Handwritten Signature Detection Model

Abstract
This article presents an open-source project for automated signature detection in document processing, structured into four key phases:
- Dataset Engineering: Curation of a hybrid dataset through aggregation of two public collections.
- Architecture Benchmarking: Systematic evaluation of state-of-the-art object detection architectures (YOLO series, DETR variants, and YOLOS), focusing on accuracy, computational efficiency, and deployment constraints.
- Model Optimization: Leveraged Optuna for hyperparameter tuning, yielding a 7.94% F1-score improvement over baseline configurations.
- Production Deployment: Utilized Triton Inference Server for OpenVINO CPU-optimized inference.
Experimental results demonstrate a robust balance between precision, recall, and inference speed, validating the solution's practicality for real-world applications.
The full pipeline, including code, models, and data, is publicly available on HuggingFace Hub and GitHub to foster reproducibility and community adaptation.



| Resource | Links / Badges | Details |
|---|---|---|
| Model Files |

|
Different formats of the final models |
| Dataset – Original |
|
2,819 document images annotated with signature coordinates |
| Dataset – Processed |

|
Augmented and pre-processed version (640px) for model training |
| Notebooks – Model Experiments |
|
Complete training and evaluation pipeline with selection among different architectures (yolo, detr, rt-detr, conditional-detr, yolos) |
| Notebooks – HP Tuning |
|
Optuna trials for optimizing the precision/recall balance |
| Inference Server |
|
Complete deployment and inference pipeline with Triton Inference Server |
| Live Demo |

