
Synthetic Content Detection (SuSy family)
Collection
SuSy is a Spatial-Based Synthetic Image Detection and Recognition Model.
•
5 items
•
Updated
•
2

Model Results
| Dataset | Type | Model | Year | Recall |
|---|---|---|---|---|
| Flickr30k | Authentic | - | 2014 | 90.53 |
| Google Landmarks v2 | Authentic | - | 2020 | 64.54 |
| Synthbuster | Synthetic | Glide | 2021 | 53.50 |
| Synthbuster | Synthetic | Stable Diffusion 1.3 | 2022 | 87.00 |
| Synthbuster | Synthetic | Stable Diffusion 1.4 | 2022 | 87.10 |
| Synthbuster | Synthetic | Stable Diffusion 2 | 2022 | 68.40 |
| Synthbuster | Synthetic | DALL-E 2 | 2022 | 20.70 |
| Synthbuster | Synthetic | MidJourney V5 | 2023 | 73.10 |
| Synthbuster | Synthetic | Stable Diffusion XL | 2023 | 79.50 |
| Synthbuster | Synthetic | Firefly | 2023 | 40.90 |
| Synthbuster | Synthetic | DALL-E 3 | 2023 | 88.60 |
| Authors | Synthetic | Stable Diffusion 3 Medium | 2024 | 93.23 |
| Authors | Synthetic | Flux.1-dev | 2024 | 96.46 |
| In-the-wild | Synthetic | Mixed/Unknown | 2024 | 89.90 |
| In-the-wild | Authentic | - | 2024 | 33.06 |
SuSy is a Spatial-Based Synthetic Image Detection and Recognition Model, designed and trained to detect synthetic images and attribute them to a generative model (i.e., two StableDiffusion models, two Midjourney versions and DALL·E 3). The model takes image patches of size 224x224 as input, and outputs the probability of the image being authentic or having been created by each of the aforementioned generative models.
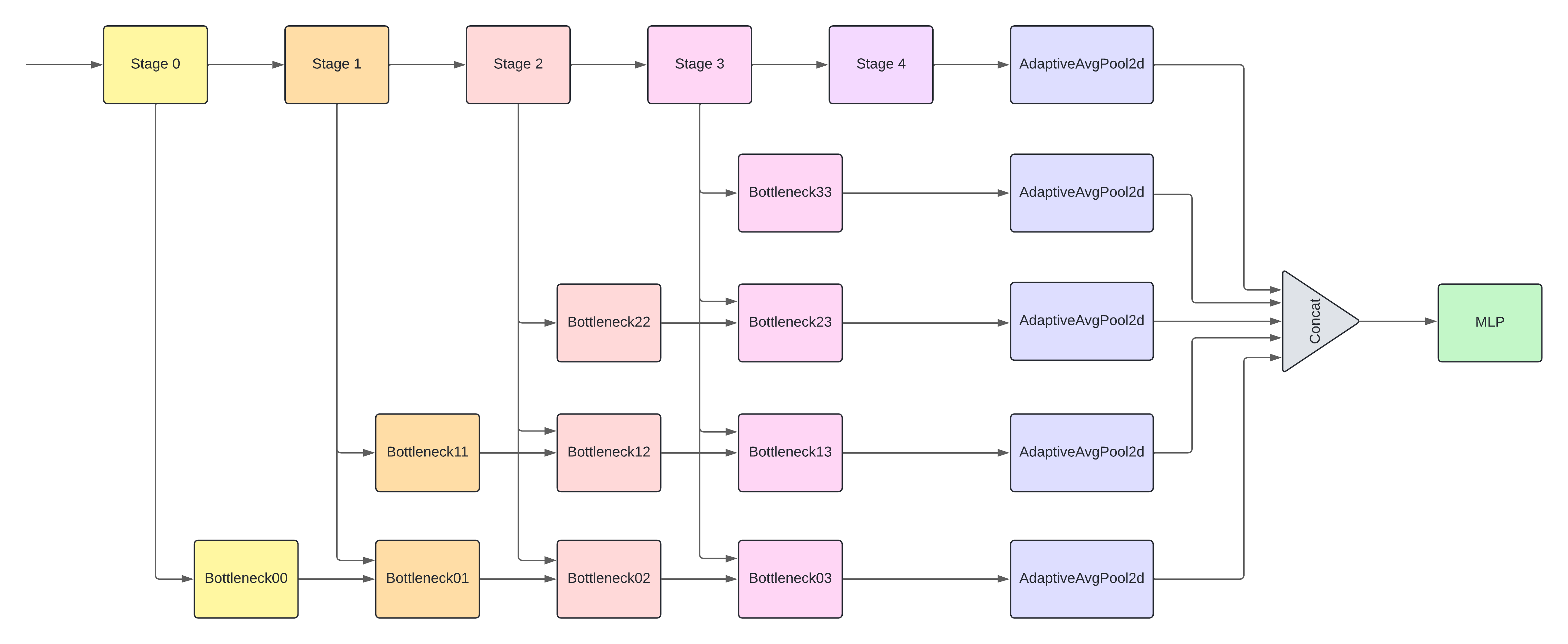
The model is based on a CNN architecture and is trained using a supervised learning approach. It's design is based on previous work, originally intended for video superresolution detection, adapted here for the tasks of synthetic image detection and recognition. The architecture consists of two modules: a feature extractor and a multi-layer perceptron (MLP), as it's quite light weight. SuSy has a total of 12.7M parameters, with the feature extractor accounting for 12.5M parameters and the MLP accounting for the remaining 197K.
