更快的训练和推理: 对比 Habana Gaudi®2 和英伟达 A100 80GB



中文翻译: MatrixYao 校对: zhongdongy
通过本文,你将学习如何使用 Habana® Gaudi®2 加速模型训练和推理,以及如何使用 🤗 Optimum Habana 训练更大的模型。然后,我们展示了几个基准测例,包括 BERT 预训练、Stable Diffusion 推理以及 T5-3B 微调,以评估 Gaudi1、Gaudi2 和英伟达 A100 80GB 之间的性能差异。剧透一下: Gaudi2 的训练和推理速度大约是英伟达 A100 80GB 的两倍!
Gaudi2 是 Habana Labs 设计的第二代 AI 硬件加速卡。每台服务器装有 8 张加速卡,每张加速卡的内存为 96GB (Gaudi1 为 32GB,A100 80GB 为 80GB)。Habana 的 SynapseAI SDK 在 Gaudi1 和 Gaudi2 上是通用的。这意味🤗 Optimum Habana,一个将 🤗 Transformers 和 🤗 Diffusers 库与 SynapseAI 连起来的、用户友好的库, 在 Gaudi2 上的工作方式与 Gaudi1 完全相同!
因此,如果你在 Gaudi1 上已经有现成的训练或推理工作流,我们鼓励你在 Gaudi2 上尝试它们,因为无需任何更改它们即可工作。
如何访问 Gaudi2?
访问 Gaudi2 的简单且经济的方法之一就是通过英特尔和 Habana 提供的英特尔开发者云 (Intel Developer Cloud,IDC) 来访问。要使用 Gaudi2,你需要完成以下操作步骤:
- 进入 英特尔开发者云登陆页面 并登录你的帐户 (如果没有账户,需要先注册一个)。
- 进入 英特尔开发者云管理控制台。
- 选择 Habana Gaudi2 Deep Learning Server,其配有 8 张 Gaudi2 HL-225H 卡以及最新的英特尔® 至强® 处理器 ,然后单击右下角的 Launch Instance ,如下所示。
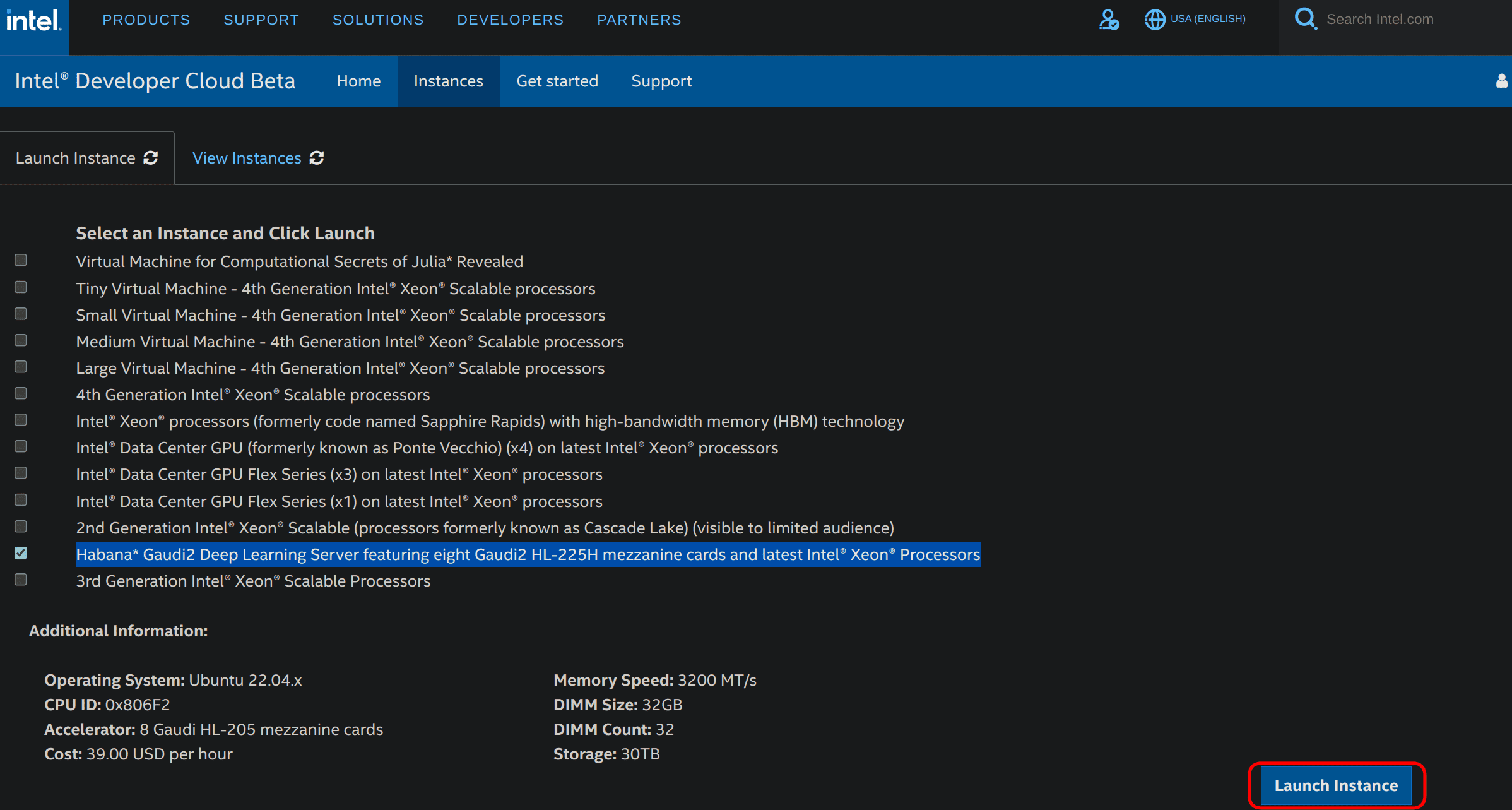
- 然后你可以申请一个实例。
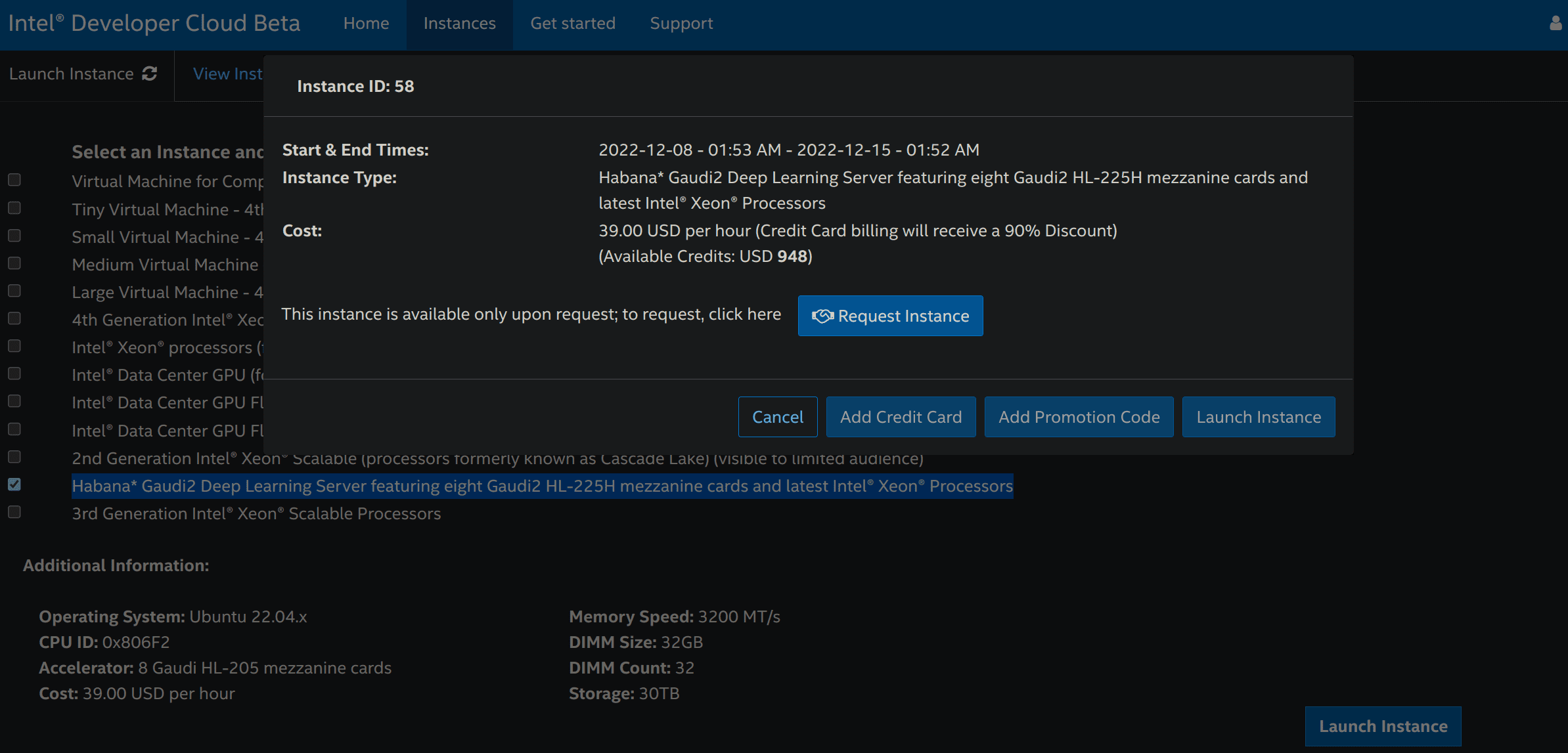
一旦申请成功,请重新执行步骤 3,然后单击 Add OpenSSH Publickey 以添加付款方式 (信用卡或促销码) 以及你的 SSH 公钥,你可使用
