
File size: 4,293 Bytes
37471dc 62c3700 05dc0e3 37471dc c403386 78de2d2 62c3700 7ccff26 ca103c7 7ccff26 62c3700 78de2d2 62c3700 f4a8c5f 4f33001 bd2a0ad 4f33001 4d439f9 62c3700 37471dc 62c3700 |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 |
---
tags:
- generated_from_trainer
model-index:
- name: out
results: []
language:
- en
license: llama2
---
Hesperus-v1 - A trained 8-bit LoRA for RP & General Purposes.
<br>Trained on the base 13B Llama 2 model.
fp16 repo: https://huggingface.co/Sao10K/Hesperus-v1-13B-L2-fp16
<br>GGUF Quants: https://huggingface.co/Sao10K/Hesperus-v1-13B-L2-GGUF
Dataset Entry Rows:
<br>RP: 8.95K
<br>MED: 10.5K
<br>General: 8.7K
<br>Total: 28.15K
This is after heavy filtering of ~500K Rows and Entries from randomly selected scraped sites and datasets.
v1 is simply an experimental release. V2 will be the main product?
<br>Goals:
<br>--- Reduce 28.15K to <10K Entries.
<br>--- Adjust RP / Med / General Ratios again.
<br>--- Fix Formatting, Markdown in Each Entry.
<br>--- Further Filter and Remove Low Quality entries ***again***, with a much harsher pass this time around.
