755778,
"node_id": "MDQ6VXNlcjMwNzU1Nzc4",
"avatar_url": "https://avatars.githubusercontent.com/u/30755778?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/LysandreJik",
"html_url": "https://github.com/LysandreJik",
"followers_url": "https://api.github.com/users/LysandreJik/followers",
"following_url": "https://api.github.com/users/LysandreJik/following{/other_user}",
"gists_url": "https://api.github.com/users/LysandreJik/gists{/gist_id}",
"starred_url": "https://api.github.com/users/LysandreJik/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/LysandreJik/subscriptions",
"organizations_url": "https://api.github.com/users/LysandreJik/orgs",
"repos_url": "https://api.github.com/users/LysandreJik/repos",
"events_url": "https://api.github.com/users/LysandreJik/events{/privacy}",
"received_events_url": "https://api.github.com/users/LysandreJik/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | 0 | 2022-02-08T18:45:19 | 2022-02-08T19:56:40 | 2022-02-08T19:56:39 | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3691",
"html_url": "https://github.com/huggingface/datasets/pull/3691",
"diff_url": "https://github.com/huggingface/datasets/pull/3691.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3691.patch",
"merged_at": "2022-02-08T19:56:39"
} | Upgrades the `datasets` library quality tool `black` to use the first stable release of `black`, version 22.0. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3691/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3691/timeline | null |
https://api.github.com/repos/huggingface/datasets/issues/3690 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3690/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3690/comments | https://api.github.com/repos/huggingface/datasets/issues/3690/events | https://github.com/huggingface/datasets/pull/3690 | 1,127,493,538 | PR_kwDODunzps4yP2p5 | 3,690 | WIP: update docs to new frontend/UI | {
"login": "mishig25",
"id": 11827707,
"node_id": "MDQ6VXNlcjExODI3NzA3",
"avatar_url": "https://avatars.githubusercontent.com/u/11827707?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mishig25",
"html_url": "https://github.com/mishig25",
"followers_url": "https://api.github.com/users/mishig25/followers",
"following_url": "https://api.github.com/users/mishig25/following{/other_user}",
"gists_url": "https://api.github.com/users/mishig25/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mishig25/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mishig25/subscriptions",
"organizations_url": "https://api.github.com/users/mishig25/orgs",
"repos_url": "https://api.github.com/users/mishig25/repos",
"events_url": "https://api.github.com/users/mishig25/events{/privacy}",
"received_events_url": "https://api.github.com/users/mishig25/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | 0 | 2022-02-08T16:38:09 | 2022-02-11T16:22:10 | null | NONE | null | true | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3690",
"html_url": "https://github.com/huggingface/datasets/pull/3690",
"diff_url": "https://github.com/huggingface/datasets/pull/3690.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3690.patch",
"merged_at": null
} | ### TLDR: Update `datasets` `docs` to the new syntax & frontend (as how it looks on [hf.co/transformers](https://huggingface.co/docs/transformers/index))
## Checklist
- [ ] update datasets docs to new syntax (should call `doc-builder convert`) (this PR)
- [x] discuss `@property` methods frontend https://github.com/huggingface/doc-builder/pull/87
- [x] discuss `inject_arrow_table_documentation` (this PR) https://github.com/huggingface/datasets/pull/3690#discussion_r801847860
- [x] update datasets docs path on moon-landing https://github.com/huggingface/moon-landing/pull/2089
- [ ] update nginx `docs/datasets` to route to moon-landing (do similar to internal repo # 81)
- [x] convert pyarrow docstring from Numpydoc style to groups style https://github.com/huggingface/doc-builder/pull/89(https://stackoverflow.com/a/24385103/6558628)
- [x] handle `Raises` section on frontend and doc-builder https://github.com/huggingface/doc-builder/pull/86
- [x] check imgs path (this PR) (nothing to update here)
- [ ] delete sphinx related files (this PR)
- [ ] update github actions (doc quality check & PR doc)
- [x] doc exaples block has to follow format `Examples::` https://github.com/huggingface/datasets/pull/3693
- [x] add `versions.yml` in doc-build https://github.com/huggingface/doc-build/pull/1
- [ ] add `versions.yml` in doc-build-dev | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3690/reactions",
"total_count": 2,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 2,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3690/timeline | null |
https://api.github.com/repos/huggingface/datasets/issues/3689 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3689/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3689/comments | https://api.github.com/repos/huggingface/datasets/issues/3689/events | https://github.com/huggingface/datasets/pull/3689 | 1,127,422,478 | PR_kwDODunzps4yPnp7 | 3,689 | Fix streaming for servers not supporting HTTP range requests | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | 10 | 2022-02-08T15:41:05 | 2022-02-10T16:51:25 | 2022-02-10T16:51:25 | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3689",
"html_url": "https://github.com/huggingface/datasets/pull/3689",
"diff_url": "https://github.com/huggingface/datasets/pull/3689.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3689.patch",
"merged_at": "2022-02-10T16:51:24"
} | Some servers do not support HTTP range requests, whereas this is required to stream some file formats (like ZIP).
~~This PR implements a workaround for those cases, by download the files locally in a temporary directory (cleaned up by the OS once the process is finished).~~
This PR raises custom error explaining that streaming is not possible because data host server does not support HTTP range requests.
Fix #3677. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3689/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3689/timeline | null |
https://api.github.com/repos/huggingface/datasets/issues/3688 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3688/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3688/comments | https://api.github.com/repos/huggingface/datasets/issues/3688/events | https://github.com/huggingface/datasets/issues/3688 | 1,127,218,321 | I_kwDODunzps5DL_yR | 3,688 | Pyarrow version error | {
"login": "Zaker237",
"id": 49993443,
"node_id": "MDQ6VXNlcjQ5OTkzNDQz",
"avatar_url": "https://avatars.githubusercontent.com/u/49993443?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Zaker237",
"html_url": "https://github.com/Zaker237",
"followers_url": "https://api.github.com/users/Zaker237/followers",
"following_url": "https://api.github.com/users/Zaker237/following{/other_user}",
"gists_url": "https://api.github.com/users/Zaker237/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Zaker237/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Zaker237/subscriptions",
"organizations_url": "https://api.github.com/users/Zaker237/orgs",
"repos_url": "https://api.github.com/users/Zaker237/repos",
"events_url": "https://api.github.com/users/Zaker237/events{/privacy}",
"received_events_url": "https://api.github.com/users/Zaker237/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | null | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
}
] | null | 3 | 2022-02-08T12:53:59 | 2022-02-09T06:35:33 | 2022-02-09T06:35:32 | NONE | null | null | null | ## Describe the bug
I installed datasets(version 1.17.0, 1.18.0, 1.18.3) but i'm right now nor able to import it because of pyarrow. when i try to import it, i get the following error:
`To use datasets, the module pyarrow>=3.0.0 is required, and the current version of pyarrow doesn't match this condition`.
i tryed with all version of pyarrow execpt `4.0.0` but still get the same error.
## Steps to reproduce the bug
```python
import datasets
```
## Expected results
A clear and concise description of the expected results.
