
General advice: Having a good dataset is more important than anything else
Trigger words
Anisphia, Euphyllia, Tilty, OyamaMahiro, OyamaMihari
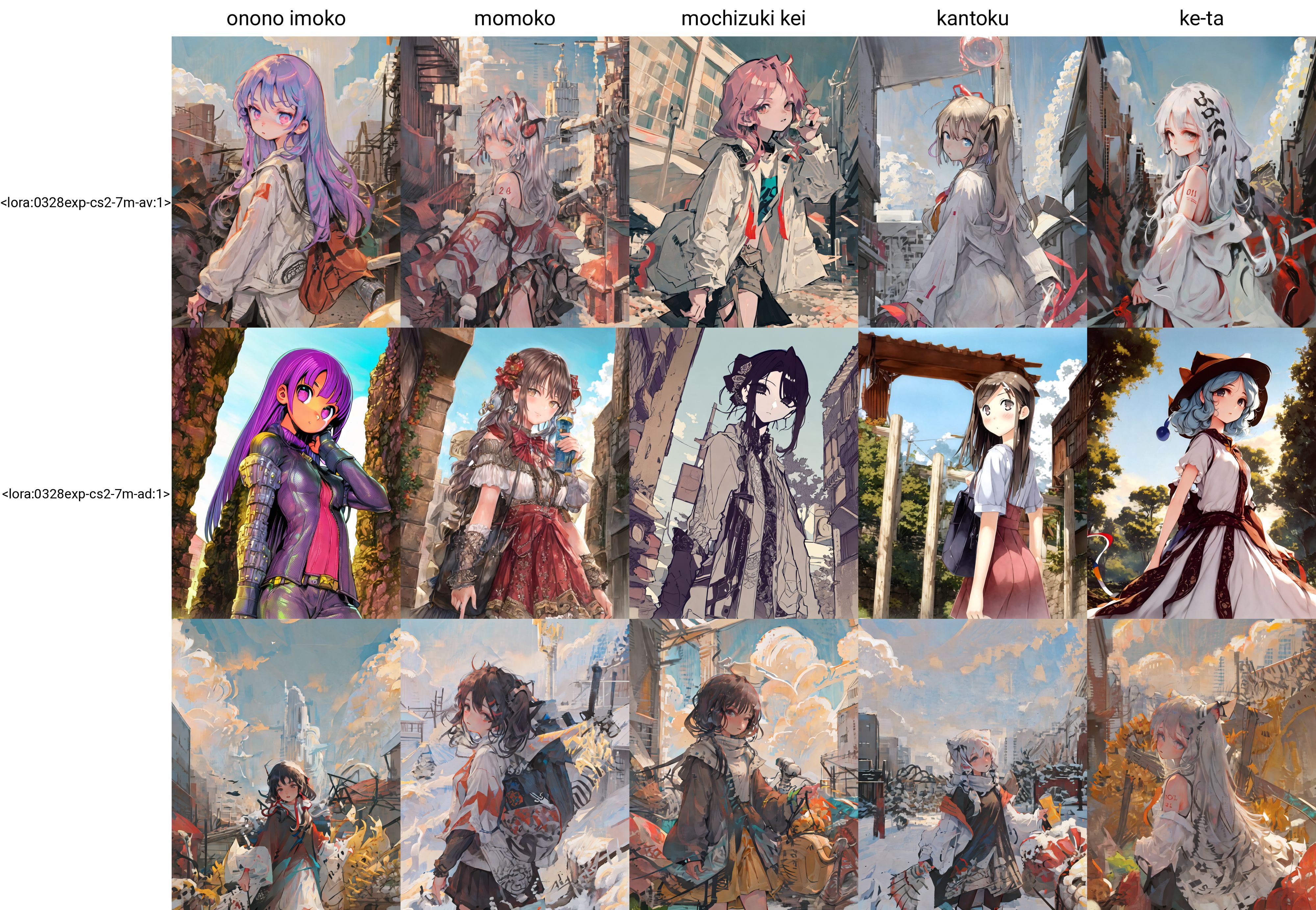
by onono imoko, by momoko, by mochizuki kei, by kantoku, by ke-ta
aniscreen, fanart
