
YAML Metadata
Warning:
empty or missing yaml metadata in repo card
(https://huggingface.co/docs/hub/model-cards#model-card-metadata)
Aggretriever is an encoder to aggregate both lexical and semantic text information into a single-vector dense vector for dense retrieval, which is finetued on MS MARCO corpus with BM25 negative sampling, following the approach described in Aggretriever: A Simple Approach to Aggregate Textual Representation for Robust Dense Passage Retrieval.
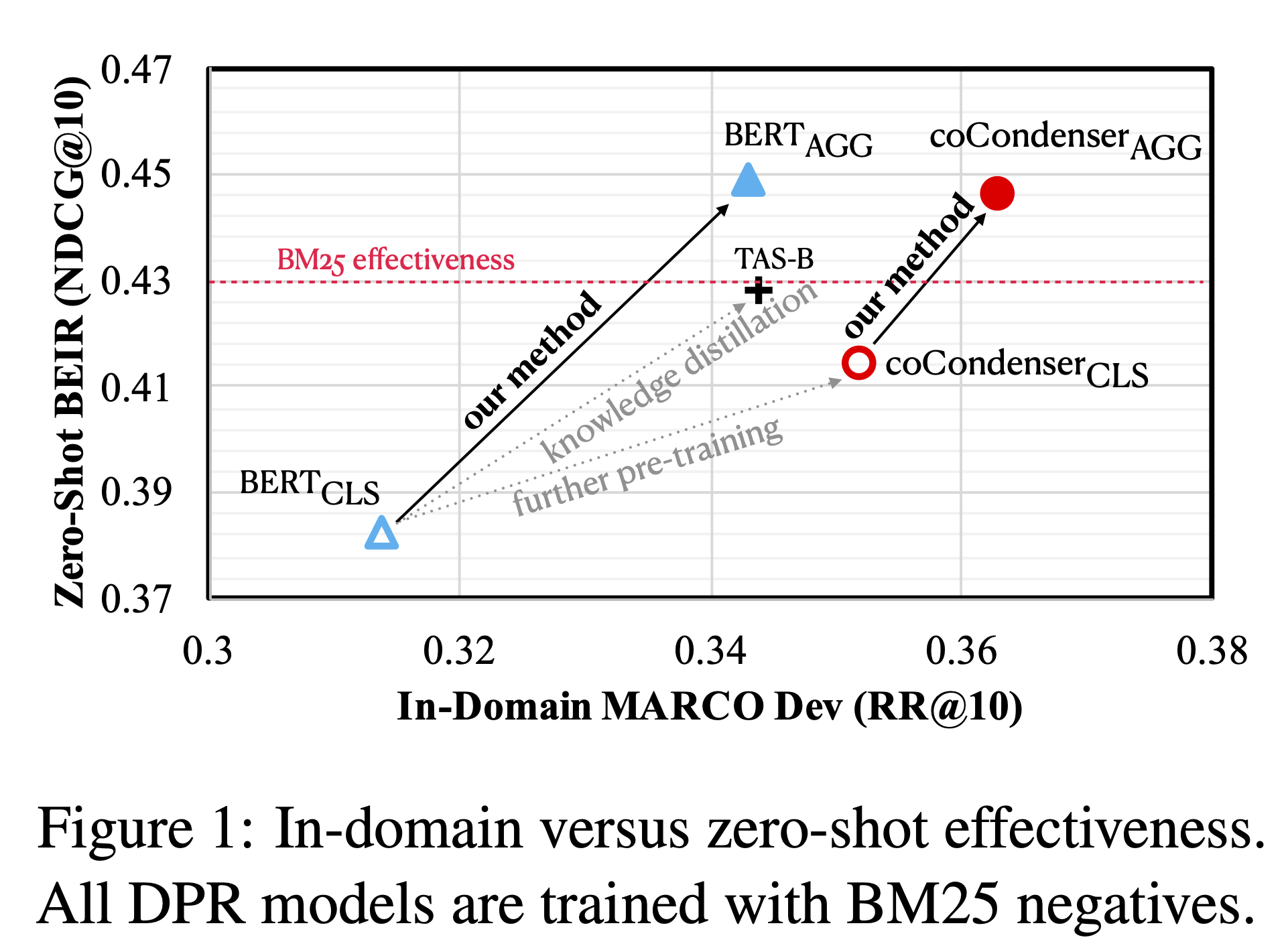
The associated GitHub repository for fine-tuning is available here and the reproduce from pyserini is [here]. The following variants are also available:
| Model | Initialization | MARCO Dev | Encoder Path |
|---|---|---|---|
| aggretriever-distilbert | distilbert-base-uncased | 34.1 | castorini/aggretriever-distilbert |
| aggretriever-cocondenser | Luyu/co-condenser-marco | 36.2 | castorini/aggretriever-cocondenser |
Usage (HuggingFace Transformers)
Using the model directly available in HuggingFace transformers. We use the implemented Aggretriever from pyserini here.
from pyserini.encode._aggretriever import AggretrieverQueryEncoder
from pyserini.encode._aggretriever import AggretrieverDocumentEncoder
model_name = '/store/scratch/s269lin/experiments/aggretriever/hf_model/aggretriever-cocondenser'
query_encoder = AggretrieverQueryEncoder(model_name, device='cpu')
context_encoder = AggretrieverDocumentEncoder(model_name, device='cpu')
query = ["Where was Marie Curie born?"]
contexts = [
"Maria Sklodowska, later known as Marie Curie, was born on November 7, 1867.",
"Born in Paris on 15 May 1859, Pierre Curie was the son of Eugène Curie, a doctor of French Catholic origin from Alsace."
]
# Compute embeddings: take the last-layer hidden state of the [CLS] token
query_emb = query_encoder.encode(query)
ctx_emb = context_encoder.encode(contexts)
# Compute similarity scores using dot product
score1 = query_emb @ ctx_emb[0] # 45.56658
score2 = query_emb @ ctx_emb[1] # 45.81762
- Downloads last month
- 109