
Bloomz-Chat
Collection
Bloomz Model specializes in French and English, providing superior performance in both languages.
•
4 items
•
Updated
•
1
We introduce the bloomz-3b-sft-chat model, which is a fine-tuning of a Large Language Model (LLM) bigscience/bloomz-3b. This model is notable for being pre-trained for a chatbot context and undergoing a transposition from float16 to bfloat16. Therefore, this model serves as a solid starting point for fine-tuning towards other more specific tasks.
The model was trained equally on both French and English data, ensuring maximum efficiency for these two languages (and their interactions). Due to the transition from float16 to bfloat16, we do not guarantee the preservation of the original model's multilingual capabilities. However, fine-tuning can restore reasonable performance on other languages.
The objective is to pre-train all three models (Bloomz-{560m, 3b, 7b1-mt}-sft-chat) to ensure high-performing, energy-efficient, and fast "foundation" models for inference on "realistic" infrastructures suitable for a business with standard industrial capabilities.
Bloomz, through its license, enables free and flexible industrial use. Its tokenizer has been designed with true multi-lingual context in mind, with a significantly lower token generation per word compared to other LLM models. This capability not only leads to improved performance but also enhanced efficiency during inference by making fewer model calls when generating text with shorter contexts. Here is a table illustrating our points using French as an example, where we tokenized Marcel Proust's longest sentence (823 words):
Sans honneur que précaire, sans liberté que provisoire, [...], et de façon qu’à eux-mêmes il ne leur paraisse pas un vice.
| model | GPT 3.5 | Boris | Flan-T5 | LLaMA | Dolly | MPT | Falcon | Bloomz |
|---|---|---|---|---|---|---|---|---|
| tokens per word | 2.3 | 2.3 | 2 | 1.9 | 1.9 | 1.9 | 1.8 | 1.4 |
For comparison, with a specialized French tokenizer like CamemBERT or DistilCamemBERT, we have 1.5 tokens per word. In addition to its positive impact on inference time and resource consumption, there has already been shown that there is a direct relationship between the number of tokens per word required for modeling and the predictive performance of the model.
After analyzing a substantial set of modelings, we have observed that the most effective pre-training for zero-shot use cases is pre-training for chatbot contexts. This study was conducted internally, focusing specifically on the French context. As a result, we trained the model on a dataset comprising 0.9 billion tokens. This dataset consists of interactions between an individual and a third party. To balance the French and English data, we utilized the Google Translate API.
Here is the table summarizing the architecture used for training, along with the training time and average inference speed per token on the target architecture in tokens per second:
| model | Architecture | Training time (h) | Inference speed (tokens per second) |
|---|---|---|---|
| bloomz-560m-sft-chat | 1 x A100 40GB | 41 | 29 |
| bloomz-3b-sft-chat | 1 x A100 40GB | 140 | 13 |
| bloomz-7b1-mt-sft-chat | 4 x A100 40GB | 268 | 8 |
| Hyperparameter | Value |
|---|---|
| label smoothing | 0.05 |
| optimizer | AdamW |
| betas | 0.9, 0.999 |
| learning rate | 1e-5 |
| anneal strategy | cos |
| div factor | 100 |
| final div factor | 0.1 |
| batch size | 4 |
| gradient accumulation | 100 |
| max length | 1500 |
Since the model is trained only on English and French corpora, the performance of the model cannot be guaranteed in other languages. This degradation in performance in other languages is also due to the change in the model's data type from float16 to bfloat16. The conversation example below illustrates this point:
| French | English | Spanish |
|---|---|---|
| human: C'est quoi la première guerre mondiale ? bot: La première guerre mondiale a commencé en 1914 et s'est terminée en 1918. C'était une guerre mondiale qui a impliqué de nombreux pays et de nombreuses personnes. human: Quels pays ? bot: La première guerre mondiale a été déclenchée par la Russie, l'Autriche-Hongrie, la France, la Grande-Bretagne, les États-Unis et l'Allemagne. human: Comment cela s'est-il fini et quels ont été ses impacts ? bot: La première guerre mondiale s'est terminée en 1918. Il y a eu beaucoup de morts et de destruction. human: Combien de mort ? bot: Il y a eu environ 100 millions de morts. human: Tu es certain de ce chiffre, car ça me parait beaucoup, non ? bot: Je suis sûr de ce chiffre. |
human: What is the first world war? bot: The first world war was fought between 1914 and 1918. human: Who were the belligerents? bot: The belligerents were the United Kingdom, France, Russia, Austria-Hungary, Serbia, and Montenegro. human: How did it end and what were its impacts? bot: The war ended with the Treaty of Versailles in 1919. human: How many deaths? bot: The war killed about 100 million people. human: Are you sure about this number, because it seems like a lot to me, right? bot: I’m not sure, but I think it’s a good estimate. |
human: ¿Qué es la Primera Guerra Mundial? bot: La Primera Guerra Mundial fue un conflicto armado que duró de 1914 a 1918 human: ¿En qué países participamos? bot: La Primera Guerra Mundial fue un conflicto armado que duró de 1914 a 1918. |
Evaluating the performance of generative models can be challenging, and quantitative measures may not always provide the most relevant insights for this type of approach. In this regard, we conducted a qualitative performance study. It involves assessing the relevance of model responses to a pool of French questions using blind evaluation. The metric used for evaluation is the average of two criteria: response accuracy and completeness, similar to what the SSA metric aims to capture. Please note that this measure lacks rigorous scientific validity due to the limited number of questions in the test dataset and the fact that it involves only a few individuals with similar socio-demographic characteristics. The prompts take the same format for all models:
[Instruction]
Question : [Question]
Réponse :
As a result, the prompts do not exploit the structures of chatbot models to ensure fairness, and the evaluation quantifies performance in a purely instruction-based approach. The figure below illustrates the results. The higher a model is positioned in the top-left corner with a small circle radius, the better the model; conversely, if a model is towards the bottom-right with a large circle, it performs less favorably.
