
MiniCPM-V-2-GGUF
- Original model: MiniCPM-V-2
Description
This repo contains GGUF format model files for MiniCPM-V-2.
About GGUF
GGUF is a new format introduced by the llama.cpp team on August 21st 2023. It is a replacement for GGML, which is no longer supported by llama.cpp. Here is an incomplete list of clients and libraries that are known to support GGUF:
- llama.cpp. This is the source project for GGUF, providing both a Command Line Interface (CLI) and a server option.
- text-generation-webui, Known as the most widely used web UI, this project boasts numerous features and powerful extensions, and supports GPU acceleration.
- Ollama Ollama is a lightweight and extensible framework designed for building and running language models locally. It features a simple API for creating, managing, and executing models, along with a library of pre-built models for use in various applications
- KoboldCpp, A comprehensive web UI offering GPU acceleration across all platforms and architectures, particularly renowned for storytelling.
- GPT4All, This is a free and open source GUI that runs locally, supporting Windows, Linux, and macOS with full GPU acceleration.
- LM Studio An intuitive and powerful local GUI for Windows and macOS (Silicon), featuring GPU acceleration.
- LoLLMS Web UI. A notable web UI with a variety of unique features, including a comprehensive model library for easy model selection.
- Faraday.dev, An attractive, user-friendly character-based chat GUI for Windows and macOS (both Silicon and Intel), also offering GPU acceleration.
- llama-cpp-python, A Python library equipped with GPU acceleration, LangChain support, and an OpenAI-compatible API server.
- candle, A Rust-based ML framework focusing on performance, including GPU support, and designed for ease of use.
- ctransformers, A Python library featuring GPU acceleration, LangChain support, and an OpenAI-compatible AI server.
- localGPT An open-source initiative enabling private conversations with documents.
Explanation of quantisation methods
Click to see details
The new methods available are:- GGML_TYPE_Q2_K - "type-1" 2-bit quantization in super-blocks containing 16 blocks, each block having 16 weight. Block scales and mins are quantized with 4 bits. This ends up effectively using 2.5625 bits per weight (bpw)
- GGML_TYPE_Q3_K - "type-0" 3-bit quantization in super-blocks containing 16 blocks, each block having 16 weights. Scales are quantized with 6 bits. This end up using 3.4375 bpw.
- GGML_TYPE_Q4_K - "type-1" 4-bit quantization in super-blocks containing 8 blocks, each block having 32 weights. Scales and mins are quantized with 6 bits. This ends up using 4.5 bpw.
- GGML_TYPE_Q5_K - "type-1" 5-bit quantization. Same super-block structure as GGML_TYPE_Q4_K resulting in 5.5 bpw
- GGML_TYPE_Q6_K - "type-0" 6-bit quantization. Super-blocks with 16 blocks, each block having 16 weights. Scales are quantized with 8 bits. This ends up using 6.5625 bpw.
How to download GGUF files
Note for manual downloaders: You almost never want to clone the entire repo! Multiple different quantisation formats are provided, and most users only want to pick and download a single folder.
The following clients/libraries will automatically download models for you, providing a list of available models to choose from:
- LM Studio
- LoLLMS Web UI
- Faraday.dev
In text-generation-webui
Under Download Model, you can enter the model repo: LiteLLMs/MiniCPM-V-2-GGUF and below it, a specific filename to download, such as: Q4_0/Q4_0-00001-of-00009.gguf.
Then click Download.
On the command line, including multiple files at once
I recommend using the huggingface-hub Python library:
pip3 install huggingface-hub
Then you can download any individual model file to the current directory, at high speed, with a command like this:
huggingface-cli download LiteLLMs/MiniCPM-V-2-GGUF Q4_0/Q4_0-00001-of-00009.gguf --local-dir . --local-dir-use-symlinks False
More advanced huggingface-cli download usage (click to read)
You can also download multiple files at once with a pattern:
huggingface-cli download LiteLLMs/MiniCPM-V-2-GGUF --local-dir . --local-dir-use-symlinks False --include='*Q4_K*gguf'
For more documentation on downloading with huggingface-cli, please see: HF -> Hub Python Library -> Download files -> Download from the CLI.
