
Model Card for Fine-tuned Microsoft Phi-3 Mini (3b) with DPO
This model card describes a text-to-text generation model fine-tuned from the Microsoft Phi-3 Mini (3b) base model using Direct Preference Optimization (DPO).
Model Details
Model Description
This model is designed to generate more informative and concise responses compared to out-of-the-box large language models. It is fine-tuned on the Intel/orca_dpo_pairs dataset to achieve this goal. The DPO approach helps the model adapt to the expected format of responses, reducing the number of tokens needed for instructions. This leads to more efficient inference during model usage.
- Developed by: Mayank Raj
- Model type: Transformer
- Language(s) (NLP): En
- License: MIT
- Finetuned from model [optional]: Microsoft Phi-3 Mini
Model Sources [optional]
- Repository: Intel/orca_dpo_pairs
- Google Colab Notebook: Link to Google Colab notebook
- Weights and Biases Results: Results
Uses
Direct Use
This model can be used for text-to-text generation tasks where informative and concise responses are desired. It can be ideal for applications like summarizing factual topics, generating code comments, or creating concise instructions. [More Information Needed]
Bias, Risks, and Limitations
- Bias: As with any large language model, this model may inherit biases present in the training data. It's important to be aware of these potential biases and use the model responsibly.
- Risks: The model may generate factually incorrect or misleading information. It's crucial to evaluate its outputs carefully and not rely solely on its output.
- Limitations: The model's performance depends on the quality and relevance of the input text. It may not perform well on topics outside its training domain.
How to Get Started with the Model
Please refer to the provided Google Colab notebook link for instructions on using the model.
Training Details
Training Data
The model was fine-tuned on the Intel/orca_dpo_pairs dataset, which consists of text prompts and corresponding informative response pairs.
Training Procedure
Preprocessing [optional]
- The training data was preprocessed to clean and format the text prompts and responses.
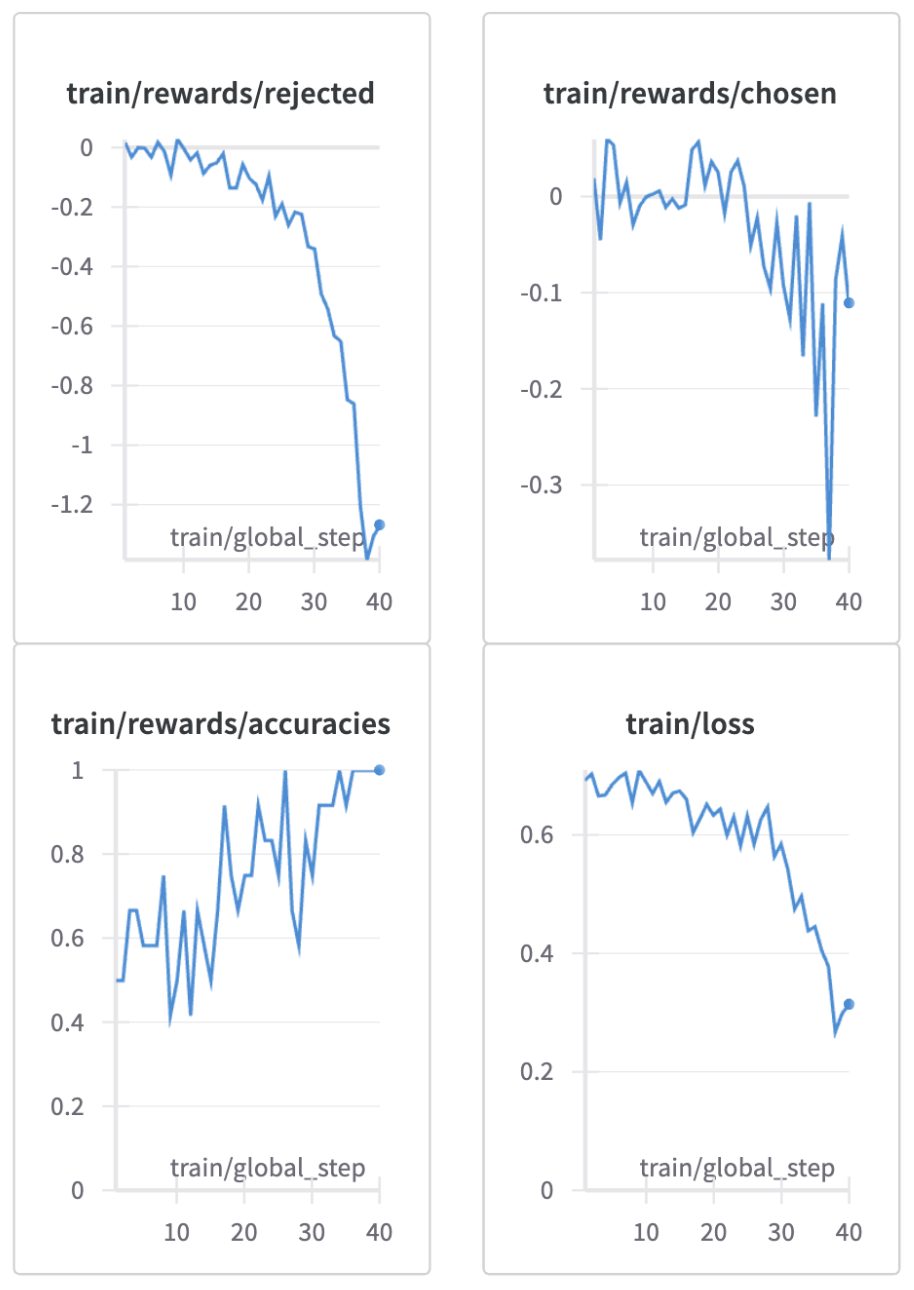
Results:
- Downloads last month
- 0