
ibm/otter_ubc_classifier
Updated
•
2
The dataset viewer is not available because its heuristics could not detect any supported data files. You can try uploading some data files, or configuring the data files location manually.
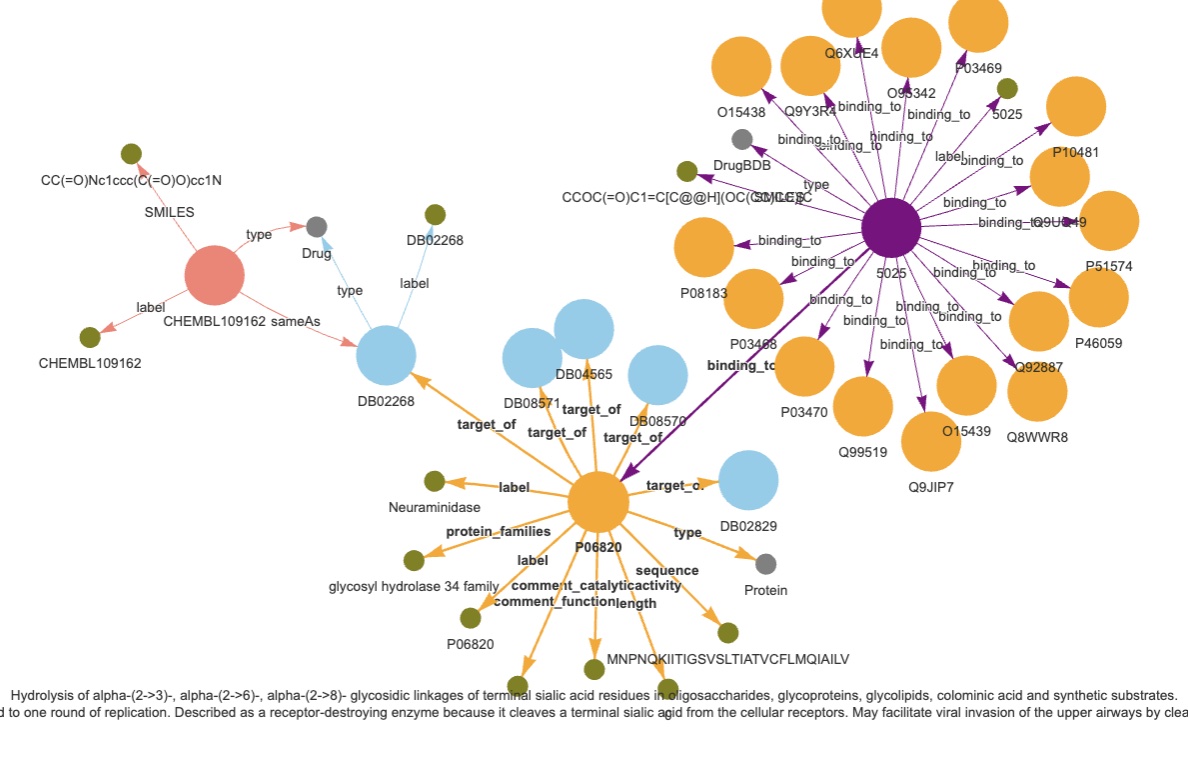
UBC is a dataset comprising entities (Proteins/Drugs) from Uniprot (U), BindingDB (B) and. ChemBL (C). It contains 6,207,654 triples.