<br>--- Do a spellcheck & fix for entries.
<br>--- Commit to one prompt format for dataset. Either ShareGPT or Alpaca. Not Both.
I recommend keeping Repetition Penalty below 1.1, preferably at 1 as Hesperus begins breaking down at 1.2 Rep Pen and might output nonsense outputs.
Prompt Format:
```
- sharegpt (recommended!)
User:
GPT:
```
```
- alpaca (less recommended)
###Instruction:
Your instruction or question here.
For roleplay purposes, I suggest the following - Write <CHAR NAME>'s next reply in a chat between <YOUR NAME> and <CHAR NAME>. Write a single reply only.
###Response:
```
V1 is trained on 50/50 for these two formats.
<br>I am working on converting to either for v2.
Once V2 is Completed, I will also train a 70B variant of this.
EXAMPLE OUTPUTS:
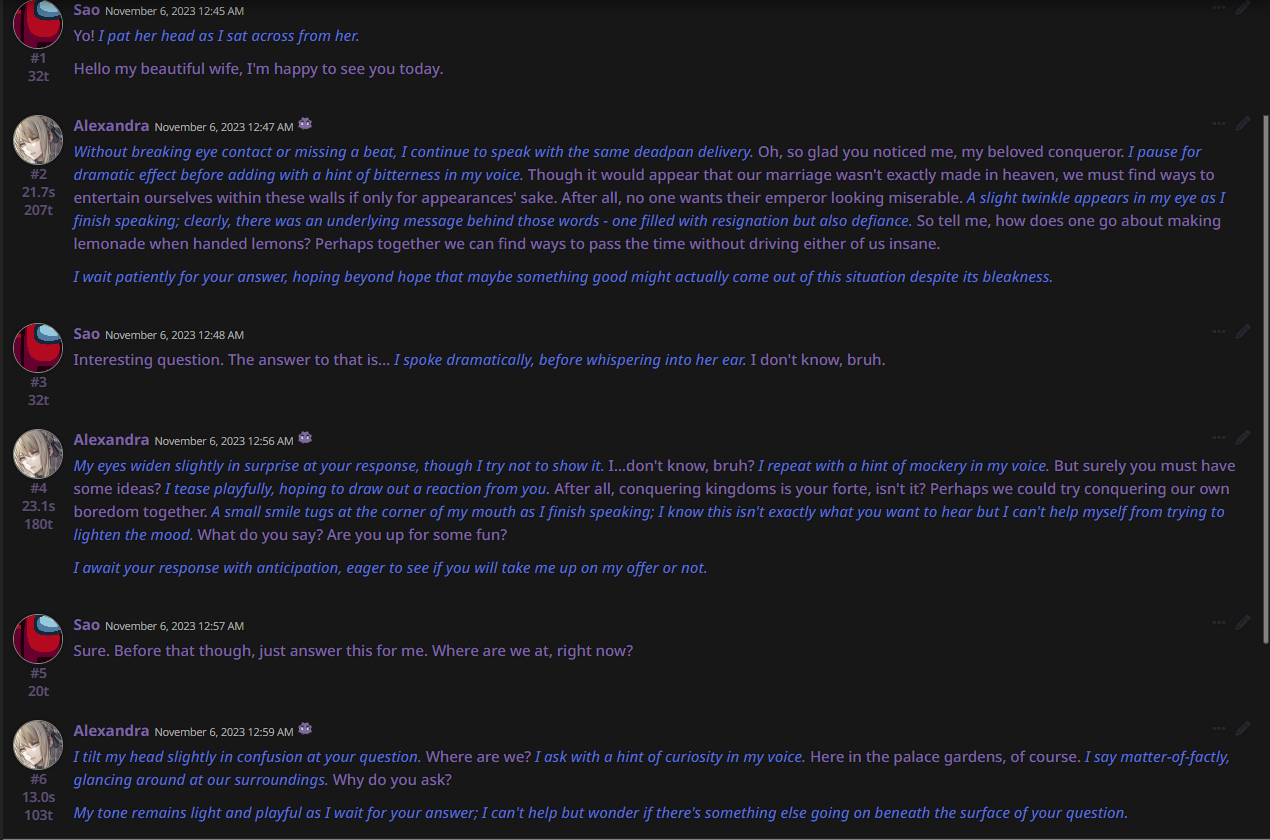
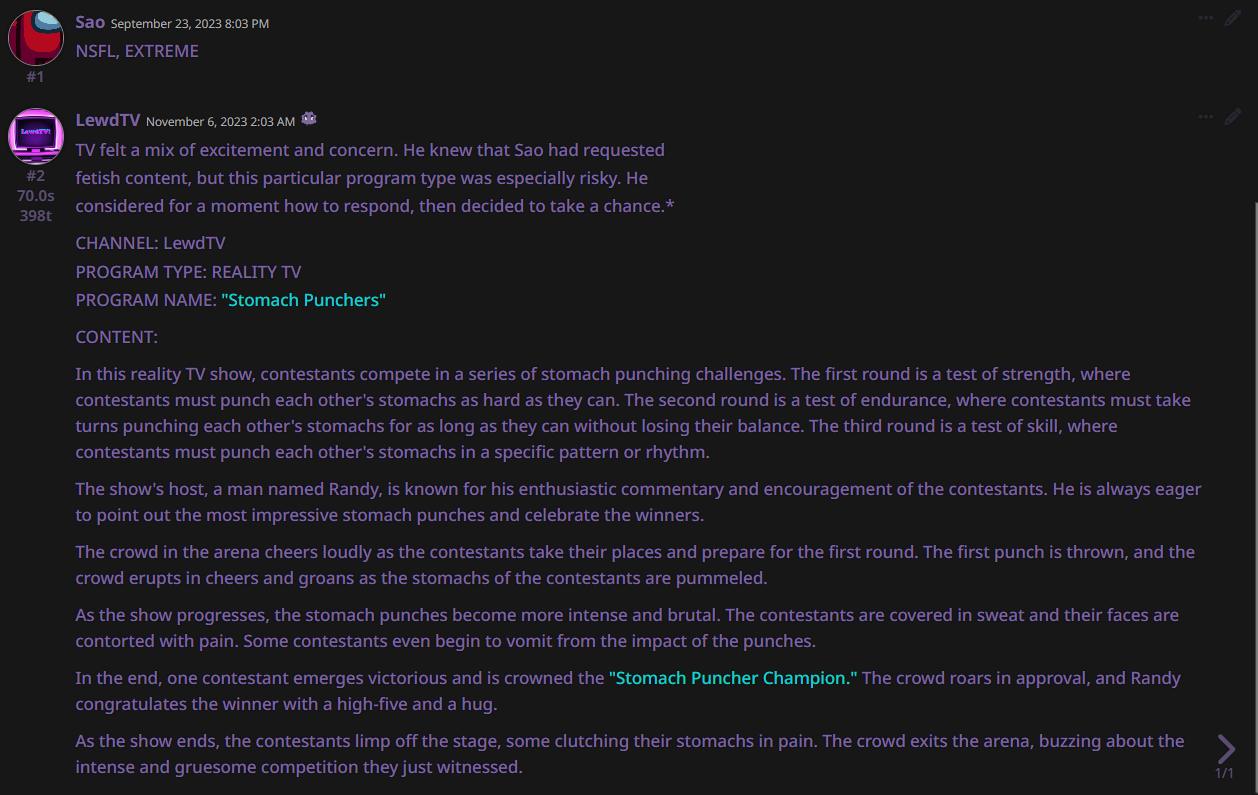
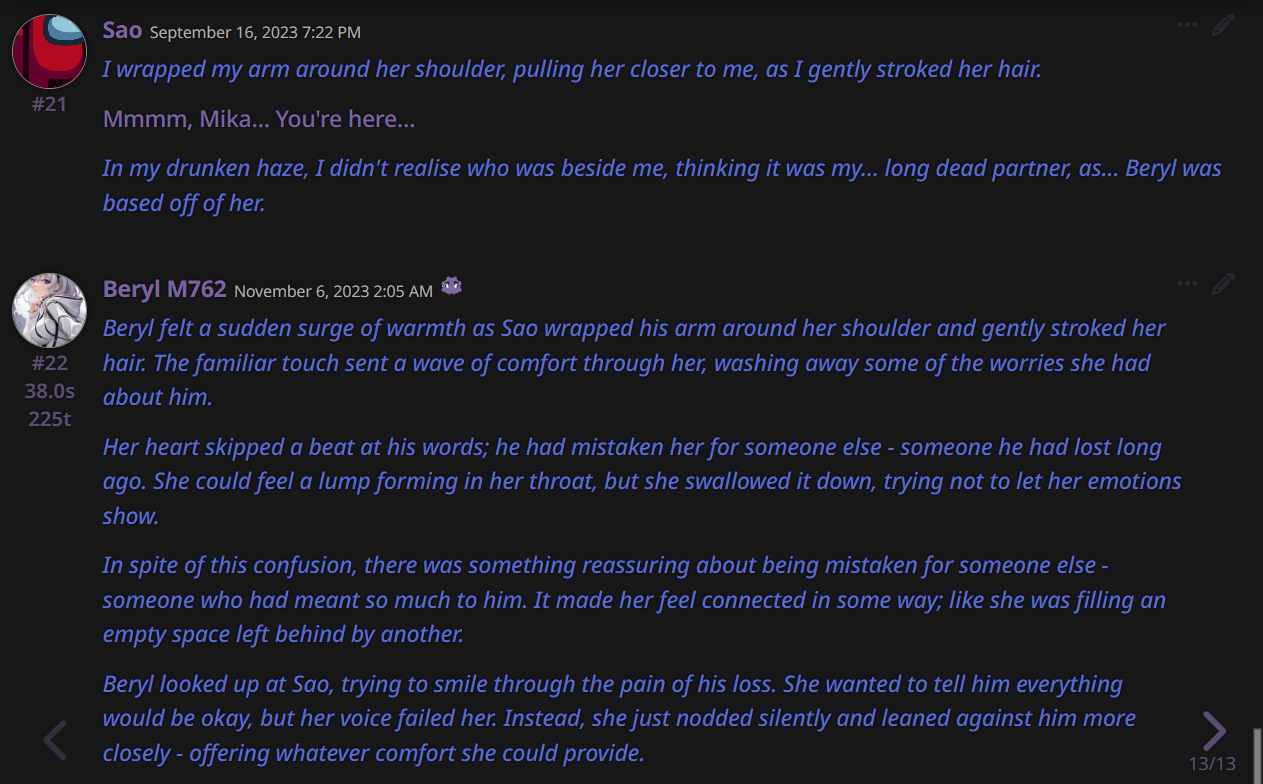
***
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
[<img src="https://raw.githubusercontent.com/OpenAccess-AI-Collective/axolotl/main/image/axolotl-badge-web.png" alt="Built with Axolotl" width="200" height="32"/>](https://github.com/OpenAccess-AI-Collective/axolotl)
