Using LoRA for Efficient Stable Diffusion Fine-Tuning








LoRA for Diffusers 🧨
Even though LoRA was initially proposed for large-language models and demonstrated on transformer blocks, the technique can also be applied elsewhere. In the case of Stable Diffusion fine-tuning, LoRA can be applied to the cross-attention layers that relate the image representations with the prompts that describe them. The details of the following figure (taken from the Stable Diffusion paper) are not important, just note that the yellow blocks are the ones in charge of building the relationship between image and text representations.
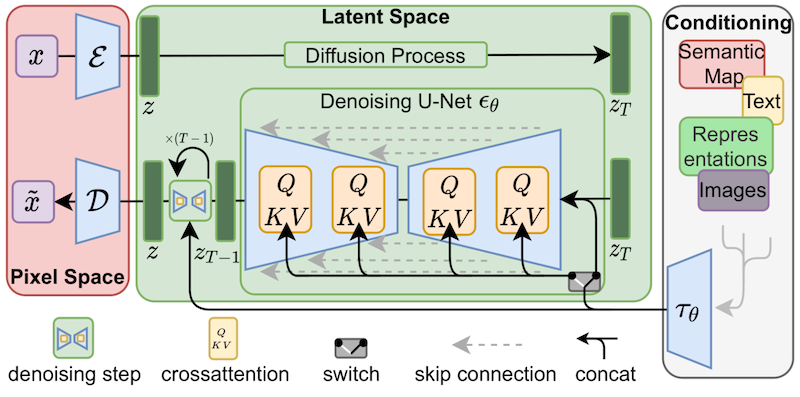
To the best of our knowledge, Simo Ryu (@cloneofsimo) was the first one to come up with a LoRA implementation adapted to Stable Diffusion. Please, do take a look at their GitHub project to see examples and lots of interesting discussions and insights.
In order to inject LoRA trainable matrices as deep in the model as in the cross-attention layers, people used to need to hack the source code of diffusers in imaginative (but fragile) ways. If Stable Diffusion has shown us one thing, it is that the community always comes up with ways to bend and adapt the models for creative purposes, and we love that! Providing the flexibility to manipulate the cross-attention layers could be beneficial for many other reasons, such as making it easier to adopt optimization techniques such as xFormers. Other creative projects such as Prompt-to-Prompt could do with some easy way to access those layers, so we decided to provide a general way for users to do it. We've been testing that pull request since late December, and it officially launched with our diffusers release yesterday.
We've been working with @cloneofsimo to provide LoRA training support in diffusers, for both Dreambooth and full fine-tuning methods! These techniques provide the following benefits:
- Training is much faster, as already discussed.
- Compute requirements are lower. We could create a full fine-tuned model in a 2080 Ti with 11 GB of VRAM!
- Trained weights are much, much smaller. Because the original model is frozen and we inject new layers to be trained, we can save the weights for the new layers as a single file that weighs in at ~3 MB in size. This is about one thousand times smaller than the original size of the UNet model!
We are particularly excited about the last point. In order for users to share their awesome fine-tuned or dreamboothed models, they had to share a full copy of the final model. Other users that want to try them out have to download the fine-tuned weights in their favorite UI, adding up to combined massive storage and download costs. As of today, there are about 1,000 Dreambooth models registered in the Dreambooth Concepts Library, and probably many more not registered in the library.
With LoRA, it is now possible to publish a single 3.29 MB file to allow others to use your fine-tuned model.
(h/t to @mishig25, the first person I heard use dreamboothing as a verb in a normal conversation).
LoRA fine-tuning
Full model fine-tuning of Stable Diffusion used to be slow and difficult, and that's part of the reason why lighter-weight methods such as Dreambooth or Textual Inversion have become so popular. With LoRA, it is much easier to fine-tune a model on a custom dataset.