To accelerate downloads on fast connections (1Gbit/s or higher), install hf_transfer:
pip3 install huggingface_hub[hf_transfer]
And set environment variable HF_HUB_ENABLE_HF_TRANSFER to 1:
HF_HUB_ENABLE_HF_TRANSFER=1 huggingface-cli download LiteLLMs/MiniCPM-V-2-GGUF Q4_0/Q4_0-00001-of-00009.gguf --local-dir . --local-dir-use-symlinks False
Windows Command Line users: You can set the environment variable by running set HF_HUB_ENABLE_HF_TRANSFER=1 before the download command.
Make sure you are using llama.cpp from commit d0cee0d or later.
./main -ngl 35 -m Q4_0/Q4_0-00001-of-00009.gguf --color -c 8192 --temp 0.7 --repeat_penalty 1.1 -n -1 -p "<PROMPT>"
Change -ngl 32 to the number of layers to offload to GPU. Remove it if you don't have GPU acceleration.
Change -c 8192 to the desired sequence length. For extended sequence models - eg 8K, 16K, 32K - the necessary RoPE scaling parameters are read from the GGUF file and set by llama.cpp automatically. Note that longer sequence lengths require much more resources, so you may need to reduce this value.
If you want to have a chat-style conversation, replace the -p <PROMPT> argument with -i -ins
For other parameters and how to use them, please refer to the llama.cpp documentation
How to run in text-generation-webui
Further instructions can be found in the text-generation-webui documentation, here: text-generation-webui/docs/04 ‐ Model Tab.md.
How to run from Python code
You can use GGUF models from Python using the llama-cpp-python or ctransformers libraries. Note that at the time of writing (Nov 27th 2023), ctransformers has not been updated for some time and is not compatible with some recent models. Therefore I recommend you use llama-cpp-python.
How to load this model in Python code, using llama-cpp-python
For full documentation, please see: llama-cpp-python docs.
First install the package
Run one of the following commands, according to your system:
# Base ctransformers with no GPU acceleration
pip install llama-cpp-python
# With NVidia CUDA acceleration
CMAKE_ARGS="-DLLAMA_CUBLAS=on" pip install llama-cpp-python
# Or with OpenBLAS acceleration
CMAKE_ARGS="-DLLAMA_BLAS=ON -DLLAMA_BLAS_VENDOR=OpenBLAS" pip install llama-cpp-python
# Or with CLBLast acceleration
CMAKE_ARGS="-DLLAMA_CLBLAST=on" pip install llama-cpp-python
# Or with AMD ROCm GPU acceleration (Linux only)
CMAKE_ARGS="-DLLAMA_HIPBLAS=on" pip install llama-cpp-python
# Or with Metal GPU acceleration for macOS systems only
CMAKE_ARGS="-DLLAMA_METAL=on" pip install llama-cpp-python
# In windows, to set the variables CMAKE_ARGS in PowerShell, follow this format; eg for NVidia CUDA:
$env:CMAKE_ARGS = "-DLLAMA_OPENBLAS=on"
pip install llama-cpp-python
Simple llama-cpp-python example code
from llama_cpp import Llama
# Set gpu_layers to the number of layers to offload to GPU. Set to 0 if no GPU acceleration is available on your system.
llm = Llama(
model_path="./Q4_0/Q4_0-00001-of-00009.gguf", # Download the model file first
n_ctx=32768, # The max sequence length to use - note that longer sequence lengths require much more resources
n_threads=8, # The number of CPU threads to use, tailor to your system and the resulting performance
n_gpu_layers=35 # The number of layers to offload to GPU, if you have GPU acceleration available
)
# Simple inference example
output = llm(
"<PROMPT>", # Prompt
max_tokens=512, # Generate up to 512 tokens
stop=["</s>"], # Example stop token - not necessarily correct for this specific model! Please check before using.
echo=True # Whether to echo the prompt
)
# Chat Completion API
llm = Llama(model_path="./Q4_0/Q4_0-00001-of-00009.gguf", chat_format="llama-2") # Set chat_format according to the model you are using
llm.create_chat_completion(
messages = [
{"role": "system", "content": "You are a story writing assistant."},
{
"role": "user",
"content": "Write a story about llamas."