For 0324_all_aniscreen_tags, I accidentally tag all the character images with aniscreen.
For the others, things are done correctly (anime screenshots tagged as aniscreen, fanart tagged as fanart).
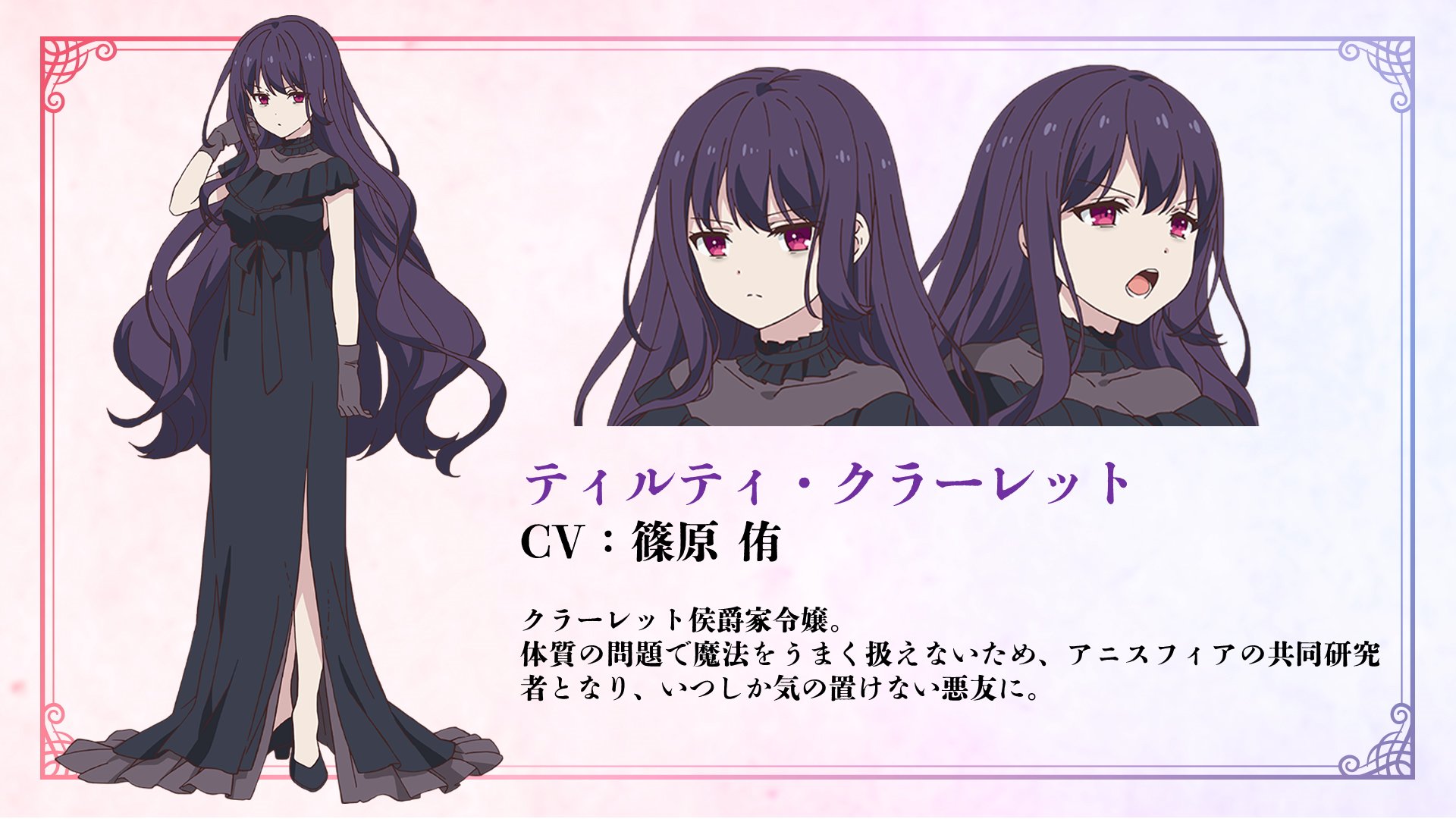
For reference, this is what each character looks like
Anisphia