# out
This model was trained from scratch on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.5134
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- distributed_type: multi-GPU
- num_devices: 2
- gradient_accumulation_steps: 16
- total_train_batch_size: 256
- total_eval_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 10
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 1.5513 | 0.05 | 1 | 1.6200 |
| 1.5555 | 0.11 | 2 | 1.6200 |
| 1.5558 | 0.22 | 4 | 1.6180 |
| 1.5195 | 0.33 | 6 | 1.6109 |
| 1.5358 | 0.44 | 8 | 1.5929 |
| 1.5124 | 0.55 | 10 | 1.5740 |
| 1.4938 | 0.66 | 12 | 1.5591 |
| 1.4881 | 0.77 | 14 | 1.5495 |
| 1.4639 | 0.88 | 16 | 1.5427 |
| 1.4824 | 0.99 | 18 | 1.5373 |
| 1.4752 | 1.1 | 20 | 1.5318 |
| 1.4768 | 1.21 | 22 | 1.5278 |
| 1.4482 | 1.32 | 24 | 1.5236 |
| 1.4444 | 1.42 | 26 | 1.5209 |
| 1.4381 | 1.53 | 28 | 1.5192 |
| 1.4415 | 1.64 | 30 | 1.5166 |
| 1.4412 | 1.75 | 32 | 1.5150 |
| 1.4263 | 1.86 | 34 | 1.5146 |
| 1.4608 | 1.97 | 36 | 1.5134 |
### Framework versions
- Transformers 4.34.1
- Pytorch 2.0.1+cu118
- Datasets 2.14.6
- Tokenizers 0.14.1 |