Instruction-tuning Stable Diffusion with InstructPix2Pix







This post explores instruction-tuning to teach Stable Diffusion to follow instructions to translate or process input images. With this method, we can prompt Stable Diffusion using an input image and an “instruction”, such as - Apply a cartoon filter to the natural image.
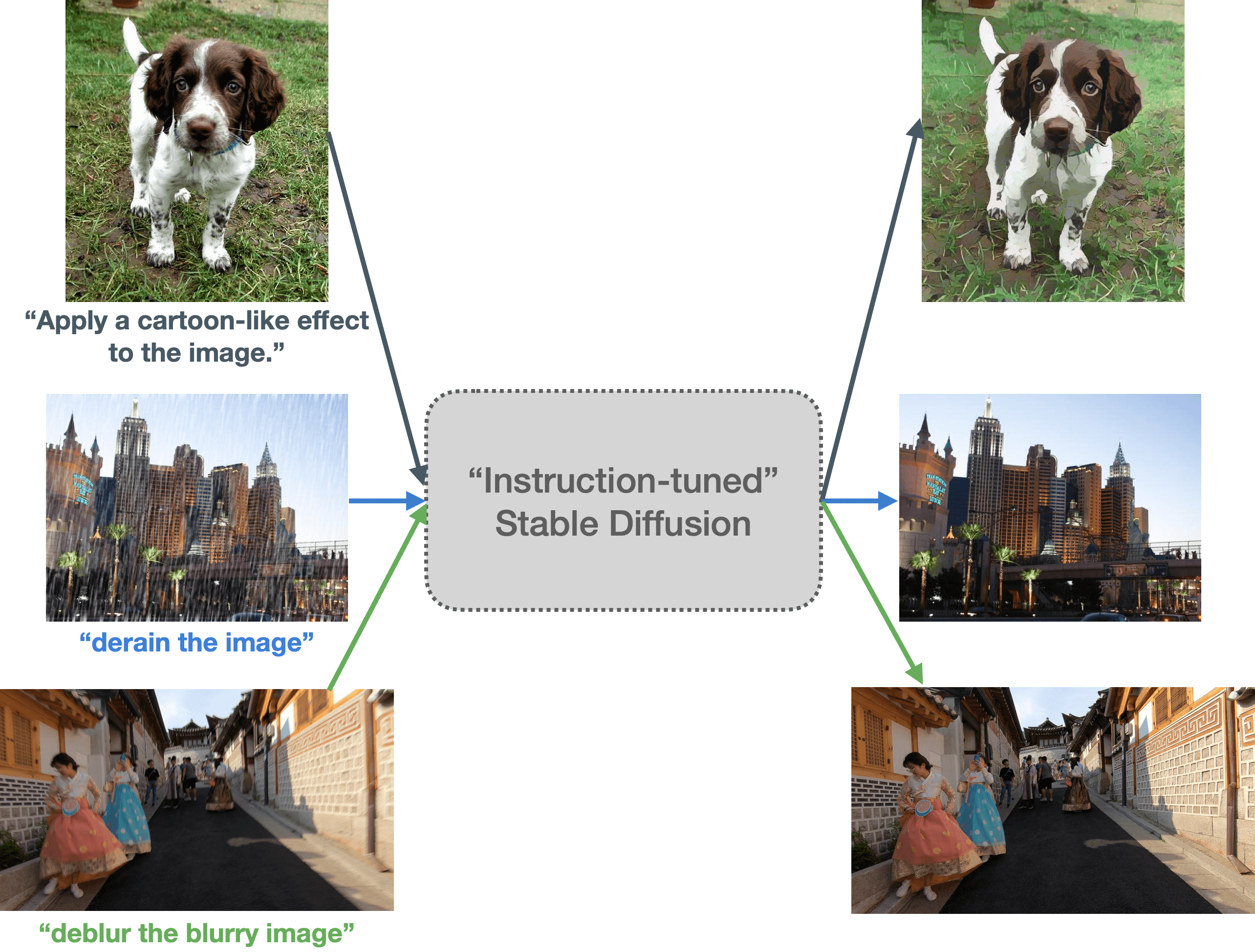 |
|---|
| Figure 1: We explore the instruction-tuning capabilities of Stable Diffusion. In this figure, we prompt an instruction-tuned Stable Diffusion system with prompts involving different transformations and input images. The tuned system seems to be able to learn these transformations stated in the input prompts. Figure best viewed in color and zoomed in. |
This idea of teaching Stable Diffusion to follow user instructions to perform edits on input images was introduced in InstructPix2Pix: Learning to Follow Image Editing Instructions. We discuss how to extend the InstructPix2Pix training strategy to follow more specific instructions related to tasks in image translation (such as cartoonization) and low-level image processing (such as image deraining). We cover:
- Introduction to instruction-tuning
- The motivation behind this work
- Dataset preparation
- Training experiments and results
- Potential applications and limitations
- Open questions
Our code, pre-trained models, and datasets can be found here.