Euphyllia

Tilty
OyamaMahiro (white hair one) and OyamaMihari (black hair one)

As for the styles please check the artists' pixiv yourself (note there are R-18 images)
Setting
Default settings are
- loha net dim 8, conv dim 4, alpha 1
- lr 2e-4 constant scheduler throughout
- Adam8bit
- resolution 512
- clip skip 1
Names of the files suggest how the setting is changed with respect to this default setup.
The configuration json files can otherwsie be found in the config sub-directories that lies in each folder.
For example this is the default config.
Some observations
For a thorough comparison please refer to the generated_samples folder.
Captioning
Dataset, in general, is the most important out of all. The common wisdom that we should prune anything that we want to be attach to the trigger word is exactly the way to go for. No tags at all (top three rows) is terrible, especially for style training. Having all the tags (bottom three rows) remove the traits from subjects if these tags are not used during sampling (not completely true but more or less the case, see also discussion below).

The effect of style images on characters
I do believe regularization images are important, far more important than tweaking any hyperparameters. They slow down training but also make sure that the undesired aspect are less baked into the model if we have images of other types, even if they are not for the subjects we train for.
Comparing the models trained with and without style images, we can see that models trained with general style images have less anime styles baked in. The difference is particularly clear for Tilty, who only have anime screenshots for training.

On the other hand, the default clothes seem to be better trained when there are no regularization images. While this may seem beneficial, it is worth noticing that I keep all the output tags. Therefore, in a sense we only want to get a certain outfit when we prompt them explicitly. The magic of having the trigger words to fill in what is not in caption seems to be more pronouncing when we have regularization images. In any case, this magic will not work forever as we will eventually start overfitting. The following image show that we get images that are much closer after putting clothes in prompts.

In any case, if your regularization images are properly tagged with of a lot of concepts, then you always have the benefit that you can combine them with the main things you train for.
Training resolution
The most prominent benefit of training at higher resolution is that it helps generating more complex/detailed background. Chances are that you can get more details about the outfit or pupils etc. However, training at higher-resolution is quite time-consuming and most of the time it is probably not worth it. For example, if you want better background it can be simpler to switch the model (unless, say, you are actually training background lora).


Network dimension and alpha
This is one of the most debated topic in LoRa training.
Both the original paper and the initial implementation of LoRa for SD suggest using quite small ranks.
However, the 128 dim/alpha became the unfortunate default in many implementations for some time, which resulted in files with more than 100mb.
Every since LoCon got introduced, we advocate again the use of smaller dimension and default the value of alpha to 1.
As for LoHa, I have been insisting that the values that I am using here (net dim 8, conv dim 4, alpha 1) should be more than enough in most cases.
These values do not come from no where. In fact, after some analysis, it turns out almost every model fine-tuned from SD has the information of the weight difference matrix concentrated in fewer than 64 ranks (this applies even to WD 1.5).
Therefore, 64 should enough-- if we can get to the good point.
Nonetheless, optimization is quite tricky. Changing dimension does not only increase expressive power but also modify the optimization landscape. It is also exactly for the latter that alpha gets introduced.
It turns out it might be easier to get better results with larger dimension, which explains the success of compression after training.
Actually, for my 60K umamusume dataset I have LoCon extracted from fine-tuned model but I failed to directly train a LoCon on it.
To clarify all these, I test the following three setups for LoHa with net dim 32 and conv dim 16
- lr 2e-4, alpha 1
- lr 5e-4, alpha 1
- lr 2e-4, net alpha 16, conv alpha 8
I made the following observations
- I get good results with latter two configurations, which confirms that increasing alpha and learning rate have similar effects. More precisely, I have better backgrounds and better separation between fanart and screenshot styles (only for Mihari and Euphyllia though) compared to dimension 8/4 LoHas.
- Both of them however have their own strength and own weakness. The 5e-4 one works better for
Euphyllia; fanart
- Among all the modules I trained, only the dim 32/16 half alpha one can almost consistently output the correct outfit for Mihari