}
]
)
How to use with LangChain
Here are guides on using llama-cpp-python and ctransformers with LangChain:
Original model card: MiniCPM-V-2
News
- [2024.04.23] MiniCPM-V 2.0 supports vLLM now!
- [2024.04.18] We create a HuggingFace Space to host the demo of MiniCPM-V 2.0 at here!
- [2024.04.17] MiniCPM-V 2.0 supports deploying WebUI Demo now!
- [2024.04.15] MiniCPM-V 2.0 supports fine-tuning with the SWIFT framework!
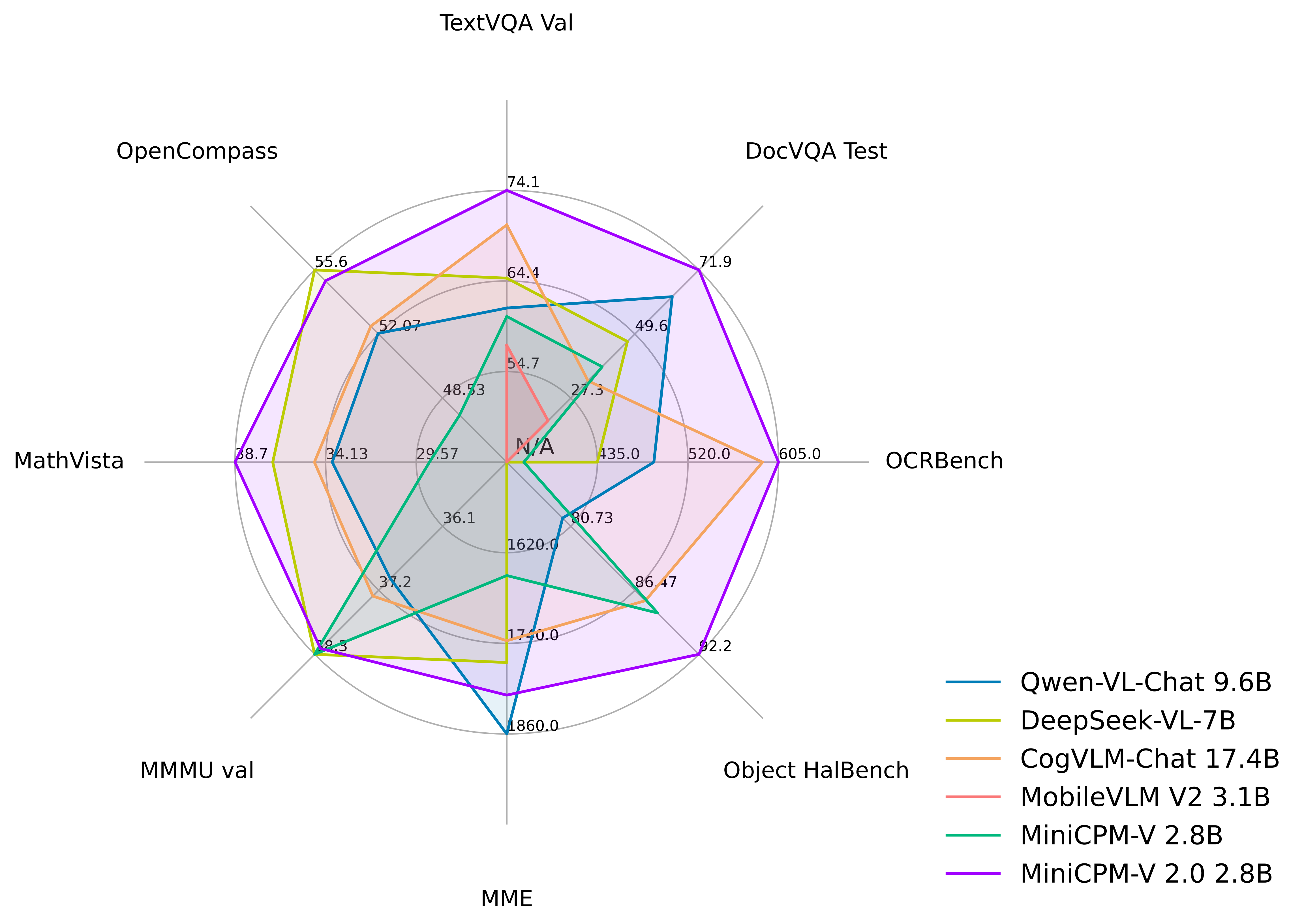
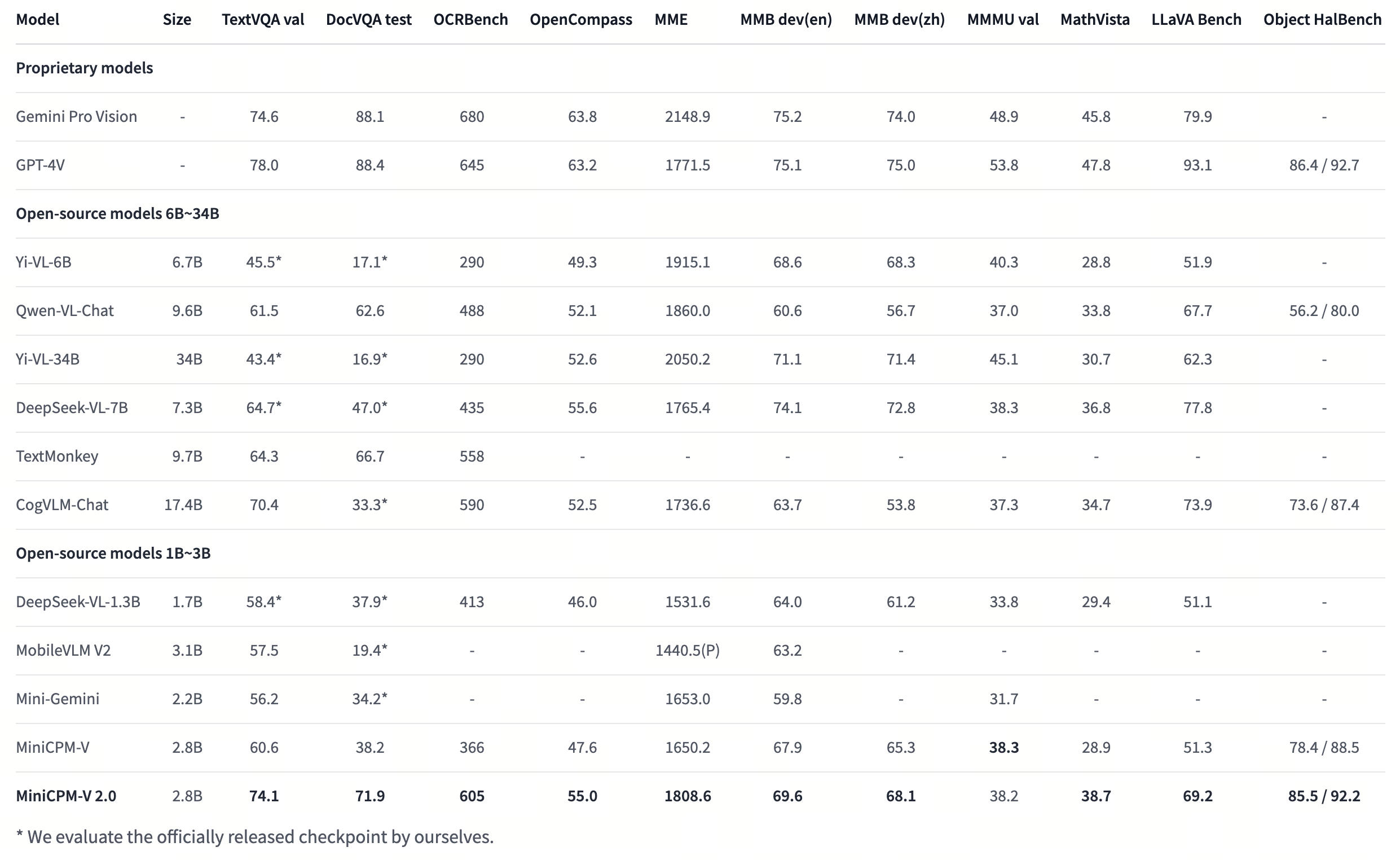
- [2024.04.12] We open-source MiniCPM-V-2.0, which achieves comparable performance with Gemini Pro in understanding scene text and outperforms strong Qwen-VL-Chat 9.6B and Yi-VL 34B on OpenCompass, a comprehensive evaluation over 11 popular benchmarks. Click here to view the MiniCPM-V 2.0 technical blog.