## Actual results
AttributeError Traceback (most recent call last)
<ipython-input-19-652e886d387f> in <module>
----> 1 import datasets
~\AppData\Local\Continuum\anaconda3\lib\site-packages\datasets\__init__.py in <module>
26
27
---> 28 if _version.parse(pyarrow.__version__).major < 3:
29 raise ImportWarning(
30 "To use `datasets`, the module `pyarrow>=3.0.0` is required, and the current version of `pyarrow` doesn't match this condition.\n"
AttributeError: 'Version' object has no attribute 'major'
## Environment info
Traceback (most recent call last):
File "c:\users\alex\appdata\local\continuum\anaconda3\lib\runpy.py", line 193, in _run_module_as_main
"__main__", mod_spec)
File "c:\users\alex\appdata\local\continuum\anaconda3\lib\runpy.py", line 85, in _run_code
exec(code, run_globals)
File "C:\Users\Alex\AppData\Local\Continuum\anaconda3\Scripts\datasets-cli.exe\__main__.py", line 5, in <module>
File "c:\users\alex\appdata\local\continuum\anaconda3\lib\site-packages\datasets\__init__.py", line 28, in <module>
if _version.parse(pyarrow.__version__).major < 3:
AttributeError: 'Version' object has no attribute 'major'
- `datasets` version:
- Platform: Linux(Ubuntu) and Windows: conda on the both
- Python version: 3.7
- PyArrow version: 7.0.0
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3688/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3688/timeline | null |
https://api.github.com/repos/huggingface/datasets/issues/3687 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3687/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3687/comments | https://api.github.com/repos/huggingface/datasets/issues/3687/events | https://github.com/huggingface/datasets/issues/3687 | 1,127,154,766 | I_kwDODunzps5DLwRO | 3,687 | Can't get the text data when calling to_tf_dataset | {
"login": "phrasenmaeher",
"id": 82086367,
"node_id": "MDQ6VXNlcjgyMDg2MzY3",
"avatar_url": "https://avatars.githubusercontent.com/u/82086367?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/phrasenmaeher",
"html_url": "https://github.com/phrasenmaeher",
"followers_url": "https://api.github.com/users/phrasenmaeher/followers",
"following_url": "https://api.github.com/users/phrasenmaeher/following{/other_user}",
"gists_url": "https://api.github.com/users/phrasenmaeher/gists{/gist_id}",
"starred_url": "https://api.github.com/users/phrasenmaeher/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/phrasenmaeher/subscriptions",
"organizations_url": "https://api.github.com/users/phrasenmaeher/orgs",
"repos_url": "https://api.github.com/users/phrasenmaeher/repos",
"events_url": "https://api.github.com/users/phrasenmaeher/events{/privacy}",
"received_events_url": "https://api.github.com/users/phrasenmaeher/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [
{
"login": "Rocketknight1",
"id": 12866554,
"node_id": "MDQ6VXNlcjEyODY2NTU0",
"avatar_url": "https://avatars.githubusercontent.com/u/12866554?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Rocketknight1",
"html_url": "https://github.com/Rocketknight1",
"followers_url": "https://api.github.com/users/Rocketknight1/followers",
"following_url": "https://api.github.com/users/Rocketknight1/following{/other_user}",
"gists_url": "https://api.github.com/users/Rocketknight1/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Rocketknight1/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Rocketknight1/subscriptions",
"organizations_url": "https://api.github.com/users/Rocketknight1/orgs",
"repos_url": "https://api.github.com/users/Rocketknight1/repos",
"events_url": "https://api.github.com/users/Rocketknight1/events{/privacy}",
"received_events_url": "https://api.github.com/users/Rocketknight1/received_events",
"type": "User",
"site_admin": false
}
] | null | 5 | 2022-02-08T11:52:10 | 2022-02-08T16:54:55 | null | NONE | null | null | null | I am working with the SST2 dataset, and am using TensorFlow 2.5
I'd like to convert it to a `tf.data.Dataset` by calling the `to_tf_dataset` method.
The following snippet is what I am using to achieve this:
```
from datasets import load_dataset
from transformers import DefaultDataCollator
data_collator = DefaultDataCollator(return_tensors="tf")
dataset = load_dataset("sst")
train_dataset = dataset["train"].to_tf_dataset(columns=['sentence'], label_cols="label", shuffle=True, batch_size=8,collate_fn=data_collator)
```
However, this only gets me the labels; the text--the most important part--is missing:
```
for s in train_dataset.take(1):
print(s) #prints something like: ({}, <tf.Tensor: shape=(8,), ...>)
```
As you can see, it only returns the label part, not the data, as indicated by the empty dictionary, `{}`. So far, I've played with various settings of the method arguments, but to no avail; I do not want to perform any text processing at this time. On my quest to achieve what I want ( a `tf.data.Dataset`), I've consulted these resources:
[https://www.philschmid.de/huggingface-transformers-keras-tf](https://www.philschmid.de/huggingface-transformers-keras-tf)
[https://huggingface.co/docs/datasets/use_dataset.html?highlight=tensorflow](https://huggingface.co/docs/datasets/use_dataset.html?highlight=tensorflow)
I was surprised to not find more extensive examples on how to transform a Hugginface dataset to one compatible with TensorFlow.
If you could point me to where I am going wrong, please do so.
Thanks in advance for your support.
---
Edit: In the [docs](https://huggingface.co/docs/datasets/package_reference/main_classes.html#datasets.Dataset.to_tf_dataset), I found the following description:
_In general, only columns that the model can use as input should be included here (numeric data only)._
Does this imply that no textual, i.e., `string` data can be loaded?
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3687/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3687/timeline | null |
https://api.github.com/repos/huggingface/datasets/issues/3686 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3686/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3686/comments | https://api.github.com/repos/huggingface/datasets/issues/3686/events | https://github.com/huggingface/datasets/issues/3686 | 1,127,137,290 | I_kwDODunzps5DLsAK | 3,686 | `Translation` features cannot be `flatten`ed | {
"login": "SBrandeis",
"id": 33657802,
"node_id": "MDQ6VXNlcjMzNjU3ODAy",
"avatar_url": "https://avatars.githubusercontent.com/u/33657802?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/SBrandeis",
"html_url": "https://github.com/SBrandeis",
"followers_url": "https://api.github.com/users/SBrandeis/followers",
"following_url": "https://api.github.com/users/SBrandeis/following{/other_user}",
"gists_url": "https://api.github.com/users/SBrandeis/gists{/gist_id}",
"starred_url": "https://api.github.com/users/SBrandeis/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/SBrandeis/subscriptions",
"organizations_url": "https://api.github.com/users/SBrandeis/orgs",
"repos_url": "https://api.github.com/users/SBrandeis/repos",
"events_url": "https://api.github.com/users/SBrandeis/events{/privacy}",
"received_events_url": "https://api.github.com/users/SBrandeis/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | open | false | null | [
{
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"type": "User",
"site_admin": false
}
] | null | 1 | 2022-02-08T11:33:48 | 2022-02-08T13:52:34 | null | CONTRIBUTOR | null | null | null | ## Describe the bug
(`Dataset.flatten`)[https://github.com/huggingface/datasets/blob/master/src/datasets/arrow_dataset.py#L1265] fails for columns with feature (`Translation`)[https://github.com/huggingface/datasets/blob/3edbeb0ec6519b79f1119adc251a1a6b379a2c12/src/datasets/features/translation.py#L8]
## Steps to reproduce the bug
```python
from datasets import load_dataset
dataset = load_dataset("europa_ecdc_tm", "en2fr", split="train[:10]")
print(dataset.features)
# {'translation': Translation(languages=['en', 'fr'], id=None)}
print(dataset[0])
# {'translation': {'en': 'Vaccination against hepatitis C is not yet available.', 'fr': 'Aucune vaccination contre l’hépatite C n’est encore disponible.'}}
dataset.flatten()
```
## Expected results
`dataset.flatten` should flatten the `Translation` column as if it were a dict of `Value("string")`
```python
dataset[0]
# {'translation.en': 'Vaccination against hepatitis C is not yet available.', 'translation.fr': 'Aucune vaccination contre l’hépatite C n’est encore disponible.' }
dataset.features
# {'translation.en': Value("string"), 'translation.fr': Value("string")}
```
## Actual results
```python
In [31]: dset.flatten()
---------------------------------------------------------------------------
KeyError Traceback (most recent call last)
<ipython-input-31-bb88eb5276ee> in <module>
----> 1 dset.flatten()
[...]\site-packages\datasets\fingerprint.py in wrapper(*args, **kwargs)
411 # Call actual function
412
--> 413 out = func(self, *args, **kwargs)
414
415 # Update fingerprint of in-place transforms + update in-place history of transforms
[...]\site-packages\datasets\arrow_dataset.py in flatten(self, new_fingerprint, max_depth)
1294 break
1295 dataset.info.features = self.features.flatten(max_depth=max_depth)
-> 1296 dataset._data = update_metadata_with_features(dataset._data, dataset.features)
1297 logger.info(f'Flattened dataset from depth {depth} to depth {1 if depth + 1 < max_depth else "unknown"}.')
1298 dataset._fingerprint = new_fingerprint
[...]\site-packages\datasets\arrow_dataset.py in update_metadata_with_features(table, features)
534 def update_metadata_with_features(table: Table, features: Features):
535 """To be used in dataset transforms that modify the features of the dataset, in order to update the features stored in the metadata of its schema."""
--> 536 features = Features({col_name: features[col_name] for col_name in table.column_names})
537 if table.schema.metadata is None or b"huggingface" not in table.schema.metadata:
538 pa_metadata = ArrowWriter._build_metadata(DatasetInfo(features=features))
[...]\site-packages\datasets\arrow_dataset.py in <dictcomp>(.0)
534 def update_metadata_with_features(table: Table, features: Features):
535 """To be used in dataset transforms that modify the features of the dataset, in order to update the features stored in the metadata of its schema."""
