
Flux Training Concept - Wonderman POC
Darin Holbrook - Chief Technology Officer
RunDiffusion.com /
contact@rundiffusion.com
Follow Us on X! Wonderman Demands!


- Prompt
- Wonderman wearing a black mask is a muscular man in a green and red costume with a 'W' emblem on his chest. He navigates through an ancient temple, carefully avoiding the booby traps set in the stone walls. His muscles are taut as he reaches for an artifact glowing on a pedestal, his face showing a mix of caution and determination. Dust fills the air as he steps closer, high-quality graphic art.

- Prompt
- An action scene of graphic novel art character Wonderman wearing a black mask charging himself with super powers, Wonderman a muscular man in a green and red costume with a 'W' emblem on his chest is screaming in pain while being charged by electricity to gain super powers. He is standing with arms wide open consuming the energy around him. high quality graphic art

- Prompt
- photo realistic still of Wonderman wearing a black mask is a muscular man in a green and red costume with a 'W' emblem on his chest. He stands on a frozen tundra, a blizzard raging around him. His body is covered in frost, but he shows no signs of slowing down as he pushes forward through the snow, his eyes focused on a distant mountain peak where an ancient power is hidden. photo

- Prompt
- Wonderman wearing a black mask is a muscular man in a green and red costume with a 'W' emblem on his chest. He is walking away from aliens on the moon, high-quality graphic art.

- Prompt
- A photo realistic comic book character Wonderman wearing a black mask fighting a villain. In the foreground, Wonderman a muscular man in a green and red costume with a 'W' emblem on his chest. The background depicts an action scene of all sorts of fighting characters and a dark, cloudy sky. This is a cinematic action scene that is photorealistic similar to cosplay. photograph

- Prompt
- Wonderman wearing a black mask is a muscular man in a green and red costume with a 'W' emblem on his chest. He sits in a quiet diner late at night. His mask is still on, but his posture is relaxed as he sips a cup of coffee, watching the rain fall outside. The city is peaceful for now, but Wonderman knows this calm won't last. Modern realistic art style with detailed shading and highlights and high contrast and vivid colors

- Prompt
- Wonderman in a black mask a muscular man in a green and red costume with a 'W' emblem on his chest—leaps from a crumbling skyscraper, dodging falling debris while holding a glowing energy sphere in his hand. His black mask is torn, but his face shows fierce determination as he hurls the sphere at an oncoming enemy ship. The sky is filled with smoke and fire from the battle, high-quality graphic art.

- Prompt
- photo realistic still of Wonderman wearing a black mask is a muscular man in a green and red costume with a 'W' emblem on his chest. He stands on a frozen tundra, a blizzard raging around him. His body is covered in frost, but he shows no signs of slowing down as he pushes forward through the snow, his eyes focused on a distant mountain peak where an ancient power is hidden. photo

- Prompt
- Wonderman wearing a black mask is a muscular man in a green and red costume with a 'W' emblem on his chest. He battles a pack of mutant wolves in an abandoned warehouse, his powerful strikes knocking them back one by one. The moonlight filters through broken windows, casting long shadows as Wonderman moves swiftly, his every motion precise and controlled, high-quality graphic art.

- Prompt
- Wonderman wearing a black mask is a muscular man in a green and red costume with a 'W' emblem on his chest. He crouches in a rain-soaked alley, muscles tense as thunder rumbles in the background. He grips his glowing energy staff, ready to confront a shadowy figure in the distance. The city lights flicker behind him, high-quality graphic art.

- Prompt
- photo of Wonderman wearing a black mask is a muscular man in a green and red costume with a 'W' emblem on his chest. He stands proudly in front of a massive explosion, framed in the golden hour's soft, warm lighting. His costume is brilliantly contrasted against the fiery background, with the photo perfectly timed to capture the intensity of the scene, high-resolution photograph.