MiniCPM-V 2.0
MiniCPM-V 2.8B is a strong multimodal large language model for efficient end-side deployment. The model is built based on SigLip-400M and MiniCPM-2.4B, connected by a perceiver resampler. Our latest version, MiniCPM-V 2.0 has several notable features.
🔥 State-of-the-art Performance.
MiniCPM-V 2.0 achieves state-of-the-art performance on multiple benchmarks (including OCRBench, TextVQA, MME, MMB, MathVista, etc) among models under 7B parameters. It even outperforms strong Qwen-VL-Chat 9.6B, CogVLM-Chat 17.4B, and Yi-VL 34B on OpenCompass, a comprehensive evaluation over 11 popular benchmarks. Notably, MiniCPM-V 2.0 shows strong OCR capability, achieving comparable performance to Gemini Pro in scene-text understanding, and state-of-the-art performance on OCRBench among open-source models.
🏆 Trustworthy Behavior.
LMMs are known for suffering from hallucination, often generating text not factually grounded in images. MiniCPM-V 2.0 is the first end-side LMM aligned via multimodal RLHF for trustworthy behavior (using the recent RLHF-V [CVPR'24] series technique). This allows the model to match GPT-4V in preventing hallucinations on Object HalBench.
🌟 High-Resolution Images at Any Aspect Raito.
MiniCPM-V 2.0 can accept 1.8 million pixels (e.g., 1344x1344) images at any aspect ratio. This enables better perception of fine-grained visual information such as small objects and optical characters, which is achieved via a recent technique from LLaVA-UHD.
⚡️ High Efficiency.
MiniCPM-V 2.0 can be efficiently deployed on most GPU cards and personal computers, and even on end devices such as mobile phones. For visual encoding, we compress the image representations into much fewer tokens via a perceiver resampler. This allows MiniCPM-V 2.0 to operate with favorable memory cost and speed during inference even when dealing with high-resolution images.
🙌 Bilingual Support.
MiniCPM-V 2.0 supports strong bilingual multimodal capabilities in both English and Chinese. This is enabled by generalizing multimodal capabilities across languages, a technique from VisCPM [ICLR'24].
Evaluation
Examples

We deploy MiniCPM-V 2.0 on end devices. The demo video is the raw screen recording on a Xiaomi 14 Pro without edition.


Demo
Click here to try out the Demo of MiniCPM-V 2.0.
Deployment on Mobile Phone
MiniCPM-V 2.0 can be deployed on mobile phones with Android and Harmony operating systems. 🚀 Try it out here.
Inference with vLLM
Click to see how to inference with vLLM
Because our pull request to vLLM is still waiting for reviewing, we fork this repository to build and test our vLLM demo. Here are the steps:- Clone our version of vLLM:
git clone https://github.com/OpenBMB/vllm.git
- Install vLLM:
cd vllm
pip install -e .