The CNN feature extractor consists of five stages following a ResNet-18 scheme. The output of each of the blocks is used as input for various bottleneck modules that are arranged in a staircase pattern. The bottleneck modules consist of three 2D convolutional layers. Each level of bottlenecks takes input at a later stage than the previous level, and each bottleneck module takes input from the current stage and, except the first bottleneck of each level, from the previous bottleneck module.
The outputs of each level of bottlenecks and stage 4 are passed to a 2D adaptative average pooling layer and then concatenated to form the feature map feeding the MLP. The MLP consists of three fully connected layers with 512, 256 and 256 units, respectively. Between each layer, a dropout layer (rate of 0.5) prevents overfitting. The output of the MLP has 6 units, corresponding to the number of classes in the dataset (5 synthetic models and 1 real image class).
The model can be used as a detector by either taking the class with the highest probability as the output or summing the probabilities of the synthetic classes and comparing them to the real class. The model can also be used as an recognition model by taking the class with the highest probability as the output.
This model can be used to detect synthetic images in a scalable manner, thanks to its small size. Since it operates on patches of 224x224, a moving window should be implemented in inference when applied on larger inputs (the most likely scenario, and the one it was trained under). This also enables the capacity for synthetic content localization within a high resolution input.
Any individual or organization seeking for support on the identification of synthetic content can use this model. However, it should not be used as the only source of evidence, particularly when applied to inputs produced by generative models not included in its training (see details in Training Data below).
Intended uses include the following:
Out-of-scope uses include the following:
This model may not be used to train generative models or tools aimed at purposefully deceiving the model or creating misleading content.
The model may be biased in the following ways:
The model has the following technical limitations:
Use the code below to get started with the model.
import torch
from PIL import Image
from torchvision import transforms
# Load the model
model = torch.jit.load("SuSy.pt")
# Load patch
patch = Image.open("midjourney-images-example-patch0.png")
# Transform patch to tensor
patch = transforms.PILToTensor()(patch).unsqueeze(0) / 255.
# Predict patch
model.eval()
with torch.no_grad():
preds = model(patch)
print(preds)
See test_image.py and test_patch.py for other examples on how to use the model.
The dataset is available at: https://huggingface.co/datasets/HPAI-BSC/SuSy-Dataset
| Dataset | Year | Train | Validation | Test | Total |
|---|---|---|---|---|---|
| COCO | 2017 | 2,967 | 1,234 | 1,234 | 5,435 |
| dalle-3-images | 2023 | 987 | 330 | 330 | 1,647 |
| diffusiondb | 2022 | 2,967 | 1,234 | 1,234 | 5,435 |
| realisticSDXL | 2023 | 2,967 | 1,234 | 1,234 | 5,435 |
| midjourney-tti | 2022 | 2,718 | 906 | 906 | 4,530 |
| midjourney-images | 2023 | 1,845 | 617 | 617 | 3,079 |
We use a random subset of the COCO dataset, containing 5,435 images, for the authentic images in our training dataset. The partitions are made respecting the original COCO splits, with 2,967 images in the training partition and 1,234 in the validation and test partitions.
