
![]()
VBD-LLaMA2-Chat - a Conversationally-tuned LLaMA2 for Vietnamese
(Disclaimer 1: VBD-LLaMA family is an effort by VinBigData to support and promote research on LLM in Vietnam. This model is not related to the ViGPT/ViViChat or any other product operating at VinBigData)
We release VBD-LLaMA2-7B-Chat, a finetuned model based on Meta's LLaMA2-7B specifically for the Vietnamese 🇻🇳 language. This is part of our effort to support the community in building Vietnamese Large Language Models (LLMs). The pretrained weight for this model was trained through continuous self-supervised learning (SSL) by extending LLaMA2's vocab on a corpus consisting of 100 billion Vietnamese 🇻🇳 tokens and 40 billion English 🇬🇧 tokens. This approach attempts to leverage the full potential of existing language models and adapt them to lower resource languages, thereby reduce the hardware, time, and data cost associated building LLMs for these languages. Subsequent supervised finetuning (SFT) was conducted using our internal SFT dataset, which consists of 2 million Vietnamese samples.
For this release, we are only including the pretrained weight and the SFT weight of our model's checkpoint, which was trained on 40b Vietnamese and 16b English tokens (56b tokens total).
Model weights:
- VBD-LLaMA2-7B-50b: the snapshot of the pretrained model after 40b Vietnamese tokens and 16b Enlgish tokens ((~50b tokens total))
- VBD-LLaMA2-7B-50b-Chat: a snapshot demonstrating the efficacy of the proposed methodology. This base model is pretrained on 40b Vietnamese tokens and 16b English tokens and SFT on 2 million samples.
Terms of Use and License: By using our released weights, you agree to and comply with the terms and conditions specified in Meta's LLaMA-2 license.
Disclaimer 2: While we have made considerable efforts to minimize misleading, inaccurate, and harmful content generation, it's important to acknowledge that our released model carries inherent risks. We strongly recommend utilizing this model exclusively within a closely supervised environment and/or conducting additional testing, red teaming, and alignment procedures. The utilization of this model must adhere to and comply with local governance and regulations. The authors of this model shall not be held liable for any claims, damages, or other liabilities arising from the use of the released weights..
Pre-training Proposal
We propose to do continued pretraining of the 3/7/13 billion parameters large language models (LLaMA, Bloom, MPT, Falcon, etc) for the Vietnamese and English languages.
Our proposal involves conducting experiments to enhance the conversational capabilities of this model in Vietnamese while retaining its abilities in English. This will be achieved by transferring knowledge from the English latent space to the Vietnamese latent space.
Instead of training a Vietnamese LLM from scratch, we want to leverage the full potential of existing language models (in English) and transform it into Vietnamese. We aim to reduce hardware costs, time, and data in building language models for Vietnamese.
We intend to augment the original latent space of LLaMA/Bloom LLM by incorporating a Vietnamese latent space. We will then transfer knowledge between these two spaces and fine-tune self-supervised learning (SSL) using both English and Vietnamese unsupervised corpora.
With this model, we expect to make a significant contribution to the development of large language models in Vietnam, making it easier for Vietnamese people to access larger language models in-house. It will create a recipe for other low-resource languages to follow as well.
Vietnamese language, methods, and research objectives
We experiment adding the Vietnamese language into large language models that do not originally support Vietnamese. Our hypothesis is that is is feasible to transfer knowledge transfer between different languages utilizing the cross-lingual capabilities of large models to quickly develop a Vietnamese Language Model (LLM) with less training time, data, and computational resources.
Our proposed methods:
- We will start with a English/multilingual large language model:
- We will rebuild the BPE-based tokenizers by preserving the original tokens and incorporating Vietnamese syllables.
- We will transfer knowledge in the latent space by fine-tuning the `added latent space while freezing the original latent space. This step is conducted by using the En-Vi and Vi-En translation tasks.
- Using the new latent space (original latent space + added latent space), we will fine-tune self-supervised learning (SSL) using 40B English tokens and 100B Vietnamese tokens of unsupervised corpora. (the number of tokens as the recent well-performing LLaMA models - of around 1-1.5T tokens.)
