

add zeroclue
Browse files- .gitattributes +1 -0
- README.md +93 -0
- pytorch_model.bin +1 -1
- zeroclue.png +3 -0
.gitattributes
CHANGED
|
@@ -31,3 +31,4 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 31 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 32 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 33 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
| 31 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 32 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 33 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 34 |
+
*.png filter=lfs diff=lfs merge=lfs -text
|
README.md
CHANGED
|
@@ -23,6 +23,12 @@ widget:
|
|
| 23 |
|
| 24 |
On the basis of Randeng-T5-784M, about 100 Chinese datasets were collected and pre-trained for the supervised task of Text2Text unified paradigm.
|
| 25 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 26 |
## 模型分类 Model Taxonomy
|
| 27 |
|
| 28 |
| 需求 Demand | 任务 Task | 系列 Series | 模型 Model | 参数 Parameter | 额外 Extra |
|
|
@@ -105,9 +111,96 @@ example_dict={
|
|
| 105 |
'实体识别':{"text_a":"北京大学是我国的一座历史名校,坐落在海淀区,蔡元培曾经担任校长","question":"机构"},
|
| 106 |
'抽取式阅读理解':{"text_a":"《H》正式定档3月7日下午两点整在京东商城独家平台开启第一批5000份预售,定价230元人民币,回馈最忠实的火星歌迷,意在用精品回馈三年来跟随华晨宇音乐不离不弃的粉丝们的支持与厚爱","question":"华晨宇专辑h预售价格是多少?"},
|
| 107 |
'关键词抽取':{"text_a":"今儿在大众点评,找到了口碑不错的老茶故事私房菜。"},
|
|
|
|
| 108 |
|
| 109 |
"生成式摘要":{"text_a":"针对传统的流量分类管理系统存在不稳定、结果反馈不及时、分类结果显示不直观等问题,设计一个基于web的在线的流量分类管理系统.该系统采用流中前5个包(排除3次握手包)所含信息作为特征值计算资源,集成一种或多种分类算法用于在线网络流量分类,应用数据可视化技术处理分类结果.实验表明:在采用适应在线分类的特征集和c4.5决策树算法做分类时,系统能快速做出分类,且精度达到94%以上;数据可视化有助于人机交互,改善分类指导."}
|
| 110 |
}
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 111 |
```
|
| 112 |
|
| 113 |
## 预训练或微调 prtrain or finetune
|
|
|
|
| 23 |
|
| 24 |
On the basis of Randeng-T5-784M, about 100 Chinese datasets were collected and pre-trained for the supervised task of Text2Text unified paradigm.
|
| 25 |
|
| 26 |
+
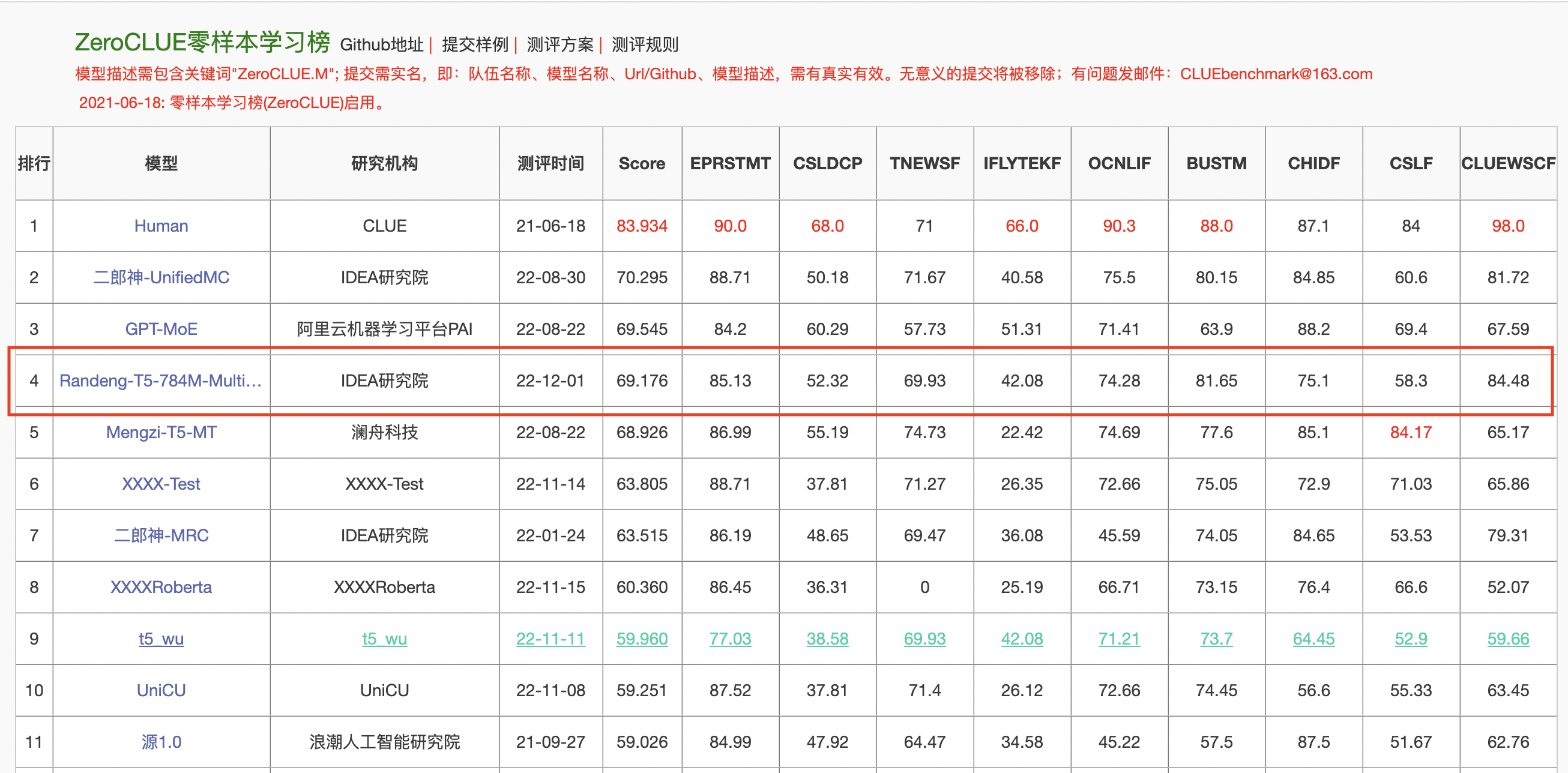
本模型在中文zero-shot榜单ZeroClue上取得了第三名(不包括人类)的成绩,在所有基于T5(encoder-decoder架构)的模型中排名第一。
|
| 27 |
+
|
| 28 |
+
This model achieved the 3rd place (excluding humans) on the Chinese zero-shot benchmark ZeroClue, ranking first among all models based on T5 (encoder-decoder architecture).