--> 536 features = Features({col_name: features[col_name] for col_name in table.column_names})
537 if table.schema.metadata is None or b"huggingface" not in table.schema.metadata:
538 pa_metadata = ArrowWriter._build_metadata(DatasetInfo(features=features))
KeyError: 'translation.en'
```
## Environment info
- `datasets` version: 1.18.3
- Platform: Windows-10-10.0.19041-SP0
- Python version: 3.7.10
- PyArrow version: 3.0.0
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3686/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3686/timeline | null |
https://api.github.com/repos/huggingface/datasets/issues/3685 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3685/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3685/comments | https://api.github.com/repos/huggingface/datasets/issues/3685/events | https://github.com/huggingface/datasets/pull/3685 | 1,126,240,444 | PR_kwDODunzps4yLw3m | 3,685 | Add support for `Audio` and `Image` feature in `push_to_hub` | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | 2 | 2022-02-07T16:47:16 | 2022-02-11T19:40:00 | null | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3685",
"html_url": "https://github.com/huggingface/datasets/pull/3685",
"diff_url": "https://github.com/huggingface/datasets/pull/3685.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3685.patch",
"merged_at": null
} | Add support for the `Audio` and the `Image` feature in `push_to_hub`.
The idea is to remove local path information and store file content under "bytes" in the Arrow table before the push.
My initial approach (https://github.com/huggingface/datasets/commit/34c652afeff9686b6b8bf4e703c84d2205d670aa) was to use a map transform similar to [`decode_nested_example`](https://github.com/huggingface/datasets/blob/5e0f6068741464f833ff1802e24ecc2064aaea9f/src/datasets/features/features.py#L1023-L1056) while having decoding turned off, but I wasn't satisfied with the code quality, so I ended up using the `temporary_assignment` decorator to override `cast_storage`, which allows me to directly modify the underlying storage (the final op is similar to `Dataset.cast`) and results in a much simpler code.
Additionally, I added the `allow_cast` flag that can disable this behavior in the situations where it's not needed (e.g. the dataset is already in the correct format for the Hub, etc.) | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3685/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3685/timeline | null |
https://api.github.com/repos/huggingface/datasets/issues/3684 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3684/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3684/comments | https://api.github.com/repos/huggingface/datasets/issues/3684/events | https://github.com/huggingface/datasets/pull/3684 | 1,125,133,664 | PR_kwDODunzps4yIOer | 3,684 | [fix]: iwslt2017 download urls | {
"login": "msarmi9",
"id": 48395294,
"node_id": "MDQ6VXNlcjQ4Mzk1Mjk0",
"avatar_url": "https://avatars.githubusercontent.com/u/48395294?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/msarmi9",
"html_url": "https://github.com/msarmi9",
"followers_url": "https://api.github.com/users/msarmi9/followers",
"following_url": "https://api.github.com/users/msarmi9/following{/other_user}",
"gists_url": "https://api.github.com/users/msarmi9/gists{/gist_id}",
"starred_url": "https://api.github.com/users/msarmi9/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/msarmi9/subscriptions",
"organizations_url": "https://api.github.com/users/msarmi9/orgs",
"repos_url": "https://api.github.com/users/msarmi9/repos",
"events_url": "https://api.github.com/users/msarmi9/events{/privacy}",
"received_events_url": "https://api.github.com/users/msarmi9/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | 4 | 2022-02-06T07:56:55 | 2022-02-09T08:39:31 | null | NONE | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3684",
"html_url": "https://github.com/huggingface/datasets/pull/3684",
"diff_url": "https://github.com/huggingface/datasets/pull/3684.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3684.patch",
"merged_at": null
} | Fixes #2076. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3684/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3684/timeline | null |
https://api.github.com/repos/huggingface/datasets/issues/3683 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3683/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3683/comments | https://api.github.com/repos/huggingface/datasets/issues/3683/events | https://github.com/huggingface/datasets/pull/3683 | 1,124,458,371 | PR_kwDODunzps4yGKoj | 3,683 | added told-br (brazilian hate speech) dataset | {
"login": "JAugusto97",
"id": 26556320,
"node_id": "MDQ6VXNlcjI2NTU2MzIw",
"avatar_url": "https://avatars.githubusercontent.com/u/26556320?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/JAugusto97",
"html_url": "https://github.com/JAugusto97",
"followers_url": "https://api.github.com/users/JAugusto97/followers",
"following_url": "https://api.github.com/users/JAugusto97/following{/other_user}",
"gists_url": "https://api.github.com/users/JAugusto97/gists{/gist_id}",
"starred_url": "https://api.github.com/users/JAugusto97/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/JAugusto97/subscriptions",
"organizations_url": "https://api.github.com/users/JAugusto97/orgs",
"repos_url": "https://api.github.com/users/JAugusto97/repos",
"events_url": "https://api.github.com/users/JAugusto97/events{/privacy}",
"received_events_url": "https://api.github.com/users/JAugusto97/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | 2 | 2022-02-04T17:44:32 | 2022-02-07T21:14:52 | 2022-02-07T21:14:52 | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3683",
"html_url": "https://github.com/huggingface/datasets/pull/3683",
"diff_url": "https://github.com/huggingface/datasets/pull/3683.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3683.patch",
"merged_at": "2022-02-07T21:14:52"
} | Hey,
Adding ToLD-Br. Feel free to ask for modifications.
Thanks!! | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3683/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3683/timeline | null |
https://api.github.com/repos/huggingface/datasets/issues/3682 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3682/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3682/comments | https://api.github.com/repos/huggingface/datasets/issues/3682/events | https://github.com/huggingface/datasets/pull/3682 | 1,124,434,330 | PR_kwDODunzps4yGFml | 3,682 | adding told-br for toxic/abusive hatespeech detection | {
"login": "JAugusto97",
"id": 26556320,
"node_id": "MDQ6VXNlcjI2NTU2MzIw",
"avatar_url": "https://avatars.githubusercontent.com/u/26556320?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/JAugusto97",
"html_url": "https://github.com/JAugusto97",
"followers_url": "https://api.github.com/users/JAugusto97/followers",
"following_url": "https://api.github.com/users/JAugusto97/following{/other_user}",
"gists_url": "https://api.github.com/users/JAugusto97/gists{/gist_id}",
"starred_url": "https://api.github.com/users/JAugusto97/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/JAugusto97/subscriptions",
"organizations_url": "https://api.github.com/users/JAugusto97/orgs",
"repos_url": "https://api.github.com/users/JAugusto97/repos",
"events_url": "https://api.github.com/users/JAugusto97/events{/privacy}",
"received_events_url": "https://api.github.com/users/JAugusto97/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | 2 | 2022-02-04T17:18:29 | 2022-02-07T03:23:24 | 2022-02-04T17:36:40 | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3682",
"html_url": "https://github.com/huggingface/datasets/pull/3682",
"diff_url": "https://github.com/huggingface/datasets/pull/3682.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3682.patch",
"merged_at": null
} | Hey,
I'm adding our dataset from our paper published at AACL 2020. Feel free to ask for modifications.
Thanks! | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3682/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3682/timeline | null |
https://api.github.com/repos/huggingface/datasets/issues/3681 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3681/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3681/comments | https://api.github.com/repos/huggingface/datasets/issues/3681/events | https://github.com/huggingface/datasets/pull/3681 | 1,124,237,458 | PR_kwDODunzps4yFcpM | 3,681 | Fix TestCommand to move dataset_infos instead of copying | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | 5 | 2022-02-04T14:01:52 | 2022-02-04T18:47:16 | null | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3681",
"html_url": "https://github.com/huggingface/datasets/pull/3681",
"diff_url": "https://github.com/huggingface/datasets/pull/3681.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3681.patch",
"merged_at": null
} | Why do we copy instead of moving the file?
CC: @lhoestq @lvwerra | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3681/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3681/timeline | null |
https://api.github.com/repos/huggingface/datasets/issues/3680 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3680/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3680/comments | https://api.github.com/repos/huggingface/datasets/issues/3680/events | https://github.com/huggingface/datasets/pull/3680 | 1,124,213,416 | PR_kwDODunzps4yFXm8 | 3,680 | Fix TestCommand to copy dataset_infos to local dir with only data files | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | 0 | 2022-02-04T13:36:46 | 2022-02-08T10:32:55 | 2022-02-08T10:32:55 | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3680",
"html_url": "https://github.com/huggingface/datasets/pull/3680",
"diff_url": "https://github.com/huggingface/datasets/pull/3680.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3680.patch",
"merged_at": "2022-02-08T10:32:55"
} | Currently this case is missed.