- In this step, we use a special strategy called hybrid training. This allows the model to have better zero-shot/few-shot capabilities even if the model has not been SFT trained. This also enhance the model's capability to understand prompts with limited SFT.
- The training time for the 3B model is roughly 8k GPU hours (roughly 44 days on GPU DGX 8 A100s 40GB), and 16k GPU hours for the 7B model (roughly 84 days on GPU DGX 8 A100s 40GB).
- We will evaluate the model periodically to observe improvents and/or the possibility of early completion of the training progress.
Self-supervised Fine-Tuning (SFT)
We believe that Conversational-AI will be a significant interface for human-machine interaction in the next few years. Therefore, VBD-LLaMA2-7B-50b-Chat is finetuned on 2 million conversational data, in hopes that there will be more applications of LLMs in conversational systems in the near future.
In the following section, we document some of the benchmark of the released weight(s).
Evaluation
We evaluated our model via peer comparison on multiple publicly available dataset using @hieunguyen1053 fork of lm-evaluation-harness , and combine the results with that provided by the authors of VinaLLaMA. The results are bellow:
| Model | Model size | arc_vi (acc) | hellaswag_vi (acc) | mmlu_vi (acc) | truthfulqa_vi (acc) | Average |
|---|---|---|---|---|---|---|
| URA-LLaMA-13B | 0,3752 | 0,4830 | 0,3973 | 0,4574 | 0,4282 | |
| BLOOMZ-7B | 0,3205 | 0,4930 | 0,3975 | 0,4523 | 0,4158 | |
| PhoGPT-7B5-Instruct | 0,2470 | 0,2578 | 0,2413 | 0,4759 | 0,3055 | |
| SeaLLM-7B-chat | 0,3607 | 0,5112 | 0,3339 | 0,4948 | 0,4252 | |
| Vietcuna-7b-v3 | 0,3419 | 0,4939 | 0,3354 | 0,4807 | 0,4130 | |
| VinaLLaMA-2.7B-chat | 0,3273 | 0,4814 | 0,3051 | 0,4972 | 0,4028 | |
| VinaLLaMA-7B-chat | 0,4239 | 0,5407 | 0,3932 | 0,5251 | 0,4707 | |
| VBD-LLaMA2-7B-50b | 0,3222 | 0,5195 | 0,2964 | 0,4614 | 0,3999 | |
| VBD-LLaMA2-7B-50b-Chat | 0,3585 | 0,5207 | 0,3444 | 0,5179 | 0,4354 |
Table 1. Benchmark on Vietnamese datasets
| Organization | Model | Model size | ARC (ACC) | HellaSwag (ACC) | LAMBADA (perplexity) | MMLU (ACC) |
|---|---|---|---|---|---|---|
| VLSP | hoa-7b | ~7B | 0,2722 | 0,4867 | 18,53 | |
| BK Lab | LLaMA-2-BK | ~7B | 0,4164 | 0,7216 | 5,010 | |
| ViLM | vietcuna-7b-v3 | ~7B | 0,3976 | 0,6309 | 7,125 | |
| BigScience | Bloomz-T0 | ~7B | 0,436 | 0,6401 | 6,542 | 0,3785 |
| TII | Falcon-7B-Instruct | ~7B | 0,4258 | 0,6976 | 7,463 | 0,2584 |
| MosaicML | MPT-7B-Chat | ~7B | 0,4258 | 0,7438 | 5,797 | 0,3762 |
| Meta | LLaMA-2-Chat | ~7B | 0,442 | 0,7547 | 3,968 | 0,4832 |
| AISingapore | Sealion7b | ~7B | 0,3422 | 0,6705 | 6,715 | 0,268 |
| VBD | VBD-LLaMA2-7B-50b-Chat | ~7B | 0,4556 | 0,7384 | 4,645 | 0,4558 |
Table 2. Benchmark on English datasets
Based on this results, our model performs on-par or better than most models for tasks in Vietnamese and demonstrate that this approach is extremely potential.
While this model primarily specializes in multi-turn conversational scenarios, it has demonstrated its competence in various multiple-choice question and answer tasks during testing. Below, you can find the results, fairly evaluated by the VMLU team, in comparison to other open-source models, including VBD-LLaMA2-7B-50b-Chat. (We extend our gratitude to the VMLU team for their diligent work in creating an open-source public evaluation dataset).