|
Graphical interface with real-time inference |
1. Introduction
The application of automation in document processing has received much attention in both industry and academia. In this context, handwritten signature detection presents certain challenges, including orientation, lighting, noise, document layout, cursive letters in the document content, signatures in varying positions, among others. This paper describes the end-to-end development of a model for this task, including architecture selection, dataset creation, hyperparameter optimization, and production deployment.
2. Methodology
2.1 Object Detection Architectures
Object detection in computer vision has improved significantly, balancing speed and precision for use cases such as autonomous driving and surveillance applications.
The field has evolved rapidly, with architectures generally falling into certain paradigms:
- CNN-based Two-Stage Detectors: Models from the R-CNN family first identify potential object regions before classifying them
- CNN-based One-Stage Detectors: YOLO family and SSD models that predict bounding boxes and classes in one pass
- Transformer-based Detectors: DETR-based models applying attention mechanisms for end-to-end detection
- Hybrid Architectures: Systems that combine CNN efficiency with Transformer contextual understanding
- Zero-shot Detectors: Capable of recognizing unfamiliar object classes without specific training
| Model | Architecture/Design | Latency | Applications | Precision (mAP) – Size Variants | Training Frameworks | License | Parameters (M) |
|---|---|---|---|---|---|---|---|
| YOLOv8 | CNN (One-Stage), Yolov5 adapt -> C2f Block, SSPF and decoupled head | Very Low (1.47-14.37) [T4 GPU, TensorRT FP16] | Real-time detection, tracking | 37.4–53.9 [n-x] (COCO) | PyTorch, Ultralytics, KerasCV, TensorFlow | AGPL-3.0 | 3.2–68.2 |
| YOLOv9 | CNN, GELAN (Generalized Efficient Layer Aggregation Network), Programmable Gradient Information (PGI), CSP-ELAN blocks | Low (2.3-16.77) [T4 GPU, TensorRT FP16] | Real-time detection | 38.3–55.6 [t-e] (COCO) | PyTorch, Ultralytics | AGPL-3.0 | 4.5–71.0 |
| YOLOv10 | CNN, Consistent Dual Assignments, Holistic Efficiency-Accuracy Design (Lightweight Head, Decoupled Downsampling, Rank-guided Blocks, Large-kernel Conv, Partial Self-Attention) | Very Low (1.84–10.79 ms) [T4 GPU, TensorRT FP16] | Real-time detection | 38.5–54.4 [n-x] (COCO) | PyTorch, Ultralytics | AGPL-3.0 | 2.3–29.5 |
| YOLO11 | CNN + Attention, PSA, Dual Label Assignment, C3K2 block | Very Low (1.5-11.3) [T4 GPU, TensorRT FP16] | Real-time detection | 43.5–58.5 [n-x] (COCO) | PyTorch, Ultralytics | AGPL-3.0 | 5.9–89.7 |
| RTMDet | CNN (One-Stage), CSPDarkNet, CSP-PAFPN neck, soft label dynamic assignment | Low (2.34–18.8 ms) [T4 GPU, TensorRT FP16] | Real-time detection | 41.1–52.8 [tiny-x] (COCO) | PyTorch, MMDetection | Apache-2.0 | 4.8–94.9 |
| DETR | Transformer (Encoder-Decoder), CNN Backbone (ResNet), Bipartite Matching Loss, Set-based Prediction | Moderate (12–28 ms) [T4 GPU, TensorRT FP16] | Object detection | 42.0–44.0 [R50-R101] (COCO) | PyTorch, Hugging Face, PaddlePaddle | Apache-2.0 | 41–60 |
| RT-DETR | Transformer (Encoder-Decoder), Efficient Hybrid Encoder, Uncertainty-Minimal Query Selection, CNN Backbone (ResNet) | Very Low 9.3–13.5 ms (108–74 FPS) [T4 GPU, TensorRT FP16] | Real-time detection | 53.1–56.2 AP [R50-R101] (COCO) | PyTorch, Hugging Face, PaddlePaddle, Ultralytics | Apache-2.0 | 20.0–67.0 |
| DETA | Transformer (Two-Stage), CNN Backbone, IoU-based Label Assignment, NMS for Post-Processing | Moderate ~100 ms [V100 GPU] | High-precision detection | 50.1-62.9 (COCO) | PyTorch, Detectron2, Hugging Face | Apache-2.0 | 48–52 |
| GroundingDINO | Transformer-based (DINO + grounded pre-training), dual-encoder-single-decoder, Swin-T/Swin-L image backbone, BERT text backbone, feature enhancer, language-guided query selection, cross-modality decoder | ~119 ms (8.37 FPS on T4 GPU)* | Open-set detection | 52.5 AP (COCO zero-shot), 62.6–63.0 AP (COCO fine-tuned) [Swin-T (172M) / Swin-L (341M)] (COCO) | PyTorch, Hugging Face | Apache-2.0 | 172–341 |
| YOLOS | Vision Transformer (ViT) with detection tokens, encoder-only, bipartite matching loss, minimal 2D inductive biases | Moderate (11.9–370.4 ms) [1080Ti GPU] | Object detection | 28.7–42.0 [Tiny-Base] (COCO) | PyTorch, Hugging Face | Apache-2.0 | 6.5–127 |
Check this leaderboard for the latest updates on object detection models: Object Detection Leaderboard.
Background and Evolution
Object detection has evolved from the conventional CNN-based models like Faster R-CNN and SSD to more recent transformer-based models like DETR, released in 2020 by Facebook AI. This is targeted at enhancing accuracy through the application of transformer models, which possess a superior capacity for handling global context. Recent models like RT-DETR and YOLOv11 continue to refine this balance, focusing on real-time performance and precision.
YOLO Series
You Only Look Once (YOLO) was introduced in 2016 by Joseph Redmon, Santosh Divvala, Ross Girshick, and Ali Farhadi, revolutionizing object detection by proposing a single-stage detector. While two-stage approaches first create region proposals and then classify and classify them, YOLO predicts bounding boxes and object classes in a single pass of the network. This design makes YOLO very fast and ideal for edge devices and real-time computing tasks like security surveillance, traffic monitoring, and industrial inspection.

