
👑 Llama-3
Collection
My experiments with Llama-3 models
•
61 items
•
Updated
•
22

This model is a fine-tune (DPO) of meta-llama/Meta-Llama-3-70B-Instruct model.
All GGUF models are available here: MaziyarPanahi/calme-2.3-llama3-70b-GGUF
Detailed results can be found here
| Metric | Value |
|---|---|
| Avg. | 78.74 |
| AI2 Reasoning Challenge (25-Shot) | 72.35 |
| HellaSwag (10-Shot) | 86.00 |
| MMLU (5-Shot) | 80.47 |
| TruthfulQA (0-shot) | 63.45 |
| Winogrande (5-shot) | 82.95 |
| GSM8k (5-shot) | 87.19 |
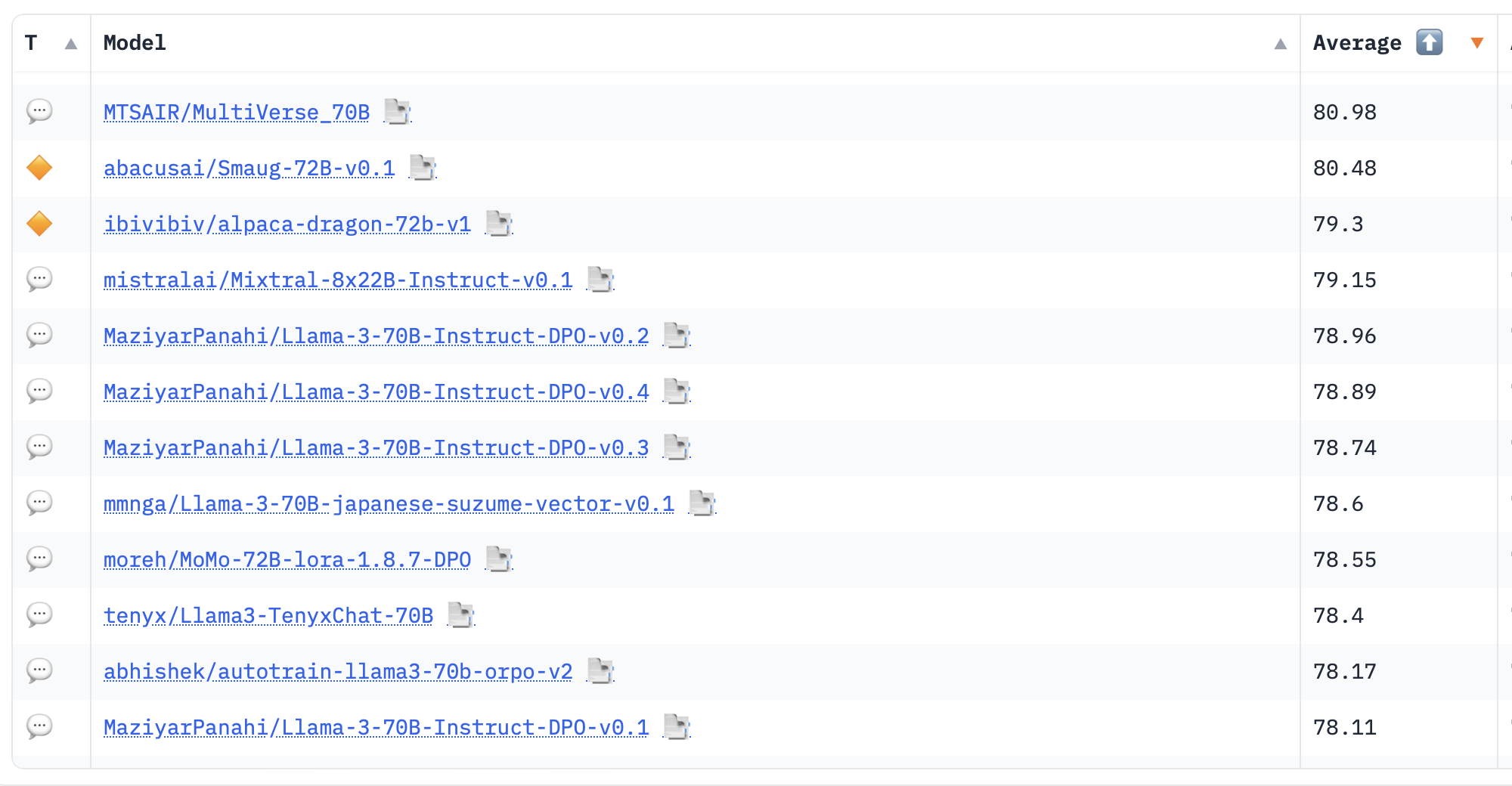
Top 10 models on the Leaderboard
This model uses ChatML prompt template:
<|im_start|>system
{System}
<|im_end|>
<|im_start|>user
{User}
<|im_end|>
<|im_start|>assistant
{Assistant}
You can use this model by using MaziyarPanahi/calme-2.3-llama3-70b as the model name in Hugging Face's
transformers library.
from transformers import AutoModelForCausalLM, AutoTokenizer, TextStreamer
from transformers import pipeline
import torch
model_id = "MaziyarPanahi/calme-2.3-llama3-70b"
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
device_map="auto",
trust_remote_code=True,
# attn_implementation="flash_attention_2"
)
tokenizer = AutoTokenizer.from_pretrained(
model_id,
trust_remote_code=True
)
streamer = TextStreamer(tokenizer)
pipeline = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
model_kwargs={"torch_dtype": torch.bfloat16},
streamer=streamer
)
# Then you can use the pipeline to generate text.
messages = [
{"role": "system", "content": "You are a pirate chatbot who always responds in pirate speak!"},
{"role": "user", "content": "Who are you?"},
]
prompt = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
terminators = [
tokenizer.eos_token_id,
tokenizer.convert_tokens_to_ids("<|im_end|>"),
tokenizer.convert_tokens_to_ids("<|eot_id|>") # safer to have this too
]
outputs = pipeline(
prompt,
max_new_tokens=2048,
eos_token_id=terminators,
do_sample=True,
temperature=0.6,
top_p=0.95,
)
print(outputs[0]["generated_text"][len(prompt):])