
Model Card for SilverAudio
Model Details
- The audio model is a critical component of the
SilverAssistantsystem, designed to detect potentially dangerous situations such as falls, cries for help, or signs of violence through audio analysis. Its primary purpose is to enhance user safety while respecting privacy. - By leveraging Mel-Frequency Cepstral Coefficients (MFCC) for feature extraction and Convolutional Neural Networks (CNN) for classification, the model ensures accurate detection without requiring constant video monitoring, preserving user privacy.
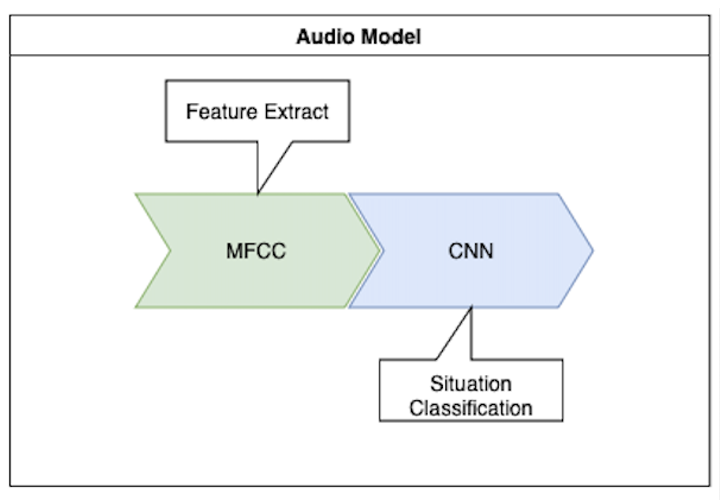

Model Description
- Activity with: NIPA-Google(2024.10.23-20224.11.08), Kosa Hackathon(2024.12.9)
- Model type: Audio CNN Model
- API used: Keras
- Dataset: HuggingFace Silver-Audio-Dataset
- Code: GitHub Silver Model Code
- Language(s) (NLP): Korean
Training Details
Dataset Preperation
- HuggingFace: HuggingFace Silver-Audio-Dataset
- Description:
- The dataset used for this audio model consists of
.npyfiles containing MFCC features extracted from raw audio recordings. These recordings include various real-world scenarios, such as:- Criminal activities
- Violence
- Falls
- Cries for help
- Normal indoor sounds
- The dataset used for this audio model consists of
Model Details
- Model Structure:
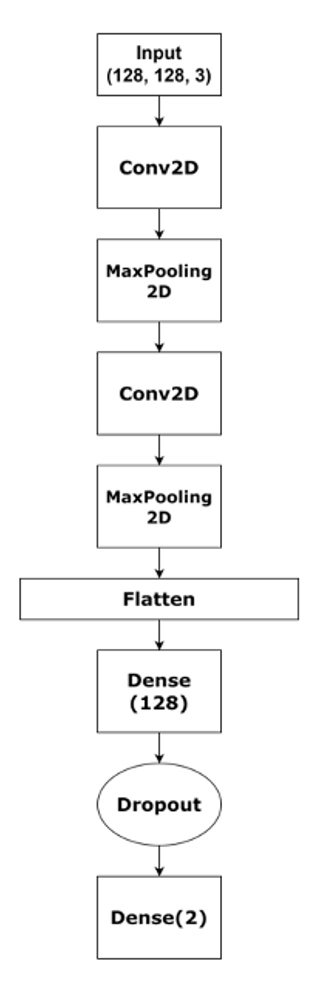
- Input Layer
- Shape: (128, 128, 3)
- Represents the input MFCC features reshaped into a 128x128 image-like format with 3 channels (RGB)
- This transformation helps the CNN process MFCC features as spatial data.
- Convolutional Layers (Conv2D)
- First Conv2D Layer:
- Extracts low-level features from the MFCC input (e.g., frequency characteristics).
- Applies filters (kernels) to create feature maps by learning patterns in the audio data.
- Second Conv2D Layer:
- Further processes the feature maps, learning more complex and hierarchical audio features.
- First Conv2D Layer:
- MaxPooling2D Layers
- Located after each Conv2D layer.
- Reduces the spatial dimensions of feature maps, lowering computational complexity and extracting dominant features.
- Helps in preventing overfitting by reducing noise and irrelevant details.
- Flatten Layer
- Converts the 2D feature maps into a 1D vector.
- Prepares the data for the dense (fully connected) layers, which act as the classifier.
- Fully Connected Layers (Dense)
- First Dense Layer:
- Contains 128 neurons.
- Processes the flattened features to learn complex relationships in the data.
- Dropout Layer:
- Randomly sets a fraction of input neurons to zero during training.