Source: What is YOLO? The Ultimate Guide [2025]
Year after year, the YOLO family has been improved over and over again. Each version had new methods and advancements to compensate for the others' weaknesses:
- YOLOv1: First to remove region proposals by scanning the entire image in one forward pass, grabbing both global and local context at once.
- YOLOv2 and YOLOv3: Brought forth major advancements like Feature Pyramid Networks (FPN), multi-scale training, and the application of anchor boxes, improving the model's capability to detect objects of different sizes.
- YOLOv4: Marked a major architectural upgrade by adopting a CSPDarknet53-PANet-SPP backbone and integrating novel techniques like a bag of specials, a bag of freebies, genetic algorithms, and attention modules to improve both accuracy and speed.
- YOLOv5: While architecturally similar to YOLOv4, its implementation in PyTorch and the streamlined training process within the Ultralytics framework contributed to its widespread adoption.
- YOLO-R, YOLO-X, YOLOv6, and YOLOv7: These versions explored multitask learning (YOLO-R), anchor-free detection, decoupled heads, reparameterization, knowledge distillation, and quantization—allowing improved scaling and optimization of the models.
- YOLOv8 and YOLO-NAS: YOLOv8 builds upon YOLOv5 with minor changes, such as replacing the CSPLayer with the C2f module, and incorporates optimized loss functions for small object detection. YOLO-NAS stands out as a model generated through neural architecture search (NAS), employing quantization-aware blocks to achieve an optimal balance between speed and accuracy.
One of the challenges with the YOLO architecture is the large number of different versions, as the name can be used freely, and not all recent versions necessarily bring significant improvements. Indeed, when a new model is released under the YOLO name, it often shows superior metric results, but the differences tend to be minimal.

Moreover, a model achieving superior metrics on a general evaluation dataset, such as COCO, does not necessarily mean it will perform better in your specific use case. There are also differences in model size, inference and training time, library and hardware compatibility, and differences in the characteristics and quality of your data.

Source: Ultralytics YOLO11
The family is distinguished by its unified and optimized design, making it deployable on low-resource devices and real-time applications. The diversity of YOLO versions presents challenges in choosing the ideal model for a specific use case.
DETR
The DEtection TRansformer (DETR) introduces an innovative approach by combining convolutional neural networks with transformer architecture, eliminating traditional and complex post-processing steps used in other methods, such as Non-Maximum Suppression (NMS).

Source: End-to-End Object Detection with Transformers
The DETR architecture can be divided into four main components:
Backbone (e.g., ResNet):
- Function: Extract a feature map rich in semantic and spatial information from the input image.
- Output: A set of two-dimensional vectors (feature map) that serves as input for the transformer module.
Transformer Encoder-Decoder:
- Encoder:
- Function: Process the feature map from the backbone by applying multi-head self-attention and feed-forward layers, capturing global and contextual relationships between different regions of the image.
- Decoder:
- Function: Use a fixed set of object queries (embeddings representing candidate objects) to iteratively refine bounding box and class label predictions.
- Output: A final set of predictions, where each query corresponds to a bounding box and its respective class.
- Encoder:
Feed-Forward Network (FFN):
- Function: For each query processed by the decoder, the FFN generates the final predictions, including normalized box coordinates (x, y, width, and height) and classification scores (including a special class for "no object").
Joint Reasoning:
- Feature: DETR processes all objects simultaneously, leveraging pairwise relationships between predictions to handle ambiguities such as object overlap, eliminating the need for post-processing techniques like NMS.
The original DETR faced challenges such as slow convergence and suboptimal performance on small object detection. To address these limitations, improved variants have emerged:
-
- Deformable Attention: Focuses attention on a fixed number of sampling points near each reference, improving efficiency and enabling the detection of fine details in high-resolution images.
- Multiscale Module: Incorporates feature maps from different backbone layers, enhancing the model's ability to detect objects of varying sizes.
 Figure 5: Deformable DETR mitigates the slow convergence issues and limited feature spatial resolution of the original DETR.
Figure 5: Deformable DETR mitigates the slow convergence issues and limited feature spatial resolution of the original DETR.
Source: Deformable DETR: Deformable Transformers for End-to-End Object Detection -
- Convergence Improvement: Introduces conditional cross-attention in the decoder, making the object queries more specific to the input image and accelerating training (with reported convergence up to 6.7 times faster).
 Figure 6: Conditional DETR shows faster convergence.
Figure 6: Conditional DETR shows faster convergence.
Source: Conditional DETR for Fast Training Convergence
Thus, DETR and its variants represent a paradigm shift in object detection, harnessing the power of transformers to capture global and contextual relationships in an end-to-end manner while simplifying the detection pipeline by removing manual post-processing steps.
RT-DETR
RT-DETR (Real-Time DEtection TRansformer) is a transformer-based model designed for real-time object detection, extending the foundational DETR architecture with optimizations for speed and efficiency.