- They seem to give better results for style training in general.



- They seem to provide better style transfer. Please refer to the end (image of 144mb).
One interesting observation is that in the first image we get better background for small LoHa trained at higher resolution and larger LoHa trained only at resolution 512. This again suggests we may be able to get good results with small dimension if they are trained properly. It is however unclear how to achieve that. Simply increasing the learning rate to 5e-4 does not seem to be sufficient in this case (as can be seen from the above images).
Finally, these results do not mean that you would always want to use larger dimension, as probably you do not really need all these details that the additional dimension brings you.
Optimizer, learning rate scheduler, and learning rate
This is probably the most important things to tune after you get a good dataset, but I don't have many things to say here.
You should just find the one that works.
Some people suggest the lr finder strategy https://followfoxai.substack.com/p/find-optimal-learning-rates-for-stable
I tested several things, and here is what I can say
- Setting the learning rate larger of course makes training faster as long as it does not fry things up. Here switching the learning rate from lr 2e-4 to 5e-4 increases the likeliness. Would it however be better to train longer with smaller learning rate? This still needs more test. (I will zoom in on the case where we only change the text encoder learning rate below.)
- Cosine schduler learns slower than constant scheduler for a fixed learning rate.
- It seems that Dadaptation trains faster at styles but slower at characters. Why?
Since the outputs of Dadaptation seems to change more over time, I guess it may just have picked a larger learning rate. Does this then mean larger learning rate would pick the style first?
Text encoder learning rate
It is often suggested to set the text encoder learning rate to be smaller than that of unet. This of course causes training to be slower white it is hard to evaluate the benefit. To begin, let me show how it actually slow downs the trainer process. In contrary to the common belief, it actually affects style training more than character training. I half the text encoder learning rate for the following experiments.
This is what you get for characters. If the trigger words are put properly you barely see the difference, not mentioning the case of single character training that most people focus on. The interesting point however comes from the blending between Mahiro and Mihari due to sharing
Oyamain the trigger words. Large text encoder learning rate help reduces the blending faster.
For styles you can see training with lower text encoder rate actually makes training slower (the largest difference happens to ke-ta and momoko)

In total I train the model two times longer. After spending some time here are two situations that reveal the potential benefit of having smaller text encoder learning rate.
- In my training set I have anime screenshots, tagged with
aniscreenand fanarts, taggedd withfanart. Although they are balanced to have the same weight, the consistency of anime screenshots seems to drive the characters toward this style by default. When I putaniscreento negative, this causes bad results in general but the one trained with lower text encoder learning rate seems to survive the best. Note that Tilty (second image) is only trained with anime screenshots.


- Training at lower text encoder rate should better preserve the model's ability to understand the prompt. This aspect is difficult to test, but it seems to be confirmed by this "umbrella" experiment (though some other setup, such as lora and higher dimension seem to give even better results).