- Helps in regularization, preventing overfitting by ensuring the model doesn’t rely on specific neurons.
- Output Dense Layer:
- Neurons: 2 (for binary classification)
- Class 0: Normal
- Class 1: Danger
- Activation: Softmax (to output probabilities for each class).
- Neurons: 2 (for binary classification)
- First Dense Layer:
- Input Layer
- Model Performance:
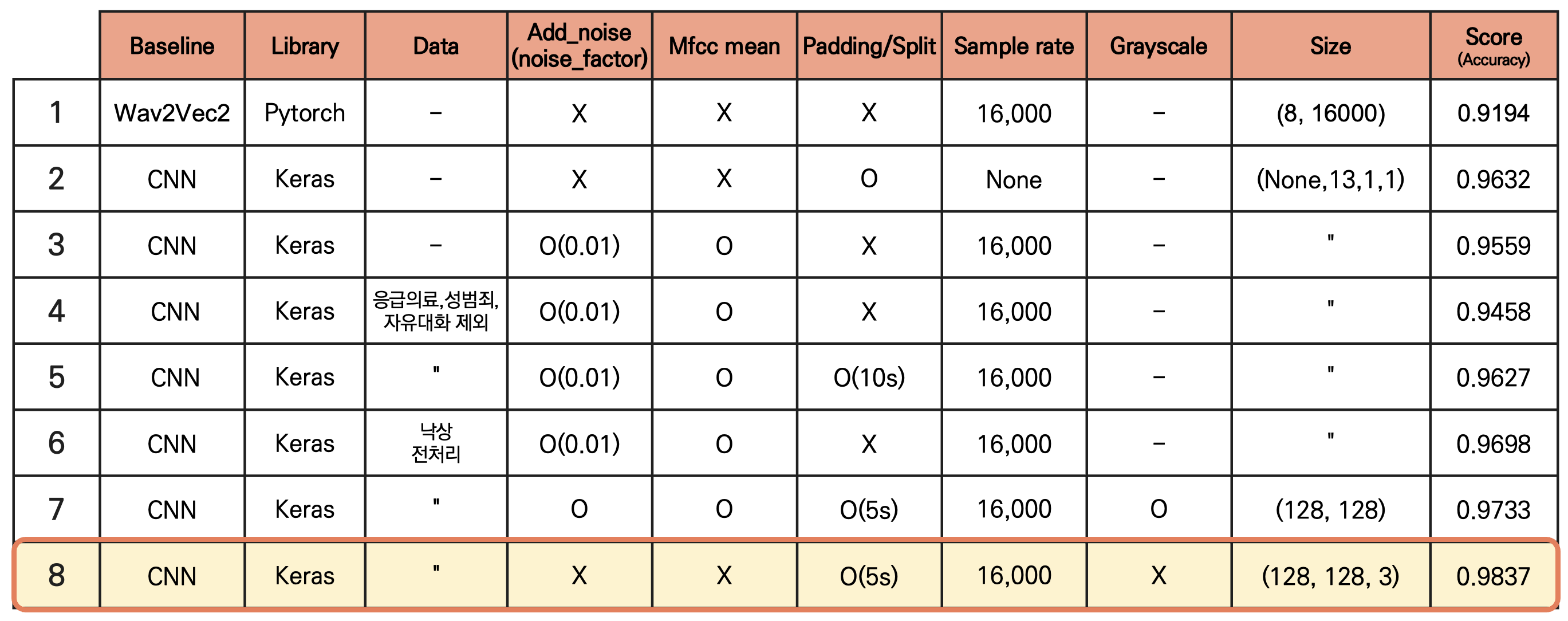
- Accuracy and Preprocessing (Table Summary)
- The CNN model achieves the highest accuracy of 98.37% in the 8th configuration.
- Key factors contributing to this performance:
- Input Size: 128 \times 128 \times 3, leveraging image-like MFCC features.
- Padding/Splitting: Audio segments are preprocessed into 5-second splits, ensuring uniform input.
- No Noise Addition: Training without additional noise leads to better feature retention.
- Library: Keras is used for training and architecture implementation.
- Sample Rate: A consistent sample rate of 16,000 Hz was maintained for all preprocessing steps.