- Prompt
- Wonderman wearing a black mask is a muscular man in a green and red costume with a 'W' emblem on his chest. In an action shot, Wonderman speeds through a crowded street, his figure tack sharp while the background is blurred with motion, capturing the sense of speed. The natural light creates a subtle lens flare on his mask in modern realistic art style with detailed shading and highlights and high contrast and vivid colors
Wonderman - By RunDiffusion.com
Project Overview
We successfully trained a concept into Flux that did not exist, it responded exceptionally well and the entire community should be excited to embrace this model. Over 100 hours went into this proof of concept and this guide. Please take time to go through it, share it online, with your friends/followers or your team and coworkers. All credit for Flux goes to the amazing team at Black Forest Labs. Please adhere to their license. They deserve your support. Follow RunDiffusion.com for more projects. We are diving into advertising next!
View the five part portal PDF Version of this guide here
Proof of Concept Goals
For this POC we needed to achieve these goals:
- The concept cannot exist in the Flux dataset. (This is cheating)
- The concept needed to be present but still allow flexibility for creativity.
- The concept needed to resemble the subject within 90% accuracy.
- The subject could not "take over" the model.
- We used the lowest quality data we could find. (This was easy!)
We chose Wonderman from 1947! Wonderman is in the public domain, so it can be freely shared, except where restricted by Flux's non-commercial license.
Flux thinks that "Wonderman" is "Superman"

Data Used for Training
You can view the RAW low quality data here:
The training data was low resolution, cropped, oddly shaped, pixelated, and overall the worst possible data we've come across. That didn't stop us! AI to the rescue!

Data Cleanup Strategy
To fix the data we had to:
- Inpaint problem areas like backgrounds, signatures, and text
- Outpaint to expand images
- Upscale to get above 1024x1024 at a minimum
- Create variations to increase the dataset and provide diverse data
We were able to get the dataset to 13 with these techniques.
Full dataset is here

Captioning the Data
We are not entirely familiar with Flux's preferred captioning style. We understand that this model responds will to full descriptive sentences so we went with that. Below are some examples of the images with their captions. We chose LLaMA v3 inspired by this paper: https://arxiv.org/html/2406.08478v1 The system prompt used was basic and could likely benefit from further refinement.
A vintage comic book cover of Wonderman. On the cover, there are three main characters: Wonderman in a green costume with a large 'W' on his chest, a woman in a yellow and black outfit, and a smaller figure in a brown costume. Wonderman and the woman appear to be in a dynamic pose, suggesting action or combat. Wonderman is holding a thin, sharp object, possibly a weapon. The woman has a confident expression and is looking towards the viewer. The background is a mix of green and yellow, with some abstract designs.

Wonderman, a male superhero character. He is wearing a green and red costume with a large 'W' emblem on the chest. Wonderman has a muscular physique, brown hair, and is wearing a black mask covering his eyes. He stands confidently with his hands by his sides. photo