Introduction and motivation
Instruction-tuning is a supervised way of teaching language models to follow instructions to solve a task. It was introduced in Fine-tuned Language Models Are Zero-Shot Learners (FLAN) by Google. From recent times, you might recall works like Alpaca and FLAN V2, which are good examples of how beneficial instruction-tuning can be for various tasks.
The figure below shows a formulation of instruction-tuning (also called “instruction-finetuning”). In the FLAN V2 paper, the authors take a pre-trained language model (T5, for example) and fine-tune it on a dataset of exemplars, as shown in the figure below.
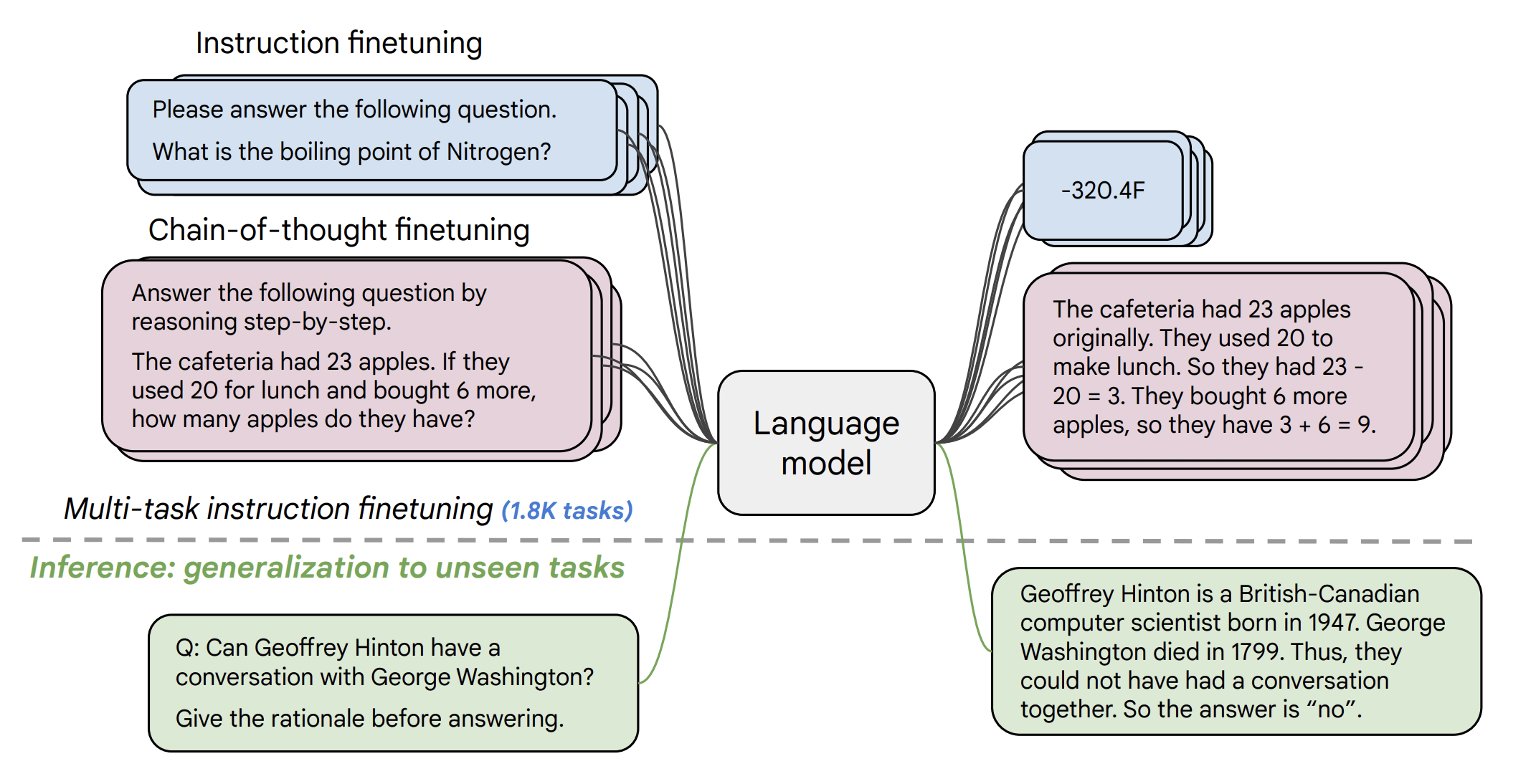 |
|---|
| Figure 2: FLAN V2 schematic (figure taken from the FLAN V2 paper). |
With this approach, one can create exemplars covering many different tasks, which makes instruction-tuning a multi-task training objective:
| Input | Label | Task |
|---|---|---|
