
finetune_starcoder2
This model is a fine-tuned version of bigcode/starcoder2-3b on bigcode/the-stack-smol.
Model description
This fine-tuned model builds upon the bigcode/starcoder2-3b base model, further specializing it for code completion tasks using the bigcode/the-stack-smol dataset on SQL data. This dataset focuses on code snippets and solutions, allowing the model to suggest relevant completions and potentially even generate code based on your prompts.
Intended uses & limitations
This Text-to-SQL generator is designed to bridge the gap between users and databases. Here are some of its key intended uses:
- Non-programmers interacting with databases: Users who are unfamiliar with writing SQL queries can leverage this tool to ask questions about the database in natural language and get the corresponding SQL query generated. This allows them to access and analyze data without needing programming expertise.
- Data exploration and analysis: Analysts or researchers can use the Text-to-SQL generator to quickly formulate queries for exploratory data analysis. It can save time by automatically generating basic SQL queries, allowing users to focus on refining their questions and interpreting the results.
- Automating repetitive tasks: For tasks requiring frequent execution of similar SQL queries based on changing parameters, the Text-to-SQL generator can automate the process of generating the queries. This can improve efficiency and reduce errors.
- Learning SQL: Beginners can use the Text-to-SQL generator to experiment with natural language prompts and see the corresponding SQL queries. This can be a helpful tool for understanding the relationship between natural language and SQL syntax, aiding in learning the basics of SQL.
Limitations of the Text-to-SQL Generator
While this tool offers a convenient way to generate SQL queries, it's important to be aware of its limitations:
- Complexity: The Text-to-SQL generator might struggle with highly complex queries involving advanced SQL features (e.g., joins with multiple conditions, subqueries). It's best suited for simpler queries that can be expressed in natural language.
- Accuracy: The generated SQL queries might not always be perfect. The model might misinterpret the user's intent or generate syntactically incorrect queries. It's crucial to review and potentially edit the generated SQL before running it on the database.
- Domain-specific knowledge: The Text-to-SQL generator might not understand the specific terminology or structure of your database. If your database schema or data contains domain-specific terms, you might need to adjust the natural language prompts to ensure accurate query generation.
- Security: It's important to be cautious when using the Text-to-SQL generator with sensitive data. Ensure the tool doesn't introduce security vulnerabilities by generating unintended queries or exposing sensitive information.
Training and evaluation data
More information needed
Training procedure
1. Load Dataset and Model:
- Load the
bigcode/the-stack-smoldataset using the Hugging Face Datasets library. - Filter for the specified subset (
data/sql) and split (train). - Load the
bigcode/starcoder2-3bmodel from the Hugging Face Hub with '4-bit' quantization.
2. Preprocess Data:
- Tokenize the code text using the appropriate tokenizer for the chosen model.
- Apply necessary cleaning or normalization (e.g., removing comments, handling indentation).
- Create input examples suitable for the model's architecture (e.g., with masked language modeling objectives).
3. Configure Training:
- Initialize a Trainer object (likely from a library like Transformers).
- Set training arguments based on the provided
args:- Learning rate, optimizer, scheduler
- Gradient accumulation steps
- Weight decay
- Loss function (likely cross-entropy)
- Evaluation metrics (e.g., accuracy, perplexity)
- Device placement (GPU/TPU)
- Number of processes for potential distributed training
4. Train the Model:
- Start the training loop for the specified
max_steps. - Iterate through batches of preprocessed code examples.
- Forward pass through the model to generate predictions.
- Calculate loss based on ground truth and predictions.
- Backpropagate gradients to update model parameters.
5. Evaluation (Optional):
- Periodically evaluate model performance on a validation or test set.
- Calculate relevant metrics (accuracy, perplexity, code completion accuracy).
- Monitor training progress and adjust hyperparameters as needed.
6. Save the Fine-tuned Model:
- Save the model's weights and configuration to the
output_dir.
7. Push to Hugging Face Hub (Optional):
- If
push_to_hubis True, create a model card and push the model to Hugging Face Hub for sharing and use.
Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 1
- eval_batch_size: 8
- seed: 0
- gradient_accumulation_steps: 4
- total_train_batch_size: 4
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 100
- training_steps: 1000
- mixed_precision_training: Native AMP
Training results
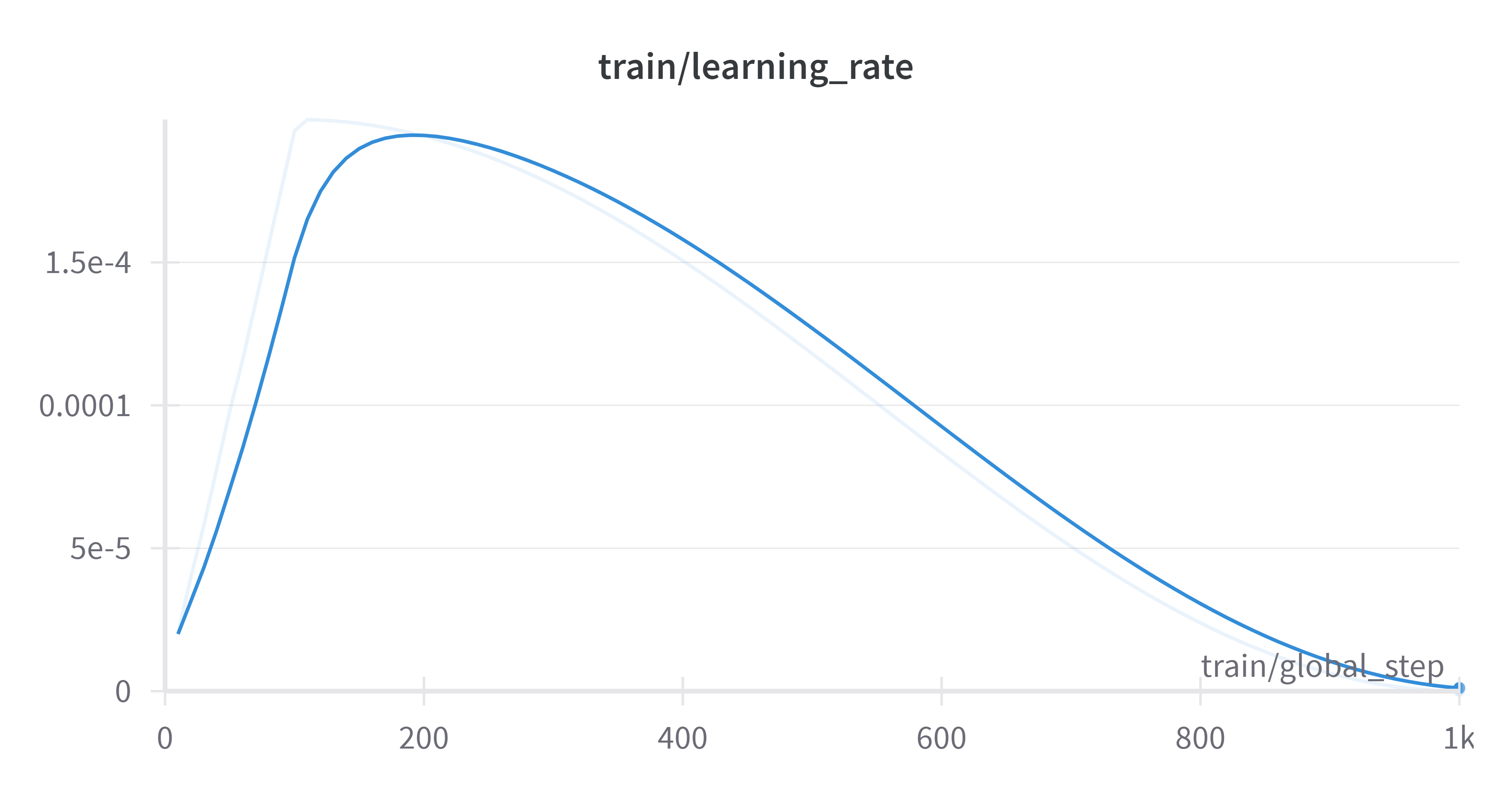
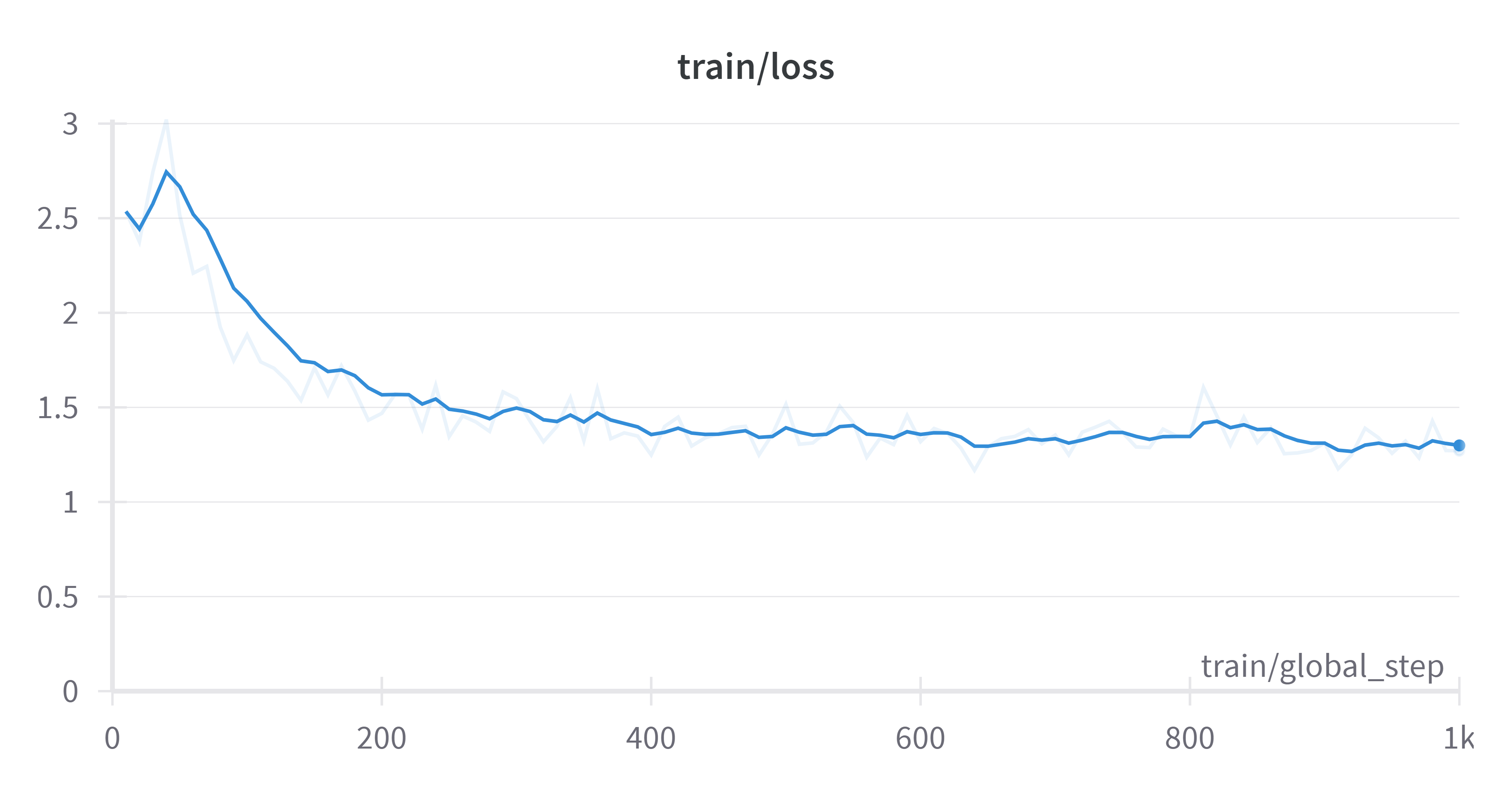
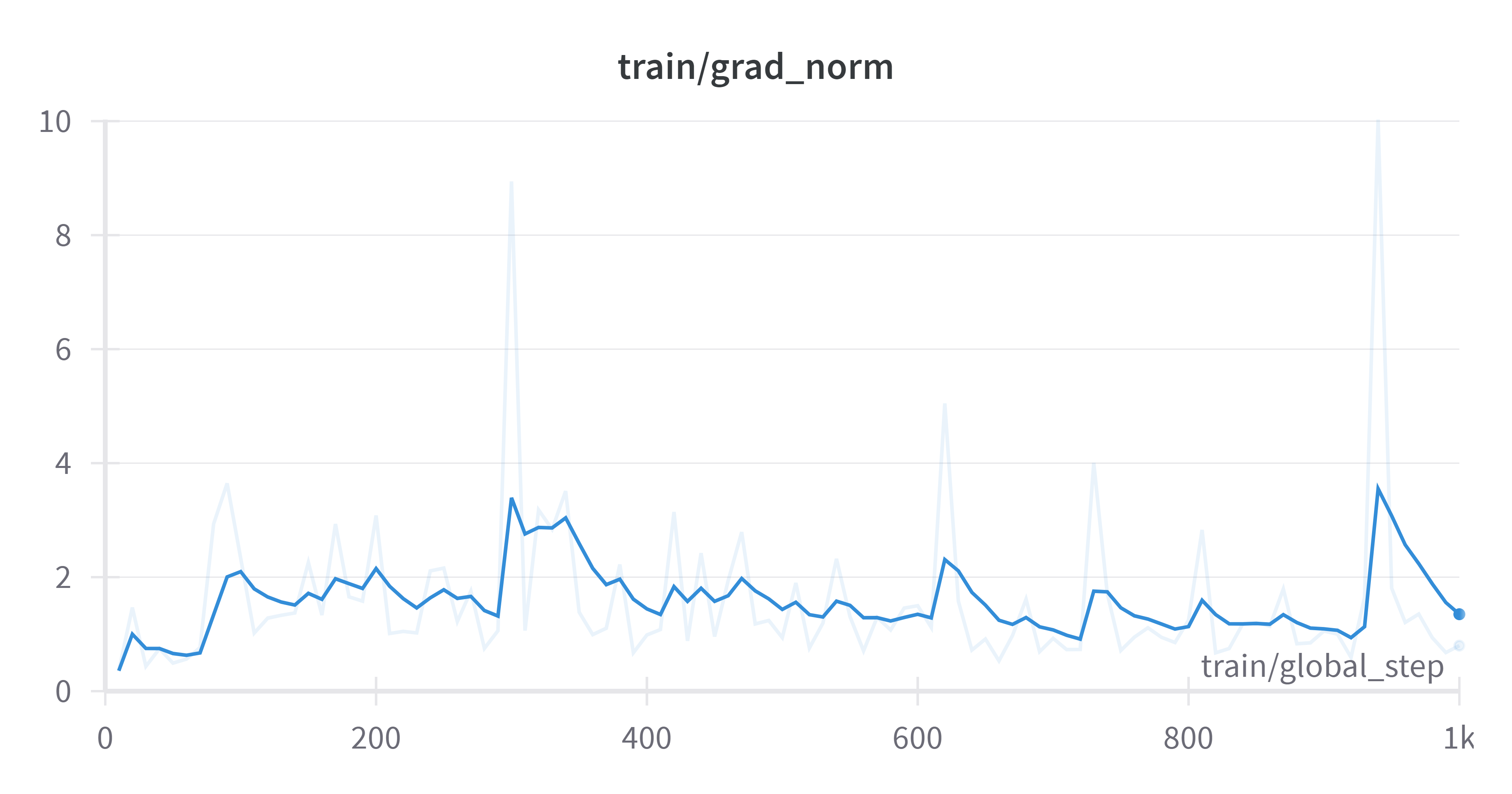

Framework versions
- PEFT 0.8.2
- Transformers 4.40.0.dev0
- Pytorch 2.2.1+cu121
- Datasets 2.18.0
- Tokenizers 0.15.2
- Downloads last month
- 12
Model tree for Sayan18/finetune_starcoder2
Base model
bigcode/starcoder2-3b