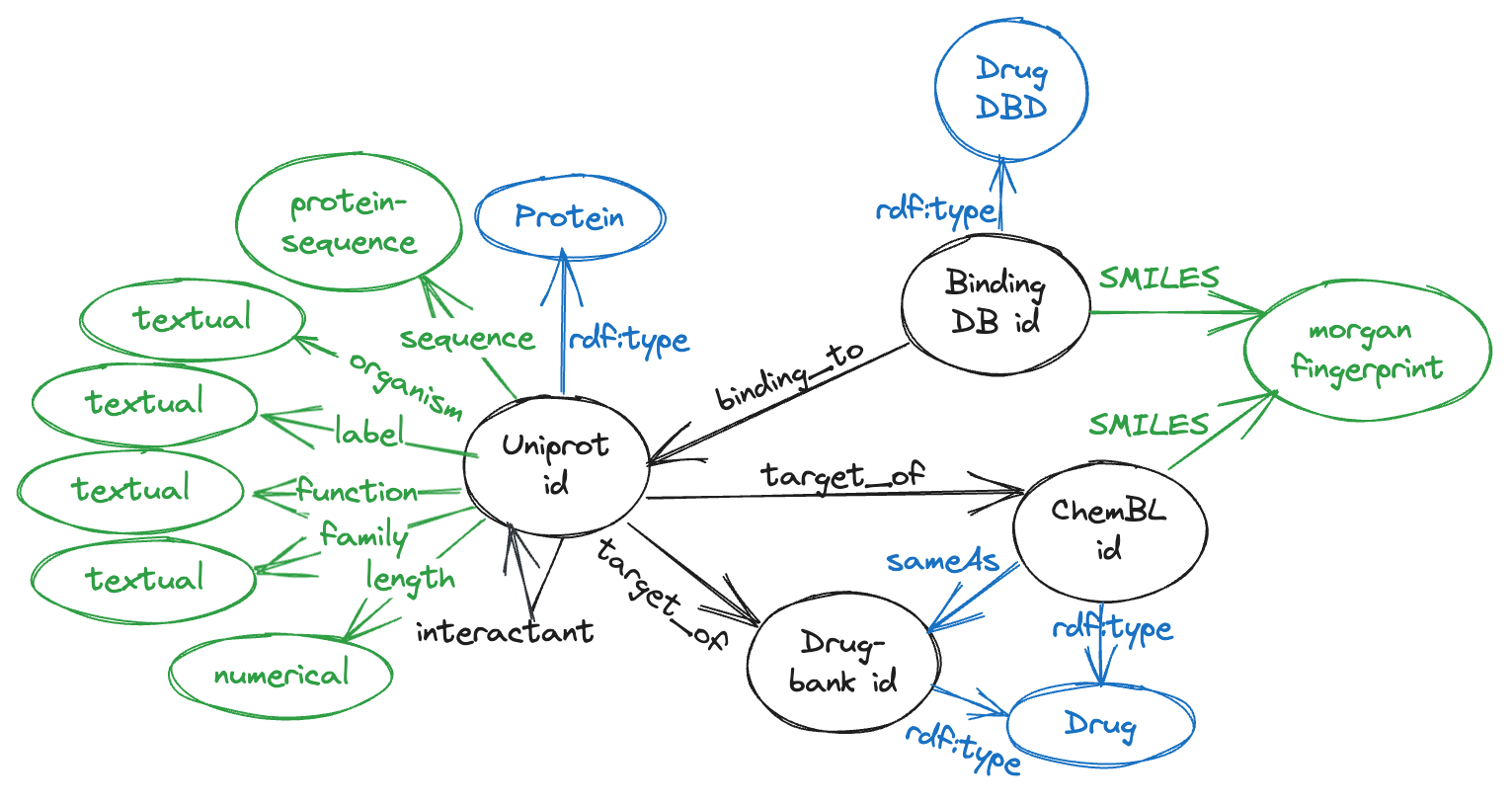
Uniprot comprises of 573,227 proteins from SwissProt, which is the subset of manually curated entries within UniProt, including attributes with different modalities like the sequence (567,483 of them), full name, organism, protein family, description of its function, catalytics activity, pathways and its length. The number of edges are 38,665 of type target_of from Uniprot ids to both ChEMBL and Drugbank ids, and 196,133 interactants between Uniprot protein ids.
BindingDB consists of 2,656,221 data points, involving 1.2 million compounds and 9,000 targets. Instead of utilizing the affinity score, we generate a triple for each combination of drugs and proteins. In order to prevent any data leakage, we eliminate overlapping triples with the TDC DTI dataset. As a result, the dataset concludes with a total of 2,232,392 triples.
ChemBL comprises of drug-like bioactive molecules, 10,261 ChEMBL ids with their corresponding SMILES were downloaded from OpenTargets, from which 7,610 have a sameAs link to drugbank id molecules.
Original datasets:
Paper or resources for more information:
License:
MIT
Where to send questions or comments about the dataset:
Models trained on Otter UBC