|
| 29 |
+
|
| 30 |
+

|
| 31 |
+
|
| 32 |
## 模型分类 Model Taxonomy
|
| 33 |
|
| 34 |
| 需求 Demand | 任务 Task | 系列 Series | 模型 Model | 参数 Parameter | 额外 Extra |
|
|
|
|
| 111 |
'实体识别':{"text_a":"北京大学是我国的一座历史名校,坐落在海淀区,蔡元培曾经担任校长","question":"机构"},
|
| 112 |
'抽取式阅读理解':{"text_a":"《H》正式定档3月7日下午两点整在京东商城独家平台开启第一批5000份预售,定价230元人民币,回馈最忠实的火星歌迷,意在用精品回馈三年来跟随华晨宇音乐不离不弃的粉丝们的支持与厚爱","question":"华晨宇专辑h预售价格是多少?"},
|
| 113 |
'关键词抽取':{"text_a":"今儿在大众点评,找到了口碑不错的老茶故事私房菜。"},
|
| 114 |
+
'关键词识别':{"text_a":"今儿在大众点评,找到了口碑不错的老茶故事私房菜。","question":"请问这篇文章的关键词是大众点评、老茶私房菜吗?,"choices":["是","不是"]}
|
| 115 |
|
| 116 |
"生成式摘要":{"text_a":"针对传统的流量分类管理系统存在不稳定、结果反馈不及时、分类结果显示不直观等问题,设计一个基于web的在线的流量分类管理系统.该系统采用流中前5个包(排除3次握手包)所含信息作为特征值计算资源,集成一种或多种分类算法用于在线网络流量分类,应用数据可视化技术处理分类结果.实验表明:在采用适应在线分类的特征集和c4.5决策树算法做分类时,系统能快速做出分类,且精度达到94%以上;数据可视化有助于人机交互,改善分类指导."}
|
| 117 |
}
|
| 118 |
+
|
| 119 |
+
# 构造prompt的过程中,verbalizer这个占位key的内容,是通过 "/".join(choices) 拼接起来
|
| 120 |
+
dataset2instruction = {
|
| 121 |
+
"情感分析": {
|
| 122 |
+
"prompt": "{}任务:【{}】这篇文章的情感态度是什么?{}",
|
| 123 |
+
"keys_order": ["subtask_type","text_a", "verbalizer"],
|
| 124 |
+
"data_type": "classification",
|
| 125 |
+
},
|
| 126 |
+
"文本分类": {
|
| 127 |
+
"prompt": "{}任务:【{}】这篇文章的类别是什么?{}",
|
| 128 |
+
"keys_order": ["subtask_type","text_a", "verbalizer"],
|
| 129 |
+
"data_type": "classification",
|
| 130 |
+
},
|
| 131 |
+
"新闻分类": {
|
| 132 |
+
"prompt": "{}任务:【{}】这篇文章的类别是什么?{}",
|
| 133 |
+
"keys_order": ["subtask_type","text_a", "verbalizer"],
|
| 134 |
+
"data_type": "classification",
|
| 135 |
+
},
|
| 136 |
+
"意图识别": {
|
| 137 |
+
"prompt": "{}任务:【{}】这句话的意图是什么?{}",
|
| 138 |
+
"keys_order": ["subtask_type","text_a", "verbalizer"],
|
| 139 |
+
"data_type": "classification",
|
| 140 |
+
},
|
| 141 |
+
# --------------------
|
| 142 |
+
"自然语言推理": {
|
| 143 |
+
"prompt": "{}任务:【{}】和【{}】,以上两句话的逻辑关系是什么?{}",
|
| 144 |
+
"keys_order": ["subtask_type","text_a", "text_b", "verbalizer"],
|
| 145 |
+
"data_type": "classification",
|
| 146 |
+
},
|
| 147 |
+
"语义匹配": {
|
| 148 |
+
"prompt": "{}任务:【{}】和【{}】,以上两句话的内容是否相似?{}",
|
| 149 |
+
"keys_order": ["subtask_type","text_a", "text_b", "verbalizer"],
|
| 150 |
+
"data_type": "classification",
|
| 151 |
+
},
|
| 152 |
+
