



FluffyRock Unbound is a finetune of Fluffyrock Unleashed v1.0 trained on an expanded, curated e621 dataset and with training changes adapted from Nvidia Labs EDM2.
This model can produce detailed sexually explicit content and is not suitable for use by minors. It will generally not produce sexually explicit content unless prompted.
Downloads
Fluffyrock-Unbound-v1-1.safetensors - Main model EMA checkpoint.
Fluffyrock-Unbound-v1-1.yaml - YAML file for A1111 Stable Diffusion WebUI. Place this in the same folder as the model.
fluffyrock-unbound-tag-strength-v1.1.csv - Recommended tag completion file, representing the strength of each concept in the model. (Raw Counts, Metadata)
boring_e621_unbound_lite.safetensors - Boring-E621 style embedding to improve quality. Use in the negative prompt. (Stronger Plus Version)
Prompting Guide
This model is trained on e621 tags seperated by commas, but without underscores. "by" has been added before artist names. Trailing commas are used.
Example prompt: solo, anthro, female, wolf, breasts, clothed, standing, outside, full-length portrait, (detailed fur,) by artist name,
- Some tags have been shortened to save on tokens, so be sure to use the tag completion files if you can.
- Most purple "copyright tags" have been removed from the model, so you must not prompt
dreamworks, how to train your dragon, toothlesstoothless. - Rare tags are excluded from the autocompletion file so as to not give false hope.
Automatic1111 Stable Diffusion WebUI Instructions
Place the model and the corresponding .yaml file in the models/Stable-diffusion/ folder. The model will not work properly without the .yaml file.
You will most likely need the CFG Rescale extension: https://github.com/Seshelle/CFG_Rescale_webui A setting of 0.7 seems to be good for almost all cases.
For ideal results go to Settings -> Sampler Parameters and choose Zero Terminal SNR as the "Noise schedule for sampling" and set sigma max to 160 if using a Karras schedule.
ComfyUI Instructions
Place the model checkpoint in the models/checkpoints folder. The optional Boring-E621 embeddings go in models/embeddings.
The model is zero-terminal-SNR with V-prediction. Use the ModelSamplingDiscrete node to configure it properly.
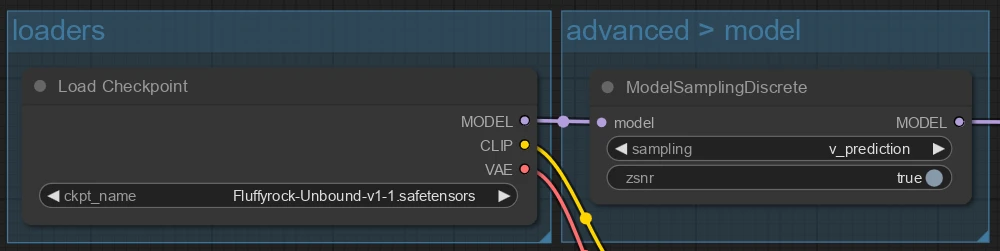
If you are using a KarrasScheduler and zsnr, set sigma_max to 160. Do not use zsnr with the default KSampler karras schedule as the sigma_max will not be set correctly.
Quality Embeddings
Experimental textual inversion embeddings in a similar vein to the Boring Embeddings are provided above. They're intended to improve quality while not drastically altering image content. They should be used as part of a negative prompt, although using them in the positive prompt can be fun too.
- The "lite" version is 6 tokens wide and is initialized on the values of
by <|endoftext|><|endoftext|><|endoftext|><|endoftext|><|endoftext|>, which is very close to a "blank slate". - The "plus" version is trained on the same dataset, is 8 tokens wide, and is initialized on an average vector of 100 low-scoring artists.
- Currently, the "lite" version is recommended.
Training Details
- Adaptive timestep weighting: Timesteps are weighted using a similar method to what the EDM2 paper used, according to the homoscedastic uncertainty of MSE loss on each timestep, thereby equalizing the contribution of each timestep. Loss weight was also conditioned on resolution in order to equalize the contribution of each resolution group. The overall effect of this is that the model is now very good at both high- and low-frequency details, and is not as biased towards blurry backgrounds.
- EMA weights were assembled post-hoc using the method described in the EDM2 paper. The checkpoint shipped uses an EMA length sigma of 0.225.
- Cross-attention masking was applied to extra completely empty blocks of CLIP token embeddings, making the model work better with short prompts. Previously, if an image had a short caption, it would be fed in similarly to if you had added
BREAK BREAK BREAKto the prompt in A1111, which caused the model to depend on those extra blocks and made it produce better images with 225 tokens of input. The model is no longer dependent on this. - Optimizer replaced with schedule-free AdamW, and weight decay was turned off in bias layers, which has greatly stabilized training.
- Low resolution images were removed from higher-resolution buckets. This resulted in removal of approximately 1/3 of images from the highest resolution group. From our testing, we have observed no negative impact on high res generation quality, and this should improve fine details on high res images.
- The tokenizer used for training inputs was set up to never split tags down the middle. If a tag would go to the edge of the block, it will now be moved to the next block. This is similar to how most frontends behave.
- Random dropout is now applied to implied tags. The overall effect of this change should be that more specific tags will be more powerful and less dependent on implied tags, but more general tags will still be present and usable.
Dataset Changes
- A sizeable overhaul of E621 tagging was done, removing several useless tags and renaming others. We are including new tag files that represent the current state of the dataset.
- The dataset was curated to remove harmful content that was discovered in the prior dataset, and content which was previously found to negatively impact generation quality for adjacent concepts.
- Downloads last month
- 79
Model tree for RedRocket/Fluffyrock-Unbound
Base model
runwayml/stable-diffusion-v1-5