There may be some other disadvantages other than slower training but this needs to be further explored.
In any case, I still believe if we want to get the best result we should avoid compeletely text encoder training and do pivotal tuning instead.
LoRa, LoCon, LoHa
It may seem weird to mention this so late, but honestly I do not find them to give very different result here.
The common belief is that LoHa trains more style than LoCon, which in turn trains more style than LoRa.
This seems to be mostly true, but the difference is quite subtle. Moreover, I would rather use the word "texture" instead of style.
I especially test whether any of them would be more favorable when transferred to different base model. No conclusion here.
- LoHA

- LoCon

- LoRa

- Without additional network

Some remarks
- In the above images, LoHa has dim 8/4, LoCon has dim 16/8, and LoRa has dim 8. LoHa and LoCon thus have roughly the same size (25mb) while LoRa is smaller (11mb). LoRa with smaller dimension seems to train faster here.
- Some comparaison between LoHa and LoCon do suggest that LoHa indeed trains faster at texture while LoCon faster at higher level traits. The difference is however very small so it is not really conclusive.


- In an early experiment I saw that LoHa and LoCon training lead to quite different result. One possible explanation is that I train on NAI here while I trained on BP in that experiment.
Clip skip 1 versus 2
People say that wy should train on clip skip 2 for anime models, but honestly I cannot see any difference. The only important thing is to use the same clip skip for training and sampling.


Style Transfer
The simple rule seems to be that we get better style transfer if the styles are better trained.
Although it is impossible to make any conclusion from a single image, dim 32/16 half alpha is clearly the winner here, followed by dim 32/16 5e-4.
Among the remaining ones LoRa and Dadaption are probably slightly better. This can be explained by the fact that they both train faster (LoRa has smaller dimension while Dadaption supposed uses larger learning rate) and thus the model just knows the styles better. However, the Dadaption LoHa completely fails at altering the style of Tilty, who only has anime screenshots in training set. After some tests I find this can be fixed by by weighting the prompts differently.

A Certain Theory on Lora Transfer
Inspired by the introduction of AnyLora and an experiment done by @Machi#8166. I decided to further investigate the influence of base model. It is worth noticing that you may get different results due to difference in dataset and hyperparameters, though I do believe the general trend should be preserved. However, I do get some result that is contradictory to what Machi observed. In particular, counterfeit does not seem to be a good base model to train on in my experiments. Now, let's dive in.
I only put jpgs below, I invite you to download pngs from https://huggingface.co/alea31415/LyCORIS-experiments/tree/main/generated_samples_0329 to check the details yourself
Setup
I used the default setup described earlier except that I set clip skip to 2 here to be coherent with what the creator of AnyLora suggests. I train on the following 15 models
- NAI
- AnyLora
- NeverEndingDream (NED)
- Counterfeit-V2.5
- Aom3a1
- Anything4.5
- ACertainty (AC)
- BP
- NMFSAN
- VBP2.2
- MyneFactoryBaseV1.0 (MFB)
- RacyMix
- PastelMix
- ChilloutMix
In addition to the above we test on the following models
- Mix-Pro-V3
- Fantasy Background
- Salt Mix
- nep (the model is not online anymore)
As we will see later, it seems that the above models can be roughly separate into the following groups
- Source (Ancestor) Models: NAI, AC
- Anything/Orange family: AOM, Anything, AnyLora, Counterfeit, NED
- Photorealistic: NeverEndingDream, ChilloutMix
- Pastel: RacyMix, PastelMix
- AC family: ACertainty, BP, NMFSAN (BP is trained from AC and NMFSAN is trained from BP)
- Outliers: the remaining ones, and notably MFB
Character Training
Most people who train characters want to be able to switch style by switching models. In this case you indeed want to use NAI, or otherwise the mysterious ACertainty
Anisphia

Tilty

Character training is mostly robust to model transfer. Nonetheless, if you pick models that are far away, such as MFB, or pastel-mix, to train on, the results could be much worse.
Of course you can have two characters in the same image as well.
Anisphia X Euphyllia