- Install timm:
pip install timm=0.9.10
- Run our demo:
python examples/minicpmv_example.py
Usage
Inference using Huggingface transformers on Nivdia GPUs or Mac with MPS (Apple silicon or AMD GPUs). Requirements tested on python 3.10:
Pillow==10.1.0
timm==0.9.10
torch==2.1.2
torchvision==0.16.2
transformers==4.36.0
sentencepiece==0.1.99
# test.py
import torch
from PIL import Image
from transformers import AutoModel, AutoTokenizer
model = AutoModel.from_pretrained('openbmb/MiniCPM-V-2', trust_remote_code=True, torch_dtype=torch.bfloat16)
# For Nvidia GPUs support BF16 (like A100, H100, RTX3090)
model = model.to(device='cuda', dtype=torch.bfloat16)
# For Nvidia GPUs do NOT support BF16 (like V100, T4, RTX2080)
#model = model.to(device='cuda', dtype=torch.float16)
# For Mac with MPS (Apple silicon or AMD GPUs).
# Run with `PYTORCH_ENABLE_MPS_FALLBACK=1 python test.py`
#model = model.to(device='mps', dtype=torch.float16)
tokenizer = AutoTokenizer.from_pretrained('openbmb/MiniCPM-V-2', trust_remote_code=True)
model.eval()
image = Image.open('xx.jpg').convert('RGB')
question = 'What is in the image?'
msgs = [{'role': 'user', 'content': question}]
res, context, _ = model.chat(
image=image,
msgs=msgs,
context=None,
tokenizer=tokenizer,
sampling=True,
temperature=0.7
)
print(res)
Please look at GitHub for more detail about usage.
MiniCPM-V 1.0
Please see the info about MiniCPM-V 1.0 here.
License
Model License
- The code in this repo is released according to Apache-2.0
- The usage of MiniCPM-V 2.0's parameters is subject to "General Model License Agreement - Source Notes - Publicity Restrictions - Commercial License"
- The parameters are fully open to acedemic research
- Please contact cpm@modelbest.cn to obtain a written authorization for commercial uses. Free commercial use is also allowed after registration.
Statement
- As a LLM, MiniCPM-V 2.0 generates contents by learning a large mount of texts, but it cannot comprehend, express personal opinions or make value judgement. Anything generated by MiniCPM-V 2.0 does not represent the views and positions of the model developers
- We will not be liable for any problems arising from the use of the MinCPM-V open Source model, including but not limited to data security issues, risk of public opinion, or any risks and problems arising from the misdirection, misuse, dissemination or misuse of the model.
Other Multimodal Projects from Our Team
Citation
If you find our work helpful, please consider citing the following papers
@article{yu2023rlhf,
title={Rlhf-v: Towards trustworthy mllms via behavior alignment from fine-grained correctional human feedback},
author={Yu, Tianyu and Yao, Yuan and Zhang, Haoye and He, Taiwen and Han, Yifeng and Cui, Ganqu and Hu, Jinyi and Liu, Zhiyuan and Zheng, Hai-Tao and Sun, Maosong and others},
journal={arXiv preprint arXiv:2312.00849},
year={2023}
}
@article{viscpm,
title={Large Multilingual Models Pivot Zero-Shot Multimodal Learning across Languages},
author={Jinyi Hu and Yuan Yao and Chongyi Wang and Shan Wang and Yinxu Pan and Qianyu Chen and Tianyu Yu and Hanghao Wu and Yue Zhao and Haoye Zhang and Xu Han and Yankai Lin and Jiao Xue and Dahai Li and Zhiyuan Liu and Maosong Sun},
journal={arXiv preprint arXiv:2308.12038},
year={2023}
}
@article{xu2024llava-uhd,
title={{LLaVA-UHD}: an LMM Perceiving Any Aspect Ratio and High-Resolution Images},
author={Xu, Ruyi and Yao, Yuan and Guo, Zonghao and Cui, Junbo and Ni, Zanlin and Ge, Chunjiang and Chua, Tat-Seng and Liu, Zhiyuan and Huang, Gao},
journal={arXiv preprint arXiv:2403.11703},
year={2024}
}
- Downloads last month
- 0