
Reference-Image-Embed-Manga-Colorization
An amazing manga colorization project
You can colorize gray manga or character sketches using any reference image you want, this model will faithfully retain the color features and transfer them to your manga. This is useful when you wish the color of the character's hair or clothes to be consistent.
If the project is helpful, please leave a ⭐ this repo. best luck, my friend 😊
Overview
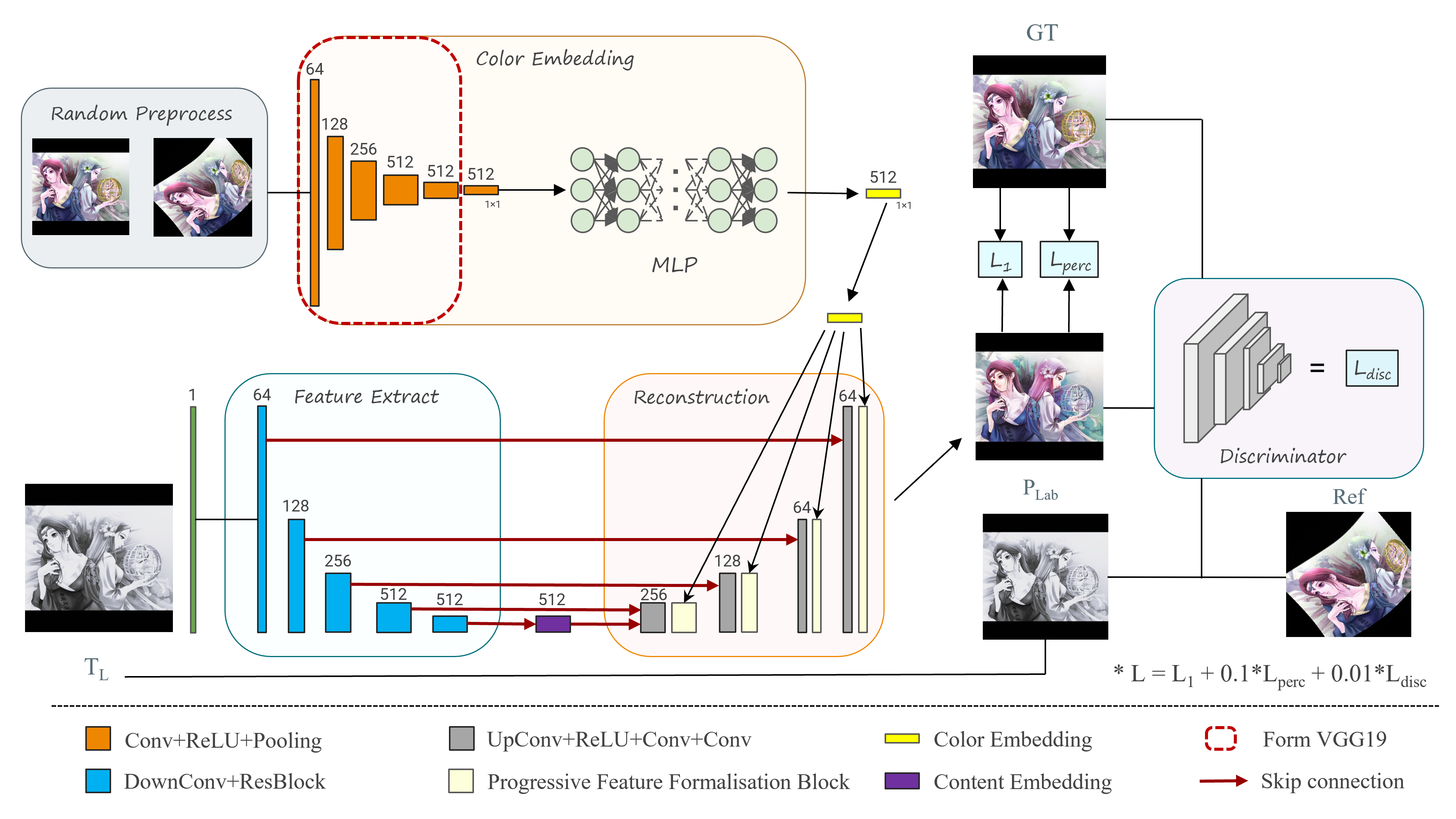
It's basically a cGAN(Conditional Generative Adversarial Network) architecture.
Generator
Generator is divided into two parts.
Color Embedding Layer consists of part of pretrained VGG19 net and an MLP(Multilayer Perceptron), which is used to extract color embedding from reference image(for training, its preprocessed Ground Truth Image).
