
Model
GPT-2 Türkçe Modeli
Model Açıklaması
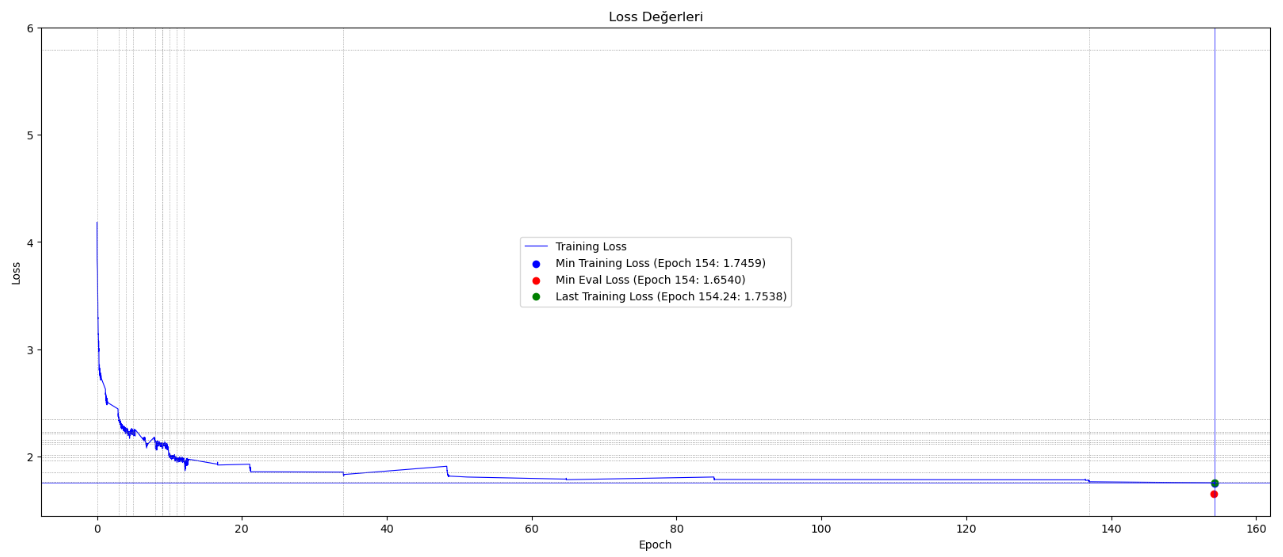
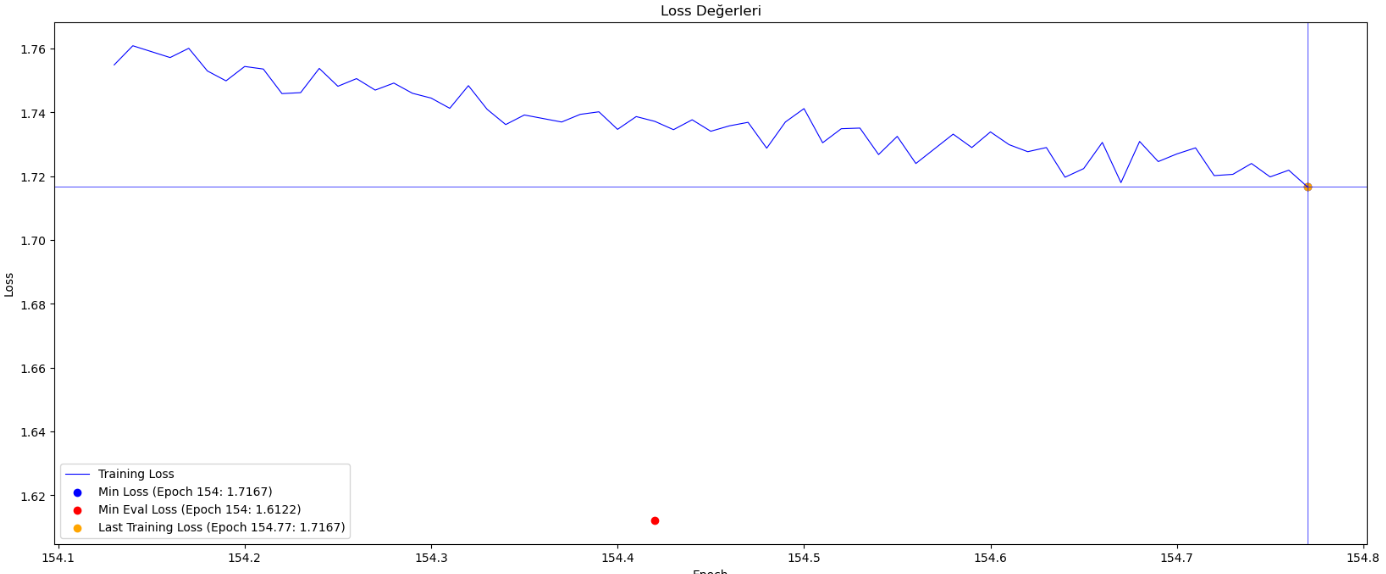
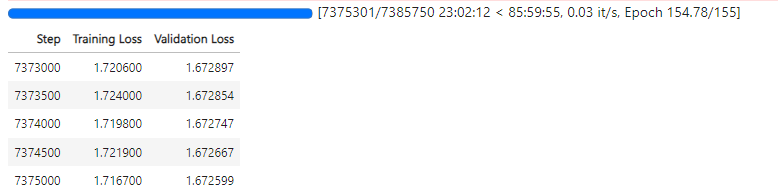
GPT-2 Türkçe Modeli, Türkçe diline özelleştirilmiş bir büyük veri modelidir ve LLM (Large Language Model) kategorisine aittir. Bu model, GPT-2 mimarisini temel alarak oluşturulmuş ve tokenizer yapısı özel olarak hazırlanmış bir Türkçe dil modelini temsil eder. Model, belirli bir başlangıç metni kullanarak insana benzer metinler üretebilme yeteneğine sahiptir ve geniş bir Türkçe metin veri kümesi üzerinde eğitilmiştir. Modelin eğitimi için 900 milyon karakterli Vikipedi seti kullanılmıştır. Eğitim setindeki cümleler maksimum 128 tokendan (token = kelime kökü ve ekleri) oluşmuştur bu yüzden oluşturacağı cümlelerin boyu sınırlıdır.. Türkçe heceleme yapısına uygun tokenizer kullanılmış ve model 7.5 milyon adımda yaklaşık 154 epoch eğitilmiştir. Eğitim için 4GB hafızası olan Nvidia Geforce RTX 3050 GPU kullanılmaktadır. 16GB Paylaşılan GPU'dan da yararlanılmakta ve eğitimin devamında toplamda 20GB hafıza kullanılmaktadır.
Model Nasıl Kullanılabilir
ÖNEMLİ: model harf büyüklüğüne duyarlı olduğu için, prompt tamamen küçük harflerle yazılmalıdır.
# Model ile çıkarım yapmak için örnek kod
from transformers import GPT2Tokenizer, GPT2LMHeadModel