ssh-keygen -t rsa -b 4096 -f ~/.ssh/id_rsa命令以生成公钥。每次添加付款方式或 SSH 公钥时,你可能会被重定向到步骤 3。重新执行步骤 3,然后单击 Launch Instance 。你必须接受建议条款才能真正把实例启动起来。
进入 英特尔开发者云管理控制台,然后单击 View Instances 选项卡。
你可以复制实例界面上的 SSH 命令来远程访问你的 Gaudi2 实例!
如果你终止实例后想再次使用 Gaudi2,则必须重新执行整个过程。
你可以在 此处 找到更多相关信息。
基准测试
下面,我们将进行多项基准测试来评估 Gaudi1、Gaudi2 和 A100 80GB 在各种尺寸的模型上的训练和推理能力。
BERT 模型预训练
几个月前,Hugging Face 的技术主管 Philipp Schmid 介绍了 如何使用 🤗 Optimum Habana 在 Gaudi 上预训练 BERT。该预训练一共执行了 6.5 万步,每张卡的 batch size 为 32 (因此总 batch size 为 8 * 32 = 256),总训练时长为 8 小时 53 分钟 (你可以在 此处 查看此次训练的 TensorBoard 日志)。
我们在 Gaudi2 上使用相同的超参重新运行相同的脚本,总训练时间为 2 小时 55 分钟 (日志见 此处)。 也就是说,无需任何更改,Gaudi2 的速度提升了 3.04 倍。
由于与 Gaudi1 相比,Gaudi2 的单卡内存大约增加了 3 倍,因此我们可以充分利用这更大的内存容量来增大 batch size。这将会进一步增加 HPU 的计算密度,并允许开发人员尝试那些在 Gaudi1 上无法尝试的超参。在 Gaudi2 上,我们仅需 2 万训练步,每张卡的 batch size 为 64 (总 batch size 为 512),就可以获得与之前运行的 6.5 万步相似的收敛损失,这使得总训练时长降低为 1 小时 33 分钟 (日志见 此处)。使用新的配置,训练吞吐量提高了 1.16 倍,同时新的 batch size 还极大地加速了收敛。 总体而言,与 Gaudi1 相比,Gaudi2 的总训练时长减少了 5.75 倍,吞吐量提高了 3.53 倍。
Gaudi2 比 A100 更快: batch size 为 32 时,Gaudi2 吞吐为每秒 1580.2 个样本,而 A100 为 981.6; batch size 为 64 时,Gaudi2 吞吐为每秒 1835.8 个样本,而 A100 为 1082.6。这与 Habana 宣称的 batch size 为 64 时 Gaudi2 在 BERT 预训练第一阶段上的训练性能是 A100 的 1.8 倍 相一致。