| Predict the sentiment of the following sentence: “The movie was pretty amazing. I could not turn around my eyes even for a second.” |
Positive | Sentiment analysis / Sequence classification |
| Please answer the following question. What is the boiling point of Nitrogen? |
320.4F | Question answering |
| Translate the following English sentence into German: “I have a cat.” |
Ich habe eine Katze. | Machine translation |
| … | … | … |
Using a similar philosophy, the authors of FLAN V2 conduct instruction-tuning on a mixture of thousands of tasks and achieve zero-shot generalization to unseen tasks:
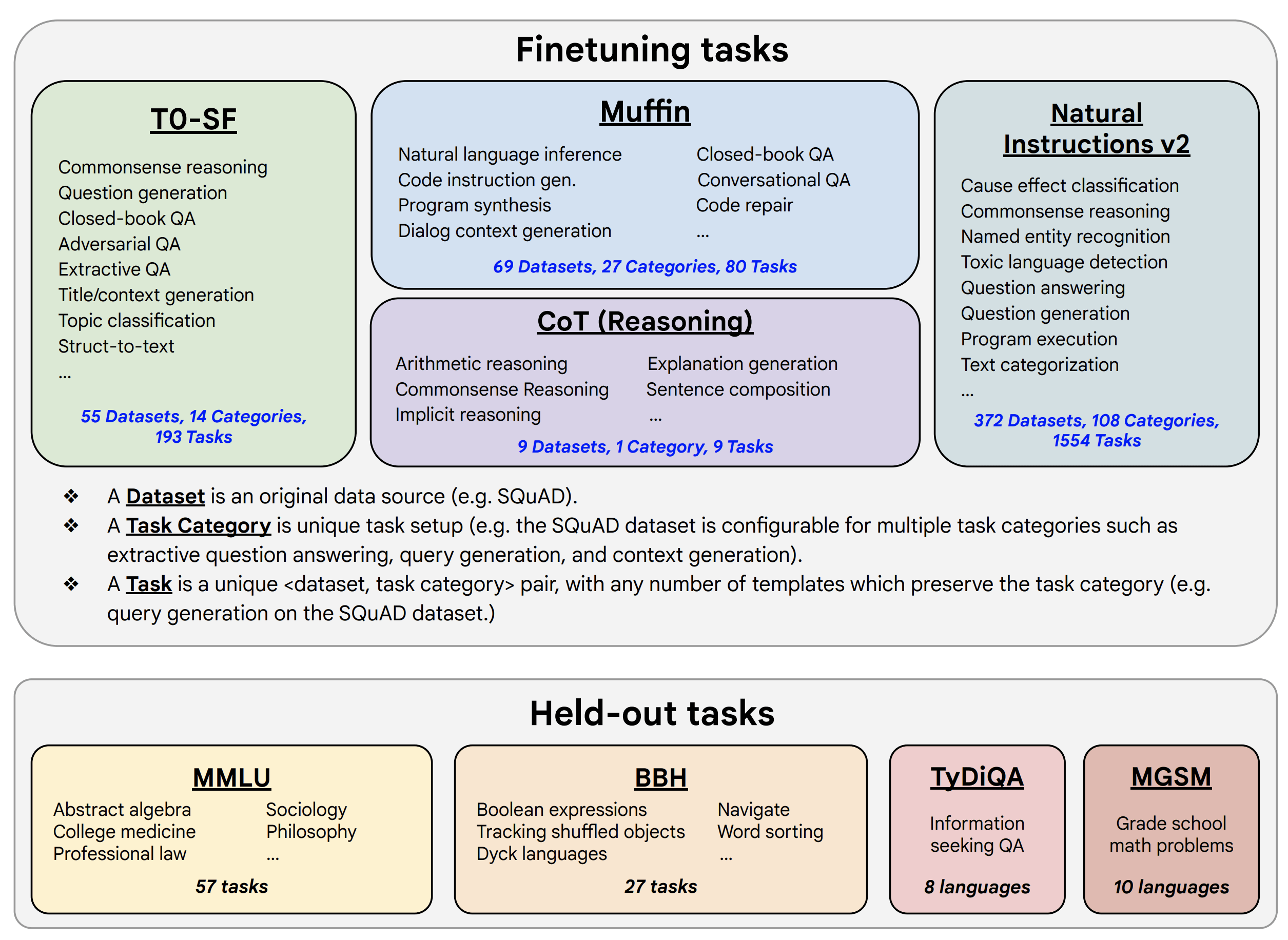 |
|---|
| Figure 3: FLAN V2 training and test task mixtures (figure taken from the FLAN V2 paper). |
Our motivation behind this work comes partly from the FLAN line of work and partly from InstructPix2Pix. We wanted to explore if it’s possible to prompt Stable Diffusion with specific instructions and input images to process them as per our needs.