model_name = "cenkersisman/gpt2-turkish-128-token"
tokenizer = GPT2Tokenizer.from_pretrained(model_name)
model = GPT2LMHeadModel.from_pretrained(model_name)
prompt = "okyanusun derinliklerinde bulunan"
input_ids = tokenizer.encode(prompt, return_tensors="pt")
output = model.generate(input_ids, max_length=100, pad_token_id=tokenizer.eos_token_id)
generated_text = tokenizer.decode(output[0], skip_special_tokens=True)
print(generated_text)
Eğitim Süreci Eğrisi
Sınırlamalar ve Önyargılar
Bu model, bir özyineli dil modeli olarak eğitildi. Bu, temel işlevinin bir metin dizisi alıp bir sonraki belirteci tahmin etmek olduğu anlamına gelir. Dil modelleri bunun dışında birçok görev için yaygın olarak kullanılsa da, bu çalışmayla ilgili birçok bilinmeyen bulunmaktadır.
Model, küfür, açık saçıklık ve aksi davranışlara yol açan metinleri içerdiği bilinen bir veri kümesi üzerinde eğitildi. Kullanım durumunuza bağlı olarak, bu model toplumsal olarak kabul edilemez metinler üretebilir.
Tüm dil modellerinde olduğu gibi, bu modelin belirli bir girişe nasıl yanıt vereceğini önceden tahmin etmek zordur ve uyarı olmaksızın saldırgan içerik ortaya çıkabilir. Sonuçları yayınlamadan önce hem istenmeyen içeriği sansürlemek hem de sonuçların kalitesini iyileştirmek için insanların çıktıları denetlemesini veya filtrelemesi önerilir.
- Downloads last month
- 1,010