CC: @lvwerra | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3680/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3680/timeline | null |
https://api.github.com/repos/huggingface/datasets/issues/3679 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3679/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3679/comments | https://api.github.com/repos/huggingface/datasets/issues/3679/events | https://github.com/huggingface/datasets/issues/3679 | 1,124,062,133 | I_kwDODunzps5C_9O1 | 3,679 | Download datasets from a private hub | {
"login": "juliensimon",
"id": 3436143,
"node_id": "MDQ6VXNlcjM0MzYxNDM=",
"avatar_url": "https://avatars.githubusercontent.com/u/3436143?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/juliensimon",
"html_url": "https://github.com/juliensimon",
"followers_url": "https://api.github.com/users/juliensimon/followers",
"following_url": "https://api.github.com/users/juliensimon/following{/other_user}",
"gists_url": "https://api.github.com/users/juliensimon/gists{/gist_id}",
"starred_url": "https://api.github.com/users/juliensimon/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/juliensimon/subscriptions",
"organizations_url": "https://api.github.com/users/juliensimon/orgs",
"repos_url": "https://api.github.com/users/juliensimon/repos",
"events_url": "https://api.github.com/users/juliensimon/events{/privacy}",
"received_events_url": "https://api.github.com/users/juliensimon/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
},
{
"id": 3814924348,
"node_id": "LA_kwDODunzps7jYyA8",
"url": "https://api.github.com/repos/huggingface/datasets/labels/private-hub",
"name": "private-hub",
"color": "A929D8",
"default": false,
"description": ""
}
] | open | false | null | [] | null | 2 | 2022-02-04T10:49:06 | 2022-02-09T15:04:25 | null | NONE | null | null | null | In the context of a private hub deployment, customers would like to use load_dataset() to load datasets from their hub, not from the public hub. This doesn't seem to be configurable at the moment and it would be nice to add this feature.
The obvious workaround is to clone the repo first and then load it from local storage, but this adds an extra step. It'd be great to have the same experience regardless of where the hub is hosted.
The same issue exists with the transformers library and the CLI. I'm going to create issues there as well, and I'll reference them below. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3679/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3679/timeline | null |
https://api.github.com/repos/huggingface/datasets/issues/3678 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3678/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3678/comments | https://api.github.com/repos/huggingface/datasets/issues/3678/events | https://github.com/huggingface/datasets/pull/3678 | 1,123,402,426 | PR_kwDODunzps4yCt91 | 3,678 | Add code example in wikipedia card | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | 0 | 2022-02-03T18:09:02 | 2022-02-04T13:21:39 | 2022-02-04T13:21:39 | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3678",
"html_url": "https://github.com/huggingface/datasets/pull/3678",
"diff_url": "https://github.com/huggingface/datasets/pull/3678.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3678.patch",
"merged_at": "2022-02-04T13:21:39"
} | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3678/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3678/timeline | null |
https://api.github.com/repos/huggingface/datasets/issues/3677 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3677/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3677/comments | https://api.github.com/repos/huggingface/datasets/issues/3677/events | https://github.com/huggingface/datasets/issues/3677 | 1,123,192,866 | I_kwDODunzps5C8pAi | 3,677 | Discovery cannot be streamed anymore | {
"login": "severo",
"id": 1676121,
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/severo",
"html_url": "https://github.com/severo",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://api.github.com/users/severo/gists{/gist_id}",
"starred_url": "https://api.github.com/users/severo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/severo/subscriptions",
"organizations_url": "https://api.github.com/users/severo/orgs",
"repos_url": "https://api.github.com/users/severo/repos",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"received_events_url": "https://api.github.com/users/severo/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | null | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
}
] | null | 2 | 2022-02-03T15:02:03 | 2022-02-10T16:51:24 | 2022-02-10T16:51:24 | CONTRIBUTOR | null | null | null | ## Describe the bug
A clear and concise description of what the bug is.
## Steps to reproduce the bug
```python
from datasets import load_dataset
iterable_dataset = load_dataset("discovery", name="discovery", split="train", streaming=True)
list(iterable_dataset.take(1))
```
## Expected results
The first row of the train split.
## Actual results
```
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/datasets/iterable_dataset.py", line 365, in __iter__
for key, example in self._iter():
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/datasets/iterable_dataset.py", line 362, in _iter
yield from ex_iterable
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/datasets/iterable_dataset.py", line 272, in __iter__
yield from islice(self.ex_iterable, self.n)
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/datasets/iterable_dataset.py", line 79, in __iter__
yield from self.generate_examples_fn(**self.kwargs)
File "/home/slesage/.cache/huggingface/modules/datasets_modules/datasets/discovery/542fab7a9ddc1d9726160355f7baa06a1ccc44c40bc8e12c09e9bc743aca43a2/discovery.py", line 333, in _generate_examples
with open(data_file, encoding="utf8") as f:
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/datasets/streaming.py", line 64, in wrapper
return function(*args, use_auth_token=use_auth_token, **kwargs)
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/datasets/utils/streaming_download_manager.py", line 369, in xopen
file_obj = fsspec.open(file, mode=mode, *args, **kwargs).open()
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/fsspec/core.py", line 456, in open
return open_files(
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/fsspec/core.py", line 288, in open_files
fs, fs_token, paths = get_fs_token_paths(
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/fsspec/core.py", line 611, in get_fs_token_paths
fs = filesystem(protocol, **inkwargs)
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/fsspec/registry.py", line 253, in filesystem
return cls(**storage_options)
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/fsspec/spec.py", line 68, in __call__
obj = super().__call__(*args, **kwargs)
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/fsspec/implementations/zip.py", line 57, in __init__
self.zip = zipfile.ZipFile(self.fo)
File "/home/slesage/.pyenv/versions/3.9.6/lib/python3.9/zipfile.py", line 1257, in __init__
self._RealGetContents()
File "/home/slesage/.pyenv/versions/3.9.6/lib/python3.9/zipfile.py", line 1320, in _RealGetContents
endrec = _EndRecData(fp)
File "/home/slesage/.pyenv/versions/3.9.6/lib/python3.9/zipfile.py", line 263, in _EndRecData
fpin.seek(0, 2)
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/fsspec/implementations/http.py", line 676, in seek
raise ValueError("Cannot seek streaming HTTP file")
ValueError: Cannot seek streaming HTTP file
```
## Environment info
- `datasets` version: 1.18.3
- Platform: Linux-5.11.0-1027-aws-x86_64-with-glibc2.31
- Python version: 3.9.6
- PyArrow version: 6.0.1
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3677/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3677/timeline | null |
https://api.github.com/repos/huggingface/datasets/issues/3676 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3676/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3676/comments | https://api.github.com/repos/huggingface/datasets/issues/3676/events | https://github.com/huggingface/datasets/issues/3676 | 1,123,096,362 | I_kwDODunzps5C8Rcq | 3,676 | `None` replaced by `[]` after first batch in map | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [
{
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
}
] | null | 2 | 2022-02-03T13:36:48 | 2022-02-03T16:30:52 | null | MEMBER | null | null | null | Sometimes `None` can be replaced by `[]` when running map:
```python
from datasets import Dataset
ds = Dataset.from_dict({"a": range(4)})
ds = ds.map(lambda x: {"b": [[None, [0]]]}, batched=True, batch_size=1, remove_columns=["a"])
print(ds.to_pandas())
# b
# 0 [None, [0]]
# 1 [[], [0]]
# 2 [[], [0]]
# 3 [[], [0]]
```
This issue has been experienced when running the `run_qa.py` example from `transformers` (see issue https://github.com/huggingface/transformers/issues/15401)
This can be due to a bug in when casting `None` in nested lists. Casting only happens after the first batch, since the first batch is used to infer the feature types.
cc @sgugger | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3676/reactions",
"total_count": 2,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 1,
"rocket": 0,
"eyes": 1
} | https://api.github.com/repos/huggingface/datasets/issues/3676/timeline | null |
https://api.github.com/repos/huggingface/datasets/issues/3675 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3675/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3675/comments | https://api.github.com/repos/huggingface/datasets/issues/3675/events | https://github.com/huggingface/datasets/issues/3675 | 1,123,078,408 | I_kwDODunzps5C8NEI | 3,675 | Add CodeContests dataset | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 2067376369,
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request",
"name": "dataset request",
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset"
}
] | open | false | null | [] | null | 1 | 2022-02-03T13:20:00 | 2022-02-10T20:50:38 | null | CONTRIBUTOR | null | null | null | ## Adding a Dataset
- **Name:** CodeContests
- **Description:** CodeContests is a competitive programming dataset for machine-learning.
- **Paper:**
- **Data:** https://github.com/deepmind/code_contests
- **Motivation:** This dataset was used when training [AlphaCode](https://deepmind.com/blog/article/Competitive-programming-with-AlphaCode).
Instructions to add a new dataset can be found [here](https://github.com/huggingface/datasets/blob/master/ADD_NEW_DATASET.md).