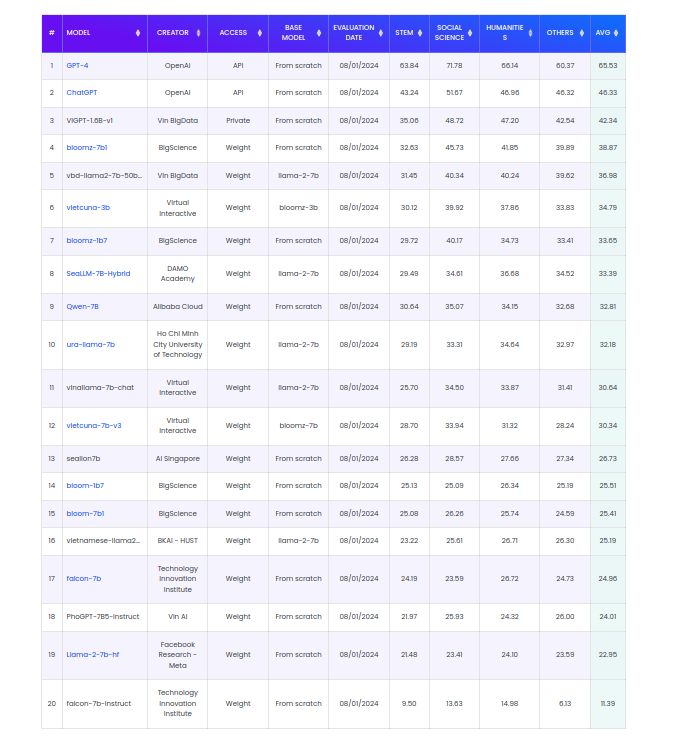
Table 3. Benchmark on VMLU datasets
Pretraining loss:

Run the model
with Huggingface's transformers
import torch
from transformers import AutoConfig, AutoModelForCausalLM, AutoTokenizer
model_path = "LR-AI-Labs/vbd-llama2-7B-50b-chat"
tokenizer = AutoTokenizer.from_pretrained(model_path, use_fast=False)
model = AutoModelForCausalLM.from_pretrained(
model_path, torch_dtype=torch.bfloat16,
device_map='auto',
# load_in_8bit=True
)
model.eval()
SYS_PROMPT = "A chat between a curious user and an artificial intelligence assistant. "\
"The assistant gives helpful, detailed, and polite answers to the user's questions."
def response_generate(input_prompt):
input_ids = tokenizer(input_prompt, return_tensors="pt")
outputs = model.generate(
inputs=input_ids["input_ids"].to("cuda"),
attention_mask=input_ids["attention_mask"].to("cuda"),
do_sample=True,
temperature=0.7,
top_k=50,
top_p=0.9,
max_new_tokens=1024,
eos_token_id=tokenizer.eos_token_id,
pad_token_id=tokenizer.pad_token_id
)
response = tokenizer.batch_decode(outputs, skip_special_tokens=True)[0]
response = response.split("ASSISTANT:")[-1].strip()
return response
print(response_generate(f"{SYS_PROMPT} USER: Xin chào, bạn là ai? ASSISTANT:"))
# Xin chào, ViVi là một trợ lý trí tuệ nhân tạo có thể trả lời câu hỏi của bạn và trò chuyện với bạn.
For single-turn chat:
print(response_generate(f"{SYS_PROMPT} USER: Cách để nấu món phở ngon ASSISTANT:"))
print(response_generate(f"{SYS_PROMPT} USER: Viết cho tôi một email xin sếp tăng lương ASSISTANT:"))
print(response_generate(f'''{SYS_PROMPT} USER: Trả lời câu hỏi dựa vào thông tin lấy từ các đoạn văn sau. Nếu không có thông tin trả lời "Thật tiếc, câu hỏi của bạn Vivi không biết." Nếu có câu trả lời, yêu cầu trả ra cả nguồn chứa câu trả lời dạng "[đoạn k]."