下表展示了我们在 Gaudi1、Gaudi2 和英伟达 A100 80GB GPU 上测得的吞吐量:
| Gaudi1 (BS=32) | Gaudi2 (BS=32) | Gaudi2 (BS=64) | A100 (BS=32) | A100 (BS=64) | |
|---|---|---|---|---|---|
| 吞吐量 (每秒样本数) | 520.2 | 1580.2 | 1835.8 | 981.6 | 1082.6 |
| 加速比 | x1.0 | x3.04 | x3.53 | x1.89 | x2.08 |
BS 是每张卡上的 batch size。 Gaudi 训练时使用了混合精度 (bf16/fp32),而 A100 训练时使用了 fp16。所有数据都基于 8 卡分布式训练方案测得。
使用 Stable Diffusion 进行文生图
🤗 Optimum Habana 1.3 的主要新特性之一是增加了 对 Stable Diffusion 的支持。现在,在 Gaudi 上进行文生图非常容易。与 GPU 上的 🤗 Diffusers 不同,Optimum Habana 上的图像是批量生成的。由于模型编译耗时的原因,前两个 batch 比后面的 batch 的生成速度要慢。在此基准测试中,在计算 Gaudi1 和 Gaudi2 的吞吐量时,我们丢弃了前两个 batch 的生成时间。
这个脚本 使用的 batch size 为 8,其 gaudi_config 为 Habana/stable-diffusion。
我们得到的结果与 Habana 发布的 数字 一致,如下表所示。 Gaudi2 的延迟比 Gaudi1 快 3.51 倍 (0.925 秒对比 3.25 秒),比英伟达 A100 快 2.84 倍 (0.925 秒对比 2.63 秒)。 而且,Gaudi2 支持的 batch size 更大。
| Gaudi1 (BS=8) | Gaudi2 (BS=8) | A100 (BS=1) | |
|---|---|---|---|
| 延迟 (每图像秒数) | 3.25 | 0.925 | 2.63 |
| 加速比 | x1.0 | x3.51 | x1.24 |
更新: 上图已更新,因为 SynapseAI 1.10 和 Optimum Habana 1.6 为 Gaudi1 和 Gaudi2 带来了额外的加速。