Source: DETRs Beat YOLOs on Real-time Object Detection
Hybrid Encoder:
- RT-DETR employs a hybrid encoder that integrates intra-scale interaction and cross-scale fusion. This design enables the model to efficiently process features at different scales, capturing both local details and global relationships.
- This is particularly advantageous for detecting objects of varying sizes in complex scenes, a challenge for earlier transformer models.
Elimination of NMS:
- Like DETR, RT-DETR eliminates the need for Non-Maximum Suppression (NMS) by predicting all objects simultaneously. This end-to-end approach simplifies the detection pipeline and reduces post-processing overhead.
Real-time Optimization:
- RT-DETR achieves medium latency (10–200 ms), making it suitable for real-time applications such as autonomous driving and video surveillance, while maintaining competitive accuracy.
RT-DETR approximates high-speed CNN-based models like YOLO and accuracy-focused transformer models.
YOLOS
YOLOS (You Only Look at One Sequence) introduces a novel transformer-based approach to object detection, drawing inspiration from the Vision Transformer (ViT). Unlike traditional CNN-based models, YOLOS reimagines object detection by treating images as sequences of patches, leveraging the transformer’s sequence-processing strengths.
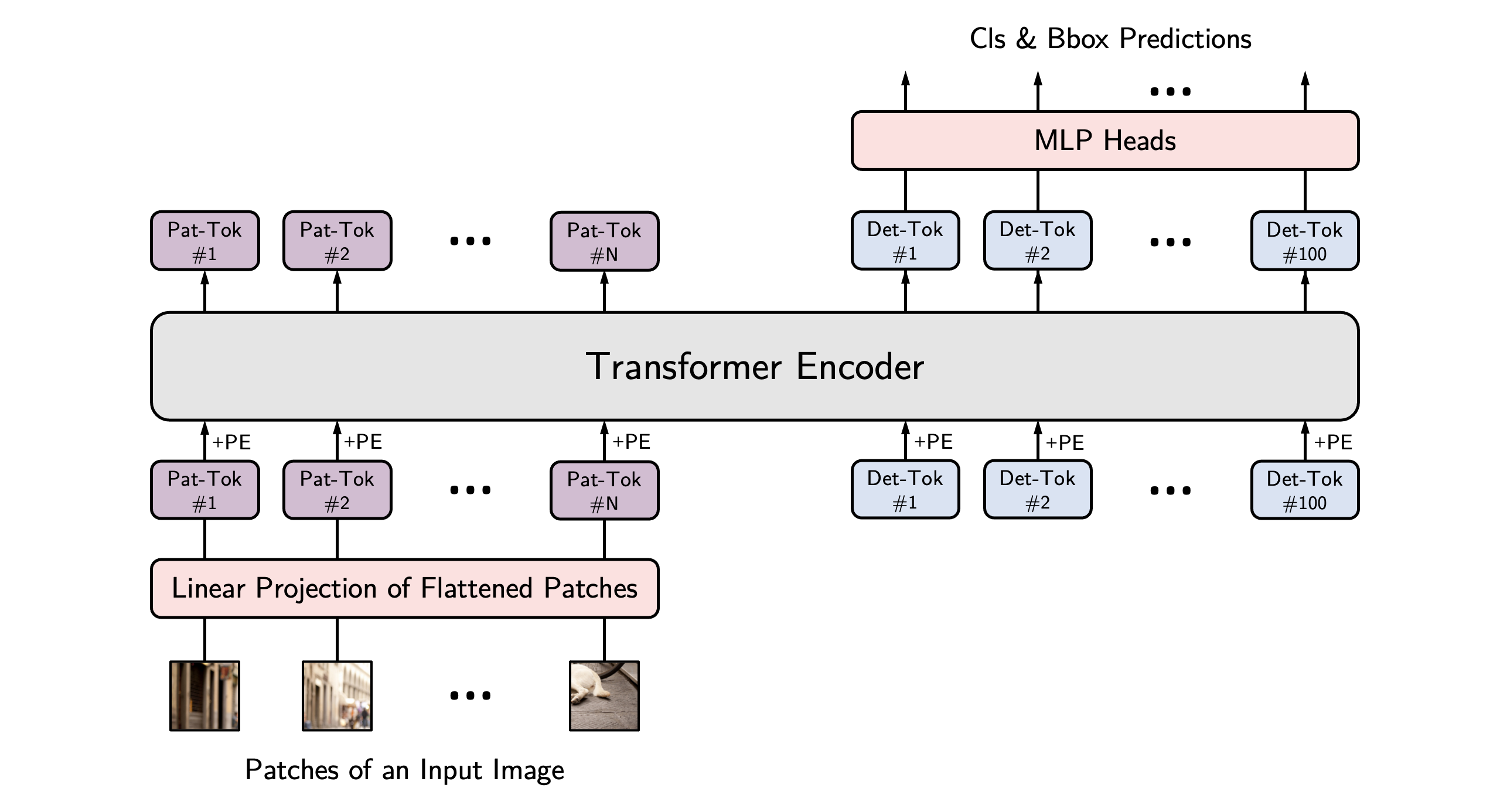
Source: You Only Look at One Sequence: Rethinking Transformer in Vision through Object Detection
Vision Transformer (ViT) Backbone:
- YOLOS uses a ViT backbone, which splits the input image into fixed-size patches (e.g., 16x16 pixels). Each patch is treated as a token, allowing the transformer to process the image as a sequence and capture long-range dependencies.
Patch-based Processing:
- By converting the image into a sequence of patches, YOLOS efficiently handles high-resolution inputs and detects objects across different scales, making it adaptable to diverse detection tasks.
Object Queries:
- Similar to DETR, YOLOS employs object queries to predict bounding boxes and class labels directly. This eliminates the need for anchor boxes or NMS, aligning with the end-to-end philosophy of transformer-based detection.
Efficiency Variants:
- YOLOS offers variants such as yolos-tiny, -small, and -base, allowing to balance computational cost and performance based on application needs.