# -----------------------
|
| 153 |
+
"指代消解": {
|
| 154 |
+
"prompt": "{}任务:文章【{}】中{}{}",
|
| 155 |
+
"keys_order": ["subtask_type","text_a", "question", "verbalizer"],
|
| 156 |
+
"data_type": "classification",
|
| 157 |
+
},
|
| 158 |
+
"多项选择": {
|
| 159 |
+
"prompt": "{}任务:阅读文章【{}】问题【{}】?{}",
|
| 160 |
+
"keys_order": ["subtask_type","text_a", "question", "verbalizer"],
|
| 161 |
+
"data_type": "classification",
|
| 162 |
+
},
|
| 163 |
+
# ------------------------
|
| 164 |
+
"抽取式阅读理解": {
|
| 165 |
+
"prompt": "{}任务:阅读文章【{}】问题【{}】的答案是什么?",
|
| 166 |
+
"keys_order": ["subtask_type","text_a", "question"],
|
| 167 |
+
"data_type": "mrc",
|
| 168 |
+
},
|
| 169 |
+
"实体识别": {
|
| 170 |
+
"prompt": "{}任务:找出【{}】这篇文章中所有【{}】类型的实体?",
|
| 171 |
+
"keys_order": ["subtask_type","text_a", "question"],
|
| 172 |
+
"data_type": "ner",
|
| 173 |
+
},
|
| 174 |
+
# ------------------------
|
| 175 |
+
"关键词抽取": {
|
| 176 |
+
"prompt": "{}任务:【{}】这篇文章的关键词是什么?",
|
| 177 |
+
"keys_order": ["subtask_type","text_a"],
|
| 178 |
+
"data_type": "keys",
|
| 179 |
+
},
|
| 180 |
+
"关键词识别":{
|
| 181 |
+
"prompt": "{}任务:阅读文章【{}】问题【{}】{}",
|
| 182 |
+
"keys_order": ["subtask_type","text_a","question","verbalizer"],
|
| 183 |
+
"data_type": "classification",
|
| 184 |
+
},
|
| 185 |
+
"生成式摘要": {
|
| 186 |
+
"prompt": "{}任务:【{}】这篇文章的摘要是什么?",
|
| 187 |
+
"keys_order": ["subtask_type","text_a"],
|
| 188 |
+
"data_type": "summ",
|
| 189 |
+
},
|
| 190 |
+
}
|
| 191 |
+
|
| 192 |
+
def get_instruction(sample):
|
| 193 |
+
|
| 194 |
+
template = dataset2instruction[sample["subtask_type"]]
|
| 195 |
+
# print(template)
|
| 196 |
+
# print(sample)
|
| 197 |
+
sample["instruction"] = template["prompt"].format(*[
|
| 198 |
+
sample[k] for k in template["keys_order"]
|
| 199 |
+
])
|
| 200 |
+
|
| 201 |
+
print(sample["instruction"])
|
| 202 |
+
|
| 203 |
+
return sample["instruction"]
|
| 204 |
```
|
| 205 |
|
| 206 |
## 预训练或微调 prtrain or finetune
|
pytorch_model.bin
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
size 3136623589
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:53a9274353c0e873b6c61a84d5210bfc78d3d2f78653f7911eb5cf09a9b964ca
|
| 3 |
size 3136623589
|
zeroclue.png
ADDED
|
Git LFS Details
|