Style Training
In style training people may want to retain the styles when switching model but instead benefit from other components of the base model (such as more detailed background). Unfortunately, it seems that there is not a single go-to model for style training. The general trend is, you get better style preservation if the two models are close enough, and in particular if they are in the same group described above. This is actually already clear with the anime styles in the previous images. Let us check some more specific examples.
ke-ta

onono imoko

A lot of people like to use models of the orange and anything series. In this case, as claimed AnyLora can indeed be a good base model for style training. However, training on Anything, AOM, or even NED could also be more or less effective.
It is also worth noticing that while training on PastelMix and RacyMix give bad results on other models in general, they allow for style to be preserved on each other. Finally, training on ChilloutMix can kill the photo-realistic style of NED and vice versa.
Why?
While a thorough explanation on how the model transfers would require much more investigation, I think one way to explain this is by considering the "style vector" pointing to every single model. When training on a merge of various models, these style vectors get corrected or compensated so the style is retained when switching to these closely related models. On the other hand, the source model is unaware of these style vectors. After training on it and transferring to another model the style vectors are added and we indeed recover the style of the new base model.
A Case Study on AC family
It is known that BP is trained from AC and NMFSAN is trained from BP, so this provides a good test case on how this affects the final result. According to the above theory, training on upstream model helps more get the style of downstream model, and this seems to be indeed the case.
We get more fkey style on nmfsan with the LoHa trained on AC (and not with the LoHa trained on nmfsan)

Same for shion

On the other hand, styles trained into LoHas would be less effective if applying from downstream models to upstream model, because what they need to achieve that may be much less than what the upstream model would need. We can also observe in early examples that LoHas trained on AnyLora can give bad result on NAI.


Implication for Making Cosplay Images
To summarize, if you want to have style of some model X, instead of training directly on X it would be better to train on an ancestor of X that does not contain this style.
Therefore, if you want to get cosplay of characters, you can do either of the following
- Train on NED and add a decent amount of photos in regularization set
- Train on NAI and transfer to NED
Lykon did show some successful results by only training with anime images on NED, but I doubt this is really optimal. Actually, he uses again a doll LoRa to reinforce the photo-realistic concept. It may be simper to just do what I suggest above.
For illustration, here is what we get by applying the LoHas trained on different base models on NeverEndingDream. As we can see, the one trained on NAI retains the most photo-realistic style (of course you can always adjusting various weight to improve things but I still get the best result with the one trained on NAI).

Some Myths
Clearly, the thing that really matters is how the model is made, and not how the model looks like. A model that is versatile in style does not make it a good base model for whatever kind of training. In fact, VBP2-2 has around 300 styles trained in but LoHa trained on top of it does not transfer well to other models.
Similarly, two models that produce similar style do not mean they transfer well to each other. Both MFB and Salt-Mix have strong anime screenshot style but a LoHa trained on MFB does not transfer well to Salt-Mix.
A Case Study on Customized Merge Model
To understand whether you can train a style to be used on a group of models by simply merging these models, I pick a few models and merge them myself to see if this is really effective. I especially choose models that are far from each other, and consider both average and add difference merges. Here are the two recipes that I use.
# Recipe for average merge
tmp1 = nai-full-pruned + bp_nman_e29, 0.5, fp16, ckpt
tmp2 = __O1__ + nep, 0.333, fp16, ckpt
tmp3 = __O2__ + Pastel-Mix, 0.25, fp16, ckpt
tmp4 = __O3__ + fantasyBackground_v10PrunedFp16, 0.2, fp16, ckpt
tmp5 = __O4__ + MyneFactoryBase_V1.0, 0.166, fp16, ckpt
AleaMix = __O5__ + anylora_FTMSE, 0.142, fp16, ckpt
# Recipe for add difference merge
tmp1 = nai-full-pruned + bp_nman_e29, 0.5, fp16, ckpt
tmp2-ad = __O1__ + nep + nai-full-pruned, 0.5, fp16, safetensors
tmp3-ad = __O2__ + Pastel-Mix + nai-full-pruned, 0.5, fp16, safetensors
tmp4-ad = __O3__ + fantasyBackground_v10PrunedFp16 + nai-full-pruned, 0.5, fp16, safetensors
tmp5-ad = __O4__ + MyneFactoryBase_V1.0 + nai-full-pruned, 0.5, fp16, safetensors
AleaMix-ad = __O5__ + anylora_FTMSE + nai-full-pruned, 0.5, fp16, safetensors
I then trained on top of tmp3, AleaMix, tmp3-ad, and AleaMix-ad. It turns out that these models are too different so it does not work very well. Getting style transfer to PastelMix and FantasyBackgrond are quite difficult. I however observe the following.
- We generally get bad results when applying to NAI. This is in line with previous experiments.
- We get better transfer to NMFSAN compared to most of previous LoHas that are not trained on BP family.
- Add difference with too many models (7) with high weight (0.5) blows the model up: you can still train on it and get reasonable result but it does not transfer to individual component.
- Add difference with a smaller number of models (4) can work. It seems to be more effective then simple average sometimes (note that how the model trained on tmp3-ad manages to cancel out the style of nep and PastelMix in the examples below).



