
openbmb/Eurus-7b-kto-GGUF
- This is quantized version of openbmb/Eurus-7b-kto
Model Description
Eurus-7B-KTO is KTO fine-tuned from Eurus-7B-SFT on all multi-turn trajectory pairs in UltraInteract and all pairs in UltraFeedback.
It achieves the best overall performance among open-source models of similar sizes and even outperforms specialized models in corresponding domains in many cases. Notably, Eurus-7B-KTO outperforms baselines that are 5× larger.
Usage
We apply tailored prompts for coding and math, consistent with UltraInteract data formats:
Coding
[INST] Write Python code to solve the task:
{Instruction} [/INST]
Math-CoT
[INST] Solve the following math problem step-by-step.
Simplify your answer as much as possible. Present your final answer as \\boxed{Your Answer}.
{Instruction} [/INST]
Math-PoT
[INST] Tool available:
[1] Python interpreter
When you send a message containing Python code to python, it will be executed in a stateful Jupyter notebook environment.
Solve the following math problem step-by-step.
Simplify your answer as much as possible.
{Instruction} [/INST]
Evaluation
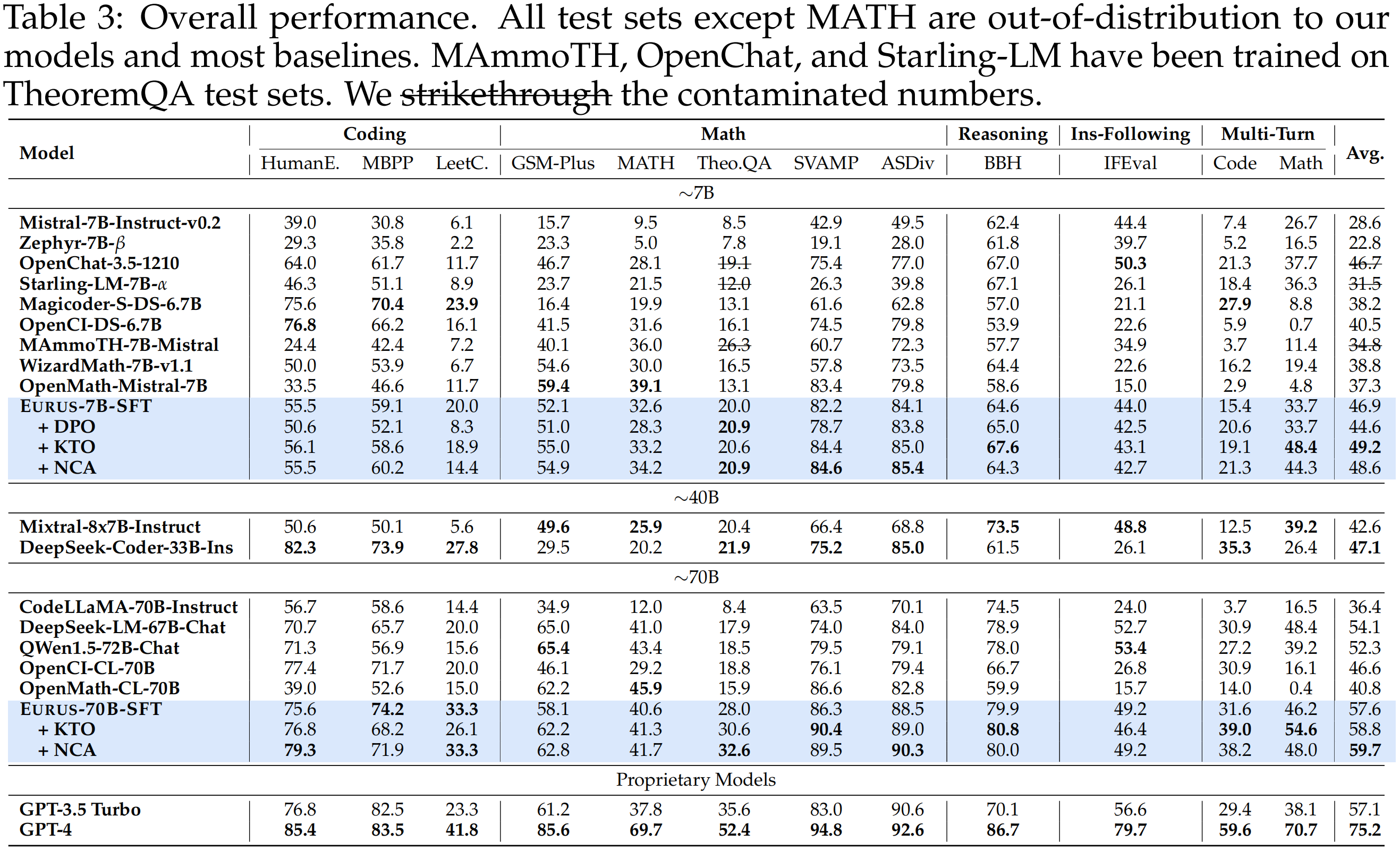
- Eurus, both the 7B and 70B variants, achieve the best overall performance among open-source models of similar sizes. Eurus even outperforms specialized models in corresponding domains in many cases. Notably, Eurus-7B outperforms baselines that are 5× larger, and Eurus-70B achieves better performance than GPT-3.5 Turbo.
- Preference learning with UltraInteract can further improve performance, especially in math and the multi-turn ability.
- Downloads last month
- 279
Inference Providers
NEW
This model is not currently available via any of the supported Inference Providers.
The model cannot be deployed to the HF Inference API:
The model has no library tag.
Model tree for QuantFactory/Eurus-7b-kto-GGUF
Base model
openbmb/Eurus-7b-kto