The pre-trained InstructPix2Pix models are good at following general instructions, but they may fall short of following instructions involving specific transformations:
 |
|---|
| Figure 4: We observe that for the input images (left column), our models (right column) more faithfully perform “cartoonization” compared to the pre-trained InstructPix2Pix models (middle column). It is interesting to note the results of the first row where the pre-trained InstructPix2Pix models almost fail significantly. Figure best viewed in color and zoomed in. See original here. |
But we can still leverage the findings from InstructPix2Pix to suit our customizations.
On the other hand, paired datasets for tasks like cartoonization, image denoising, image deraining, etc. are available publicly, which we can use to build instruction-prompted datasets taking inspiration from FLAN V2. Doing so allows us to transfer the instruction-templating ideas explored in FLAN V2 to this work.
Dataset preparation
Cartoonization
In our early experiments, we prompted InstructPix2Pix to perform cartoonization and the results were not up to our expectations. We tried various inference-time hyperparameter combinations (such as image guidance scale and the number of inference steps), but the results still were not compelling. This motivated us to approach the problem differently.
As hinted in the previous section, we wanted to benefit from both worlds:
(1) training methodology of InstructPix2Pix and (2) the flexibility of creating instruction-prompted dataset templates from FLAN.
We started by creating an instruction-prompted dataset for the task of cartoonization. Figure 5 presents our dataset creation pipeline:
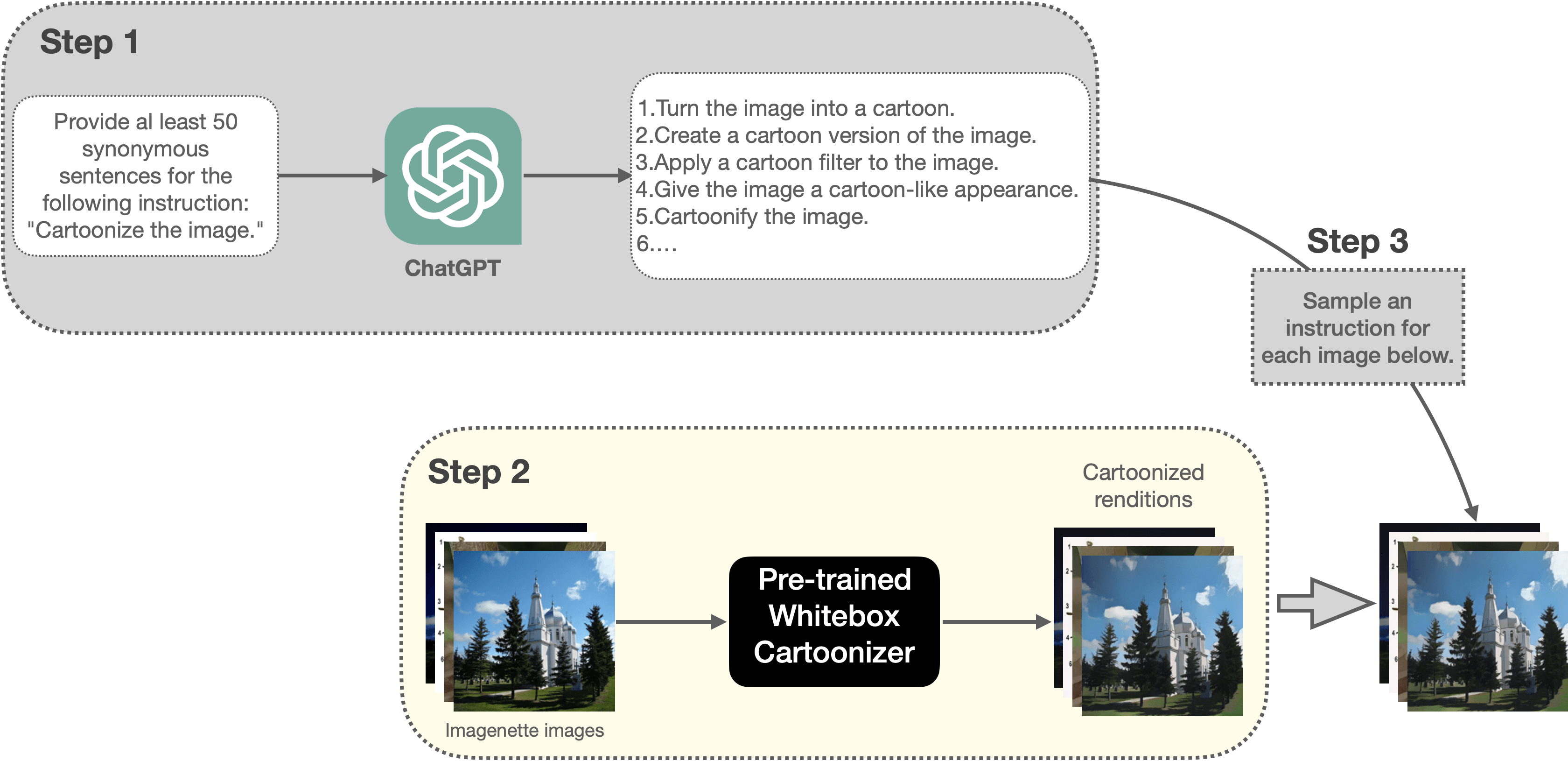 |
|---|
| Figure 5: A depiction of our dataset creation pipeline for cartoonization (best viewed in color and zoomed in). |
In particular, we:
- Ask ChatGPT to generate 50 synonymous sentences for the following instruction: "Cartoonize the image.”
- We then use a random sub-set (5000 samples) of the Imagenette dataset and leverage a pre-trained Whitebox CartoonGAN model to produce the cartoonized renditions of those images. The cartoonized renditions are the labels we want our model to learn from. So, in a way, this corresponds to transferring the biases learned by the Whitebox CartoonGAN model to our model.
- Then we create our exemplars in the following format:
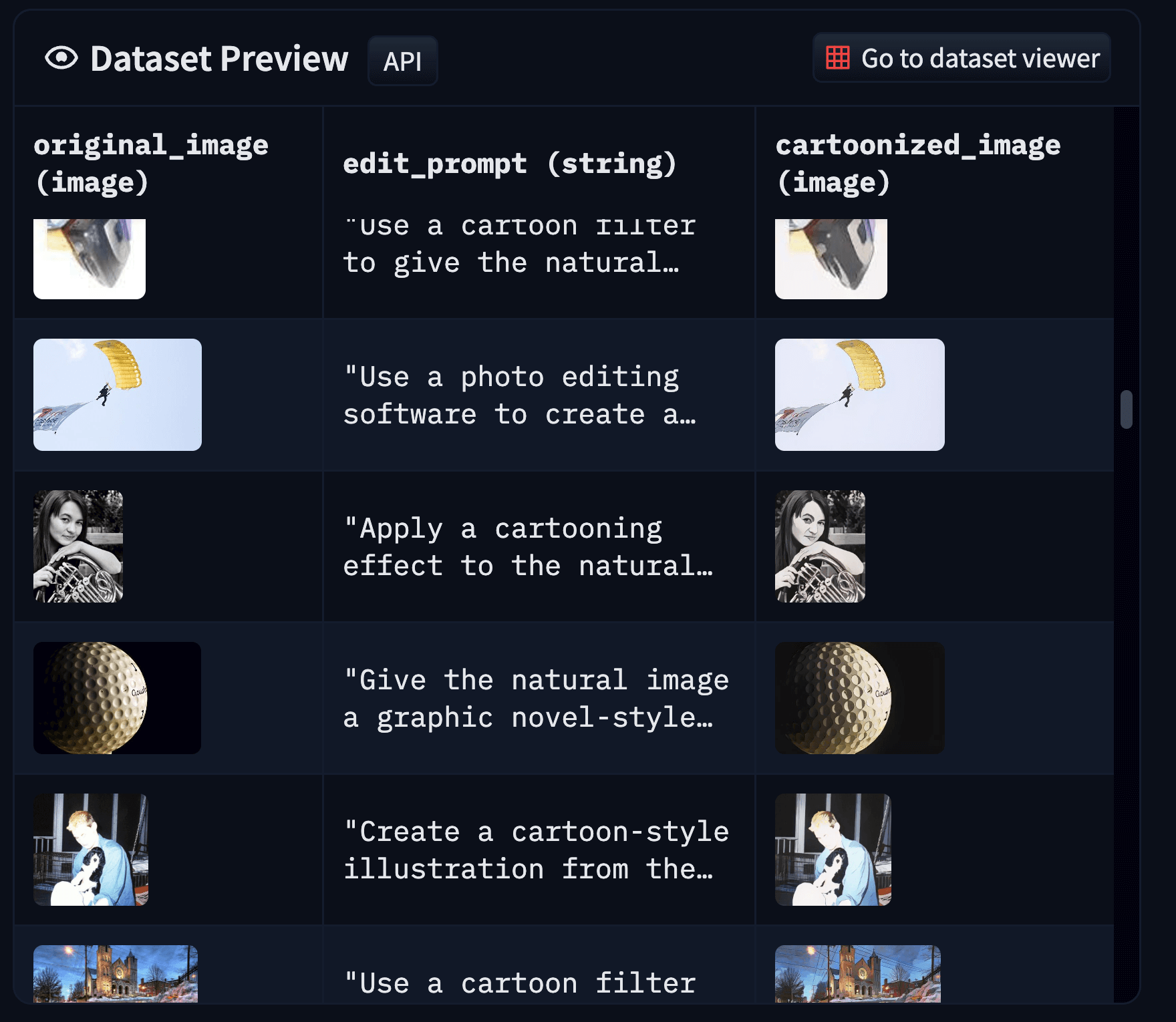 |
|---|
| Figure 6: Samples from the final cartoonization dataset (best viewed in color and zoomed in). |
Our final dataset for cartoonization can be found here. For more details on how the dataset was prepared, refer to this directory. We experimented with this dataset by fine-tuning InstructPix2Pix and got promising results (more details in the “Training experiments and results” section).
We then proceeded to see if we could generalize this approach to low-level image processing tasks such as image deraining, image denoising, and image deblurring.
Low-level image processing
We focus on the common low-level image processing tasks explored in MAXIM. In particular, we conduct our experiments for the following tasks: deraining, denoising, low-light image enhancement, and deblurring.