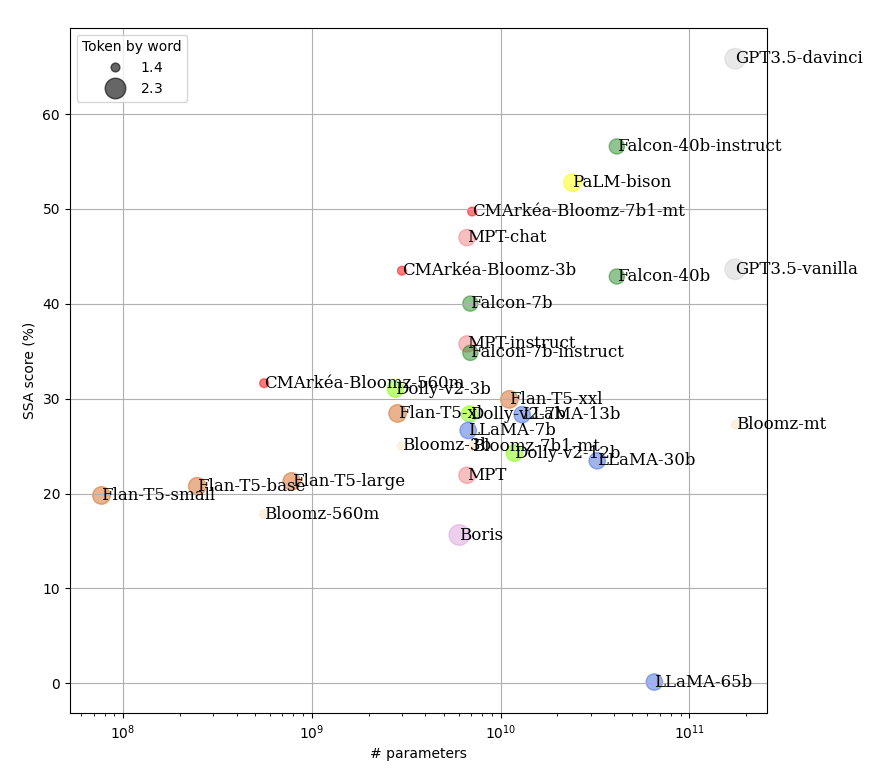 We observe that across all models, the performance gain is logarithmic in relation to the increase in model parameters. However, for models that undergo multiple pre-trainings (vanilla, instruction, and chat), models pre-trained on instruction and chat perform significantly better in zero-shot contexts, with a notable improvement for chat-based approaches. The models we have trained demonstrate promising efficiency in this test compared to the number of parameters, indicating cost-effectiveness in a production context.
We observe that across all models, the performance gain is logarithmic in relation to the increase in model parameters. However, for models that undergo multiple pre-trainings (vanilla, instruction, and chat), models pre-trained on instruction and chat perform significantly better in zero-shot contexts, with a notable improvement for chat-based approaches. The models we have trained demonstrate promising efficiency in this test compared to the number of parameters, indicating cost-effectiveness in a production context.
There are no specific instructions for using these models in a normal causal inference context. However, to leverage the chatbot capability of the model, an individual's prompt should be preceded by the EOS token (</s>), and the generated part should be preceded by the BOS token (<s>). The structure takes the following form:
</s>[human prompt 1]<s>[bot answer 1]</s>[human prompt 2]<s>
For example, to load the model using the HuggingFace pipeline interface:
from transformers import pipeline
model = pipeline("text-generation", "cmarkea/bloomz-3b-sft-chat")
result = model("</s>C'est quoi le deep learning ?<s>", max_new_tokens=512)
result
[{'generated_text': "</s>C'est quoi le deep learning ?<s>Le deep learning
est un sous-ensemble de l'intelligence artificielle qui utilise des
réseaux de neurones pour apprendre à partir de données."}]
@online{DeBloomzChat,
AUTHOR = {Cyrile Delestre},
URL = {https://huggingface.co/cmarkea/bloomz-3b-sft-chat},
YEAR = {2023},
KEYWORDS = {NLP ; Transformers ; LLM ; Bloomz},
}