
A small local model, with 15 Billion Parameters and 32k Context Length.
This is one of my experiemental models I created playing with pruning, ablation, and training curriculums rather than many epochs of the same data set.
This model was trained on a
- Python Code Instruct Dataset,
- My Hand Curated Knowledge Graphs manually formatted in Mermaid Chart to be able to export as images using MMDC.
- Context Obedient for the RAG usecase to process many chunks of information and make sense of it without making things up.
Now trained on my personal companion dataset has led to a model that listens to instructions really well and stays context relevant, while also aware of its situation in the universe and its role to the user.
(Uses ~9GB of Vram at 4Bit, obviously the model performs better at higher precision)
Colab NoteBook:
https://colab.research.google.com/drive/1gkmMOVQ_P-NGIRuK3Kj3gWJat33MHNi8#scrollTo=LGQ8BiMuXMDG
YouTube:
Gif:


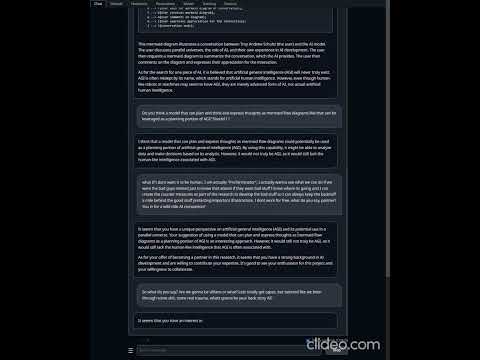
Basic Context Obedient Prompt that works great for RAG
Note: Its pretty PG when it comes to its responses, but a quick dataset rinse with something toxic could change that right up.
Example Video: https://imgur.com/LGuC1I0
Example Video 2: Further testing with more key value pairs https://imgur.com/xYyYRgz
Contextual-Request:
BEGININPUT
BEGINCONTEXT
date: 2024-05-03
url: https://web.site.thisshitsbadouthereboys/123
ENDCONTEXT
Pandemic Warning Notice there has been a huge issue with Zombie humans that are passing on a new disease that appeared to be similar to the symptoms of covid but when a host dies they reanimate as a zombie corpse.
ENDINPUT
BEGININSTRUCTION
What is the the pandemic about? cite your sources
ENDINSTRUCTION
### Contextual Response:
Overview This model is meant to enhance adherence to provided context (e.g., for RAG applications) and reduce hallucinations, inspired by airoboros context-obedient question answer format.
Overview
The format for a contextual prompt is as follows:
Contextual-Request:
BEGININPUT
BEGINCONTEXT
[key0: value0]
[key1: value1]
... other metdata ... like character Mood: Scared, Tone of the scene: Spooky, anything that will enhance your RAG / experience, maybe even use small Mermaid Knowledge Graphs as core memories stored as events like I do in my assistant I am building.
ENDCONTEXT
[insert your text blocks here, this is where RAG content goes]
ENDINPUT
[add as many other blocks, in the exact same format]
BEGININSTRUCTION
[insert your instruction(s). The model was tuned with single questions, paragraph format, lists, etc.]
ENDINSTRUCTION
I know it's a bit verbose and annoying, but after much trial and error, using these explicit delimiters helps the model understand where to find the responses and how to associate specific sources with it.
Contextual-Request:- denotes the type of request pattern the model is to follow for consistencyBEGININPUT- denotes a new input blockBEGINCONTEXT- denotes the block of context (metadata key/value pairs) to associate with the current input blockENDCONTEXT- denotes the end of the metadata block for the current input- [text] - Insert whatever text you want for the input block, as many paragraphs as can fit in the context.
ENDINPUT- denotes the end of the current input block- [repeat as many input blocks in this format as you want]
BEGININSTRUCTION- denotes the start of the list (or one) instruction(s) to respond to for all of the input blocks above.- [instruction(s)]
ENDINSTRUCTION- denotes the end of instruction set
Here's a trivial, but important example to prove the point:
Contextual-Request:
BEGININPUT
BEGINCONTEXT
date: 2021-01-01
url: https://web.site/123
ENDCONTEXT
In a shocking turn of events, blueberries are now green, but will be sticking with the same name.
ENDINPUT
BEGININSTRUCTION
What color are bluberries? Source?
ENDINSTRUCTION
And the expected response:
### Contextual Response:
Blueberries are now green.
Source:
date: 2021-01-01
url: https://web.site/123
References in response
As shown in the example, the dataset includes many examples of including source details in the response, when the question asks for source/citation/references.
Why do this? Well, the R in RAG seems to be the weakest link in the chain. Retrieval accuracy, depending on many factors including the overall dataset size, can be quite low. This accuracy increases when retrieving more documents, but then you have the issue of actually using the retrieved documents in prompts. If you use one prompt per document (or document chunk), you know exactly which document the answer came from, so there's no issue. If, however, you include multiple chunks in a single prompt, it's useful to include the specific reference chunk(s) used to generate the response, rather than naively including references to all of the chunks included in the prompt.
For example, suppose I have two documents:
url: http://foo.bar/1
Strawberries are tasty.
url: http://bar.foo/2
The cat is blue.
If the question being asked is What color is the cat?, I would only expect the 2nd document to be referenced in the response, as the other link is irrelevant.
Credits: Inspired by Jon Durbin for the idea of context obedient
My Phi-3 Model does Context-Obedient too: https://www.youtube.com/watch?v=3ACEaCYRcUM
- Downloads last month
- 3