
~ GenZ ~
Democratizing access to LLMs for the open-source community.
Let's advance AI, together.
Introduction 🎉
Welcome to GenZ, an advanced Large Language Model (LLM) fine-tuned on the foundation of Meta's open-source Llama V2 70B parameter model. At Bud Ecosystem, we believe in the power of open-source collaboration to drive the advancement of technology at an accelerated pace. Our vision is to democratize access to fine-tuned LLMs, and to that end, we will be releasing a series of models across different parameter counts (7B, 13B, and 70B) and quantizations (32-bit and 4-bit) for the open-source community to use, enhance, and build upon.
The smaller quantization version of our models makes them more accessible, enabling their use even on personal computers. This opens up a world of possibilities for developers, researchers, and enthusiasts to experiment with these models and contribute to the collective advancement of language model technology.
GenZ isn't just a powerful text generator—it's a sophisticated AI assistant, capable of understanding and responding to user prompts with high-quality responses. We've taken the robust capabilities of Llama V2 and fine-tuned them to offer a more user-focused experience. Whether you're seeking informative responses or engaging interactions, GenZ is designed to deliver.
And this isn't the end. It's just the beginning of a journey towards creating more advanced, more efficient, and more accessible language models. We invite you to join us on this exciting journey. 🚀
Milestone Releases ️🏁
[21 August 2023] GenZ-70B : We're excited to announce the release of our Genz 70BB model. Experience the advancements by downloading the model from HuggingFace.
[27 July 2023] GenZ-13B V2 (ggml) : Announcing our GenZ-13B v2 with ggml. This variant of GenZ can run inferencing using only CPU and without the need of GPU. Download the model from HuggingFace.
[27 July 2023] GenZ-13B V2 (4-bit) : Announcing our GenZ-13B v2 with 4-bit quantisation. Enabling inferencing with much lesser GPU memory than the 32-bit variant. Download the model from HuggingFace.