Another part is a U-net-like network. The encoder layer extracts content embedding from gray input image(only contains L-channel information), and the decoder layer reconstructs the image with color embedding through PFFB(Progressive Feature Formalization Block) and outputs the ab_channel information.
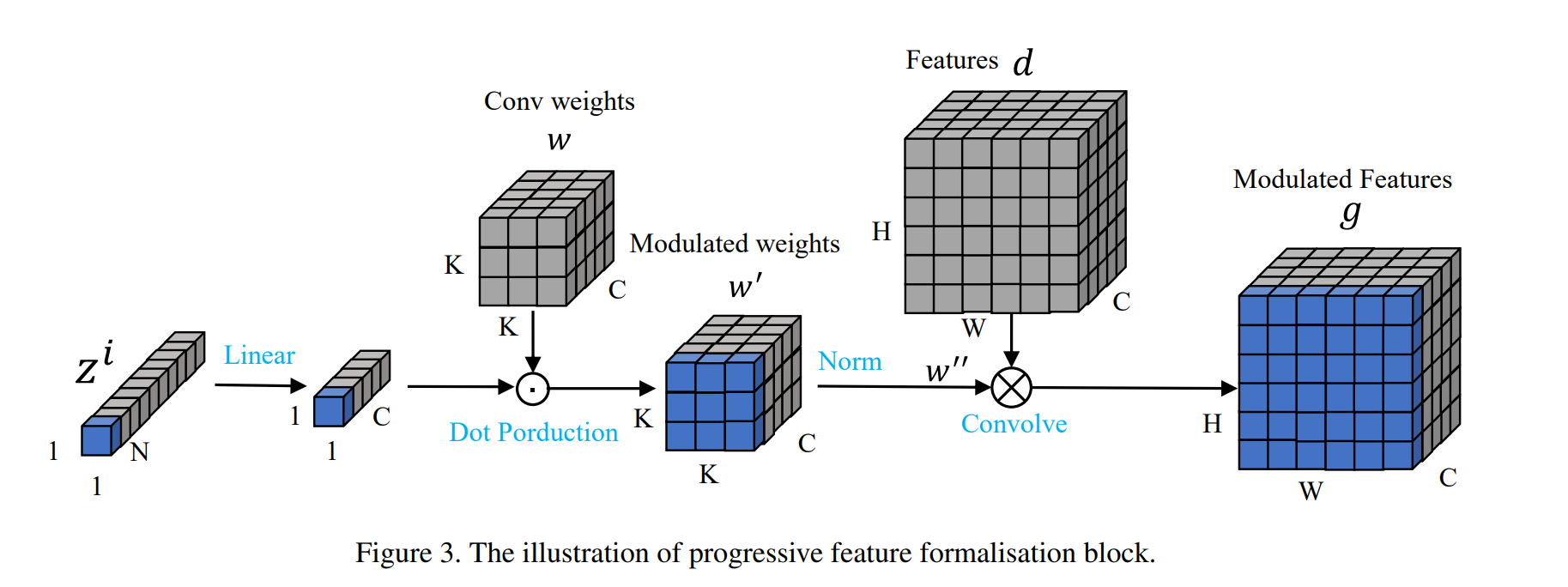
The figure shows how PFFB works.
It generates a filter by applying color embedding, and then convolving with content features. The figure is from this paper and check it for more details.
Discriminator
Discriminator is a PatchGAN, referring to pix2pix. The difference is that there are two conditions used for input. One is the gray image waiting for colorization, and one is the reference image providing color information.
Loss
There are three losses in total, L1 loss, perceptual loss produced by pretrained vgg19, and adversarial loss produced by discriminator. The ratio is 1: 0.1: 0.01.