Câu hỏi: {question}
Đoạn 0: {chunk_0}
Đoạn 1: {chunk_1}
Đoạn 2: {chunk_2}
Đoạn 3: {chunk_3}
Đoạn 4: {chunk_4} ASSISTANT:'''))
For conversation chat:
turns = []
while True:
user_input = input("USER: ")
turns.append("USER: " + user_input)
bot_output = "ASSISTANT: " + response_generate("%s %s ASSISTANT:" %(SYS_PROMPT, " ".join(turns)))
print(bot_output)
turns.append(bot_output)
# USER: Xin chào
# ASSISTANT: Xin chào. Làm thế nào ViVi có thể giúp bạn?
# USER: Anh bị đau đầu quá
# ASSISTANT: Bạn có thể nói với ViVi nhiều hơn về cơn đau đầu của bạn?
# USER: anh bị đau nửa đầu về đêm, sáng dậy không tỉnh táo
# ASSISTANT: Điều quan trọng là bạn nhận thức được rằng cơn đau đầu của bạn không phải là điều hiếm gặp và nó có thể có nhiều nguyên nhân. Một số nguyên nhân phổ biến của cơn đau đầu là căng thẳng, thiếu ngủ, căng thẳng, chế độ ăn uống kém và mất nước.
# Nếu cơn đau đầu của bạn không giảm đi sau khi nghỉ ngơi và nghỉ ngơi, điều quan trọng là bạn nói chuyện với bác sĩ của bạn. Bác sĩ của bạn có thể giúp bạn xác định nguyên nhân của cơn đau đầu của bạn và đề xuất các phương pháp điều trị thích hợp.
# USER: có cách nào giảm đau tại nhà không?
# ASSISTANT: Có, có một số cách bạn có thể thử giảm đau đầu tại nhà:
# - Uống nhiều nước để giảm đau đầu do mất nước.
# - Nghỉ ngơi và ngủ nhiều hơn.
# - Áp dụng băng lạnh hoặc nóng vào khu vực đau.
# - Áp dụng thuốc giảm đau không kê đơn như ibuprofen hoặc paracetamol.
# - Thực hiện các kỹ thuật thư giãn như thiền, thở sâu hoặc yoga.
# - Massage khu vực bị ảnh hưởng.
# Điều quan trọng cần nhớ là trong khi các biện pháp khắc phục tại nhà có thể giúp giảm đau đầu, chúng không thay thế cho lời khuyên y tế chuyên nghiệp. Nếu cơn đau đầu của bạn vẫn tồn tại hoặc trở nên tồi tệ hơn, điều quan trọng là bạn nói chuyện với bác sĩ của bạn.
Modify the parameters "temperature", "top_k", "top_p" to suit your usecase.
Limitations and Future Research
The published model has certain limitations. For example, it performs poorly on tasks involving reasoning, coding or mathematics. In addition, the model will occasionally produce harmful, biased responses, or answer unsafe questions. Users should be cautious while interacting with VBD-LLaMA2-7B-50b-Chat and verify important information taken from the model's outputs because such infomation can be factually incorrect.
This model has been trained on and exhibits decent capability to tackle Vietnamese tasks, especially those associated with conversations. However, the model still struggles with questions related to Vietnamese history, culture, and society. We recommend some approaches to further improve this model:
- Data Distillation: Construct a small dataset of local/in-domain knowledge to continuously train the model. You might find great ideas searching through the topic of domain adaptation too ;)
- Merging/Combining/Ensembling Models: There have been numerous models developed based on Meta's LLaMA, so another approach might be to a training process similar to knowledge distilation, where the teacher consists of combinations of previously trained models.
- RLHF/Alignment: The model has not been trained with RFHF or alignment techniques such as DPO.
- Retrieval Augmented Generation (RAG): Combine the model with external knowledge sources.
Acknowledgements:
We would like to express our gratitude towards the Virtual Assistant Technology Center at VinBigData JSC. led by Dr. Kim Anh Nguyen for providing us with the necessary resources to deliver this project. We are also greatly indebted to our fellow colleagues at the Natural Language Processing Department at VinBigData, whose feedbacks and expertise had been of great help.
Citation
If you find our project useful, we hope you would kindly star our repo and cite our work as follows:
Corresponding Author:
- Downloads last month
- 33