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3675/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3675/timeline | null |
https://api.github.com/repos/huggingface/datasets/issues/3674 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3674/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3674/comments | https://api.github.com/repos/huggingface/datasets/issues/3674/events | https://github.com/huggingface/datasets/pull/3674 | 1,123,027,874 | PR_kwDODunzps4yBe17 | 3,674 | Add FrugalScore metric | {
"login": "moussaKam",
"id": 28675016,
"node_id": "MDQ6VXNlcjI4Njc1MDE2",
"avatar_url": "https://avatars.githubusercontent.com/u/28675016?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/moussaKam",
"html_url": "https://github.com/moussaKam",
"followers_url": "https://api.github.com/users/moussaKam/followers",
"following_url": "https://api.github.com/users/moussaKam/following{/other_user}",
"gists_url": "https://api.github.com/users/moussaKam/gists{/gist_id}",
"starred_url": "https://api.github.com/users/moussaKam/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/moussaKam/subscriptions",
"organizations_url": "https://api.github.com/users/moussaKam/orgs",
"repos_url": "https://api.github.com/users/moussaKam/repos",
"events_url": "https://api.github.com/users/moussaKam/events{/privacy}",
"received_events_url": "https://api.github.com/users/moussaKam/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | 2 | 2022-02-03T12:28:52 | 2022-02-08T15:28:56 | null | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3674",
"html_url": "https://github.com/huggingface/datasets/pull/3674",
"diff_url": "https://github.com/huggingface/datasets/pull/3674.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3674.patch",
"merged_at": null
} | This pull request add FrugalScore metric for NLG systems evaluation.
FrugalScore is a reference-based metric for NLG models evaluation. It is based on a distillation approach that allows to learn a fixed, low cost version of any expensive NLG metric, while retaining most of its original performance.
Paper: https://arxiv.org/abs/2110.08559?context=cs
Github: https://github.com/moussaKam/FrugalScore
@lhoestq | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3674/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3674/timeline | null |
https://api.github.com/repos/huggingface/datasets/issues/3673 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3673/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3673/comments | https://api.github.com/repos/huggingface/datasets/issues/3673/events | https://github.com/huggingface/datasets/issues/3673 | 1,123,010,520 | I_kwDODunzps5C78fY | 3,673 | `load_dataset("snli")` is different from dataset viewer | {
"login": "pietrolesci",
"id": 61748653,
"node_id": "MDQ6VXNlcjYxNzQ4NjUz",
"avatar_url": "https://avatars.githubusercontent.com/u/61748653?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/pietrolesci",
"html_url": "https://github.com/pietrolesci",
"followers_url": "https://api.github.com/users/pietrolesci/followers",
"following_url": "https://api.github.com/users/pietrolesci/following{/other_user}",
"gists_url": "https://api.github.com/users/pietrolesci/gists{/gist_id}",
"starred_url": "https://api.github.com/users/pietrolesci/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/pietrolesci/subscriptions",
"organizations_url": "https://api.github.com/users/pietrolesci/orgs",
"repos_url": "https://api.github.com/users/pietrolesci/repos",
"events_url": "https://api.github.com/users/pietrolesci/events{/privacy}",
"received_events_url": "https://api.github.com/users/pietrolesci/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
},
{
"id": 3470211881,
"node_id": "LA_kwDODunzps7O1zsp",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset-viewer",
"name": "dataset-viewer",
"color": "E5583E",
"default": false,
"description": "Related to the dataset viewer on huggingface.co"
}
] | closed | false | null | [
{
"login": "severo",
"id": 1676121,
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/severo",
"html_url": "https://github.com/severo",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://api.github.com/users/severo/gists{/gist_id}",
"starred_url": "https://api.github.com/users/severo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/severo/subscriptions",
"organizations_url": "https://api.github.com/users/severo/orgs",
"repos_url": "https://api.github.com/users/severo/repos",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"received_events_url": "https://api.github.com/users/severo/received_events",
"type": "User",
"site_admin": false
}
] | null | 9 | 2022-02-03T12:10:43 | 2022-02-11T17:01:21 | 2022-02-11T17:01:21 | NONE | null | null | null | ## Describe the bug
The dataset that is downloaded from the Hub via `load_dataset("snli")` is different from what is available in the dataset viewer. In the viewer the labels are not encoded (i.e., "neutral", "entailment", "contradiction"), while the downloaded dataset shows the encoded labels (i.e., 0, 1, 2).
Is this expected?
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version:
- Platform: Ubuntu 20.4
- Python version: 3.7
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3673/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3673/timeline | null |
https://api.github.com/repos/huggingface/datasets/issues/3672 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3672/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3672/comments | https://api.github.com/repos/huggingface/datasets/issues/3672/events | https://github.com/huggingface/datasets/pull/3672 | 1,122,980,556 | PR_kwDODunzps4yBUrZ | 3,672 | Prioritize `module.builder_kwargs` over defaults in `TestCommand` | {
"login": "lvwerra",
"id": 8264887,
"node_id": "MDQ6VXNlcjgyNjQ4ODc=",
"avatar_url": "https://avatars.githubusercontent.com/u/8264887?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lvwerra",
"html_url": "https://github.com/lvwerra",
"followers_url": "https://api.github.com/users/lvwerra/followers",
"following_url": "https://api.github.com/users/lvwerra/following{/other_user}",
"gists_url": "https://api.github.com/users/lvwerra/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lvwerra/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lvwerra/subscriptions",
"organizations_url": "https://api.github.com/users/lvwerra/orgs",
"repos_url": "https://api.github.com/users/lvwerra/repos",
"events_url": "https://api.github.com/users/lvwerra/events{/privacy}",
"received_events_url": "https://api.github.com/users/lvwerra/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | 0 | 2022-02-03T11:38:42 | 2022-02-04T12:37:20 | 2022-02-04T12:37:19 | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3672",
"html_url": "https://github.com/huggingface/datasets/pull/3672",
"diff_url": "https://github.com/huggingface/datasets/pull/3672.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3672.patch",
"merged_at": "2022-02-04T12:37:19"
} | This fixes a bug in the `TestCommand` where multiple kwargs for `name` were passed if it was set in both default and `module.builder_kwargs`. Example error:
```Python
Traceback (most recent call last):
File "create_metadata.py", line 96, in <module>
main(**vars(args))
File "create_metadata.py", line 86, in main
metadata_command.run()
File "/opt/conda/lib/python3.7/site-packages/datasets/commands/test.py", line 144, in run
for j, builder in enumerate(get_builders()):
File "/opt/conda/lib/python3.7/site-packages/datasets/commands/test.py", line 141, in get_builders
name=name, cache_dir=self._cache_dir, data_dir=self._data_dir, **module.builder_kwargs
TypeError: type object got multiple values for keyword argument 'name'
```
Let me know what you think. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3672/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3672/timeline | null |
https://api.github.com/repos/huggingface/datasets/issues/3671 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3671/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3671/comments | https://api.github.com/repos/huggingface/datasets/issues/3671/events | https://github.com/huggingface/datasets/issues/3671 | 1,122,864,253 | I_kwDODunzps5C7Yx9 | 3,671 | Give an estimate of the dataset size in DatasetInfo | {
"login": "severo",
"id": 1676121,
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/severo",
"html_url": "https://github.com/severo",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://api.github.com/users/severo/gists{/gist_id}",
"starred_url": "https://api.github.com/users/severo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/severo/subscriptions",
"organizations_url": "https://api.github.com/users/severo/orgs",
"repos_url": "https://api.github.com/users/severo/repos",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"received_events_url": "https://api.github.com/users/severo/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
}
] | open | false | null | [] | null | 0 | 2022-02-03T09:47:10 | 2022-02-03T09:47:10 | null | CONTRIBUTOR | null | null | null | **Is your feature request related to a problem? Please describe.**
Currently, only part of the datasets provide `dataset_size`, `download_size`, `size_in_bytes` (and `num_bytes` and `num_examples` inside `splits`). I would want to get this information, or an estimation, for all the datasets.