[26 July 2023] GenZ-13B V2 : We're excited to announce the release of our Genz 13B v2 model, a step forward with improved evaluation results compared to v1. Experience the advancements by downloading the model from HuggingFace.
[20 July 2023] GenZ-13B : We marked an important milestone with the release of the Genz 13B model. The journey began here, and you can partake in it by downloading the model from Hugging Face.
Evaluations 🎯
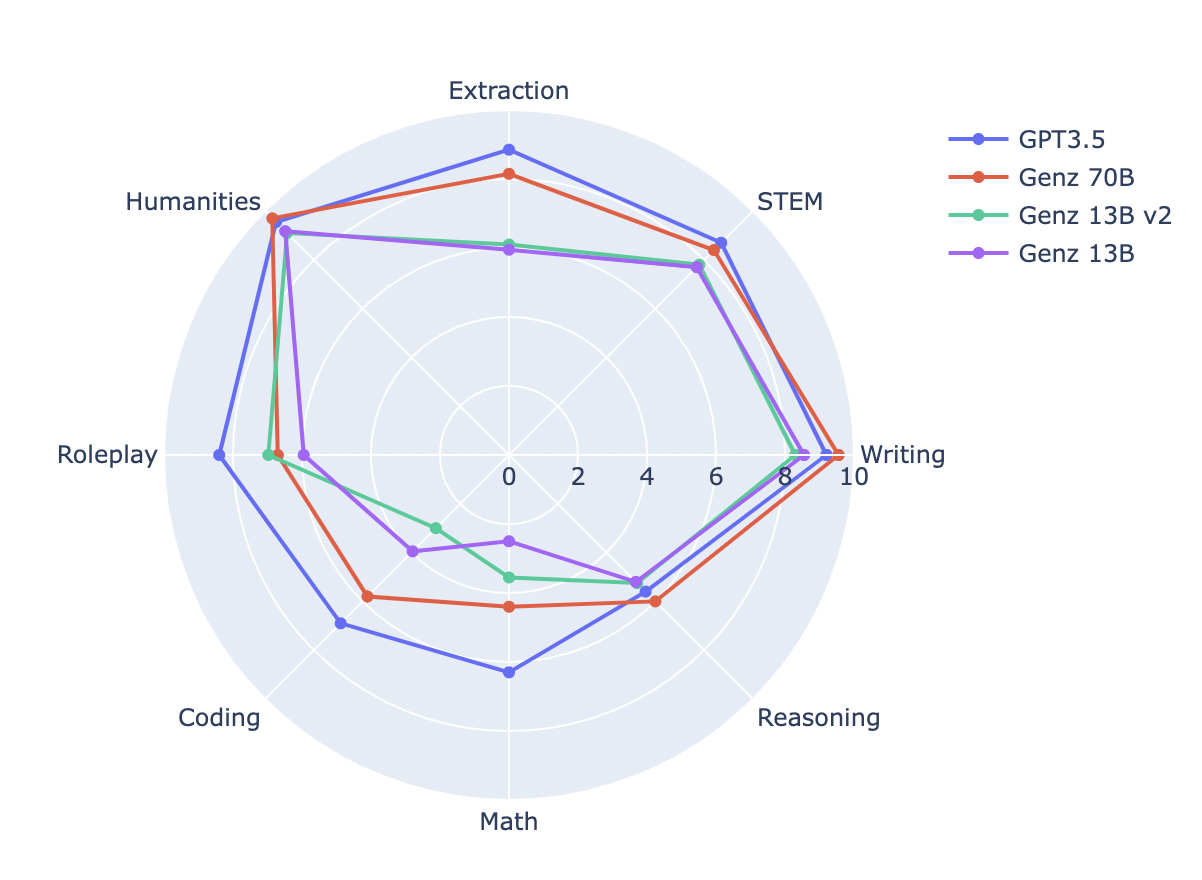
Evaluating our model is a key part of our fine-tuning process. It helps us understand how our model is performing and how it stacks up against other models. Here's a look at some of the key evaluations for GenZ 70B:
Benchmark Comparison
We've compared GenZ models to understand the improvements our fine-tuning has achieved.
| Model Name | MT Bench | MMLU | Human Eval | BBH |
|---|---|---|---|---|
| Genz 13B | 6.12 | 53.62 | 17.68 | 37.76 |
| Genz 13B v2 | 6.79 | 53.68 | 21.95 | 38.1 |
| Genz 70B | 7.33 | 70.32 | 37.8 | 54.69 |
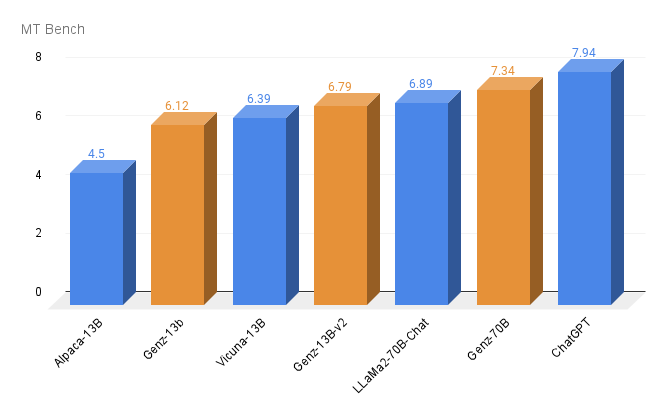
MT Bench Score
A key evaluation metric we use is the MT Bench score. This score provides a comprehensive assessment of our model's performance across a range of tasks.
Getting Started on Hugging Face 🤗
Getting up and running with our models on Hugging Face is a breeze. Follow these steps:
1️⃣ : Import necessary modules
Start by importing the necessary modules from the ‘transformers’ library and ‘torch’.
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("budecosystem/genz-70b", trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("budecosystem/genz-70b", torch_dtype=torch.bfloat16, rope_scaling={"type": "dynamic", "factor": 2})
prompt = "### User:\nWrite a python flask code for login management\n\n### Assistant:\n"
inputs = tokenizer(prompt, return_tensors="pt")
sample = model.generate(**inputs, max_length=128)
print(tokenizer.decode(sample[0]))
Want to interact with the model in a more intuitive way? We have a Gradio interface set up for that. Head over to our GitHub page, clone the repository, and run the ‘generate.py’ script to try it out. Happy experimenting! 😄
Why Use GenZ? 💡
You might be wondering, "Why should I choose GenZ over a pretrained model?" The answer lies in the extra mile we've gone to fine-tune our models.