Source: You Only Look at One Sequence: Rethinking Transformer in Vision through Object Detection
I think this figure is very cool. It illustrates the specialization of [DET] tokens to focus on specific sizes of objects and distinct regions of the image. This adaptive behavior highlights the effectiveness in object detection tasks, allowing the model to dynamically allocate its detection capabilities based on the spatial and scale characteristics of the objects.
2.2. Dataset Composition and Preprocessing
The dataset was constructed by merging two publicly available benchmarks:
- Tobacco800: A subset of the Complex Document Image Processing (CDIP) Test Collection, comprising scanned documents from the tobacco industry. Ground truth annotations include signatures and corporate logos.
- Signatures-XC8UP: Part of the Roboflow 100 benchmark, containing 368 annotated images of handwritten signatures.
Roboflow
The Roboflow platform was employed for dataset management, preprocessing, and annotation. Key workflow components included:
Dataset Partitioning:
- Training: 1,980 images (70%)
- Validation: 420 images (15%)
- Testing: 419 images (15%)
Preprocessing Pipeline:
- Auto-orientation and bilinear resampling to 640×640 pixels
Spatial-Augmentation Strategy:
- Rotation (90° fixed and ±10° random)
- Shear transformations (±4° horizontal, ±3° vertical)
- Photometric adjustments (±20% brightness/exposure variation)
- Stochastic blur (σ=1.5) and Gaussian noise (σ=0.05)
These techniques enhance model generalization across diverse document acquisition scenarios.
Dataset Availability:
- Roboflow Universe:

- Hugging Face Datasets Hub:

2.3. Training Process and Model Selection
Various models were evaluated using experiments conducted over 35 training epochs with consistent batch size and learning rate settings, based on the available computational capacity. The table below summarizes the results obtained for metrics such as CPU inference time, mAP@50, mAP@50-95, and total training time:
| Metric | rtdetr-l | yolos-base | yolos-tiny | conditional-detr-resnet-50 | detr-resnet-50 | yolov8x | yolov8l | yolov8m | yolov8s | yolov8n | yolo11x | yolo11l | yolo11m | yolo11s | yolo11n | yolov10x | yolov10l | yolov10b | yolov10m | yolov10s | yolov10n |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Inference Time (CPU - ms) | 583.608 | 1706.49 | 265.346 | 476.831 | 425.649 | 1259.47 | 871.329 | 401.183 | 216.6 | 110.442 | 1016.68 | 518.147 | 381.652 | 179.792 | 106.656 | 821.183 | 580.767 | 473.109 | 320.12 | 150.076 | 73.8596 |
| mAP@50 | 0.92709 | 0.901154 | 0.869814 | 0.936524 | 0.88885 | 0.794237 | 0.800312 | 0.875322 | 0.874721 | 0.816089 | 0.667074 | 0.707409 | 0.809557 | 0.835605 | 0.813799 | 0.681023 | 0.726802 | 0.789835 | 0.787688 | 0.663877 | 0.734332 |
| mAP@50-95 | 0.622364 | 0.583569 | 0.469064 | 0.653321 | 0.579428 | 0.552919 | 0.593976 | 0.665495 | 0.65457 | 0.623963 | 0.482289 | 0.499126 | 0.600797 | 0.638849 | 0.617496 | 0.474535 | 0.522654 | 0.578874 | 0.581259 | 0.473857 | 0.552704 |
| Training Time | 55m 33s | 7h 53m | 1h 42m | 2h 45m | 2h 31m | 1h 30m | 1h | 44m 7s | 29m 1s | 22m 51s | 1h 28m | 55m 30s | 48m 2s | 30m 37s | 27m 33s | 1h 36m | 1h 8m | 1h 1m | 51m 38s | 34m 17s | 29m 2s |

Highlights:
- Best mAP@50:
conditional-detr-resnet-50(93.65%) - Best mAP@50-95:
yolov8m(66.55%) - Lowest Inference Time:
yolov10n(73.86 ms)
The complete experiments are available on Weights & Biases.
Our findings reveal a different behavior from general benchmarks, where larger model versions typically yield incremental improvements. In this experiment, smaller models such as YOLOv8n and YOLOv11s achieved satisfactory and comparable results to their larger counterparts.
Furthermore, purely convolutional architectures demonstrated faster inference and training times compared to transformer-based models while maintaining similar levels of accuracy.
2.4. Hyperparameter Optimization
Due to its strong initial performance and ease of export, the YOLOv8s model was selected for hyperparameter fine-tuning using Optuna. A total of 20 trials were conducted, with the test set F1-score serving as the objective function. The hyperparameter search space included:
dropout = trial.suggest_float("dropout", 0.0, 0.5, step=0.1)
lr0 = trial.suggest_float("lr0", 1e-5, 1e-1, log=True)
box = trial.suggest_float("box", 3.0, 7.0, step=1.0)
cls = trial.suggest_float("cls", 0.5, 1.5, step=0.2)
opt = trial.suggest_categorical("optimizer", ["AdamW", "RMSProp"])
The results of this hypertuning experiment can be viewed here: Hypertuning Experiment.
The figure below illustrates the correlation between the hyperparameters and the achieved F1-score:

After tuning, the best trial (#10) exhibited the following improvements compared to the base model:
| Metric | Base Model | Best Trial (#10) | Difference |
|---|---|---|---|
| mAP@50 | 87.47% | 95.75% | +8.28% |
| mAP@50-95 | 65.46% | 66.26% | +0.81% |
| Precision | 97.23% | 95.61% | -1.63% |
| Recall | 76.16% | 91.21% | +15.05% |
| F1-score | 85.42% | 93.36% | +7.94% |
3. Evaluation and Results
The final evaluation of the model was conducted using ONNX format (for CPU inference) and TensorRT (for GPU – T4 inference). The key metrics obtained were:
- Precision: 94.74%
- Recall: 89.72%
- mAP@50: 94.50%
- mAP@50-95: 67.35%
Regarding inference times:
- ONNX Runtime (CPU): 171.56 ms
- TensorRT (GPU – T4): 7.657 ms
Figure 13 presents a graphical comparison of the evaluated metrics:

The Base Model – Phase 1 (☆) represents the model obtained during the selection phase of training.
4. Deployment and Publication
In this section, we describe the deployment process of the handwritten signature detection model using the Triton Inference Server and the publication of both the model and dataset on the Hugging Face Hub. The objective was to create an efficient, cost-effective, and secure solution for making the model available in a production environment, while also providing public access to the work in accordance with open science principles.
4.1. Inference Server
The Triton Inference Server was chosen as the deployment platform due to its flexibility, efficiency, and support for multiple machine learning frameworks, including PyTorch, TensorFlow, ONNX, and TensorRT. It supports inference on both CPU and GPU and offers native tools for performance analysis and optimization, making it ideal for scaling model deployment.
The repository containing the server configurations and utility code is available at: https://github.com/tech4ai/t4ai-signature-detect-server
Server Configuration
For the Triton implementation, we opted for an optimized approach using a custom Docker container. Instead of using the default image—which includes all backends and results in a size of 17.4 GB, we included only the necessary backends for this project: Python, ONNX, and OpenVINO. This optimization reduced the image size to 12.54 GB, thereby improving deployment efficiency. For scenarios that require GPU inference, the TensorRT backend would need to be included and the model would have to be in the .engine format; however, in this case, we prioritized CPU execution to reduce costs and simplify the infrastructure.
The server was configured using the following startup command, which has been adapted to ensure explicit control over models and enhanced security:
tritonserver \
--model-repository=${TRITON_MODEL_REPOSITORY} \
--model-control-mode=explicit \
--load-model=* \
--log-verbose=1 \
--allow-metrics=false \
--allow-grpc=true \
--grpc-restricted-protocol=model-repository,model-config,shared-memory,statistics,trace:admin-key=${TRITON_ADMIN_KEY} \
--http-restricted-api=model-repository,model-config,shared-memory,statistics,trace:admin-key=${TRITON_ADMIN_KEY}
The explicit mode allows models to be dynamically loaded and unloaded via HTTP/GRPC protocols, providing the flexibility to update models without restarting the server.
Access Restriction
Triton is configured to restrict access to sensitive administrative endpoints such as model-repository, model-config, shared-memory, statistics, and trace. These endpoints are accessible only to requests that include the correct admin-key header, thereby safeguarding administrative operations while leaving inference requests open to all users.
Ensemble Model
We developed an Ensemble Model within Triton to integrate the YOLOv8 model (in ONNX format) with dedicated pre- and post-processing scripts, thereby creating a complete inference pipeline executed directly on the server. This approach minimizes latency by eliminating the need for multiple network calls and simplifies client-side integration. The Ensemble Model workflow comprises:
Preprocessing (Python backend):
- Decoding the image from BGR to RGB.
- Resizing the image to 640×640 pixels.
- Normalizing pixel values (dividing by 255.0).
- Transposing the data to the [C, H, W] format.
Inference (ONNX model):
- The YOLOv8 model performs signature detection.
Post-processing (Python backend):
- Transposing the model outputs.
- Filtering bounding boxes based on a confidence threshold.
- Applying Non-Maximum Suppression (NMS) with an IoU threshold to eliminate redundant detections.
- Formatting the results in the [x, y, w, h, score] format.