Pipeline
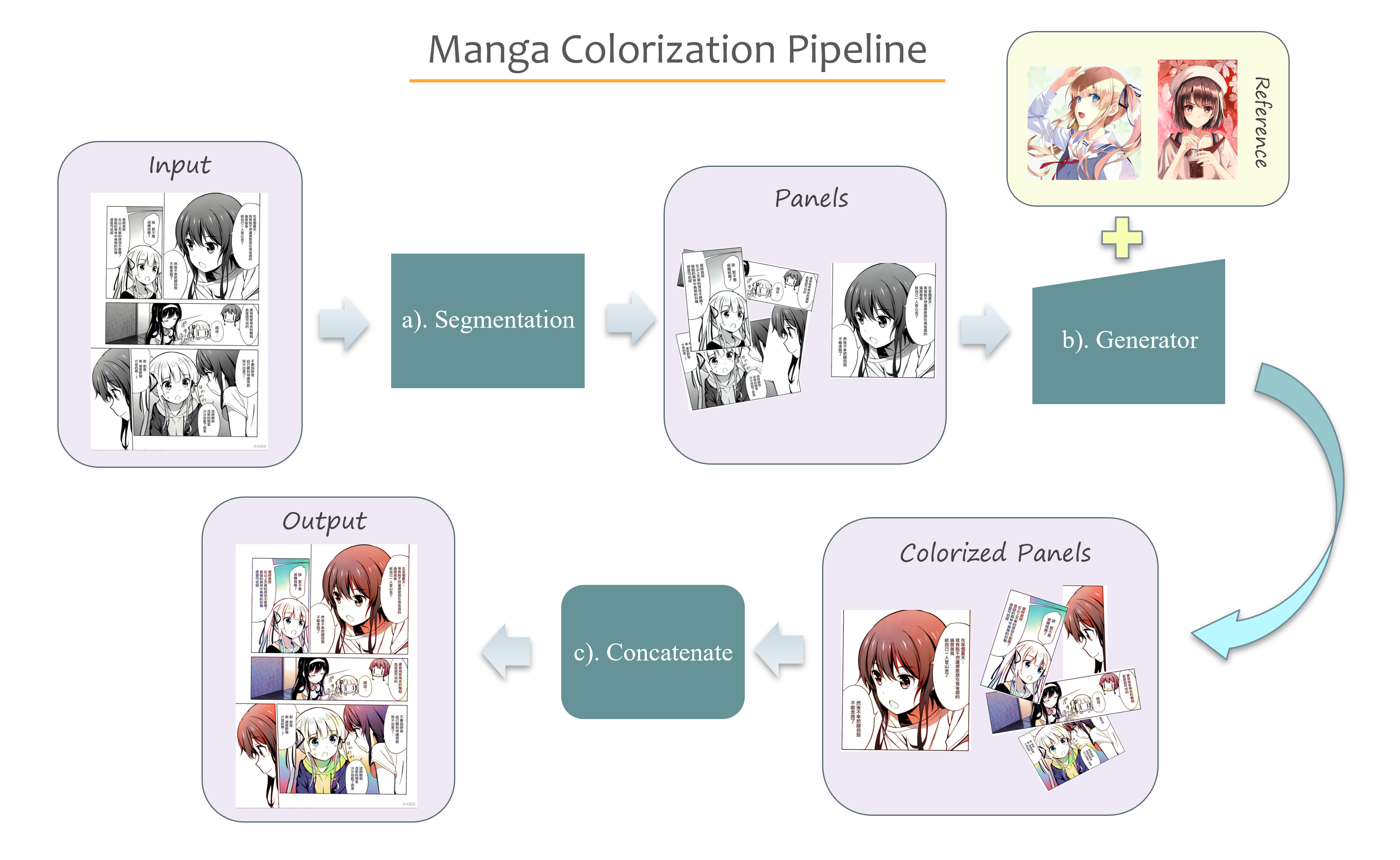
- a. Segment panels from input manga image,
Manga-Panel-Extractoris from here. - b. Select a reference image for each panel, and generator will colorize each panel.
- c. Concatenate all colorized panels into original format.
Results
Gray model
| Original | Reference | Colorization |
|---|---|---|
 |
 |
 |
|
 |
 |
 |
 |
 |
|
 |
 |
 |
 |
 |
|
 |
 |
 |
  |
 |
 |
   |
 |
 |
 |
 |
sketch model
| Original | Reference | Colorization |
|---|---|---|
 |
 |
 |
|
 |
 |
Dependencies and Installation
Clone this GitHub repo.
git clone https://github.com/linSensiGit/Example_Based_Manga_Colorization---cGAN.git cd Example_Based_Manga_Colorization---cGANCreate Environment
Python >= 3.6 (Recommend to use Anaconda)
PyTorch >= 1.5.0 (Default GPU mode)
# My environment for reference - Python = 3.9.15 - PyTorch = 1.13.0 - Torchvision = 0.14.0 - Cuda = 11.7 - GPU = RTX 3060tiInstall Dependencies
pip3 install -r requirement.txt
Get Started
Once you've set up the environment, several things need to be done before colorization.
Prepare pretrained models
Download generator. I have trained two generators, for gray manga colorization and sketch colorization. Choose what you need.
Download VGG model , it's part of generator.