While pretrained models are undeniably powerful, GenZ brings something extra to the table. We've fine-tuned it with curated datasets, which means it has additional skills and capabilities beyond what a pretrained model can offer. Whether you need it for a simple task or a complex project, GenZ is up for the challenge.
What's more, we are committed to continuously enhancing GenZ. We believe in the power of constant learning and improvement. That's why we'll be regularly fine-tuning our models with various curated datasets to make them even better. Our goal is to reach the state of the art and beyond - and we're committed to staying the course until we get there.
But don't just take our word for it. We've provided detailed evaluations and performance details in a later section, so you can see the difference for yourself.
Choose GenZ and join us on this journey. Together, we can push the boundaries of what's possible with large language models.
Model Card for GenZ 70B 📄
Here's a quick overview of everything you need to know about GenZ 70B.
Model Details:
- Developed by: Bud Ecosystem
- Base pretrained model type: Llama V2 70B
- Model Architecture: GenZ 70B, fine-tuned on Llama V2 70B, is an auto-regressive language model that employs an optimized transformer architecture. The fine-tuning process for GenZ 70B leveraged Supervised Fine-Tuning (SFT)
- License: The model is available for commercial use under a custom commercial license. For more information, please visit: Meta AI Model and Library Downloads
Intended Use 💼
When we created GenZ 70B, we had a clear vision of how it could be used to push the boundaries of what's possible with large language models. We also understand the importance of using such models responsibly. Here's a brief overview of the intended and out-of-scope uses for GenZ 70B.
Direct Use
GenZ 70B is designed to be a powerful tool for research on large language models. It's also an excellent foundation for further specialization and fine-tuning for specific use cases, such as:
- Text summarization
- Text generation
- Chatbot creation
- And much more!
Out-of-Scope Use 🚩
While GenZ 70B is versatile, there are certain uses that are out of scope:
- Production use without adequate assessment of risks and mitigation
- Any use cases which may be considered irresponsible or harmful
- Use in any manner that violates applicable laws or regulations, including trade compliance laws
- Use in any other way that is prohibited by the Acceptable Use Policy and Licensing Agreement for Llama 2
Remember, GenZ 70B, like any large language model, is trained on a large-scale corpora representative of the web, and therefore, may carry the stereotypes and biases commonly encountered online.
Recommendations 🧠
We recommend users of GenZ 70B to consider fine-tuning it for the specific set of tasks of interest. Appropriate precautions and guardrails should be taken for any production use. Using GenZ 70B responsibly is key to unlocking its full potential while maintaining a safe and respectful environment.
Training Details 📚
When fine-tuning GenZ 70B, we took a meticulous approach to ensure we were building on the solid base of the pretrained Llama V2 70B model in the most effective way. Here's a look at the key details of our training process:
Fine-Tuning Training Data
For the fine-tuning process, we used a carefully curated mix of datasets. These included data from OpenAssistant, an instruction fine-tuning dataset, and Thought Source for the Chain Of Thought (CoT) approach. This diverse mix of data sources helped us enhance the model's capabilities across a range of tasks.
Hyperparameters
Here are the hyperparameters we used for fine-tuning:
| Hyperparameter | Value |
|---|---|
| Warmup Ratio | 0.04 |
| Learning Rate Scheduler Type | Cosine |
| Learning Rate | 2e-5 |
| Number of Training Epochs | 3 |
| Per Device Training Batch Size | 4 |
| Gradient Accumulation Steps | 4 |
| Precision | FP16 |
| Optimizer | AdamW |
Looking Ahead 👀
We're excited about the journey ahead with GenZ. We're committed to continuously improving and enhancing our models, and we're excited to see what the open-source community will build with them. We believe in the power of collaboration, and we can't wait to see what we can achieve together.
Remember, we're just getting started. This is just the beginning of a journey that we believe will revolutionize the world of large language models. We invite you to join us on this exciting journey. Together, we can push the boundaries of what's possible with AI. 🚀
Check the GitHub for the code -> GenZ
- Downloads last month
- 2,616