The pre- and post-processing scripts are treated as separate "models" by Triton and are executed on the Python backend, enabling flexibility for adjustments or replacements without modifying the core model. This Ensemble Model encapsulates the entire inference pipeline into a single entry point, thereby optimizing performance and usability.
Inference Pipeline
Within the project repository, we developed multiple inference scripts to interact with the Triton Inference Server using various methods:
- Triton Client: Inference via the Triton SDK.
- Vertex AI: Integration with a Google Cloud Vertex AI endpoint.
- HTTP: Direct requests to the Triton server via the HTTP protocol.
These scripts were designed to test the server and facilitate future integrations. In addition, the pipeline includes supplementary tools:
Graphical User Interface (GUI): Developed with Gradio, this interface enables interactive model testing with real-time visualization of results. For example:
python signature-detection/gui/inference_gui.py --triton-url {triton_url}Command-Line Interface (CLI): This tool allows for batch inference on datasets, timing metrics calculation, and report generation. For example:
python signature-detection/inference/inference_pipeline.py
The pipeline was designed to be modular and extensible, supporting experimentation and deployment in various environments—from local setups to cloud-based infrastructures.
4.2. Hugging Face Hub
The signature detection model has been published on the Hugging Face Hub to make it accessible to the community and to meet the licensing requirements of Ultralytics YOLO. The model repository includes:
Model Card:
A comprehensive document detailing the training process, performance metrics (such as precision and recall), and usage guidelines. Model files are available in PyTorch, ONNX, and TensorRT formats, offering flexibility in selecting the inference backend.Demo Space:
An interactive interface developed with Gradio, where users can test the model by uploading images and viewing real-time detections.Dataset:
The dataset used for training and validation is also hosted on Hugging Face, alongside Roboflow, accompanied by comprehensive documentation and files in accessible formats.
5. Conclusion
This work demonstrated the feasibility of developing an efficient model for handwritten signature detection in documents by combining modern computer vision techniques with robust deployment tools. The comparative analysis of architectures revealed that YOLO-based models—particularly YOLOv8s—offer an ideal balance between speed and accuracy for the studied scenario, achieving 94.74% precision and 89.72% recall following hyperparameter optimization with Optuna. The integration of the Triton Inference Server enabled the creation of a scalable inference pipeline, while publication on the Hugging Face Hub ensured transparency and accessibility, in line with open science principles.
The proposed solution has immediate applications in fields such as legal, financial, and administrative sectors, where automating document verification can reduce operational costs and minimize human error. The model’s inference performance on both CPU (171.56 ms) and GPU (7.65 ms) makes it versatile for deployment across a range of infrastructures, from cloud servers to edge devices.
Limitations include the reliance on the quality of dataset annotations and the need for further validation on documents with complex layouts or partially obscured signatures. Future work may explore:
- Expanding the dataset to include images with greater cultural and typographic diversity.
- Adapting the model to detect other document elements (e.g., stamps, seals).
Ultimately, the open availability of the code, model, and dataset on the Hugging Face Hub and GitHub fosters community collaboration, accelerating the development of similar solutions. This project not only validates the efficacy of the tested approaches but also establishes a blueprint for the practical deployment of detection models in production, reinforcing the potential of AI to transform traditional workflows.