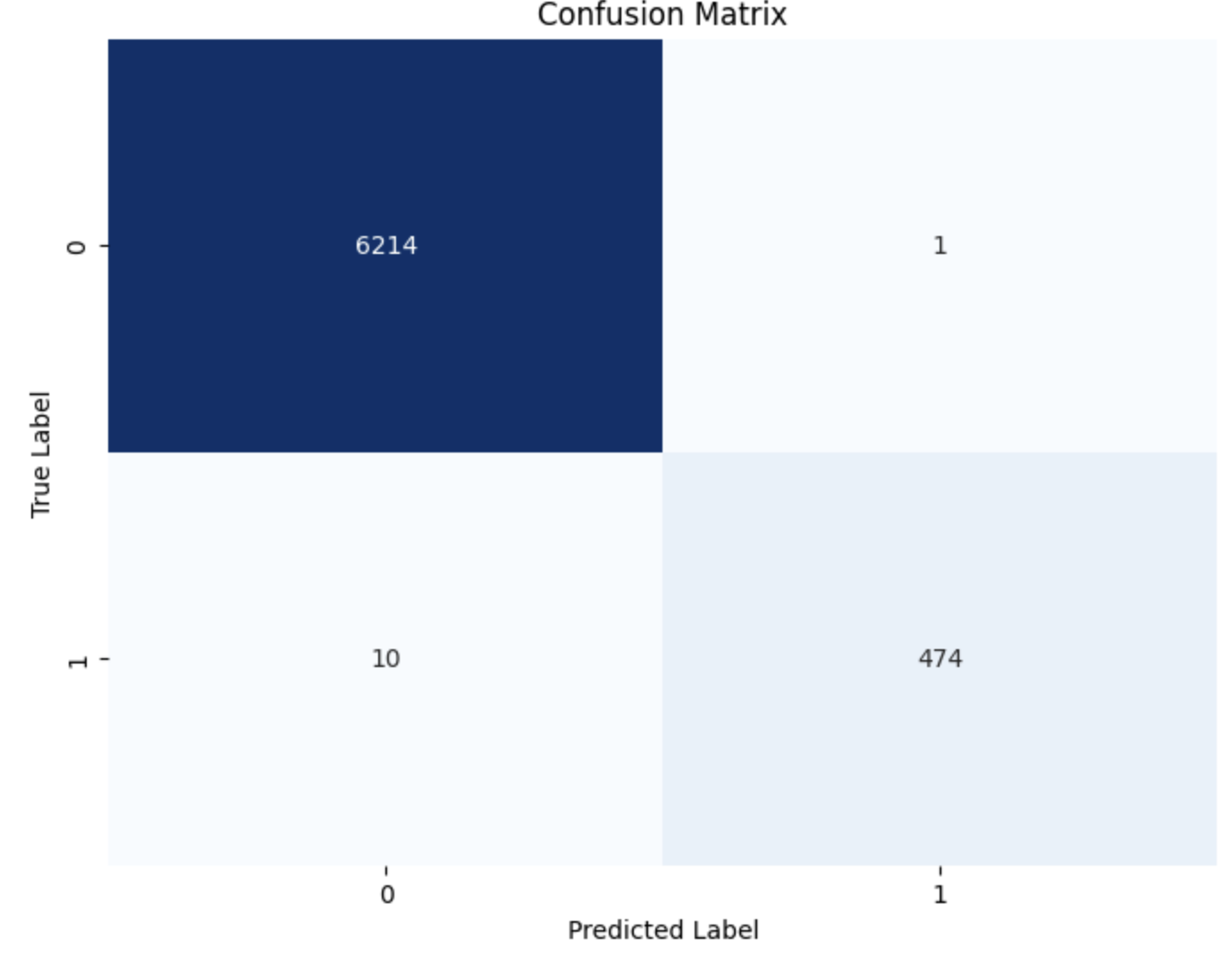
- Confusion Matrix Analysis
- High Precision: Minimal false positives suggest the model is very specific when identifying emergencies.
- High Recall: Minimal false negatives indicate that most emergencies are correctly identified.
- Accuracy and Preprocessing (Table Summary)



Model Usage
Silver AssistantProject- The audio model is a critical component of the SilverAssistant system, designed to detect potentially dangerous situations such as falls, cries for help, or signs of violence through audio analysis. Its primary purpose is to enhance user safety while respecting privacy.
- GitHub SilverAvocado
Conclusion
- The
SilverAudiomodel demonstrates exceptional performance in detecting emergency audio scenarios with high accuracy and reliability, achieving a peak accuracy of 98.37% in the 8th configuration. By leveraging MFCC features and a robust CNN-based architecture, the model effectively classifies audio inputs into predefined categories (normal vs danger). Its ability to operate on preprocessed.npyfiles ensures efficient inference, making it suitable for real-time applications. - This model is a vital component of the
SilverAssistantproject, empowering the system to accurately detect critical situations and enable timely interventions. Its real-world applicability, achieved through comprehensive training on diverse datasets such as AI Hub, makes it a powerful tool for enhancing the safety and well-being of vulnerable individuals, particularly the elderly.