We took different number of samples from the following datasets for each task and constructed a single dataset with prompts added like so:
| Task | Prompt | Dataset | Number of samples |
|---|---|---|---|
| Deblurring | “deblur the blurry image” | REDS (train_blurand train_sharp) |
1200 |
| Deraining | “derain the image” | Rain13k | 686 |
| Denoising | “denoise the noisy image” | SIDD | 8 |
| Low-light image enhancement |
"enhance the low-light image” | LOL | 23 |
Datasets mentioned above typically come as input-output pairs, so we do not have to worry about the ground-truth. Our final dataset is available here. The final dataset looks like so:
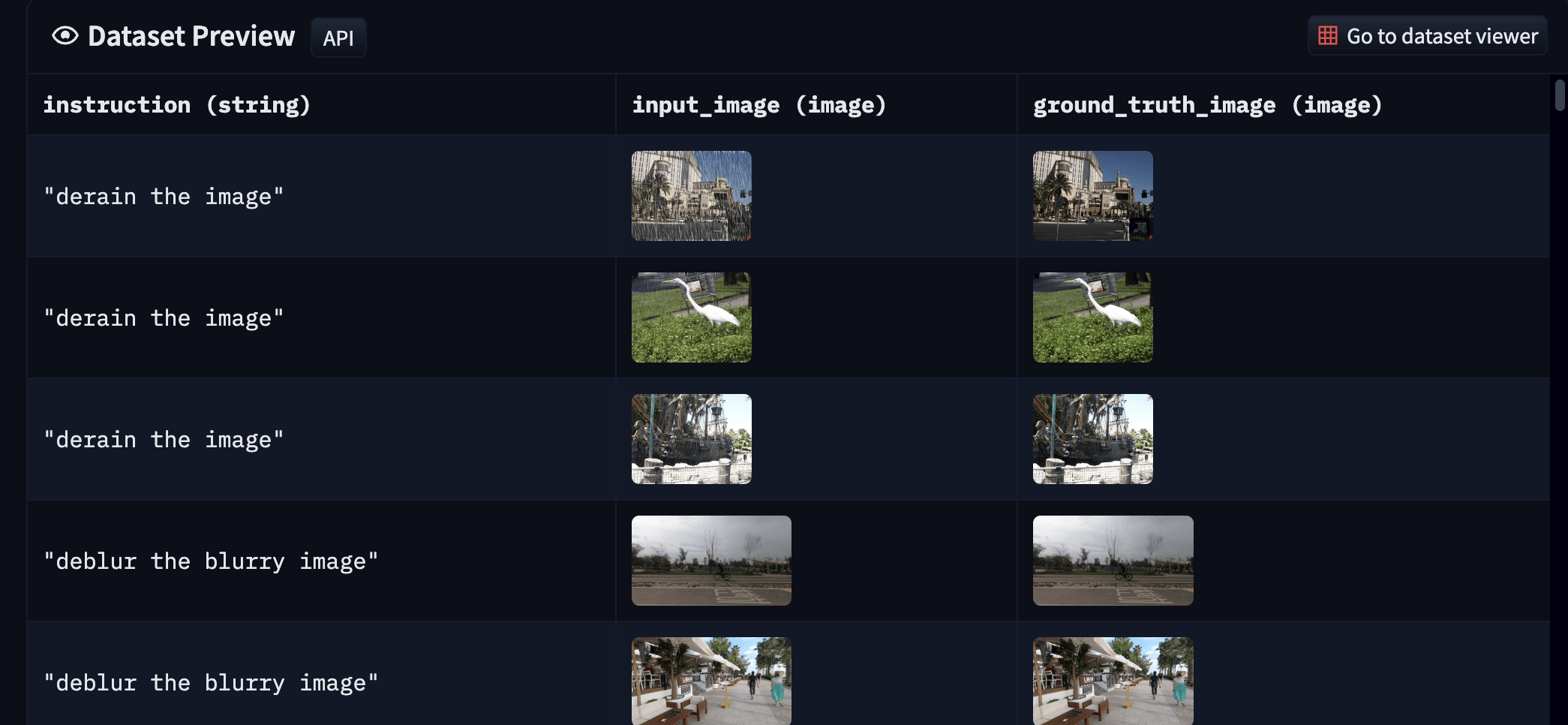 |
|---|
| Figure 7: Samples from the final low-level image processing dataset (best viewed in color and zoomed in). |
Overall, this setup helps draw parallels from the FLAN setup, where we create a mixture of different tasks. This also helps us train a single model one time, performing well to the different tasks we have in the mixture. This varies significantly from what is typically done in low-level image processing. Works like MAXIM introduce a single model architecture capable of modeling the different low-level image processing tasks, but training happens independently on the individual datasets.
Training experiments and results
We based our training experiments on this script. Our training logs (including validation samples and training hyperparameters) are available on Weight and Biases:
When training, we explored two options:
- Fine-tuning from an existing InstructPix2Pix checkpoint
- Fine-tuning from an existing Stable Diffusion checkpoint using the InstructPix2Pix training methodology