Download discriminator, for training gray manga colorization and sketch colorization. (optional)
Put the pretrained model in the correct directory:
Colorful-Manga-GAN |- experiments |- Color2Manga_gray |- xxx000_gray.pt |- Color2Manga_sketch |- xxx000_sketch.pt |- Discriminator |- xxx000_d.pt |- VGG19 |- vgg19-dcbb9e9d.pth
Quick test
I have collected some test datasets which contain manga pages and corresponding reference images. You can check it in the path ./test_datasets. When you use the file inference.py to test, you may need to edit the input file path or pretrained weights path in this file.
python inference.py
# If you don't want to segment your manga
python inference.py -ne
Initially, Manga-Panel-Extractor will segment the manga page into panels.
Then follow the instructions in the console and you will get the colorized image.
Train your Own Model
Prepare Datasets
There are three datasets I used to train the model.
For gray model, Anime Face Dataset and Tagged Anime Illustrations Dataset are used. And I only use danbooru-images folder in the second Dataset.
For sketch model, Anime Sketch Colorization Pair Dataset is used.
All the datasets are from Kaggle.
Follow instructions are based on my dataset, but feel free to use your own dataset if you like.
Preprocess training data
cd data
python prepare_data.py
If you are using Anime Sketch Colorization Pair dataset :
python prepare_data_sketch.py
Several arguments needed to be assigned :
usage: prepare_data.py [-h] [--out OUT] [--size SIZE] [--n_worker N_WORKER]
[--resample RESAMPLE]
path
positional arguments:
path the path of datasets
optional arguments:
-h, --help show this help message and exit
--out OUT the path to save generated lmdb
--size SIZE compressed image size (128, 256, 512, 1024) alternative
--n_worker N_WORKER The number of threads, depends on your CPU
--resample RESAMPLE
For instance, you can run the command like this:
python prepare_data.py --out ../train_datasets/Sketch_train_lmdb --n_worker 20 --size 256 E:/Dataset/animefaces256cleaner
Training
There are four scripts in total for training
train.py —— train only generator
train_disc —— train only discriminator
train_all_gray.py—— train both generator and discriminator, under the usual dataset
train_all_sketch.py—— train both generator and discriminator, under sketch pair dataset specific
All of these scripts share similar commands to drive:
usage: train_all_gray.py [-h] [--datasets DATASETS] [--iter ITER]
[--batch BATCH] [--size SIZE] [--ckpt CKPT]
[--ckpt_disc CKPT_DISC] [--lr LR] [--lr_disc LR_DISC]
[--experiment_name EXPERIMENT_NAME] [--wandb]
[--local_rank LOCAL_RANK]
optional arguments:
-h, --help show this help message and exit
--datasets DATASETS the path of training dataset
--iter ITER number of iteration in total
--batch BATCH batch size
--size SIZE size of image in dataset, usually 256
--ckpt CKPT path of pretrained generator
--ckpt_disc CKPT_DISC path of pretrained discriminator
--lr LR learning rate of generator
--lr_disc LR_DISC learning rate of discriminator
--experiment_name EXPERIMENT_NAME used to save training_logs and trained model
--wandb
--local_rank LOCAL_RANK
There may be a slight difference, you could check the code for more details.
For instance, you can run the command like this:
python train_all_gray.py --batch 8 --experiment_name Color2Manga_sketch --ckpt experiments/Color2Manga_sketch/078000.pt --datasets ./train_datasets/Sketch_train_lmdb --ckpt_disc experiments/Discriminator/078000_d.pt
Work in Progress
- Add SR model instead of directly interpolate upscaling
- Optimize the generator network(adding L-channel information to output which is essential for colorize sketch)
- Better developed manga-panel-extractor(current segmentation is not precise enough)
- Develop a front UI and add color hint so that users could adjust the color of a specific area
😁Contact
If you have any questions, please feel free to contact me via shizifeng0615@outlook.com
🙌 Acknowledgement
Based on https://github.com/zhaohengyuan1/Color2Embed
Thx https://github.com/pvnieo/Manga-Panel-Extractor
Reference
[1] Zhao, Hengyuan et al. “Color2Embed: Fast Exemplar-Based Image Colorization using Color Embeddings.” (2021).
[2] Isola, Phillip et al. “Image-to-Image Translation with Conditional Adversarial Networks.” 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2016): 5967-5976.
[3] Furusawa, Chie et al. “Comicolorization: semi-automatic manga colorization.” SIGGRAPH Asia 2017 Technical Briefs (2017): n. pag.
[4] Satoshi Iizuka, Edgar Simo-Serra, and Hiroshi Ishikawa. "Let there be Color!: Joint End-to-end Learning of Global and Local Image Priors for Automatic Image Colorization with Simultaneous Classification". ACM Transaction on Graphics (Proc. of SIGGRAPH), 35(4):110, 2016.