Train the Data
All tasks were performed on a local workstation equipped with an RTX 4090, i7 processor, and 64GB RAM. Note that 32GB RAM will not suffice, as you may encounter out-of-memory (OOM) errors when caching latents. We did use RunDiffusion.com for testing the LoRAs created, enabling us to launch five servers with five checkpoints to determine the best one that converged We're not going to dive into the rank and learning rate and stuff because this really depends on your goals and what you're trying to accomplish. But the rules below are good ones to follow.
- We used Ostris's ai-toolkit available here: Ostris ai-toolkit
- Default config with LR 4e-4 at Rank 16
- 2200 - 2600 steps saw good convergence. Even some checkpoints into the 4k step range turned out pretty good. If targeting finer details, you may want to adjust the rank up to 32 and lower the learning rate. You will also need to run more steps if you do this.
Training a style: Using simple captions with clear examples to maintain a coherent style is crucial. Although caption-less LoRAs can sometimes work for styles, this was not within the scope of our goals, so we cannot provide specific insights.
Training a concept: You can choose either descriptive captions to avoid interfering with existing tokens or general captions that might interfere, depending on your intention. This choice should be intentional.
Captioning has never been more critical. Flux "gives you what you ask for" - and that's a good thing. You can train a LoRA on a single cartoon concept and still generate photo realistic people. You can even caption a cartoon in the foreground and a realistic scene in the background! This capability is BY DESIGN - so do not resist it - embrace it! (Spoiler alert next!)
 You'll see in the next page of examples where the captioning really helps or hurts you. Depending on your goals again you will need to choose the path that fits what you're trying to accomplish.
Total time for the LoRA was about 2 to 2.5 hours. $1 to $2 on RunPod, Vast, or local electricity will be even cheaper.
Now for the results! (This next file is big to preserve the quality)
You'll see in the next page of examples where the captioning really helps or hurts you. Depending on your goals again you will need to choose the path that fits what you're trying to accomplish.
Total time for the LoRA was about 2 to 2.5 hours. $1 to $2 on RunPod, Vast, or local electricity will be even cheaper.
Now for the results! (This next file is big to preserve the quality)
500 Steps
Right off the bat at 500 steps you will get some likeness. This will mostly be baseline Flux. If you're training a concept that exists then you will see some convergence even at just 500 steps.
 Prompt: a vintage comic book cover for Wonderman, featuring three characters in a dynamic action scene. The central figure is Wonderman with a confident expression, wearing a green shirt with a yellow belt and red gloves. To his left is a woman with a look of concern, dressed in a yellow top and red skirt. On the right, there's a monstrous creature with sharp teeth and claws, seemingly attacking the man. The background is minimal, primarily blue with a hint of landscape at the bottom. The text WONDER COMICS and No. 11 suggests this is from a series.
Prompt: a vintage comic book cover for Wonderman, featuring three characters in a dynamic action scene. The central figure is Wonderman with a confident expression, wearing a green shirt with a yellow belt and red gloves. To his left is a woman with a look of concern, dressed in a yellow top and red skirt. On the right, there's a monstrous creature with sharp teeth and claws, seemingly attacking the man. The background is minimal, primarily blue with a hint of landscape at the bottom. The text WONDER COMICS and No. 11 suggests this is from a series.
1250 Steps
It will start to break apart a little bit here. Be patient. It's learning.
 Prompt: A vintage comic book cover titled 'Wonderman Comics'. The central figure is Wonderman who appears to be in a combat stance. He is lunging at a large, menacing creature with a gaping mouth, revealing sharp teeth. Below the main characters, there's a woman in a yellow dress holding a small device, possibly a gun. She seems to be in distress. In the background, there's a futuristic-looking tower with a few figures standing atop. The overall color palette is vibrant, with dominant yellows, greens, and purples.
Prompt: A vintage comic book cover titled 'Wonderman Comics'. The central figure is Wonderman who appears to be in a combat stance. He is lunging at a large, menacing creature with a gaping mouth, revealing sharp teeth. Below the main characters, there's a woman in a yellow dress holding a small device, possibly a gun. She seems to be in distress. In the background, there's a futuristic-looking tower with a few figures standing atop. The overall color palette is vibrant, with dominant yellows, greens, and purples.
1750 Steps
Hey! We're getting somewhere! The caption as a prompt should be showing our subject well at this stage but the real test is breaking away from the caption to see if our subject is present.
 Prompt: Wonderman wearing a green and red costume with a large 'W' emblem on the chest standing heroically
Prompt: Wonderman wearing a green and red costume with a large 'W' emblem on the chest standing heroically
2500 Steps
There he is! We can now prompt more freely to get Wonderman doing other stuff. Keep in mind we will still be limited to what we trained on, but at least we have a great starting point!
 Prompt: comic style illustration of Wonderman running from aliens on the moon. center character is Wonderman, a male superhero character. He is wearing a green and red costume with a large 'W' emblem on the chest. Black boots to his knees. Wonderman is wearing a black mask covering his eyes
Prompt: comic style illustration of Wonderman running from aliens on the moon. center character is Wonderman, a male superhero character. He is wearing a green and red costume with a large 'W' emblem on the chest. Black boots to his knees. Wonderman is wearing a black mask covering his eyes

"Cosplay" always gets super heroes to appear realistic

Anime Style

Photo Realistic

Illustration Style
Conclusion
This proof of concept provided valuable insights into working with Flux. One of the key lessons we took away is that while Flux is straightforward to train, it's crucial to clearly define your objectives before diving in. Without a clear vision, you might find your model either overwhelming or underwhelming—especially with concepts like "a cookie," which already has extensive representation within Flux. Every training project comes with its own distinct set of challenges and complexities. Patience and persistence are essential to navigate these obstacles successfully. With careful planning and a focused approach, you'll be able to overcome these hurdles and achieve your desired outcomes.
Things We Would Do Different
Upon reviewing our example data, we identified several areas that could benefit from additional cleanup. These issues impacted the final model, leading to some unexpected results. For instance, when "Wonderman" was prompted, the model occasionally generated elements of "Superman" due to similarities between the two. This led to the appearance of a "cape" in an lot of generations. Another issue we found was the appearance of multicolored tights, with some samples showing red while others displayed green. Additionally, the model produced purple shorts again, which was a direct result of the training data. While these challenges surfaced during the process, we believe they can be resolved with further refinement and adjustment of the dataset. Addressing these inconsistencies will improve the accuracy and quality of the model output.