In our experiments, we found out that the first option helps us adapt to our datasets faster (in terms of generation quality).
For more details on the training and hyperparameters, we encourage you to check out our code and the respective run pages on Weights and Biases.
Cartoonization results
For testing the instruction-tuned cartoonization model, we compared the outputs as follows:
 |
|---|
| Figure 8: We compare the results of our instruction-tuned cartoonization model (last column) with that of a CartoonGAN model (column two) and the pre-trained InstructPix2Pix model (column three). It’s evident that the instruction-tuned model can more faithfully match the outputs of the CartoonGAN model. Figure best viewed in color and zoomed in. See original here. |
To gather these results, we sampled images from the validation split of ImageNette. We used the following prompt when using our model and the pre-trained InstructPix2Pix model: “Generate a cartoonized version of the image”. For these two models, we kept the image_guidance_scale and guidance_scale to 1.5 and 7.0, respectively, and number of inference steps to 20. Indeed more experimentation is needed around these hyperparameters to study how they affect the results of the pre-trained InstructPix2Pix model, in particular.
More comparative results are available here. Our code for comparing these models is available here.
Our model, however, fails to produce the expected outputs for the classes from ImageNette, which it has not seen enough during training. This is somewhat expected, and we believe this could be mitigated by scaling the training dataset.
