Datasets:

Preview.
This repository is used to preview the effects of various speech models trained by so-vits-svc-4.0.
Click on the character name to automatically jump to the corresponding training parameters.
I recommend using Google Chrome as other browsers may not load the previewed audio correctly.
The conversion of normal speaking voices is relatively accurate, but songs with a wide range of sounds
and background music and other noises that are difficult to remove may result in a unstable effect.
If you have recommended songs that you would like to try converting and listening to or any other suggestions,
click here to give me advice.
Below are preview audios. Scroll up, down, left, and right to see them all.
| Character Name | Original Voice A | Converted Voice B | A Voice Replaced by B | Song Cover (Click to Download) |
|---|---|---|---|---|
| Wanderer | 夢で会えたら | |||
| HuTao | ......... | ......... | moonlight shadow, 云烟成雨, 原点, 夢で逢えたら, 贝加尔湖畔 | |
| Kamisato Ayaka | アムリタ, 大鱼, 遊園施設, the day you want away | |||
| Yoimiya | 昨夜书, lemon, my heart will go on, | |||
| Keqing | 嚣张, ファティマ, hero, | |||
| Klee | 樱花草, 夢をかなえてドラえもん, sun_shine, | |||
| Shikanoin Heizou | 风继续吹, 小さな恋の歌, love_yourself, | |||
| imallryt | 海阔天空, | |||
| kagami | えるの侵蝕, |
Key Parameters:
audio duration: total duration of the training dataset
epoch: number of rounds of training
Others:
batch_size = number of audio segments trained in one step
segments = the number of segments that the audio is split into ,step = segments * epoch / batch_size, which is where the numbers in the model file name come from
Using the example of "Wanderer" (a character name):
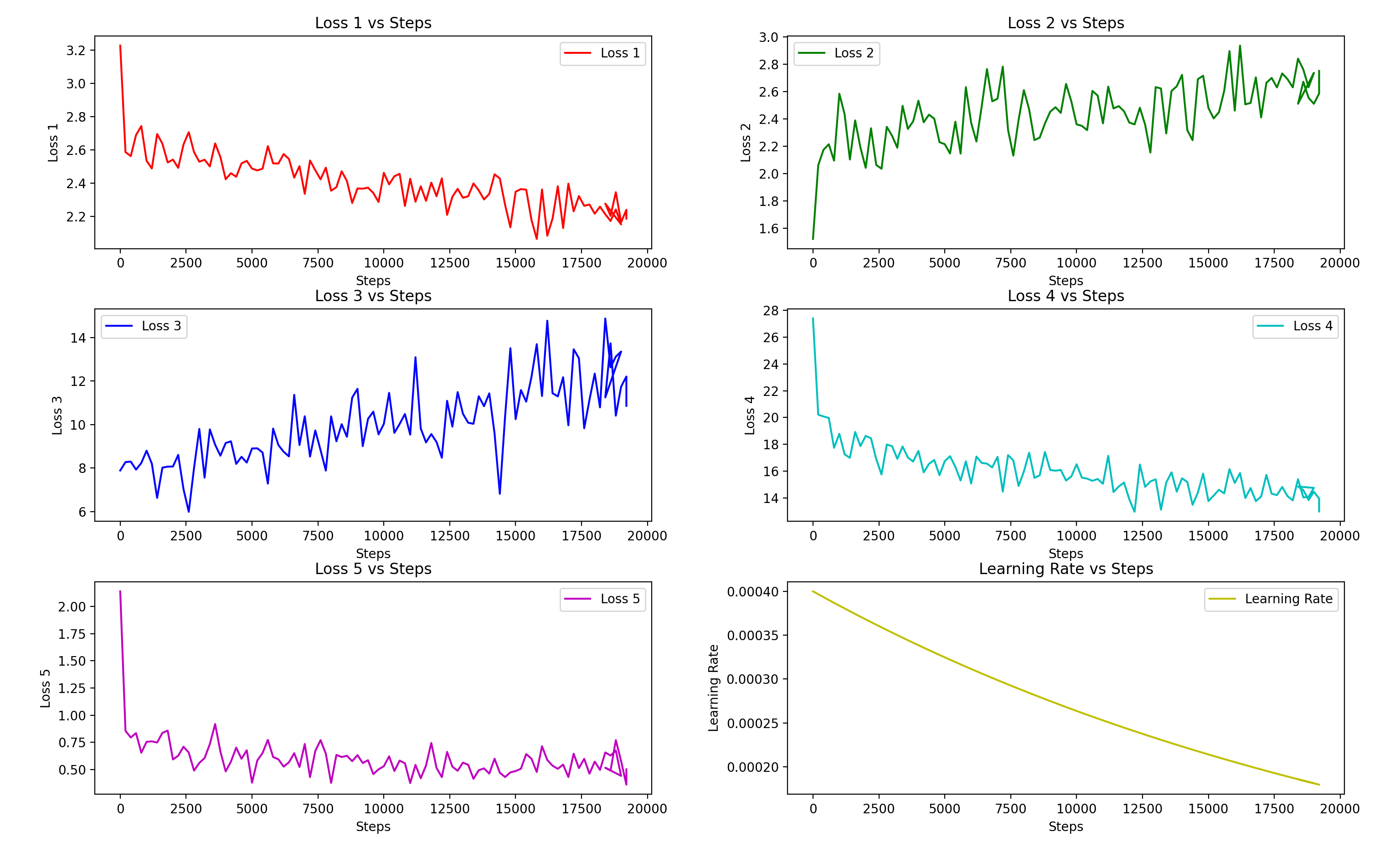
Loss Function Graph: pay attention to step and loss5, for example:
As a difficult test, all the original audios are high-pitched female voices, and this graph
shows the result of training on a 10-minute pure voice audio. The model achieved good performance at around
2800 epochs (10,000 steps), and the actual model used was trained for 5571 epochs (19,500 steps), with
slight differences between the trained voice and the original voice. Please refer to the preview audio above.
In general, 10 minutes is not enough for a sufficient training dataset.
Click here to view related files