"Wonderman running from an alien on the moon with the earth in the sky in the background" and sometimes we get "Superman"

"Cape" is present even though it was not prompted

Red and green tights were both present due to the training data which had samples of both.
Testing the LoRA Yourself
If you'd like to take the LoRA for a spin there are a few ways you can do this. In our app with hosted hardware, you can download the LoRA locally along with the ComfyUI workflows below, or use Fal.ai with the Huggingface download link. If you use our service we greatly appreciate it! This is how we pay for the research we're doing. So let's go over that.
Test with RunDiffusion.com
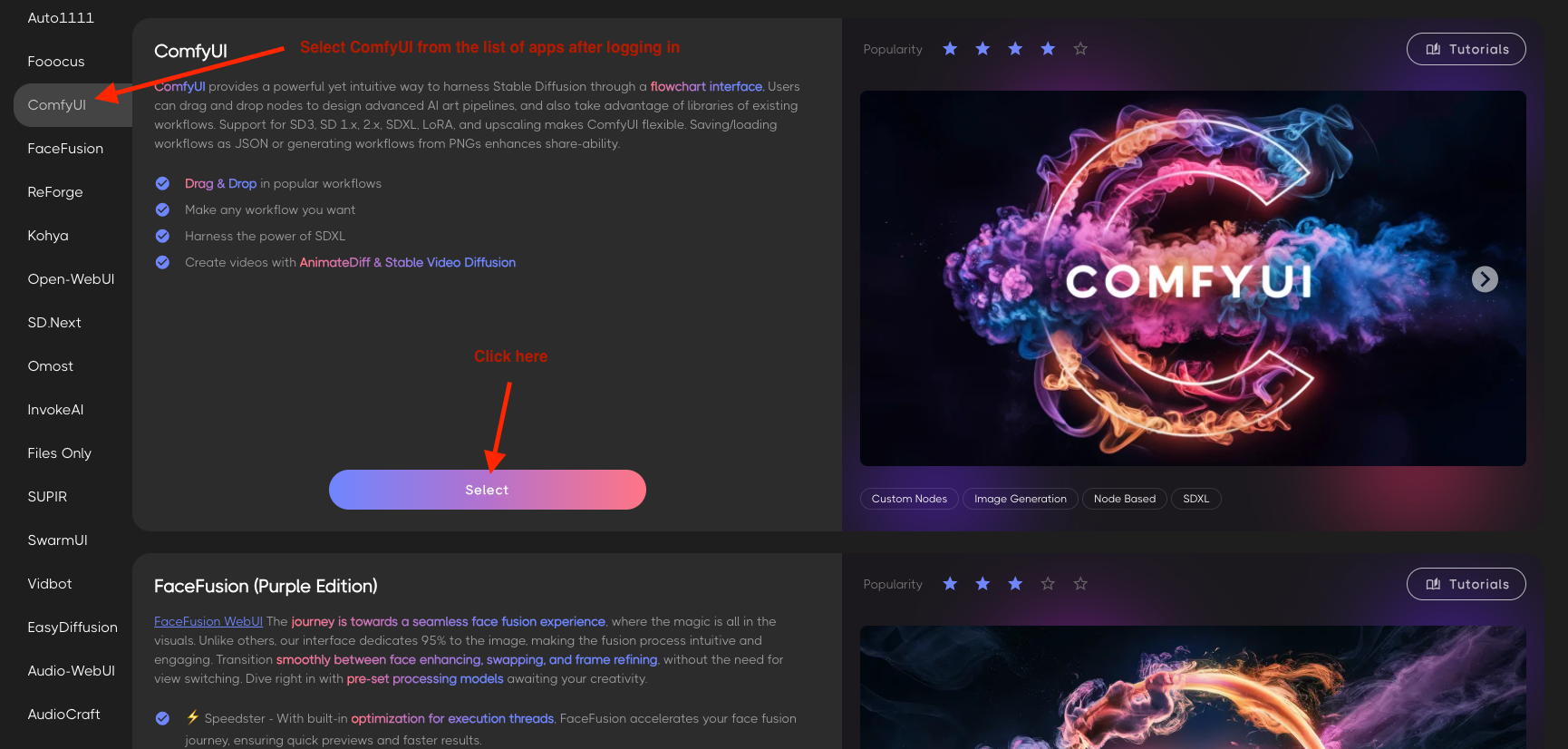
Log into RunDiffusion.com, select ComfyUI from the app list. On the next screen configure your session.
- ComfyUI
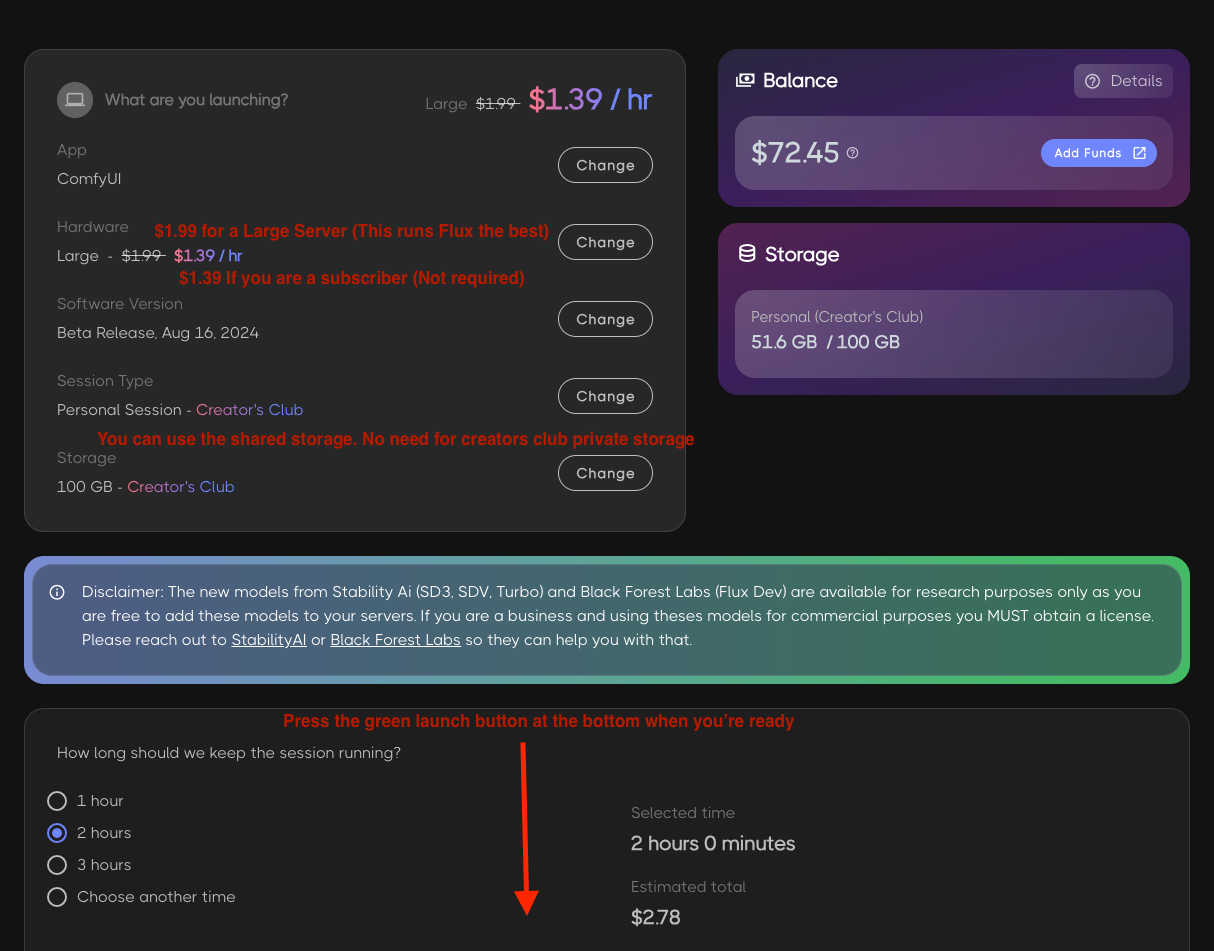
- Large Hardware
- Beta Release (At the time of this document it's at Aug 16, 2024)
- Storage can be public pay as you go or private creators club
- Set your time
- Hit "Launch"