Diffusers now provides a LoRA fine-tuning script that can run in as low as 11 GB of GPU RAM without resorting to tricks such as 8-bit optimizers. This is how you'd use it to fine-tune a model using Lambda Labs Pokémon dataset:
export MODEL_NAME="runwayml/stable-diffusion-v1-5"
export OUTPUT_DIR="/sddata/finetune/lora/pokemon"
export HUB_MODEL_ID="pokemon-lora"
export DATASET_NAME="lambdalabs/pokemon-blip-captions"
accelerate launch --mixed_precision="fp16" train_text_to_image_lora.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--dataset_name=$DATASET_NAME \
--dataloader_num_workers=8 \
--resolution=512 --center_crop --random_flip \
--train_batch_size=1 \
--gradient_accumulation_steps=4 \
--max_train_steps=15000 \
--learning_rate=1e-04 \
--max_grad_norm=1 \
--lr_scheduler="cosine" --lr_warmup_steps=0 \
--output_dir=${OUTPUT_DIR} \
--push_to_hub \
--hub_model_id=${HUB_MODEL_ID} \
--report_to=wandb \
--checkpointing_steps=500 \
--validation_prompt="Totoro" \
--seed=1337
One thing of notice is that the learning rate is 1e-4, much larger than the usual learning rates for regular fine-tuning (in the order of ~1e-6, typically). This is a W&B dashboard of the previous run, which took about 5 hours in a 2080 Ti GPU (11 GB of RAM). I did not attempt to optimize the hyperparameters, so feel free to try it out yourself! Sayak did another run on a T4 (16 GB of RAM), here's his final model, and here's a demo Space that uses it.

For additional details on LoRA support in diffusers, please refer to our documentation – it will be always kept up to date with the implementation.
Inference
As we've discussed, one of the major advantages of LoRA is that you get excellent results by training orders of magnitude less weights than the original model size. We designed an inference process that allows loading the additional weights on top of the unmodified Stable Diffusion model weights. Let's see how it works.
First, we'll use the Hub API to automatically determine what was the base model that was used to fine-tune a LoRA model. Starting from Sayak's model, we can use this code:
from huggingface_hub import model_info
# LoRA weights ~3 MB
model_path = "sayakpaul/sd-model-finetuned-lora-t4"
info = model_info(model_path)
model_base = info.cardData["base_model"]
print(model_base) # CompVis/stable-diffusion-v1-4
This snippet will print the model he used for fine-tuning, which is CompVis/stable-diffusion-v1-4. In my case, I trained my model starting from version 1.5 of Stable Diffusion, so if you run the same code with my LoRA model you'll see that the output is runwayml/stable-diffusion-v1-5.
The information about the base model is automatically populated by the fine-tuning script we saw in the previous section, if you use the --push_to_hub option. This is recorded as a metadata tag in the README file of the model's repo, as you can see here.
After we determine the base model we used to fine-tune with LoRA, we load a normal Stable Diffusion pipeline. We'll customize it with the DPMSolverMultistepScheduler for very fast inference:
import torch
from diffusers import StableDiffusionPipeline, DPMSolverMultistepScheduler
pipe = StableDiffusionPipeline.from_pretrained(model_base, torch_dtype=torch.float16)
pipe.scheduler = DPMSolverMultistepScheduler.from_config(pipe.scheduler.config)
And here's where the magic comes. We load the LoRA weights from the Hub on top of the regular model weights, move the pipeline to the cuda device and run inference:
pipe.unet.load_attn_procs(model_path)
pipe.to("cuda")
image = pipe("Green pokemon with menacing face", num_inference_steps=25).images[0]
image.save("green_pokemon.png")
Dreamboothing with LoRA
Dreambooth allows you to "teach" new concepts to a Stable Diffusion model. LoRA is compatible with Dreambooth and the process is similar to fine-tuning, with a couple of advantages:
- Training is faster.
- We only need a few images of the subject we want to train (5 or 10 are usually enough).
- We can tweak the text encoder, if we want, for additional fidelity to the subject.
To train Dreambooth with LoRA you need to use this diffusers script. Please, take a look at the README, the documentation and our hyperparameter exploration blog post for details.
For a quick, cheap and easy way to train your Dreambooth models with LoRA, please check this Space by hysts. You need to duplicate it and assign a GPU so it runs fast. This process will save you from having to set up your own training environment and you'll be able to train your models in minutes!
Other Methods
The quest for easy fine-tuning is not new. In addition to Dreambooth, textual inversion is another popular method that attempts to teach new concepts to a trained Stable Diffusion Model. One of the main reasons for using Textual Inversion is that trained weights are also small and easy to share. However, they only work for a single subject (or a small handful of them), whereas LoRA can be used for general-purpose fine-tuning, meaning that it can be adapted to new domains or datasets.
Pivotal Tuning is a method that tries to combine Textual Inversion with LoRA. First, you teach the model a new concept using Textual Inversion techniques, obtaining a new token embedding to represent it. Then, you train that token embedding using LoRA to get the best of both worlds.
We haven't explored Pivotal Tuning with LoRA yet. Who's up for the challenge? 🤗