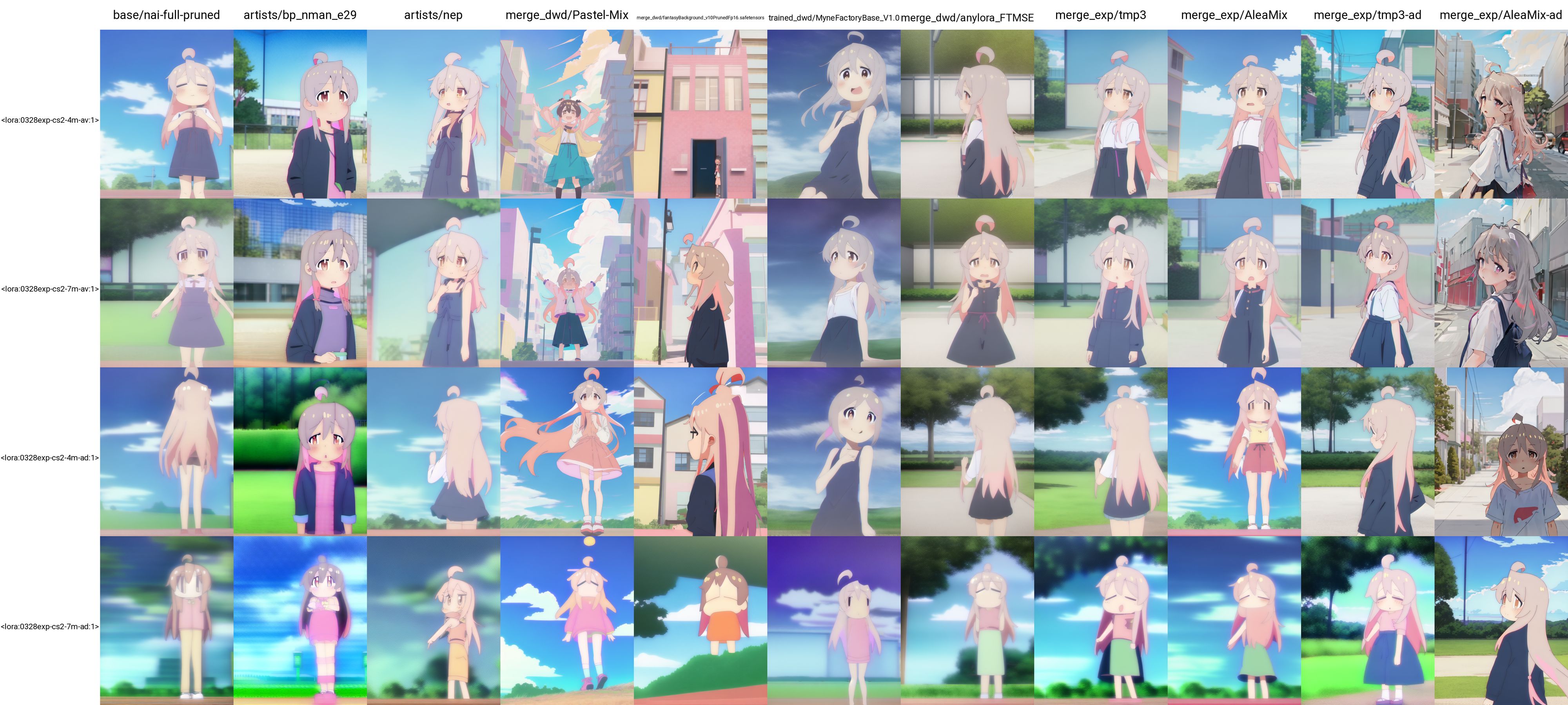

An interesting observation
While the model AleaMix-ad is barely usable, the LoHa trained on it produces very strong styles and excellent details
Results on AleaMix (the weighted sum version)

Results on AleaMix-ad (the add difference version)
However, you may also need to worry about some bad hand in such a model

A Case Study on Training on vanilla SD Model
Someone may believe that training on vanilla SD model would give better result. I however not advice it for anime training because you can hardly make your model usable with a small dataset. In turn you get a model that does not understand booru tags and often produces bad anatomy and bad hands.
Moreover, as we see below, all the vanilla SD models are so far away from NAI that even character cannot be transfer. It would only transfer to more photo-realistic model such as ChilloutMix (as they have a more important vanilla SD component) but this kills their photo-realistic style and make something terrible so this really there is really no interests in so doing in general.
The trend we see here is also coherent as what we have observed so far
- When training on vanilla SD and applying to descendant model we get mostly the style of descendant model
- The only exception is ChilloutMix for which it becomes less photo-realistic, which makes sense because it is much closer to vanilla SD
- Training on NAI and applying to vanilla SD gives a diluted anime style or no style at all



Training Speed
It is also suggested that you train faster on AnyLora. I try to look into this in several ways but I don't see a clear difference.
Note that we should mostly focus on the diagonal (LoHa applied on the model used to train it).
First, I use the 6000step checkpoints for characters