Test Locally
Simply download any of the images you see below (or grab the ComfyUI workflow here) and drag it into ComfyUI. There are instructions for installing Flux in this workflow.
Special Thanks
The team had a blast with this project and we can't wait to start the next one. The Wonderman LoRA will be available for download on Huggingface and Civitai for research. At RunDiffusion we are always trying to push the boundaries with whatever bleeding-edge tech comes out. We appreciate all our customers and supporters. Without you we would not have the funds to dedicate a team to research, so thank you!
- Ostris: Thank you to Ostris for the awesome training tools!
- Mint: Thank you to Mint for the awesome YouTube tutorial!
- Markury: Thank you to Markury for the awesome ComfyUI workflow!
- RunPod: For the compute credit
More Credits
- Developed by: Darin Holbrook - RunDiffusion co-founder and Chief Technology Officer
- Funded by: RunDiffusion.com / RunPod.io
- Model type: Flux [dev] LoRA
- License: flux1dev https://huggingface.co/black-forest-labs/FLUX.1-dev
- Finetuned from model: https://huggingface.co/black-forest-labs/FLUX.1-dev
View all the generations here You can also download (right click -> Save target as) anything below and drag it into ComfyUI for the full workflow.

Text is hit or miss

Close up shot

Took about 5 generations for this. Had to reduce the LoRA weight to .80

Pretty happy with this one

Surprised that I got this on the first gen

This took a few

Consistency in "non-trained" characters is hard

Couldn't get Wonderman to hold the thief.

Close up again

This took a few generations as well

Got lots of good ones for this

Wonderman-RunDiffusion-Flux-LoRA_00018_.png

Wonderman-RunDiffusion-Flux-LoRA_00019_.png
Wonderman-RunDiffusion-Flux-LoRA_00020_.png
Wonderman-RunDiffusion-Flux-LoRA_00021_.png
Wonderman-RunDiffusion-Flux-LoRA_00023_.png
Wonderman-RunDiffusion-Flux-LoRA_00026_.png

Wonderman-RunDiffusion-Flux-LoRA_00029_.png
Wonderman-RunDiffusion-Flux-LoRA_00030_.png

Wonderman-RunDiffusion-Flux-LoRA_00032_.png
Wonderman-RunDiffusion-Flux-LoRA_00036_.png
Wonderman-RunDiffusion-Flux-LoRA_00037_.png

Wonderman-RunDiffusion-Flux-LoRA_00040_.png

Wonderman-RunDiffusion-Flux-LoRA_00043_.png
Wonderman-RunDiffusion-Flux-LoRA_00045_.png
Wonderman-RunDiffusion-Flux-LoRA_00046_.png

Wonderman-RunDiffusion-Flux-LoRA_00049_.png
Wonderman-RunDiffusion-Flux-LoRA_00051_.png

Wonderman-RunDiffusion-Flux-LoRA_00054_.png

Wonderman-RunDiffusion-Flux-LoRA_00056_.png

Wonderman-RunDiffusion-Flux-LoRA_00058_.png

Wonderman-RunDiffusion-Flux-LoRA_00061_.png

Wonderman-RunDiffusion-Flux-LoRA_00063_.png

Wonderman-RunDiffusion-Flux-LoRA_00066_.png

Wonderman-RunDiffusion-Flux-LoRA_00067_.png

Wonderman-RunDiffusion-Flux-LoRA_00068_.png

Wonderman-RunDiffusion-Flux-LoRA_00069_.png
Wonderman-RunDiffusion-Flux-LoRA_00070_.png
Wonderman1-no-workflow.jpg

Wonderman2-no-workflow.jpg

Wonderman3-no-workflow.jpg

Wonderman4-no-workflow.jpg

Wonderman6-no-workflow.jpg

Wonderman7-no-workflow.jpg

Wonderman9-no-workflow.jpg
Model tree for RunDiffusion/Wonderman-Flux-POC
Base model
black-forest-labs/FLUX.1-dev