**Describe the solution you'd like**
- get access to the git information for the dataset files hosted on the hub
- look at the [`Content-Length`](https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers/Content-Length) for the files served by HTTP
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3671/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3671/timeline | null |
https://api.github.com/repos/huggingface/datasets/issues/3670 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3670/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3670/comments | https://api.github.com/repos/huggingface/datasets/issues/3670/events | https://github.com/huggingface/datasets/pull/3670 | 1,122,439,827 | PR_kwDODunzps4x_kBx | 3,670 | feat: 🎸 generate info if dataset_infos.json does not exist | {
"login": "severo",
"id": 1676121,
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/severo",
"html_url": "https://github.com/severo",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://api.github.com/users/severo/gists{/gist_id}",
"starred_url": "https://api.github.com/users/severo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/severo/subscriptions",
"organizations_url": "https://api.github.com/users/severo/orgs",
"repos_url": "https://api.github.com/users/severo/repos",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"received_events_url": "https://api.github.com/users/severo/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | 2 | 2022-02-02T22:11:56 | 2022-02-11T20:24:35 | null | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3670",
"html_url": "https://github.com/huggingface/datasets/pull/3670",
"diff_url": "https://github.com/huggingface/datasets/pull/3670.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3670.patch",
"merged_at": null
} | in get_dataset_infos(). Also: add the `use_auth_token` parameter, and create get_dataset_config_info()
✅ Closes: #3013 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3670/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3670/timeline | null |
https://api.github.com/repos/huggingface/datasets/issues/3669 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3669/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3669/comments | https://api.github.com/repos/huggingface/datasets/issues/3669/events | https://github.com/huggingface/datasets/pull/3669 | 1,122,335,622 | PR_kwDODunzps4x_OTI | 3,669 | Common voice validated partition | {
"login": "shalymin-amzn",
"id": 98762373,
"node_id": "U_kgDOBeL-hQ",
"avatar_url": "https://avatars.githubusercontent.com/u/98762373?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/shalymin-amzn",
"html_url": "https://github.com/shalymin-amzn",
"followers_url": "https://api.github.com/users/shalymin-amzn/followers",
"following_url": "https://api.github.com/users/shalymin-amzn/following{/other_user}",
"gists_url": "https://api.github.com/users/shalymin-amzn/gists{/gist_id}",
"starred_url": "https://api.github.com/users/shalymin-amzn/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/shalymin-amzn/subscriptions",
"organizations_url": "https://api.github.com/users/shalymin-amzn/orgs",
"repos_url": "https://api.github.com/users/shalymin-amzn/repos",
"events_url": "https://api.github.com/users/shalymin-amzn/events{/privacy}",
"received_events_url": "https://api.github.com/users/shalymin-amzn/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | 7 | 2022-02-02T20:04:43 | 2022-02-08T17:26:52 | 2022-02-08T17:23:12 | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3669",
"html_url": "https://github.com/huggingface/datasets/pull/3669",
"diff_url": "https://github.com/huggingface/datasets/pull/3669.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3669.patch",
"merged_at": "2022-02-08T17:23:12"
} | This patch adds access to the 'validated' partitions of CommonVoice datasets (provided by the dataset creators but not available in the HuggingFace interface yet).
As 'validated' contains significantly more data than 'train' (although it contains both test and validation, so one needs to be careful there), it can be useful to train better models where no strict comparison with the previous work is intended. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3669/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3669/timeline | null |
https://api.github.com/repos/huggingface/datasets/issues/3668 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3668/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3668/comments | https://api.github.com/repos/huggingface/datasets/issues/3668/events | https://github.com/huggingface/datasets/issues/3668 | 1,122,261,736 | I_kwDODunzps5C5Fro | 3,668 | Couldn't cast array of type string error with cast_column | {
"login": "R4ZZ3",
"id": 25264037,
"node_id": "MDQ6VXNlcjI1MjY0MDM3",
"avatar_url": "https://avatars.githubusercontent.com/u/25264037?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/R4ZZ3",
"html_url": "https://github.com/R4ZZ3",
"followers_url": "https://api.github.com/users/R4ZZ3/followers",
"following_url": "https://api.github.com/users/R4ZZ3/following{/other_user}",
"gists_url": "https://api.github.com/users/R4ZZ3/gists{/gist_id}",
"starred_url": "https://api.github.com/users/R4ZZ3/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/R4ZZ3/subscriptions",
"organizations_url": "https://api.github.com/users/R4ZZ3/orgs",
"repos_url": "https://api.github.com/users/R4ZZ3/repos",
"events_url": "https://api.github.com/users/R4ZZ3/events{/privacy}",
"received_events_url": "https://api.github.com/users/R4ZZ3/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | null | [] | null | 2 | 2022-02-02T18:33:29 | 2022-02-09T07:07:42 | 2022-02-09T07:07:42 | NONE | null | null | null | ## Describe the bug
In OVH cloud during Huggingface Robust-speech-recognition event on a AI training notebook instance using jupyter lab and running jupyter notebook When using the dataset.cast_column("audio",Audio(sampling_rate=16_000))
method I get error

This was working with datasets version 1.17.1.dev0
but now with version 1.18.3 produces the error above.
## Steps to reproduce the bug
load dataset:

remove columns:

run my fix_path function.
This also creates the audio column that is referring to the absolute file path of the audio

Then I concatenate few other datasets and finally try the cast_column method
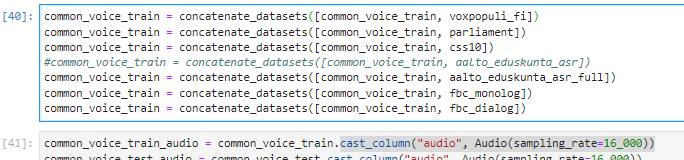
but get error:
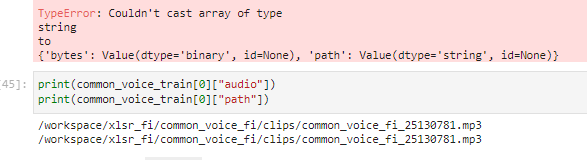
## Expected results
A clear and concise description of the expected results.
## Actual results
Specify the actual results or traceback.
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.18.3
- Platform:
OVH Cloud, AI Training section, container for Huggingface Robust Speech Recognition event image(baaastijn/ovh_huggingface)
- Python version: 3.8.8
- PyArrow version:
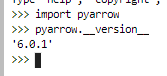
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3668/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3668/timeline | null |
https://api.github.com/repos/huggingface/datasets/issues/3667 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3667/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3667/comments | https://api.github.com/repos/huggingface/datasets/issues/3667/events | https://github.com/huggingface/datasets/pull/3667 | 1,122,060,630 | PR_kwDODunzps4x-Ujt | 3,667 | Process .opus files with torchaudio | {
"login": "polinaeterna",
"id": 16348744,
"node_id": "MDQ6VXNlcjE2MzQ4NzQ0",
"avatar_url": "https://avatars.githubusercontent.com/u/16348744?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/polinaeterna",
"html_url": "https://github.com/polinaeterna",
"followers_url": "https://api.github.com/users/polinaeterna/followers",
"following_url": "https://api.github.com/users/polinaeterna/following{/other_user}",
"gists_url": "https://api.github.com/users/polinaeterna/gists{/gist_id}",
"starred_url": "https://api.github.com/users/polinaeterna/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/polinaeterna/subscriptions",
"organizations_url": "https://api.github.com/users/polinaeterna/orgs",
"repos_url": "https://api.github.com/users/polinaeterna/repos",
"events_url": "https://api.github.com/users/polinaeterna/events{/privacy}",
"received_events_url": "https://api.github.com/users/polinaeterna/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [
{
"login": "polinaeterna",
"id": 16348744,
"node_id": "MDQ6VXNlcjE2MzQ4NzQ0",
"avatar_url": "https://avatars.githubusercontent.com/u/16348744?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/polinaeterna",
"html_url": "https://github.com/polinaeterna",
"followers_url": "https://api.github.com/users/polinaeterna/followers",
"following_url": "https://api.github.com/users/polinaeterna/following{/other_user}",
"gists_url": "https://api.github.com/users/polinaeterna/gists{/gist_id}",
"starred_url": "https://api.github.com/users/polinaeterna/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/polinaeterna/subscriptions",
"organizations_url": "https://api.github.com/users/polinaeterna/orgs",
"repos_url": "https://api.github.com/users/polinaeterna/repos",
"events_url": "https://api.github.com/users/polinaeterna/events{/privacy}",
"received_events_url": "https://api.github.com/users/polinaeterna/received_events",
"type": "User",
"site_admin": false
}
] | null | 4 | 2022-02-02T15:23:14 | 2022-02-04T15:29:38 | 2022-02-04T15:29:38 | CONTRIBUTOR | null | true | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3667",
"html_url": "https://github.com/huggingface/datasets/pull/3667",
"diff_url": "https://github.com/huggingface/datasets/pull/3667.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3667.patch",
"merged_at": null
} | @anton-l suggested to proccess .opus files with `torchaudio` instead of `soundfile` as it's faster:

(moreover, I didn't manage to load .opus files with `soundfile` / `librosa` locally on any my machine anyway for some reason, even with `ffmpeg` installed).