I do not see big difference between models of the same group. In the Tilty example I even see training on NAI, BP, and NMFSAN seems to be faster, but this is only one seed.
I move on to check the 10000step checkpoints for styles

Again there is no big difference here.
Finally I use the final checkpoint and set the weight to 0.65 as suggested by Lykon.



The only thing that I observed is that VBP2.2 seems to fit a bit quicker on the styles I test here, but it is probably because it is already trained on them (although under a different triggering mechanism as VBP2.2 is trained with embedding).
Going further
What are some good base models for "using" style LoRas
In the above experiments, it seems that some good candidates that express well the trained styles are
- VBP2.2
- Mix-Pro-V3
- Counterfeit
What else
Using different base model can affect things in many other ways, such as the quality or the flexibility of the resulting LoRa. These are however very different to evaluate. I invite you to try the LoHas I trained here to see how they differ in this aspects.
A style transfer example

Dataset
Here is the composition of the dataset
17_characters~fanart~OyamaMihari: 53
19_characters~fanart~OyamaMahiro+OyamaMihari: 47
1_artists~kantoku: 2190
24_characters~fanart~Anisphia: 37
28_characters~screenshots~Anisphia+Tilty: 24
2_artists~ke-ta: 738
2_artists~momoko: 762
2_characters~screenshots~Euphyllia: 235
3_characters~fanart~OyamaMahiro: 299
3_characters~screenshots~Anisphia: 217
3_characters~screenshots~OyamaMahiro: 210
3_characters~screenshots~OyamaMahiro+OyamaMihari: 199
3_characters~screenshots~OyamaMihari: 177
4_characters~screenshots~Anisphia+Euphyllia: 165
57_characters~fanart~Euphyllia: 16
5_artists~mochizuki_kei: 426
5_artists~onono_imoko: 373
7_characters~screenshots~Tilty: 95
9_characters~fanart~Anisphia+Euphyllia: 97