For the diffusiondb dataset, we use a random subset of 5,435 images, with 2,967 in the training partition and 1,234 in the validation and test partitions. We use only the realistic images from the realisticSDXL dataset, with images in the realistic-2.2 split in our training data and the realistic-1 split for our test partition. The remaining datasets are used in their entirety, with 60% of the images in the training partition, 20% in the validation partition and 20% in the test partition.
The training code is available at: https://github.com/HPAI-BSC/SuSy
Patch Extraction
To prepare the training data, we extract 240x240 patches from the images, minimizing the overlap between them. We then select the most informative patches by calculating the gray-level co-occurrence matrix (GLCM) for each patch. Given the GLCM, we calculate the contrast and select the five patches with the highest contrast. These patches are then passed to the model in their original RGB format and cropped to 224x224.
Data Augmentation
| Technique | Probability | Other Parameters |
|---|---|---|
| HorizontalFlip | 0.50 | - |
| RandomBrightnessContrast | 0.20 | brightness_limit=0.2 contrast_limit=0.2 |
| RandomGamma | 0.20 | gamma_limit=(80, 120) |
| AdvancedBlur | 0.20 | |
| GaussianBlur | 0.20 | |
| JPEGCompression | 0.20 | quality_lower=75 quality_upper=100 |
The evaluation code is available at: https://github.com/HPAI-BSC/SuSy
| Dataset | Year | Recall |
|---|---|---|
| Flickr30k | 2014 | 90.53 |
| Google Landmarks v2 | 2020 | 64.54 |
| In-the-wild | 2024 | 33.06 |
| Dataset | Model | Year | Recall |
|---|---|---|---|
| Synthbuster | Glide | 2021 | 53.50 |
| Synthbuster | Stable Diffusion 1.3 | 2022 | 87.00 |
| Synthbuster | Stable Diffusion 1.4 | 2022 | 87.10 |
| Synthbuster | Stable Diffusion 2 | 2022 | 68.40 |
| Synthbuster | DALL-E 2 | 2022 | 20.70 |
| Synthbuster | MidJourney V5 | 2023 | 73.10 |
| Synthbuster | Stable Diffusion XL | 2023 | 79.50 |
| Synthbuster | Firefly | 2023 | 40.90 |
| Synthbuster | DALL-E 3 | 2023 | 88.60 |
| Authors | Stable Diffusion 3 Medium | 2024 | 93.23 |
| Authors | Flux.1-dev | 2024 | 96.46 |
| In-the-wild | Mixed/Unknown | 2024 | 89.90 |
The results for authentic image datasets reveal varying detection performance across different sources. Recall rates range from 33.06% for the In-the-wild dataset to 90.53% for the Flickr30k dataset. The Google Landmarks v2 dataset shows an intermediate recall rate of 64.54%. These results indicate a significant disparity in the detectability of authentic images across different datasets, with the In-the-wild dataset presenting the most challenging case for SuSy.
The results for synthetic image datasets show varying detection performance across different image generation models. Recall rates range from 20.70% for DALL-E 2 (2022) to 96.46% for Flux.1-dev (2024). Stable Diffusion models generally exhibited high detectability, with versions 1.3 and 1.4 (2022) showing recall rates above 87%. More recent models tested by the authors, such as Stable Diffusion 3 Medium (2024) and Flux.1-dev (2024), demonstrate even higher detectability with recall rates above 93%. The in-the-wild mixed/unknown synthetic dataset from 2024 showed a high recall of 89.90%, indicating effective detection across various unknown generation methods. These results suggest an overall trend of improving detection capabilities for synthetic images, with newer generation models generally being more easily detectable.
It must be noted that these metrics were computed using the center-patch of images, instead of using the patch voting mechanisms described previously. This strategy allows a more fair comparison with other state-of-the-art methods although it hinders the performance of SuSy.
BibTeX:
@misc{bernabeu2024susy,
title={Present and Future Generalization of Synthetic Image Detectors},
author={Pablo Bernabeu-Perez and Enrique Lopez-Cuena and Dario Garcia-Gasulla},
year={2024},
eprint={2409.14128},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2409.14128},
}
@thesis{bernabeu2024aidetection,
title={Detecting and Attributing AI-Generated Images with Machine Learning},
author={Bernabeu Perez, Pablo},
school={UPC, Facultat d'Informàtica de Barcelona, Departament de Ciències de la Computació},
year={2024},
month={06}
}
Pablo Bernabeu Perez and Dario Garcia Gasulla
For further inquiries, please contact HPAI