Low-level image processing results
For low-level image processing (our model), we follow the same inference-time hyperparameters as above:
- Number of inference steps: 20
- Image guidance scale: 1.5
- Guidance scale: 7.0
For deraining, our model provides compelling results when compared to the ground-truth and the output of the pre-trained InstructPix2Pix model:
 |
|---|
| Figure 9: Deraining results (best viewed in color and zoomed in). Inference prompt: “derain the image” (same as the training set). See original here. |
However, for low-light image enhancement, it leaves a lot to be desired:
 |
|---|
| Figure 10: Low-light image enhancement results (best viewed in color and zoomed in). Inference prompt: “enhance the low-light image” (same as the training set). See original here. |
This failure, perhaps, can be attributed to our model not seeing enough exemplars for the task and possibly from better training. We notice similar findings for deblurring as well:
 |
|---|
| Figure 11: Deblurring results (best viewed in color and zoomed in). Inference prompt: “deblur the image” (same as the training set). See original here. |
We believe there is an opportunity for the community to explore how much the task mixture for low-level image processing affects the end results. Does increasing the task mixture with more representative samples help improve the end results? We leave this question for the community to explore further.
You can try out the interactive demo below to make Stable Diffusion follow specific instructions:
Potential applications and limitations
In the world of image editing, there is a disconnect between what a domain expert has in mind (the tasks to be performed) and the actions needed to be applied in editing tools (such as Lightroom). Having an easy way of translating natural language goals to low-level image editing primitives would be a seamless user experience. With the introduction of mechanisms like InstructPix2Pix, it’s safe to say that we’re getting closer to that realm.
However, challenges still remain:
- These systems need to work for large high-resolution original images.
- Diffusion models often invent or re-interpret an instruction to perform the modifications in the image space. For a realistic image editing application, this is unacceptable.
Open questions
We acknowledge that our experiments are preliminary. We did not go deep into ablating the apparent factors in our experiments. Hence, here we enlist a few open questions that popped up during our experiments:
What happens we scale up the datasets? How does that impact the quality of the generated samples? We experimented with a handful of examples. For comparison, InstructPix2Pix was trained on more than 30000 samples.
What is the impact of training for longer, especially when the task mixture is broader? In our experiments, we did not conduct hyperparameter tuning, let alone an ablation on the number of training steps.
How does this approach generalize to a broader mixture of tasks commonly done in the “instruction-tuning” world? We only covered four tasks for low-level image processing: deraining, deblurring, denoising, and low-light image enhancement. Does adding more tasks to the mixture with more representative samples help the model generalize to unseen tasks or, perhaps, a combination of tasks (example: “Deblur the image and denoise it”)?
Does using different variations of the same instruction on-the-fly help improve performance? For cartoonization, we randomly sampled an instruction from the set of ChatGPT-generated synonymous instructions during dataset creation. But what happens when we perform random sampling during training instead?
For low-level image processing, we used fixed instructions. What happens when we follow a similar methodology of using synonymous instructions for each task and input image?
What happens when we use ControlNet training setup, instead? ControlNet also allows adapting a pre-trained text-to-image diffusion model to be conditioned on additional images (such as semantic segmentation maps, canny edge maps, etc.). If you’re interested, then you can use the datasets presented in this post and perform ControlNet training referring to this post.
Conclusion
In this post, we presented our exploration of “instruction-tuning” of Stable Diffusion. While pre-trained InstructPix2Pix are good at following general image editing instructions, they may break when presented with more specific instructions. To mitigate that, we discussed how we prepared our datasets for further fine-tuning InstructPix2Pix and presented our results. As noted above, our results are still preliminary. But we hope this work provides a basis for the researchers working on similar problems and they feel motivated to explore the open questions further.
Links
- Training and inference code: https://github.com/huggingface/instruction-tuned-sd
- Demo: https://huggingface.co/spaces/instruction-tuning-sd/instruction-tuned-sd
- InstructPix2Pix: https://huggingface.co/timbrooks/instruct-pix2pix
- Datasets and models from this post: https://huggingface.co/instruction-tuning-sd
Thanks to Alara Dirik and Zhengzhong Tu for the helpful discussions. Thanks to Pedro Cuenca and Kashif Rasul for their helpful reviews on the post.
Citation
To cite this work, please use the following citation:
@article{
Paul2023instruction-tuning-sd,
author = {Paul, Sayak},
title = {Instruction-tuning Stable Diffusion with InstructPix2Pix},
journal = {Hugging Face Blog},
year = {2023},
note = {https://huggingface.co/blog/instruction-tuning-sd},
}








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}