BS 是 batch size。Gaudi 上的推理精度为 bfloat16 ,A100 上的推理精度为 fp16 (更多信息详见 此处)。所有数据均为 单卡 运行数据。
微调 T5-3B
因为每张卡的内存高达 96 GB,Gaudi2 可以运行更大的模型。举个例子,在仅应用了梯度 checkpointing 内存优化技术的条件下,我们成功微调了一个 T5-3B (参数量为 30 亿) 模型。这在 Gaudi1 上是不可能实现的。我们使用 这个脚本 在 CNN DailyMail 数据集上针对文本摘要任务进行了微调,运行日志见 这里。
结果如下表所示。 Gaudi2 比 A100 80GB 快 2.44 倍。 我们发现,目前在 Gaudi2 上的 batch size 只能为 1,不能设更大。这是由于在第一次迭代时生成的计算图占了不少内存空间。Habana 正在致力于优化 SynapseAI 的内存占用,我们期待未来新版本的 Habana SDK 能够缓解这一问题。同时,我们还期待使用 DeepSpeed 来扩展此基准,从而看看引入 DeepSpeed 后平台间的性能对比是否与现在保持一致。
| Gaudi1 | Gaudi2 (BS=1) | A100 (BS=16) | |
|---|---|---|---|
| 吞吐量 (每秒样本数) | N/A | 19.7 | 8.07 |
| 加速比 | / | x2.44 | x1.0 |
BS 指的是每卡 batch size。 Gaudi2 和 A100 使用的精度为 fp32,且启用了梯度 checkpointing 技术。所有数据都基于 8 卡分布式训练方案测得。
总结
本文讨论了我们首次使用 Gaudi2 的经历。从 Gaudi1 到 Gaudi2 的过渡完全是无缝的,因为 Habana 的 SDK SynapseAI 在两者上是完全兼容的。这意味着 SynapseAI 上的新优化会让两个平台同时受益。
可以看到,Habana Gaudi2 的性能与 Gaudi1 相比有了显著提高,且其训练和推理吞吐大约是英伟达 A100 80GB 的两倍。
我们还知道了如何在英特尔开发者云上设置 Gaudi2 实例。设置完后,你就可以 Gaudi2 上使用 🤗 Optimum Habana 轻松运行这些 例子。
如果你对使用最新的 AI 硬件加速卡和软件库加速机器学习训练和推理工作流感兴趣,可以移步我们的 专家加速计划。如果你想了解有关 Habana 解决方案的更多信息,可以在 此处 了解我们相关信息并 联系他们。要详细了解 Hugging Face 为让 AI 硬件加速卡更易于使用而做的努力,请查阅我们的 硬件合作伙伴计划。