For now my current changes work with locally stored file:
```python
# download sample opus file (from MultilingualSpokenWords dataset)
!wget https://huggingface.co/datasets/polinaeterna/test_opus/resolve/main/common_voice_tt_17737010.opus
from datasets import Dataset, Audio
audio_path = "common_voice_tt_17737010.opus"
dataset = Dataset.from_dict({"audio": [audio_path]}).cast_column("audio", Audio(48000))
dataset[0]
# {'audio': {'path': 'common_voice_tt_17737010.opus',
# 'array': array([ 0.0000000e+00, 0.0000000e+00, 3.0517578e-05, ...,
# -6.1035156e-05, 6.1035156e-05, 0.0000000e+00], dtype=float32),
# 'sampling_rate': 48000}}
```
But it doesn't work when loading inside s dataset from bytes (I checked on [MultilingualSpokenWords](https://github.com/huggingface/datasets/pull/3666), the PR is a draft now, maybe the bug is somewhere there )
```python
import torchaudio
with open(audio_path, "rb") as b:
print(torchaudio.load(b))
# RuntimeError: Error loading audio file: failed to open file <in memory buffer>
``` | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3667/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3667/timeline | null |
https://api.github.com/repos/huggingface/datasets/issues/3666 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3666/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3666/comments | https://api.github.com/repos/huggingface/datasets/issues/3666/events | https://github.com/huggingface/datasets/pull/3666 | 1,122,058,894 | PR_kwDODunzps4x-ULz | 3,666 | Multilingual Spoken Words | {
"login": "polinaeterna",
"id": 16348744,
"node_id": "MDQ6VXNlcjE2MzQ4NzQ0",
"avatar_url": "https://avatars.githubusercontent.com/u/16348744?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/polinaeterna",
"html_url": "https://github.com/polinaeterna",
"followers_url": "https://api.github.com/users/polinaeterna/followers",
"following_url": "https://api.github.com/users/polinaeterna/following{/other_user}",
"gists_url": "https://api.github.com/users/polinaeterna/gists{/gist_id}",
"starred_url": "https://api.github.com/users/polinaeterna/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/polinaeterna/subscriptions",
"organizations_url": "https://api.github.com/users/polinaeterna/orgs",
"repos_url": "https://api.github.com/users/polinaeterna/repos",
"events_url": "https://api.github.com/users/polinaeterna/events{/privacy}",
"received_events_url": "https://api.github.com/users/polinaeterna/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | 1 | 2022-02-02T15:21:48 | 2022-02-11T17:30:28 | null | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3666",
"html_url": "https://github.com/huggingface/datasets/pull/3666",
"diff_url": "https://github.com/huggingface/datasets/pull/3666.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3666.patch",
"merged_at": null
} | Add [Multillingual Spoken Words dataset](https://mlcommons.org/en/multilingual-spoken-words/)
You can specify multiple languages for downloading 😌:
```python
ds = load_dataset("datasets/ml_spoken_words", languages=["ar", "tt"])
```
1. I didn't take into account that each time you pass a set of languages the data for a specific language is downloaded even if it was downloaded before (since these are custom configs like `ar+tt` and `ar+tt+br`. Maybe that wasn't a good idea?
2. The script will have to be slightly changed after merge of https://github.com/huggingface/datasets/pull/3664
2. Just can't figure out what wrong with dummy files... 😞 Maybe we should get rid of them at some point 😁 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3666/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 1,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3666/timeline | null |
https://api.github.com/repos/huggingface/datasets/issues/3665 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3665/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3665/comments | https://api.github.com/repos/huggingface/datasets/issues/3665/events | https://github.com/huggingface/datasets/pull/3665 | 1,121,753,385 | PR_kwDODunzps4x9TnU | 3,665 | Fix MP3 resampling when a dataset's audio files have different sampling rates | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | 0 | 2022-02-02T10:31:45 | 2022-02-02T10:52:26 | 2022-02-02T10:52:26 | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3665",
"html_url": "https://github.com/huggingface/datasets/pull/3665",
"diff_url": "https://github.com/huggingface/datasets/pull/3665.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3665.patch",
"merged_at": "2022-02-02T10:52:25"
} | The resampler needs to be updated if the `orig_freq` doesn't match the audio file sampling rate
Fix https://github.com/huggingface/datasets/issues/3662 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3665/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3665/timeline | null |
https://api.github.com/repos/huggingface/datasets/issues/3664 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3664/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3664/comments | https://api.github.com/repos/huggingface/datasets/issues/3664/events | https://github.com/huggingface/datasets/pull/3664 | 1,121,233,301 | PR_kwDODunzps4x7mg_ | 3,664 | [WIP] Return local paths to Common Voice | {
"login": "anton-l",
"id": 26864830,
"node_id": "MDQ6VXNlcjI2ODY0ODMw",
"avatar_url": "https://avatars.githubusercontent.com/u/26864830?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/anton-l",
"html_url": "https://github.com/anton-l",
"followers_url": "https://api.github.com/users/anton-l/followers",
"following_url": "https://api.github.com/users/anton-l/following{/other_user}",
"gists_url": "https://api.github.com/users/anton-l/gists{/gist_id}",
"starred_url": "https://api.github.com/users/anton-l/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/anton-l/subscriptions",
"organizations_url": "https://api.github.com/users/anton-l/orgs",
"repos_url": "https://api.github.com/users/anton-l/repos",
"events_url": "https://api.github.com/users/anton-l/events{/privacy}",
"received_events_url": "https://api.github.com/users/anton-l/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | 16 | 2022-02-01T21:48:27 | 2022-02-11T23:32:08 | null | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3664",
"html_url": "https://github.com/huggingface/datasets/pull/3664",
"diff_url": "https://github.com/huggingface/datasets/pull/3664.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3664.patch",
"merged_at": null
} | Fixes https://github.com/huggingface/datasets/issues/3663
This is a proposed way of returning the old local file-based generator while keeping the new streaming generator intact.
TODO:
- [ ] brainstorm a bit more on https://github.com/huggingface/datasets/issues/3663 to see if we can do better
- [ ] refactor the heck out of this PR to avoid completely copying the logic between the two generators | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3664/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3664/timeline | null |
https://api.github.com/repos/huggingface/datasets/issues/3663 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3663/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3663/comments | https://api.github.com/repos/huggingface/datasets/issues/3663/events | https://github.com/huggingface/datasets/issues/3663 | 1,121,067,647 | I_kwDODunzps5C0iJ_ | 3,663 | [Audio] Path of Common Voice cannot be used for audio loading anymore | {
"login": "patrickvonplaten",
"id": 23423619,
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patrickvonplaten",
"html_url": "https://github.com/patrickvonplaten",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | open | false | null | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
},
{
"login": "polinaeterna",
"id": 16348744,
"node_id": "MDQ6VXNlcjE2MzQ4NzQ0",
"avatar_url": "https://avatars.githubusercontent.com/u/16348744?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/polinaeterna",
"html_url": "https://github.com/polinaeterna",
"followers_url": "https://api.github.com/users/polinaeterna/followers",
"following_url": "https://api.github.com/users/polinaeterna/following{/other_user}",
"gists_url": "https://api.github.com/users/polinaeterna/gists{/gist_id}",
"starred_url": "https://api.github.com/users/polinaeterna/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/polinaeterna/subscriptions",
"organizations_url": "https://api.github.com/users/polinaeterna/orgs",
"repos_url": "https://api.github.com/users/polinaeterna/repos",
"events_url": "https://api.github.com/users/polinaeterna/events{/privacy}",
"received_events_url": "https://api.github.com/users/polinaeterna/received_events",
"type": "User",
"site_admin": false
},
{
"login": "anton-l",
"id": 26864830,
"node_id": "MDQ6VXNlcjI2ODY0ODMw",
"avatar_url": "https://avatars.githubusercontent.com/u/26864830?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/anton-l",
"html_url": "https://github.com/anton-l",
"followers_url": "https://api.github.com/users/anton-l/followers",
"following_url": "https://api.github.com/users/anton-l/following{/other_user}",
"gists_url": "https://api.github.com/users/anton-l/gists{/gist_id}",
"starred_url": "https://api.github.com/users/anton-l/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/anton-l/subscriptions",
"organizations_url": "https://api.github.com/users/anton-l/orgs",
"repos_url": "https://api.github.com/users/anton-l/repos",
"events_url": "https://api.github.com/users/anton-l/events{/privacy}",
"received_events_url": "https://api.github.com/users/anton-l/received_events",
"type": "User",
"site_admin": false
},
{
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"type": "User",
"site_admin": false
}
] | null | 6 | 2022-02-01T18:40:10 | 2022-02-08T16:05:18 | null | MEMBER | null | null | null | ## Describe the bug
## Steps to reproduce the bug
```python
from datasets import load_dataset
from torchaudio import load
ds = load_dataset("common_voice", "ab", split="train")
# both of the following commands fail at the moment
load(ds[0]["audio"]["path"])
load(ds[0]["path"])
```
## Expected results
The path should be the complete absolute path to the downloaded audio file not some relative path.
