
Guernika
This repository contains Guernika compatible models and instructions to convert existing models.
While these models and instructions were created for Guernika, they should work and help with any CoreML based solution.
Converting Models to Guernika
WARNING: Xcode is required to convert models:
Make sure you have Xcode installed.
Once installed run the following commands:
sudo xcode-select --switch /Applications/Xcode.app/Contents/Developer/
sudo xcodebuild -license accept
- You should now be ready to start converting models!
Easy mode
Step 1: Download and install Guernika Model Converter.

Step 2: Launch Guernika Model Converter from your Applications folder, this app may take a few seconds to load.
Step 3: Once the app has loaded you will be able to select what model you want to convert:
You can input the model identifier (e.g. CompVis/stable-diffusion-v1-4) to download from Hugging Face. You may have to log in to or register for your Hugging Face account, generate a User Access Token and use this token to set up Hugging Face API access by running
huggingface-cli loginin a Terminal window.You can select a local model from your machine:
Select local modelYou can select a local .CKPT model from your machine:
Select CKPT
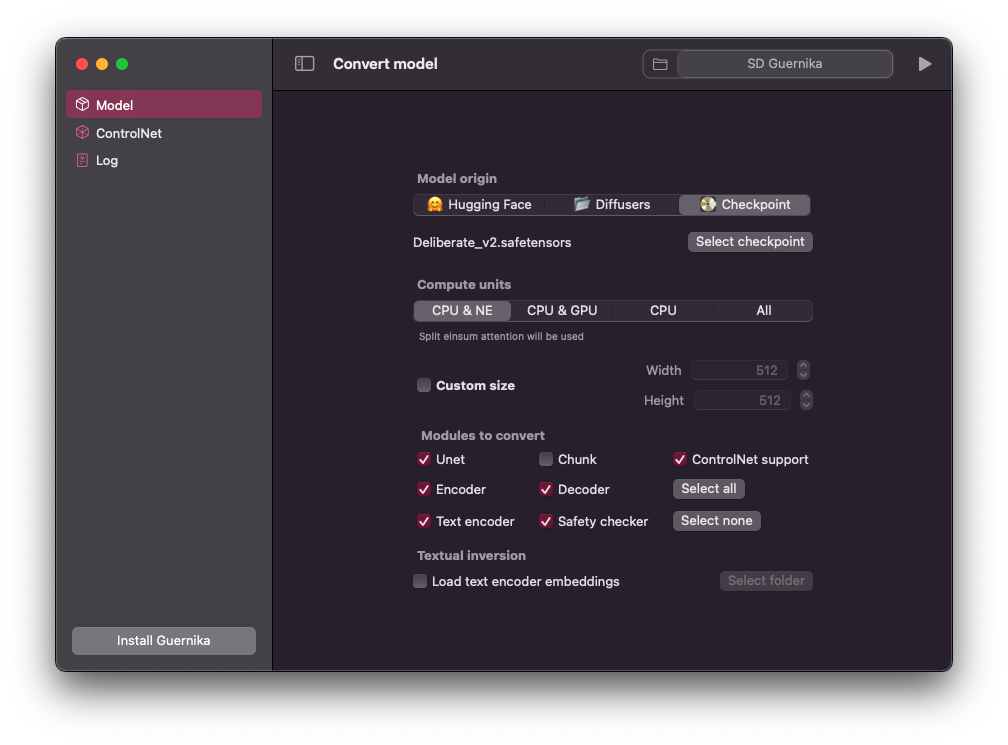
Step 4: Once you've chosen the model you want to convert you can choose what modules to convert and/or if you want to chunk the UNet module (recommended for iOS/iPadOS devices).
Step 5: Once you're happy with your selection click Convert to Guernika and wait for the app to complete conversion.
WARNING: This command may download several GB worth of PyTorch checkpoints from Hugging Face and may take a long time to complete (15-20 minutes on an M1 machine).
Advance mode
Step 1: Create a Python environment and install dependencies:
conda create -n guernika python=3.8 -y
conda activate guernika
cd /path/to/unziped/scripts/location
pip install -e .
Step 2: Choose what model you want to convert:
Huggin Face model: Log in to or register for your Hugging Face account, generate a User Access Token and use this token to set up Hugging Face API access by running huggingface-cli login in a Terminal window.
Once you know what model you want to convert and have accepted its Terms of Use, run the following command replacing <model-identifier> with the desired model's identifier:
python -m python_coreml_stable_diffusion.torch2coreml --model-version <model-identifier> -o <output-directory> --convert-unet --convert-text-encoder --convert-vae-encoder --convert-vae-decoder --convert-safety-checker --bundle-resources-for-guernika --clean-up-mlpackages
Local model: Run the following command replacing <model-location> with the desired model's location path:
python -m python_coreml_stable_diffusion.torch2coreml --model-location <model-location> -o <output-directory> --convert-unet --convert-text-encoder --convert-vae-encoder --convert-vae-decoder --convert-safety-checker --bundle-resources-for-guernika --clean-up-mlpackages
Local CKPT: Run the following command replacing <checkpoint-path> with the desired CKPT's location path:
python -m python_coreml_stable_diffusion.torch2coreml --checkpoint-path <checkpoint-path> -o <output-directory> --convert-unet --convert-text-encoder --convert-vae-encoder --convert-vae-decoder --convert-safety-checker --bundle-resources-for-guernika --clean-up-mlpackages
WARNING: These commands may download several GB worth of PyTorch checkpoints from Hugging Face.
This generally takes 15-20 minutes on an M1 MacBook Pro. Upon successful execution, the neural network models that comprise Stable Diffusion's model will have been converted from PyTorch to Guernika and saved into the specified <output-directory>.
Notable arguments
--model-version: The model version defaults to CompVis/stable-diffusion-v1-4. Developers may specify other versions that are available on Hugging Face Hub, e.g. stabilityai/stable-diffusion-2-base & runwayml/stable-diffusion-v1-5.--model-location: The location of a local model defaults toNone.--checkpoint-path: The location of a local .CKPT model defaults toNone.--bundle-resources-for-guernika: Compiles all 4 models and bundles them along with necessary resources for text tokenization into<output-mlpackages-directory>/Resourceswhich should provided as input to the Swift package. This flag is not necessary for the diffusers-based Python pipeline.--clean-up-mlpackages: Cleans up created .mlpackages leaving only the compiled model.--chunk-unet: Splits the Unet model in two approximately equal chunks (each with less than 1GB of weights) for mobile-friendly deployment. This is required for ANE deployment on iOS and iPadOS. This is not required for macOS. Swift CLI is able to consume both the chunked and regular versions of the Unet model but prioritizes the former. Note that chunked unet is not compatible with the Python pipeline because Python pipeline is intended for macOS only. Chunking is for on-device deployment with Swift only.--attention-implementation: Defaults toSPLIT_EINSUMwhich is the implementation described in Deploying Transformers on the Apple Neural Engine.--attention-implementation ORIGINALwill switch to an alternative that should be used for non-ANE deployment. Please refer to the Performance Benchmark section for further guidance.--check-output-correctness: Compares original PyTorch model's outputs to final Core ML model's outputs. This flag increases RAM consumption significantly so it is recommended only for debugging purposes.