
Adding Evaluation Results
#1
by
leaderboard-pr-bot
- opened
README.md
CHANGED
|
@@ -1,15 +1,15 @@
|
|
| 1 |
---
|
| 2 |
-
|
|
|
|
|
|
|
| 3 |
tags:
|
| 4 |
- mistral
|
| 5 |
- chatml
|
| 6 |
- merge
|
|
|
|
| 7 |
model-index:
|
| 8 |
- name: Lelantos-7B
|
| 9 |
results: []
|
| 10 |
-
license: apache-2.0
|
| 11 |
-
language:
|
| 12 |
-
- en
|
| 13 |
---
|
| 14 |
|
| 15 |
# Lelantos - Mistral 7B
|
|
@@ -87,3 +87,17 @@ So far, I have only tested Lelantos on MT-Bench using the Hermes prompt and, boy
|
|
| 87 |
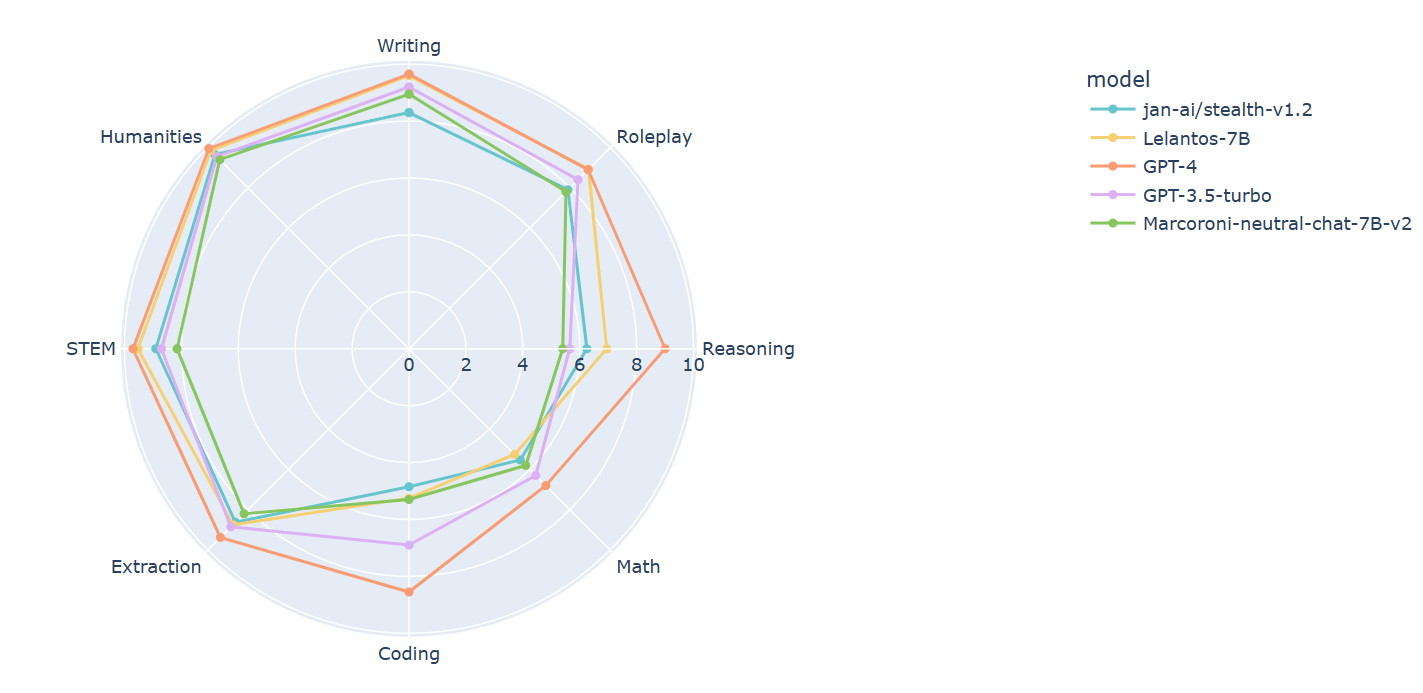
^1 xDAN's testing placed it 8.35 - this number is from my independent MT-Bench run.
|
| 88 |
|
| 89 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
---
|
| 2 |
+
language:
|
| 3 |
+
- en
|
| 4 |
+
license: apache-2.0
|
| 5 |
tags:
|
| 6 |
- mistral
|
| 7 |
- chatml
|
| 8 |
- merge
|
| 9 |
+
base_model: mistralai/Mistral-7B-v0.1
|
| 10 |
model-index:
|
| 11 |
- name: Lelantos-7B
|
| 12 |
results: []
|
|
|
|
|
|
|
|
|
|
| 13 |
---
|
| 14 |
|
| 15 |
# Lelantos - Mistral 7B
|
|
|
|
| 87 |
^1 xDAN's testing placed it 8.35 - this number is from my independent MT-Bench run.
|
| 88 |
|
| 89 |

|
| 90 |
+
|
| 91 |
+
# [Open LLM Leaderboard Evaluation Results](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)
|
| 92 |
+
Detailed results can be found [here](https://huggingface.co/datasets/open-llm-leaderboard/details_SanjiWatsuki__Lelantos-7B)
|
| 93 |
+
|
| 94 |
+
| Metric |Value|
|
| 95 |
+
|---------------------------------|----:|
|
| 96 |
+
|Avg. |72.78|
|
| 97 |
+
|AI2 Reasoning Challenge (25-Shot)|69.03|
|
| 98 |
+
|HellaSwag (10-Shot) |86.90|
|
| 99 |
+
|MMLU (5-Shot) |64.10|
|
| 100 |
+
|TruthfulQA (0-shot) |65.18|
|
| 101 |
+
|Winogrande (5-shot) |80.66|
|
| 102 |
+
|GSM8k (5-shot) |70.81|
|
| 103 |
+
|