## Actual results
```bash
~/hugging_face/venv_3.9/lib/python3.9/site-packages/torchaudio/backend/sox_io_backend.py in load(filepath, frame_offset, num_frames, normalize, channels_first, format)
150 filepath, frame_offset, num_frames, normalize, channels_first, format)
151 filepath = os.fspath(filepath)
--> 152 return torch.ops.torchaudio.sox_io_load_audio_file(
153 filepath, frame_offset, num_frames, normalize, channels_first, format)
154
RuntimeError: Error loading audio file: failed to open file cv-corpus-6.1-2020-12-11/ab/clips/common_voice_ab_19904194.mp3
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.18.3.dev0
- Platform: Linux-5.4.0-96-generic-x86_64-with-glibc2.27
- Python version: 3.9.1
- PyArrow version: 3.0.0
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3663/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3663/timeline | null |
https://api.github.com/repos/huggingface/datasets/issues/3662 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3662/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3662/comments | https://api.github.com/repos/huggingface/datasets/issues/3662/events | https://github.com/huggingface/datasets/issues/3662 | 1,121,024,403 | I_kwDODunzps5C0XmT | 3,662 | [Audio] MP3 resampling is incorrect when dataset's audio files have different sampling rates | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | 6 | 2022-02-01T17:55:04 | 2022-02-02T10:52:25 | 2022-02-02T10:52:25 | MEMBER | null | null | null | The Audio feature resampler for MP3 gets stuck with the first original frequencies it meets, which leads to subsequent decoding to be incorrect.
Here is a code to reproduce the issue:
Let's first consider two audio files with different sampling rates 32000 and 16000:
```python
# first download a mp3 file with sampling_rate=32000
!wget https://file-examples-com.github.io/uploads/2017/11/file_example_MP3_700KB.mp3
import torchaudio
audio_path = "file_example_MP3_700KB.mp3"
audio_path2 = audio_path.replace(".mp3", "_resampled.mp3")
resample = torchaudio.transforms.Resample(32000, 16000) # create a new file with sampling_rate=16000
torchaudio.save(audio_path2, resample(torchaudio.load(audio_path)[0]), 16000)
```
Then we can see an issue here when decoding:
```python
from datasets import Dataset, Audio
dataset = Dataset.from_dict({"audio": [audio_path, audio_path2]}).cast_column("audio", Audio(48000))
dataset[0] # decode the first audio file sets the resampler orig_freq to 32000
print(dataset .features["audio"]._resampler.orig_freq)
# 32000
print(dataset[0]["audio"]["array"].shape) # here decoding is fine
# (1308096,)
dataset = Dataset.from_dict({"audio": [audio_path, audio_path2]}).cast_column("audio", Audio(48000))
dataset[1] # decode the second audio file sets the resampler orig_freq to 16000
print(dataset .features["audio"]._resampler.orig_freq)
# 16000
print(dataset[0]["audio"]["array"].shape) # here decoding uses orig_freq=16000 instead of 32000
# (2616192,)
```
The value of `orig_freq` doesn't change no matter what file needs to be decoded
cc @patrickvonplaten @anton-l @cahya-wirawan @albertvillanova
The issue seems to be here in `Audio.decode_mp3`:
https://github.com/huggingface/datasets/blob/4c417d52def6e20359ca16c6723e0a2855e5c3fd/src/datasets/features/audio.py#L176-L180 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3662/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3662/timeline | null |
https://api.github.com/repos/huggingface/datasets/issues/3661 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3661/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3661/comments | https://api.github.com/repos/huggingface/datasets/issues/3661/events | https://github.com/huggingface/datasets/pull/3661 | 1,121,000,251 | PR_kwDODunzps4x61ad | 3,661 | Remove unnecessary 'r' arg in | {
"login": "bryant1410",
"id": 3905501,
"node_id": "MDQ6VXNlcjM5MDU1MDE=",
"avatar_url": "https://avatars.githubusercontent.com/u/3905501?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/bryant1410",
"html_url": "https://github.com/bryant1410",
"followers_url": "https://api.github.com/users/bryant1410/followers",
"following_url": "https://api.github.com/users/bryant1410/following{/other_user}",
"gists_url": "https://api.github.com/users/bryant1410/gists{/gist_id}",
"starred_url": "https://api.github.com/users/bryant1410/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/bryant1410/subscriptions",
"organizations_url": "https://api.github.com/users/bryant1410/orgs",
"repos_url": "https://api.github.com/users/bryant1410/repos",
"events_url": "https://api.github.com/users/bryant1410/events{/privacy}",
"received_events_url": "https://api.github.com/users/bryant1410/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | 1 | 2022-02-01T17:29:27 | 2022-02-07T16:57:27 | 2022-02-07T16:02:42 | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3661",
"html_url": "https://github.com/huggingface/datasets/pull/3661",
"diff_url": "https://github.com/huggingface/datasets/pull/3661.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3661.patch",
"merged_at": "2022-02-07T16:02:42"
} | Originally from #3489 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3661/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3661/timeline | null |
https://api.github.com/repos/huggingface/datasets/issues/3660 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3660/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3660/comments | https://api.github.com/repos/huggingface/datasets/issues/3660/events | https://github.com/huggingface/datasets/pull/3660 | 1,120,982,671 | PR_kwDODunzps4x6xr8 | 3,660 | Change HTTP links to HTTPS | {
"login": "bryant1410",
"id": 3905501,
"node_id": "MDQ6VXNlcjM5MDU1MDE=",
"avatar_url": "https://avatars.githubusercontent.com/u/3905501?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/bryant1410",
"html_url": "https://github.com/bryant1410",
"followers_url": "https://api.github.com/users/bryant1410/followers",
"following_url": "https://api.github.com/users/bryant1410/following{/other_user}",
"gists_url": "https://api.github.com/users/bryant1410/gists{/gist_id}",
"starred_url": "https://api.github.com/users/bryant1410/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/bryant1410/subscriptions",
"organizations_url": "https://api.github.com/users/bryant1410/orgs",
"repos_url": "https://api.github.com/users/bryant1410/repos",
"events_url": "https://api.github.com/users/bryant1410/events{/privacy}",
"received_events_url": "https://api.github.com/users/bryant1410/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | 0 | 2022-02-01T17:12:51 | 2022-02-01T18:34:47 | null | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3660",
"html_url": "https://github.com/huggingface/datasets/pull/3660",
"diff_url": "https://github.com/huggingface/datasets/pull/3660.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3660.patch",
"merged_at": null
} | I tested the links. I also fixed some typos.
Originally from #3489 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3660/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3660/timeline | null |
https://api.github.com/repos/huggingface/datasets/issues/3659 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3659/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3659/comments | https://api.github.com/repos/huggingface/datasets/issues/3659/events | https://github.com/huggingface/datasets/issues/3659 | 1,120,913,672 | I_kwDODunzps5Cz8kI | 3,659 | push_to_hub but preview not working | {
"login": "thomas-happify",
"id": 66082334,
"node_id": "MDQ6VXNlcjY2MDgyMzM0",
"avatar_url": "https://avatars.githubusercontent.com/u/66082334?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/thomas-happify",
"html_url": "https://github.com/thomas-happify",
"followers_url": "https://api.github.com/users/thomas-happify/followers",
"following_url": "https://api.github.com/users/thomas-happify/following{/other_user}",
"gists_url": "https://api.github.com/users/thomas-happify/gists{/gist_id}",
"starred_url": "https://api.github.com/users/thomas-happify/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/thomas-happify/subscriptions",
"organizations_url": "https://api.github.com/users/thomas-happify/orgs",
"repos_url": "https://api.github.com/users/thomas-happify/repos",
"events_url": "https://api.github.com/users/thomas-happify/events{/privacy}",
"received_events_url": "https://api.github.com/users/thomas-happify/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 3470211881,
"node_id": "LA_kwDODunzps7O1zsp",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset-viewer",
"name": "dataset-viewer",
"color": "E5583E",
"default": false,
"description": "Related to the dataset viewer on huggingface.co"
}
] | closed | false | null | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
}
] | null | 1 | 2022-02-01T16:23:57 | 2022-02-09T08:00:37 | 2022-02-09T08:00:37 | NONE | null | null | null | ## Dataset viewer issue for '*happifyhealth/twitter_pnn*'
**Link:** *[link to the dataset viewer page](https://huggingface.co/datasets/happifyhealth/twitter_pnn)*
I used
```
dataset.push_to_hub("happifyhealth/twitter_pnn")
```
but the preview is not working.
Am I the one who added this dataset ? Yes
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3659/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3659/timeline | null |
End of preview. Expand
in Data Studio
YAML Metadata
Warning:
empty or missing yaml metadata in repo card
(https://huggingface.co/docs/hub/datasets-cards)
annotations_creators:
- machine-generated language_creators:
- machine-generated languages:
- english licenses:
- unknown multilinguality:
- monolingual pretty_name: This dataset contains issues from Hugging Face Github size_categories:
- unknown source_datasets:
- original task_categories:
- text-classification
- text-retrieval task_ids:
- multi-class-classification
- multi-label-classification
- document-retrieval
- Downloads last month
- 27